
 Technologie-Peripheriegeräte
KI
Ist Transformers bahnbrechendes Papier schockierend? Das Bild stimmt nicht mit dem Code überein und der mysteriöse Fehler macht mich dumm
Technologie-Peripheriegeräte
KI
Ist Transformers bahnbrechendes Papier schockierend? Das Bild stimmt nicht mit dem Code überein und der mysteriöse Fehler macht mich dumm
Ist Transformers bahnbrechendes Papier schockierend? Das Bild stimmt nicht mit dem Code überein und der mysteriöse Fehler macht mich dumm

Heute wurde der KI-Kreis von einem schockierenden „Umsturz“ schockiert.
Das Diagramm in „Attention Is All Your Need“, der NLP-Grundlagenarbeit von Google Brain und Urheber der Transformer-Architektur, wurde von Internetnutzern herausgenommen und mit dem Code zusammengeführt . Inkonsistent.

Papieradresse: https://arxiv.org /abs/1706.03762
Seit seiner Einführung im Jahr 2017 hat sich Transformer zum Eckpfeiler im KI-Bereich entwickelt. Sogar der wahre Mastermind hinter dem beliebten ChatGPT ist er.
Auch Google hat 2019 eigens dafür ein Patent angemeldet.

geht auf den Ursprung zurück, und nun verschiedene GPTs (Generative Pre- gelernter Transformer), alle stammen aus dieser 17-jährigen Arbeit.
Laut Google Scholar wurde dieses grundlegende Werk bisher mehr als 70.000 Mal zitiert.

Der Grundstein von ChatGPT ist also nicht stabil?
Als „Urheber“ des Papiers ist das Strukturdiagramm tatsächlich falsch?
Sebastian Raschka, Gründer von Lightning AI und Forscher für maschinelles Lernen, hat herausgefunden, dass das Transformer-Diagramm in diesem Artikel falsch ist.
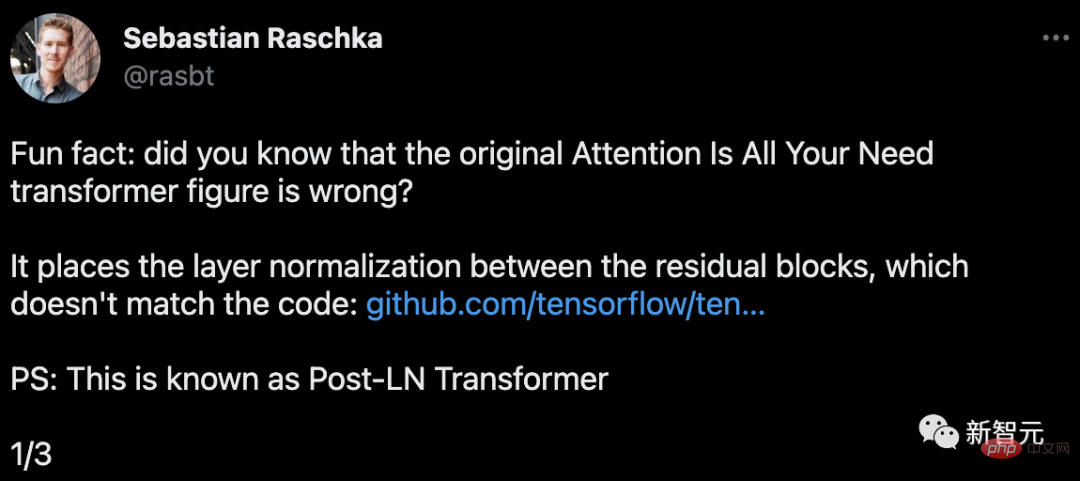
Der im Bild eingekreiste Bereich, LayerNorms, liegt hinter der Aufmerksamkeits- und vollständig verbundenen Ebene. Die Platzierung der Schichtnormalisierung zwischen Restblöcken führt zu großen erwarteten Gradienten für Parameter in der Nähe der Ausgabeschicht.
Außerdem steht dies im Widerspruch zum Code.
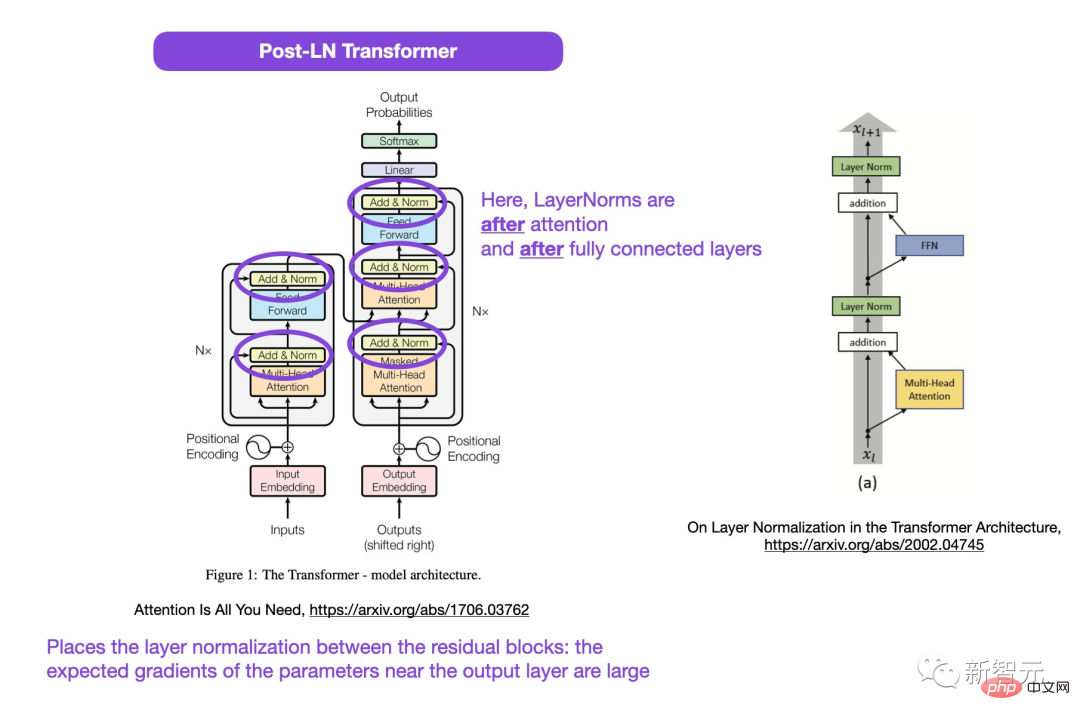
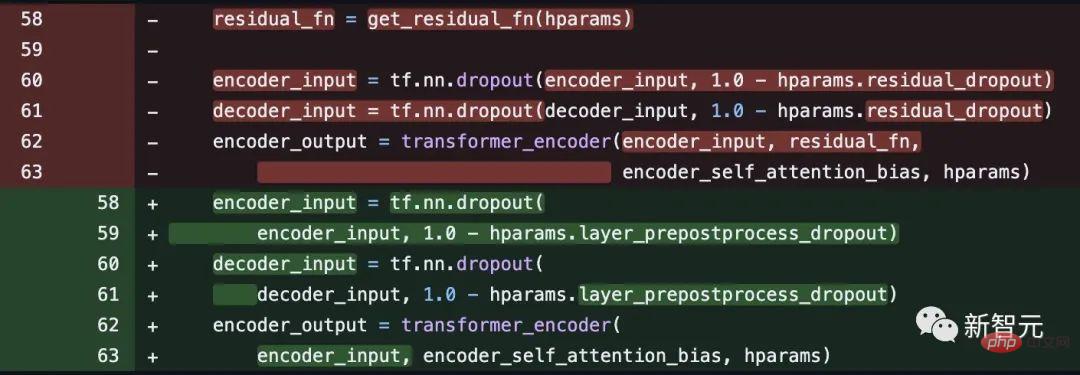
Codeadresse: https://github.com/tensorflow/tensor2tensor/commit/f5c9b17e617ea9179b7d84d36b1e8162cb369f25#diff-76e2b94ef16871bdbf46bf04dfe7f147 7bafb884748f08197c9cf1b10a4dd78e
# 🎜 🎜# Einige Internetnutzer wiesen jedoch darauf hin, dass Noam Shazeer den Code einige Wochen später korrigierte.
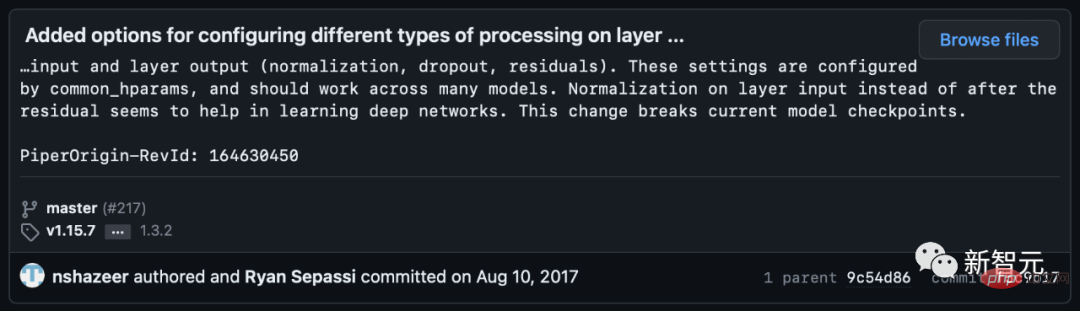

Dies ist, was viele oder die meisten Architekturen in der Praxis übernehmen, aber es kann zu einem Zusammenbruch der Repräsentation führen.
Wenn die Ebenennormalisierung in der Restverbindung vor den Aufmerksamkeits- und vollständig verbundenen Ebenen platziert wird, werden bessere Farbverläufe erzielt.
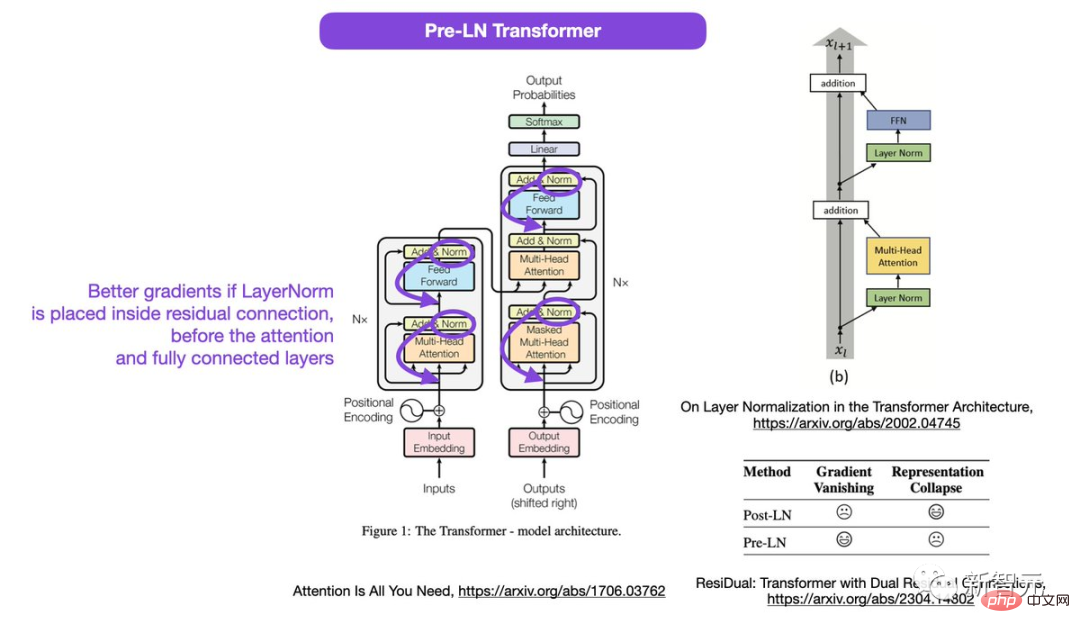
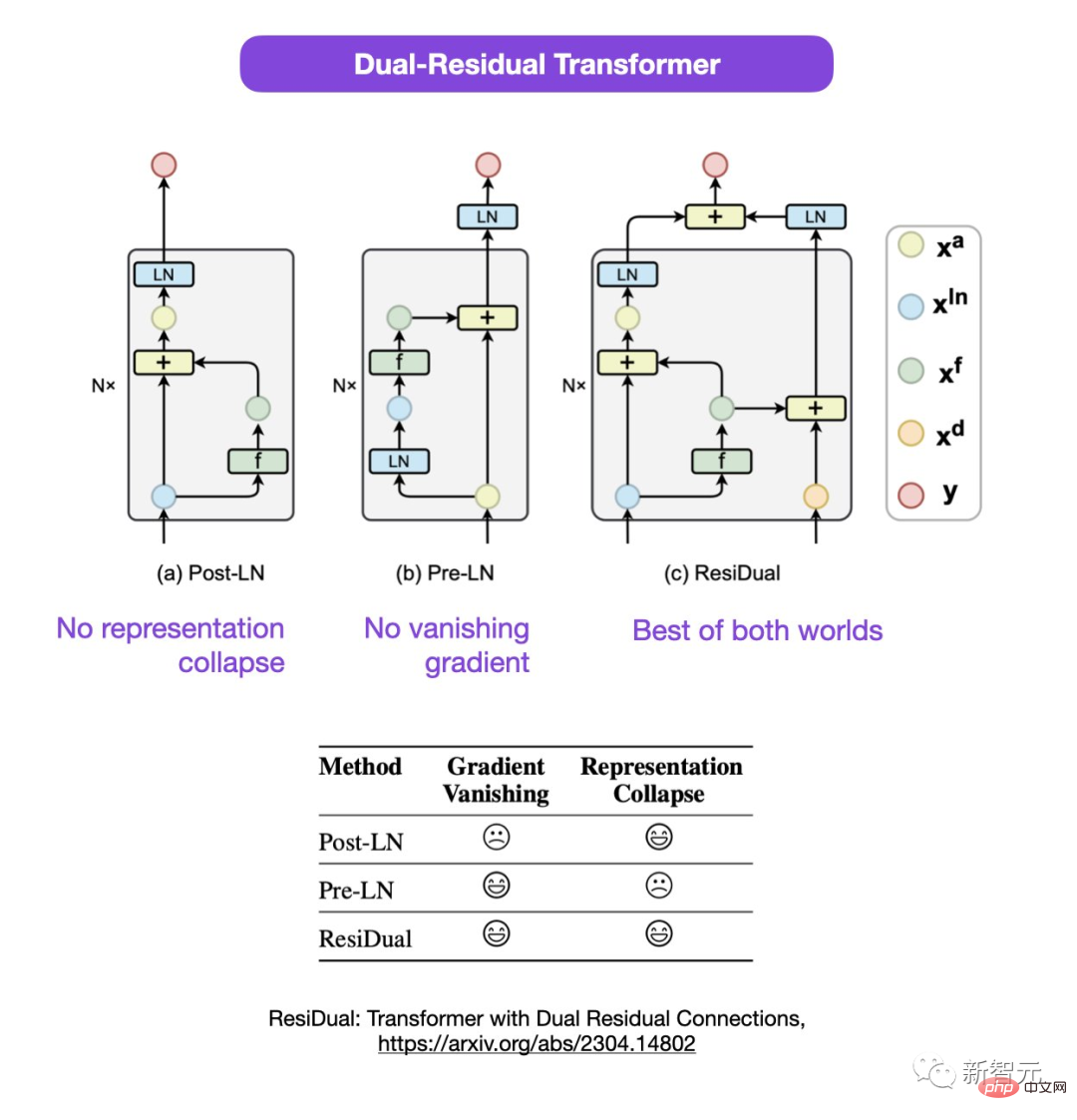
Sebastian schlug vor, dass die Diskussion über die Verwendung von Post-LN oder Pre-LN zwar noch andauert, es aber auch einen neuen Artikel gibt, der vorschlägt, beide zu kombinieren.

Papieradresse: https://arxiv.org/abs/2304.14802
In diesem doppelten Resttransformator werden die Probleme des Darstellungskollapses und des Gradientenverschwindens gelöst.
Heiße Netizen-Diskussion
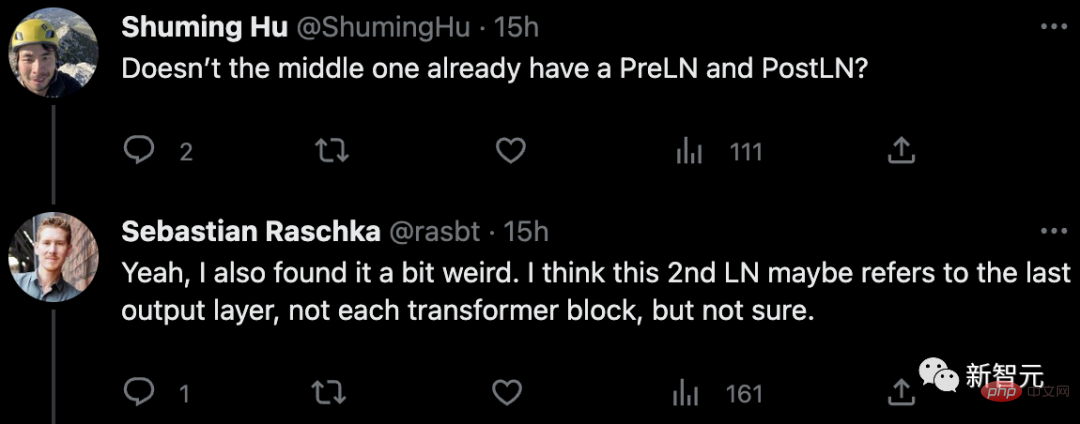
Als Antwort auf Die Zeitung In Bezug auf Zweifel wiesen einige Internetnutzer darauf hin: Gibt es nicht bereits PreLN und PostLN in der Mitte?
Sebastian antwortete, dass er sich auch etwas seltsam fühle. Vielleicht bezieht sich 2. LN eher auf die letzte Ausgangsschicht als auf jeden Transformatorblock, aber auch da ist er sich nicht sicher.
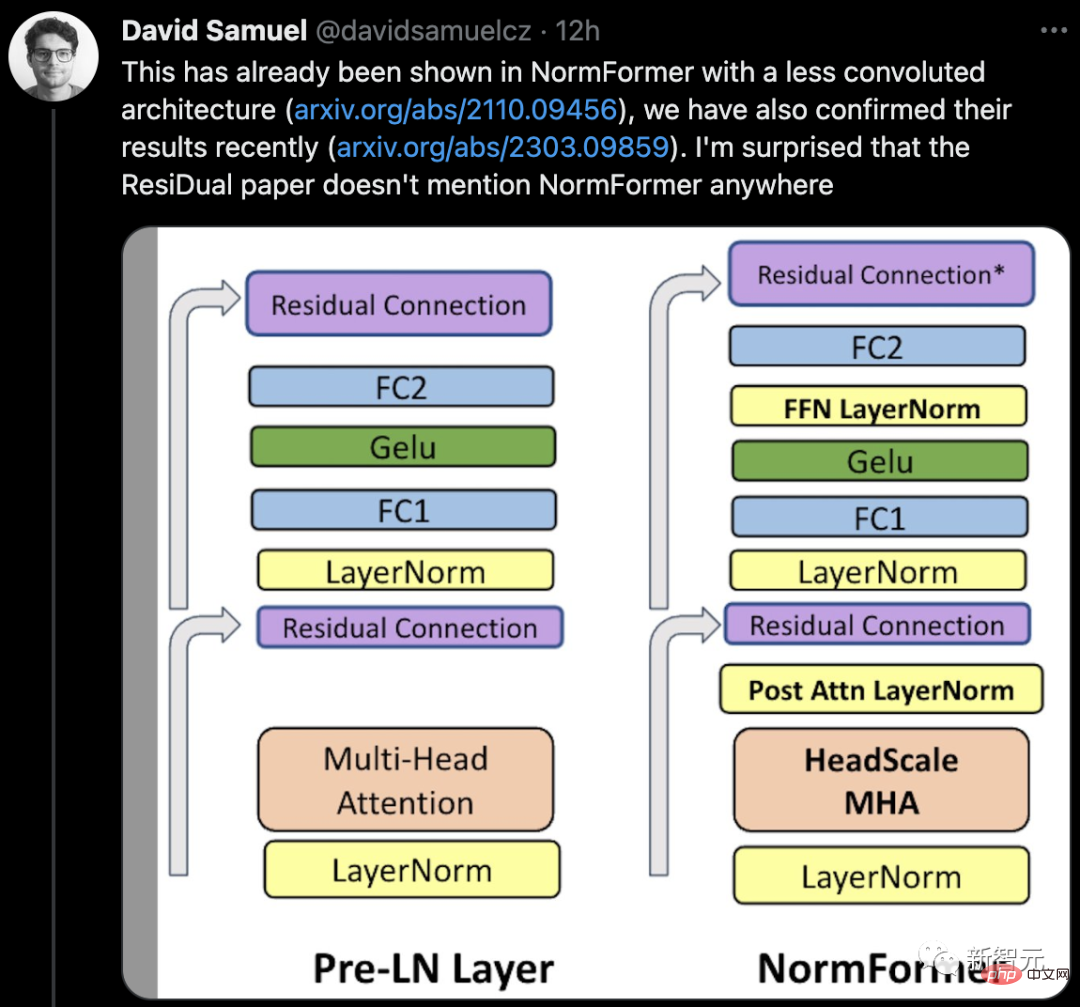
Einige Internetnutzer sagten: „Wir stoßen oft auf Inkonsistenzen mit dem Code oder den Ergebnissen.“ . Die meisten davon sind Fehler, aber manchmal ist es seltsam, dass diese Art von Frage noch nie aufgeworfen wurde #



# 🎜 🎜# Also, gibt es wirklich eine Lücke in dem Papier oder handelt es sich um einen eigenen Vorfall?
Also, gibt es wirklich eine Lücke in dem Papier oder handelt es sich um einen eigenen Vorfall?
Lasst uns abwarten, was als nächstes passiert.
Das obige ist der detaillierte Inhalt vonIst Transformers bahnbrechendes Papier schockierend? Das Bild stimmt nicht mit dem Code überein und der mysteriöse Fehler macht mich dumm. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 15 empfohlene kostenlose Open-Source-Bildanmerkungstools
Mar 28, 2024 pm 01:21 PM
15 empfohlene kostenlose Open-Source-Bildanmerkungstools
Mar 28, 2024 pm 01:21 PM
Bei der Bildanmerkung handelt es sich um das Verknüpfen von Beschriftungen oder beschreibenden Informationen mit Bildern, um dem Bildinhalt eine tiefere Bedeutung und Erklärung zu verleihen. Dieser Prozess ist entscheidend für maschinelles Lernen, das dabei hilft, Sehmodelle zu trainieren, um einzelne Elemente in Bildern genauer zu identifizieren. Durch das Hinzufügen von Anmerkungen zu Bildern kann der Computer die Semantik und den Kontext hinter den Bildern verstehen und so den Bildinhalt besser verstehen und analysieren. Die Bildanmerkung hat ein breites Anwendungsspektrum und deckt viele Bereiche ab, z. B. Computer Vision, Verarbeitung natürlicher Sprache und Diagramm-Vision-Modelle. Sie verfügt über ein breites Anwendungsspektrum, z. B. zur Unterstützung von Fahrzeugen bei der Identifizierung von Hindernissen auf der Straße und bei der Erkennung und Diagnose von Krankheiten durch medizinische Bilderkennung. In diesem Artikel werden hauptsächlich einige bessere Open-Source- und kostenlose Bildanmerkungstools empfohlen. 1.Makesens
 Zehn empfohlene Open-Source-Tools für kostenlose Textanmerkungen
Mar 26, 2024 pm 08:20 PM
Zehn empfohlene Open-Source-Tools für kostenlose Textanmerkungen
Mar 26, 2024 pm 08:20 PM
Bei der Textanmerkung handelt es sich um die Arbeit mit entsprechenden Beschriftungen oder Tags für bestimmte Inhalte im Text. Sein Hauptzweck besteht darin, zusätzliche Informationen zum Text für eine tiefere Analyse und Verarbeitung bereitzustellen, insbesondere im Bereich der künstlichen Intelligenz. Textanmerkungen sind für überwachte maschinelle Lernaufgaben in Anwendungen der künstlichen Intelligenz von entscheidender Bedeutung. Es wird zum Trainieren von KI-Modellen verwendet, um Textinformationen in natürlicher Sprache genauer zu verstehen und die Leistung von Aufgaben wie Textklassifizierung, Stimmungsanalyse und Sprachübersetzung zu verbessern. Durch Textanmerkungen können wir KI-Modellen beibringen, Entitäten im Text zu erkennen, den Kontext zu verstehen und genaue Vorhersagen zu treffen, wenn neue ähnliche Daten auftauchen. In diesem Artikel werden hauptsächlich einige bessere Open-Source-Textanmerkungstools empfohlen. 1.LabelStudiohttps://github.com/Hu
 Was tun, wenn der Bluescreen-Code 0x0000001 auftritt?
Feb 23, 2024 am 08:09 AM
Was tun, wenn der Bluescreen-Code 0x0000001 auftritt?
Feb 23, 2024 am 08:09 AM
Was tun mit dem Bluescreen-Code 0x0000001? Der Bluescreen-Fehler ist ein Warnmechanismus, wenn ein Problem mit dem Computersystem oder der Hardware vorliegt. Der Code 0x0000001 weist normalerweise auf einen Hardware- oder Treiberfehler hin. Wenn Benutzer bei der Verwendung ihres Computers plötzlich auf einen Bluescreen-Fehler stoßen, geraten sie möglicherweise in Panik und sind ratlos. Glücklicherweise können die meisten Bluescreen-Fehler mit ein paar einfachen Schritten behoben werden. In diesem Artikel werden den Lesern einige Methoden zur Behebung des Bluescreen-Fehlercodes 0x0000001 vorgestellt. Wenn ein Bluescreen-Fehler auftritt, können wir zunächst versuchen, neu zu starten
 Beheben Sie den Fehlercode 0xc000007b
Feb 18, 2024 pm 07:34 PM
Beheben Sie den Fehlercode 0xc000007b
Feb 18, 2024 pm 07:34 PM
Beendigungscode 0xc000007b Bei der Verwendung Ihres Computers treten manchmal verschiedene Probleme und Fehlercodes auf. Unter ihnen ist der Beendigungscode am störendsten, insbesondere der Beendigungscode 0xc000007b. Dieser Code weist darauf hin, dass eine Anwendung nicht ordnungsgemäß gestartet werden kann, was zu Unannehmlichkeiten für den Benutzer führt. Lassen Sie uns zunächst die Bedeutung des Beendigungscodes 0xc000007b verstehen. Bei diesem Code handelt es sich um einen Fehlercode des Windows-Betriebssystems, der normalerweise auftritt, wenn eine 32-Bit-Anwendung versucht, auf einem 64-Bit-Betriebssystem ausgeführt zu werden. Es bedeutet, dass es so sein sollte
 Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Die Technologie zur Gesichtserkennung und -erkennung ist bereits eine relativ ausgereifte und weit verbreitete Technologie. Derzeit ist JS die am weitesten verbreitete Internetanwendungssprache. Die Implementierung der Gesichtserkennung und -erkennung im Web-Frontend hat im Vergleich zur Back-End-Gesichtserkennung Vor- und Nachteile. Zu den Vorteilen gehören die Reduzierung der Netzwerkinteraktion und die Echtzeiterkennung, was die Wartezeit des Benutzers erheblich verkürzt und das Benutzererlebnis verbessert. Die Nachteile sind: Es ist durch die Größe des Modells begrenzt und auch die Genauigkeit ist begrenzt. Wie implementiert man mit js die Gesichtserkennung im Web? Um die Gesichtserkennung im Web zu implementieren, müssen Sie mit verwandten Programmiersprachen und -technologien wie JavaScript, HTML, CSS, WebRTC usw. vertraut sein. Gleichzeitig müssen Sie auch relevante Technologien für Computer Vision und künstliche Intelligenz beherrschen. Dies ist aufgrund des Designs der Webseite erwähnenswert
 Universal-Fernbedienungscode-Programm von GE auf jedem Gerät
Mar 02, 2024 pm 01:58 PM
Universal-Fernbedienungscode-Programm von GE auf jedem Gerät
Mar 02, 2024 pm 01:58 PM
Wenn Sie ein Gerät aus der Ferne programmieren müssen, hilft Ihnen dieser Artikel. Wir teilen Ihnen die besten Universal-Fernbedienungscodes von GE für die Programmierung aller Geräte mit. Was ist eine GE-Fernbedienung? GEUniversalRemote ist eine Fernbedienung, mit der mehrere Geräte wie Smart-TVs, LG, Vizio, Sony, Blu-ray, DVD, DVR, Roku, AppleTV, Streaming-Media-Player und mehr gesteuert werden können. GEUniversal-Fernbedienungen gibt es in verschiedenen Modellen mit unterschiedlichen Merkmalen und Funktionen. GEUniversalRemote kann bis zu vier Geräte steuern. Top-Universalfernbedienungscodes zum Programmieren auf jedem Gerät GE-Fernbedienungen werden mit einer Reihe von Codes geliefert, die es ihnen ermöglichen, mit verschiedenen Geräten zu arbeiten. Sie können
 Gerade erschienen! Ein Open-Source-Modell zum Generieren von Bildern im Anime-Stil mit einem Klick
Apr 08, 2024 pm 06:01 PM
Gerade erschienen! Ein Open-Source-Modell zum Generieren von Bildern im Anime-Stil mit einem Klick
Apr 08, 2024 pm 06:01 PM
Lassen Sie mich Ihnen das neueste AIGC-Open-Source-Projekt vorstellen – AnimagineXL3.1. Dieses Projekt ist die neueste Version des Text-zu-Bild-Modells mit Anime-Thema und zielt darauf ab, Benutzern ein optimiertes und leistungsfähigeres Erlebnis bei der Generierung von Anime-Bildern zu bieten. Bei AnimagineXL3.1 konzentrierte sich das Entwicklungsteam auf die Optimierung mehrerer Schlüsselaspekte, um sicherzustellen, dass das Modell neue Höhen in Bezug auf Leistung und Funktionalität erreicht. Zunächst erweiterten sie die Trainingsdaten, um nicht nur Spielcharakterdaten aus früheren Versionen, sondern auch Daten aus vielen anderen bekannten Anime-Serien in das Trainingsset aufzunehmen. Dieser Schritt erweitert die Wissensbasis des Modells und ermöglicht ihm ein umfassenderes Verständnis verschiedener Anime-Stile und Charaktere. AnimagineXL3.1 führt eine neue Reihe spezieller Tags und Ästhetiken ein
 Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Neues SOTA für multimodale Dokumentverständnisfunktionen! Das Alibaba mPLUG-Team hat die neueste Open-Source-Arbeit mPLUG-DocOwl1.5 veröffentlicht, die eine Reihe von Lösungen zur Bewältigung der vier großen Herausforderungen der hochauflösenden Bildtexterkennung, des allgemeinen Verständnisses der Dokumentstruktur, der Befolgung von Anweisungen und der Einführung externen Wissens vorschlägt. Schauen wir uns ohne weitere Umschweife zunächst die Auswirkungen an. Ein-Klick-Erkennung und Konvertierung von Diagrammen mit komplexen Strukturen in das Markdown-Format: Es stehen Diagramme verschiedener Stile zur Verfügung: Auch eine detailliertere Texterkennung und -positionierung ist einfach zu handhaben: Auch ausführliche Erläuterungen zum Dokumentverständnis können gegeben werden: Sie wissen schon, „Document Understanding“. " ist derzeit ein wichtiges Szenario für die Implementierung großer Sprachmodelle. Es gibt viele Produkte auf dem Markt, die das Lesen von Dokumenten unterstützen. Einige von ihnen verwenden hauptsächlich OCR-Systeme zur Texterkennung und arbeiten mit LLM zur Textverarbeitung zusammen.
