
 Web-Frontend
js-Tutorial
jquery implementiert den Code „sharing_jquery' für Overlay-3D-Texteffekte
Web-Frontend
js-Tutorial
jquery implementiert den Code „sharing_jquery' für Overlay-3D-Texteffekte
jquery implementiert den Code „sharing_jquery' für Overlay-3D-Texteffekte

Jquery implementiert Overlay-3D-Texteffekte und der Implementierungscode ist auch sehr einfach. Er verwendet keine HTML5- und CSS3-Elemente und wird ausschließlich mit Jquery-Code implementiert.
Operationsrendering: --------------Effektdemonstration----- -- ----------

Der für Sie freigegebene JQuery-Implementierungscode zum Überlagern von 3D-Texteffekten lautet wie folgt
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>jquery实现叠层3D文字特效</title>
<style type="text/css">
*{margin:0px; padding:0px;}
body{background:#FFF;}
.box{height:160px; width:800px; position:absolute; top:50%; left:50%; margin:-90px 0 0 -320px;}
p{color:#7a9c07; font-size:160px; position:absolute; top:0px; left:0px;letter-spacing:10px; cursor:pointer;}
</style>
<script src="js/jquery-1.7.2.min.js" type="text/javascript"></script>
<script type="text/javascript">
function move(){
var i;
var a=0;
for(i=$(".box p").size();i>0;i--){
a=a+1;
$(".box p").eq(i).css({left:a*1,top:a*(-1),opacity:i*0.02});
$(".box p").eq(i).animate({left:a*(-1),top:a*(-1),opacity:i*0.02},3000);
$(".box").animate({"margin-left":"-350px"},3000);
$(".box p").eq(i).animate({left:a*1,top:a*(-1),opacity:i*0.02},3000);
$(".box").animate({"margin-left":"-290px"},3000);
};
};
$(document).ready(function(){
var p=0;
for(p=0;p<5;p++)
{
$(".box").append($(".box p").clone());
};
move();
setInterval(move,6100);
$(".box p").click(function(){
$(".box p").text("叠层3D文字").css({"font-size":"110px"});
$(".box").css({"margin-top":"-50px"});
});
});
</script>
</head>
<body>
<div class="box">
<p>脚本之家</p>
</div>
</body>
</html>
Das Obige ist der mit Ihnen geteilte JQuery-Code zum Implementieren von Overlay-3D-Text-Spezialeffekten.

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1392
1392
 52
52

 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Projektlink vorne geschrieben: https://nianticlabs.github.io/mickey/ Anhand zweier Bilder kann die Kameraposition zwischen ihnen geschätzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere geschätzten Posen sind maßstabsunabhängig. Einige Anwendungen, wie z. B. Instant Augmented Reality jederzeit und überall, erfordern eine Posenschätzung von Skalenmetriken und sind daher auf externe Tiefenschätzer angewiesen, um die Skalierung wiederherzustellen. In diesem Artikel wird MicKey vorgeschlagen, ein Keypoint-Matching-Prozess, mit dem metrische Korrespondenzen im 3D-Kameraraum vorhergesagt werden können. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern können wir auf metrische Relativwerte schließen
 LLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version)
May 09, 2024 pm 04:55 PM
LLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version)
May 09, 2024 pm 04:55 PM
Oben geschrieben und persönliches Verständnis des Autors: Dieses Papier widmet sich der Lösung der wichtigsten Herausforderungen aktueller multimodaler großer Sprachmodelle (MLLMs) in autonomen Fahranwendungen, nämlich dem Problem der Erweiterung von MLLMs vom 2D-Verständnis auf den 3D-Raum. Diese Erweiterung ist besonders wichtig, da autonome Fahrzeuge (AVs) genaue Entscheidungen über 3D-Umgebungen treffen müssen. Das räumliche 3D-Verständnis ist für AVs von entscheidender Bedeutung, da es sich direkt auf die Fähigkeit des Fahrzeugs auswirkt, fundierte Entscheidungen zu treffen, zukünftige Zustände vorherzusagen und sicher mit der Umgebung zu interagieren. Aktuelle multimodale große Sprachmodelle (wie LLaVA-1.5) können häufig nur Bildeingaben mit niedrigerer Auflösung verarbeiten (z. B. aufgrund von Auflösungsbeschränkungen des visuellen Encoders und Einschränkungen der LLM-Sequenzlänge). Allerdings erfordern autonome Fahranwendungen
 Wie verwende ich die PUT-Anfragemethode in jQuery?
Feb 28, 2024 pm 03:12 PM
Wie verwende ich die PUT-Anfragemethode in jQuery?
Feb 28, 2024 pm 03:12 PM
Wie verwende ich die PUT-Anfragemethode in jQuery? In jQuery ähnelt die Methode zum Senden einer PUT-Anfrage dem Senden anderer Arten von Anfragen, Sie müssen jedoch auf einige Details und Parametereinstellungen achten. PUT-Anfragen werden normalerweise zum Aktualisieren von Ressourcen verwendet, beispielsweise zum Aktualisieren von Daten in einer Datenbank oder zum Aktualisieren von Dateien auf dem Server. Das Folgende ist ein spezifisches Codebeispiel, das die PUT-Anforderungsmethode in jQuery verwendet. Stellen Sie zunächst sicher, dass Sie die jQuery-Bibliotheksdatei einschließen. Anschließend können Sie eine PUT-Anfrage senden über: $.ajax({u
 Die Registrierung von Punktwolken ist für die 3D-Vision unumgänglich! Verstehen Sie alle gängigen Lösungen und Herausforderungen in einem Artikel
Apr 02, 2024 am 11:31 AM
Die Registrierung von Punktwolken ist für die 3D-Vision unumgänglich! Verstehen Sie alle gängigen Lösungen und Herausforderungen in einem Artikel
Apr 02, 2024 am 11:31 AM
Es wird erwartet, dass die Punktwolke als Sammlung von Punkten eine Veränderung bei der Erfassung und Generierung dreidimensionaler (3D) Oberflächeninformationen von Objekten durch 3D-Rekonstruktion, industrielle Inspektion und Roboterbetrieb bewirken wird. Der anspruchsvollste, aber wesentlichste Prozess ist die Punktwolkenregistrierung, d. h. das Erhalten einer räumlichen Transformation, die zwei in zwei verschiedenen Koordinaten erhaltene Punktwolken ausrichtet und abgleicht. In dieser Rezension werden ein Überblick und die Grundprinzipien der Punktwolkenregistrierung vorgestellt, verschiedene Methoden systematisch klassifiziert und verglichen und die technischen Probleme bei der Punktwolkenregistrierung gelöst. Dabei wird versucht, akademischen Forschern außerhalb des Fachgebiets und Ingenieuren Orientierung zu geben und Diskussionen über eine einheitliche Vision zu erleichtern zur Punktwolkenregistrierung. Die allgemeine Methode zur Punktwolkenerfassung ist in aktive und passive Methoden unterteilt. Die vom Sensor aktiv erfasste Punktwolke ist die aktive Methode, und die Punktwolke wird später rekonstruiert.
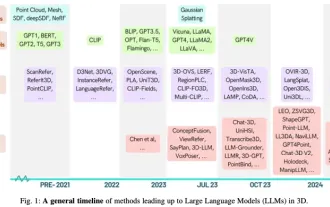 Das Neueste von der Universität Oxford |. Fast 400 Zusammenfassungen! Sprechen Sie über die neueste Überprüfung großer Sprachmodelle und der dreidimensionalen Welt
Jun 02, 2024 pm 07:41 PM
Das Neueste von der Universität Oxford |. Fast 400 Zusammenfassungen! Sprechen Sie über die neueste Überprüfung großer Sprachmodelle und der dreidimensionalen Welt
Jun 02, 2024 pm 07:41 PM
Oben geschrieben und persönliches Verständnis des Autors: Mit der Entwicklung großer Sprachmodelle (LLM) wurden schnelle Fortschritte bei der Integration zwischen ihnen und 3D-Geodaten (3DLLM) erzielt, was beispiellose Möglichkeiten zum Verständnis und zur Interaktion mit dem physischen Raum bietet. Dieser Artikel bietet einen umfassenden Überblick über den LLM-Ansatz zur Verarbeitung, zum Verständnis und zur Generierung von 3D-Daten. Wir heben die einzigartigen Vorteile von LLMs hervor, wie kontextuelles Lernen, schrittweises Denken, offene Vokabelfähigkeiten und umfassendes Weltwissen, und betonen ihr Potenzial, das räumliche Verständnis und die Interaktion mit eingebetteten Systemen der künstlichen Intelligenz (KI) zu fördern. Unsere Forschung umfasst verschiedene 3D-Datendarstellungen von Punktwolken bis hin zu Neural Rendering Fields (NeRF). und analysierten ihre Integration mit LLM für 3D-Szenenverständnis, Untertitel,
 Wie entferne ich das Höhenattribut eines Elements mit jQuery?
Feb 28, 2024 am 08:39 AM
Wie entferne ich das Höhenattribut eines Elements mit jQuery?
Feb 28, 2024 am 08:39 AM
Wie entferne ich das Höhenattribut eines Elements mit jQuery? Bei der Front-End-Entwicklung müssen wir häufig die Höhenattribute von Elementen manipulieren. Manchmal müssen wir möglicherweise die Höhe eines Elements dynamisch ändern, und manchmal müssen wir das Höhenattribut eines Elements entfernen. In diesem Artikel wird erläutert, wie Sie mit jQuery das Höhenattribut eines Elements entfernen, und es werden spezifische Codebeispiele bereitgestellt. Bevor wir jQuery zum Betreiben des Höhenattributs verwenden, müssen wir zunächst das Höhenattribut in CSS verstehen. Das Höhenattribut wird verwendet, um die Höhe eines Elements festzulegen
 jQuery-Tipps: Ändern Sie schnell den Text aller a-Tags auf der Seite
Feb 28, 2024 pm 09:06 PM
jQuery-Tipps: Ändern Sie schnell den Text aller a-Tags auf der Seite
Feb 28, 2024 pm 09:06 PM
Titel: jQuery-Tipps: Ändern Sie schnell den Text aller Tags auf der Seite. In der Webentwicklung müssen wir häufig Elemente auf der Seite ändern und bedienen. Wenn Sie jQuery verwenden, müssen Sie manchmal den Textinhalt aller a-Tags auf der Seite gleichzeitig ändern, was Zeit und Energie sparen kann. Im Folgenden wird erläutert, wie Sie mit jQuery den Text aller Tags auf der Seite schnell ändern können, und es werden spezifische Codebeispiele angegeben. Zuerst müssen wir die jQuery-Bibliotheksdatei einführen und sicherstellen, dass der folgende Code in die Seite eingefügt wird: <
