

AI Large Base, die Antwort auf die Ära der großen Modelle

1. Die Geburt von Wen Aufgaben: Baidu Intelligent Cloud begann mit der Planung des Aufbaus eines neuen Hochleistungs-GPU-Clusters. Gemeinsam mit NVIDIA wurde der Entwurf einer IB-Netzwerkarchitektur abgeschlossen, die mehr als 10.000 Karten unterbringen kann, die zwischen Knoten im Cluster verbunden sind über das IB-Netzwerk, und der Clusterbau wird im April 2022 abgeschlossen sein und Einzelcluster-Rechenleistung auf EFLOPS-Ebene bereitstellen.
Im März 2023 wurde Wen Xinyiyan in diesem Hochleistungscluster geboren und entwickelt weiterhin neue Funktionen. Derzeit wächst die Größe dieses Clusters noch.
Dr. Junjie Lai, General Manager of Solutions and Engineering bei NVIDIA China: GPU-Cluster, die durch Hochgeschwindigkeits-IB-Netzwerke miteinander verbunden sind, sind eine Schlüsselinfrastruktur im Zeitalter großer Modelle. Der größte Hochleistungs-GPU/IB-Cluster auf dem heimischen Cloud-Computing-Markt, der gemeinsam von NVIDIA und Baidu Intelligent Cloud aufgebaut wurde, wird Baidus größeren Durchbruch im Bereich großer Modelle beschleunigen.
2. Hochleistungs-Cluster-Design
Hochleistungs-Cluster ist keine einfache Anhäufung von Rechenleistung. Es erfordert auch ein spezielles Design und eine Optimierung, um die Gesamtrechenleistung des Clusters hervorzuheben.
Beim verteilten Training kommunizieren GPUs kontinuierlich zwischen und innerhalb von Maschinen. Während Hochleistungsnetzwerke wie IB und RoCE zur Bereitstellung von Diensten mit hohem Durchsatz und geringer Latenz für die Kommunikation zwischen Maschinen verwendet werden, ist es auch erforderlich, die internen Netzwerkverbindungen der Server und die Kommunikationstopologie im Clusternetzwerk speziell zu gestalten Erfüllen Sie die Kommunikationsanforderungen großer Modellschulungen.
Um die ultimative Designoptimierung zu erreichen, ist ein tiefes Verständnis dafür erforderlich, was jeder Vorgang in der KI-Aufgabe für die Infrastruktur bedeutet. Unterschiedliche parallele Strategien beim verteilten Training, d. h. die Art und Weise, wie Modelle, Daten und Parameter aufgeteilt werden, führen zu unterschiedlichen Anforderungen an die Datenkommunikation. Beispielsweise führen Datenparallelität und Modellparallelität zu einer großen Anzahl von Allreduce-Operationen innerhalb und zwischen Maschinen bzw. Expertenparallelität wird All2All-Operationen zwischen Maschinen erzeugen, 4D-Hybridparallelität wird Kommunikationsoperationen einführen, die durch verschiedene parallele Strategien generiert werden.
Zu diesem Zweck optimiert Baidu Smart Cloud das Design sowohl von eigenständigen Servern als auch von Cluster-Netzwerken, um leistungsstarke GPU-Cluster aufzubauen.
In Bezug auf eigenständige Server hat sich der Super-KI-Computer X-MAN von Baidu Smart Cloud mittlerweile zur vierten Generation weiterentwickelt. X-MAN 4.0 stellt eine leistungsstarke Kommunikation zwischen den Karten für GPUs her und bietet 134 GB/s Allreduce-Bandbreite innerhalb einer einzelnen Maschine. Dies ist derzeit Baidus Serverprodukt mit dem höchsten Grad an Individualisierung und den spezialisiertesten Materialien. In der MLCommons 1.1-Liste belegt X-MAN 4.0 Platz 2 bei der Leistung eigenständiger Hardware mit derselben Konfiguration.
In Bezug auf das Cluster-Netzwerk ist eine dreischichtige Clos-Architektur, die für das Training großer Modelle optimiert ist, speziell darauf ausgelegt, die Leistung und Beschleunigung des Clusters während des Trainings in großem Maßstab sicherzustellen. Im Vergleich zur herkömmlichen Methode wurde diese Architektur mit acht Schienen optimiert, um die Anzahl der Hops in der Kommunikation zwischen beliebigen Karten mit derselben Nummer in verschiedenen Maschinen zu minimieren und den Allreduce-Betrieb derselben Karte mit dem größten Anteil zu unterstützen Netzwerkverkehr im KI-Training. Netzwerkdienste mit hohem Durchsatz und geringer Latenz.
Diese Netzwerkarchitektur kann extrem große Cluster mit maximal 16.000 Karten unterstützen. Dieser Maßstab ist der größte Maßstab aller IB-Netzwerkbox-Netzwerke in dieser Phase. Die Netzwerkleistung des Clusters ist stabil und konstant auf einem Niveau von 98 %, was einem Zustand stabiler Kommunikation nahe kommt. Nach Überprüfung durch das Team für große Modellalgorithmen wurden auf diesem extrem großen Cluster Hunderte Milliarden Modelltrainingsjobs übermittelt, und die Gesamttrainingseffizienz bei gleicher Maschinengröße betrug das 3,87-fache der Cluster der vorherigen Generation.
Der Aufbau großer, leistungsstarker heterogener Cluster ist jedoch nur der erste Schritt zur erfolgreichen Implementierung großer Modelle. Um den erfolgreichen Abschluss groß angelegter KI-Modell-Trainingsaufgaben sicherzustellen, ist eine systematischere Optimierung von Software und Hardware erforderlich.
3. Herausforderungen beim Training großer Modelle
In den letzten Jahren wird die Parametergröße großer Modelle jedes Jahr um das Zehnfache zunehmen. Um das Jahr 2020 herum wird ein Modell mit Hunderten Milliarden Parametern als großes Modell gelten. Im Jahr 2022 werden bereits Hunderte Milliarden Parameter erforderlich sein, um als großes Modell bezeichnet zu werden.
Vor großen Modellen reichte das Training eines KI-Modells normalerweise mit einer einzigen Karte auf einer einzelnen Maschine oder mehreren Karten auf einer einzigen Maschine aus. Der Trainingszyklus reichte von Stunden bis zu Tagen. Um nun das Training großer Modelle mit Hunderten von Milliarden Parametern abzuschließen, ist ein verteiltes Training in großen Clustern mit Hunderten von Servern und Tausenden von GPU/XPU-Karten ein Muss geworden, und der Trainingszyklus wurde ebenfalls auf Monate verlängert.
Um GPT-3 mit 175 Milliarden Parametern (300 Milliarden Token-Daten) zu trainieren, dauert 1 Block A100 32 Jahre, basierend auf der Berechnung der Spitzenleistung mit halber Genauigkeit, und 1024 Blöcke A100 dauert 34 Tage, basierend auf einer Ressourcenauslastung von 45 %. Selbst wenn die Zeit nicht berücksichtigt wird, kann ein A100 natürlich kein Modell mit einer Parameterskala von 100 Milliarden trainieren, da die Modellparameter die Speicherkapazität einer einzelnen Karte überschritten haben.
Bei der Durchführung eines großen Modelltrainings in einer verteilten Trainingsumgebung verkürzt sich der Trainingszyklus für eine einzelne Karte von Jahrzehnten auf Dutzende von Tagen. Sie muss verschiedene Herausforderungen wie Computerwände, Videospeicherwände und Kommunikationswände überwinden , sodass alle Benutzer im Cluster die Ressourcen vollständig nutzen können, was den Trainingsprozess beschleunigt und den Trainingszyklus verkürzt.
Die Rechenwand bezieht sich auf den großen Unterschied zwischen der Rechenleistung einer einzelnen Karte und der Gesamtrechenleistung des Modells. Der A100 verfügt über eine Rechenleistung einer einzelnen Karte von nur 312 TFLOPS, während GPT-3 eine Gesamtrechenleistung von 314 ZFLOPs benötigt, ein Unterschied von 9 Größenordnungen.
Die Speicherwand bezieht sich auf die Tatsache, dass eine einzelne Karte die Parameter eines großen Modells nicht vollständig speichern kann. Allein die 175 Milliarden Parameter von GPT-3 erfordern 700 GB Videospeicher (jeder Parameter wird als 4 Byte berechnet), während die NVIDIA A100-GPU nur über 80 GB Videospeicher verfügt.
Das Wesen der Computerwand und der Videospeicherwand ist der Widerspruch zwischen der begrenzten Einzelkartenkapazität und den enormen Speicher- und Rechenanforderungen des Modells. Dies kann durch verteiltes Training gelöst werden, aber nach verteiltem Training werden Sie auf das Problem der Kommunikationswand stoßen.
Kommunikationswand, hauptsächlich weil jede Recheneinheit im Cluster beim verteilten Training eine häufige Parametersynchronisation benötigt und die Kommunikationsleistung die Gesamtrechengeschwindigkeit beeinflusst. Wenn die Kommunikationswand nicht gut gehandhabt wird, ist es wahrscheinlich, dass der Cluster größer wird und die Trainingseffizienz abnimmt. Das erfolgreiche Durchbrechen der Kommunikationsmauer spiegelt sich in der starken Skalierbarkeit des Clusters wider, das heißt, die Multi-Card-Beschleunigungsfähigkeit des Clusters entspricht der Skalierung. Das lineare Beschleunigungsverhältnis mehrerer Karten ist ein Indikator zur Bewertung der Beschleunigungsfähigkeiten mehrerer Karten in einem Cluster. Je höher der Wert, desto besser.
Diese Wände tauchten im Training mehrerer Maschinen und Karten auf. Wenn die Parameter des großen Modells immer größer werden, wird auch die entsprechende Clustergröße immer größer und diese drei Wände werden immer höher. Gleichzeitig kann es beim Langzeittraining großer Cluster zu Geräteausfällen kommen, die den Trainingsprozess beeinträchtigen oder unterbrechen können.
4. Der Prozess des Trainings großer Modelle
Wenn man das Training großer Modelle aus Infrastruktursicht betrachtet, kann der gesamte Prozess grob in die folgenden zwei Phasen unterteilt werden:
Phase Eins: Parallele Strategie- und Trainingsoptimierung
Nachdem das große Modell zum Trainieren eingereicht wurde, berücksichtigt das KI-Framework umfassend die Struktur und andere Informationen des großen Modells , sowie die Fähigkeit des Trainingsclusters, für diese Trainingsaufgaben eine parallele Trainingsstrategie zu formulieren und die Platzierung der KI-Aufgaben abzuschließen. Dieser Prozess besteht darin, das Modell zu zerlegen und die Aufgabe zu platzieren, das heißt, wie das große Modell zerlegt wird und wie die zerlegten Teile in jeder GPU/XPU des Clusters platziert werden.
Für KI-Aufgaben, die auf der GPU/XPU ausgeführt werden sollen, trainiert das KI-Framework den Cluster gemeinsam, um eine vollständige Link-Optimierung auf der Einzelkarten-Laufzeit- und Cluster-Kommunikationsebene durchzuführen und so jede KI zu beschleunigen Aufgabe im Trainingsprozess für große Modelle. Betriebseffizienz, einschließlich Datenladen, Bedienerberechnung, Kommunikationsstrategie usw. Beispielsweise werden gewöhnliche Operatoren, die KI-Aufgaben ausführen, durch optimierte Hochleistungsoperatoren ersetzt und Kommunikationsstrategien bereitgestellt, die sich an die aktuelle Parallelstrategie anpassen, und die Netzwerkfunktionen des Trainingsclusters trainieren.
Phase 2: Ressourcenmanagement und Aufgabenplanung
Die große Modelltrainingsaufgabe beginnt gemäß der oben formulierten Parallelstrategie zu laufen, und der Trainingscluster stellt verschiedene Hochleistungsressourcen für bereit KI-Aufgaben. In welcher Umgebung wird beispielsweise die KI-Aufgabe ausgeführt, wie wird das Andocken von Ressourcen für die KI-Aufgabe bereitgestellt, welche Speichermethode verwendet die KI-Aufgabe zum Lesen und Speichern von Daten, welche Art von Netzwerkeinrichtungen verfügt die GPU? /XPU kommuniziert über usw.
Gleichzeitig wird der Trainingscluster während des Betriebsprozesses mit dem KI-Framework kombiniert, um durch elastische Fehlertoleranz und andere Methoden eine zuverlässige Umgebung für das langfristige Training großer Modelle bereitzustellen. Zum Beispiel, wie man den Betriebsstatus verschiedener Ressourcen und KI-Aufgaben im Cluster beobachtet und wahrnimmt usw. und wie man Ressourcen und KI-Aufgaben plant, wenn sich der Cluster ändert usw.
Aus der Zerlegung der beiden oben genannten Phasen können wir feststellen, dass der gesamte Trainingsprozess großer Modelle auf der engen Zusammenarbeit des KI-Frameworks und des Trainingsclusters beruht, um den Durchbruch der drei Wände zu vollenden und stellen Sie gemeinsam sicher, dass das groß angelegte Modelltraining effizient und stabil ist.
5. Full-Stack-Integration, „AI Big Base“ beschleunigt das Training großer Modelle
Kombiniert mit jahrelanger Technologieakkumulation und Ingenieurspraxis in den Bereichen KI und große Modelle, Baidu wird eine selbstentwickelte Full-Stack-KI-Infrastruktur „AI Big Base“ auf den Markt bringen, die einen dreischichtigen Technologiestapel aus „Chip – Framework – Modell“ umfasst. Sie verfügt über wichtige selbstentwickelte Technologien und führende Produkte auf allen Ebenen Kunlun Core und Fei Paddle (PaddlePaddle), Wenxin großes Modell.
Basierend auf diesen drei Schichten des Technologie-Stacks hat Baidu Intelligent Cloud zwei große KI-Engineering-Plattformen eingeführt, „AI Middle Platform“ und „Baidu Baige·AI Heterogeneous Computing Platform“, die sich jeweils in der Entwicklung befinden. Verbessern Sie die Effizienz auf Ressourcenebene, durchbrechen Sie die drei Mauern und beschleunigen Sie den Schulungsprozess.
Unter diesen basiert die „KI-Mittelplattform“ auf dem KI-Framework, um parallele Strategien und optimierte Umgebungen für den Trainingsprozess großer Modelle zu entwickeln und den gesamten Trainingslebenszyklus abzudecken. „Baidu Baige“ realisiert eine effiziente Chip-Aktivierung und bietet die Verwaltung verschiedener KI-Ressourcen und Aufgabenplanungsfunktionen.
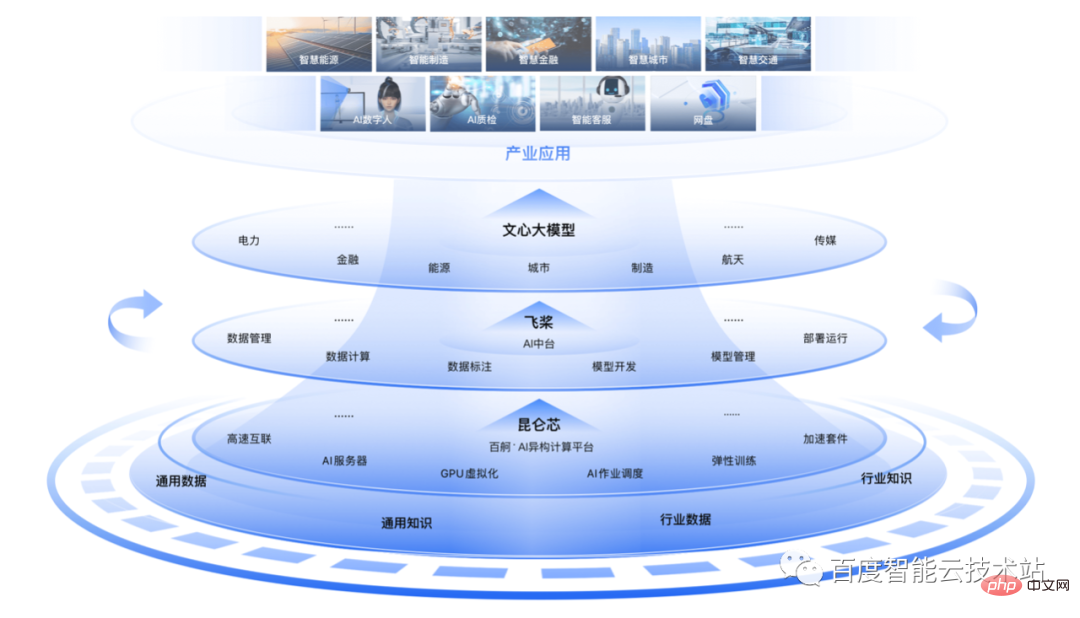
Baidus „AI Big Base“ hat eine vollständige Stack-Integration und Systemoptimierung des Technologie-Stacks auf jeder Ebene durchgeführt und damit abgeschlossen Cloud und Intelligenz Durch den integrierten Aufbau von Technologie kann eine durchgängige Optimierung und Beschleunigung des Trainings großer Modelle erreicht werden.
Hou Zhenyu, Vizepräsident der Baidu Group: Die Clustergröße, die Schulungszeit und die Kosten sind alle gestiegen viel im Vergleich zur Vergangenheit. Ohne Full-Stack-Optimierung wäre es schwierig, den erfolgreichen Abschluss eines großen Modelltrainings sicherzustellen. Baidus technische Investitionen und Engineering-Praktiken bei großen Modellen haben es uns im Laufe der Jahre ermöglicht, einen vollständigen Satz an Software-Stack-Funktionen zu etablieren, um das Training großer Modelle zu beschleunigen.
Als nächstes beschreiben wir jede Schicht des Technologie-Stacks der „AI Big Base“ basierend auf den beiden erwähnten Phasen des großen Modelltrainingsprozesses oben: Wie man sich gegenseitig integriert und das System optimiert, um eine durchgängige Optimierung und Beschleunigung des Trainings großer Modelle zu erreichen.
5.1 Parallele Strategie- und Trainingsoptimierung
Modellaufteilung
Flying Paddle kann Datenparallelität, Modellparallelität und Pipeline-Parallelität für das Training großer Modelle bereitstellen. Umfangreiche Parallelstrategien wie Parametergruppierung und -aufteilung, Expertenparallelität usw. Diese parallelen Strategien können den Anforderungen des Trainings großer Modelle mit Parametern im Bereich von einer Milliarde bis einhundert Milliarden oder sogar Billionen gerecht werden und Durchbrüche bei Computern und Videospeicherwänden erzielen. Im April 2021 war Feipiao der erste in der Branche, der eine 4D-Hybrid-Parallelstrategie vorschlug, die das Training von Hunderten Milliarden großen Modellen unterstützen kann, die auf monatlicher Ebene abgeschlossen werden müssen.
Topologiebewusstsein
Baidu Baige verfügt über Cluster-Topologiebewusstseinsfunktionen, die speziell für große Modelltrainingsszenarien vorbereitet sind, einschließlich Architekturbewusstsein innerhalb von Knoten, Architekturbewusstsein zwischen Knoten usw., wie z sowie Informationen wie die Rechenleistung innerhalb des Servers, CPU und GPU/XPU, GPU/XPU- und GPU/XPU-Verbindungsmethoden sowie GPU/XPU- und GPU/XPU-Netzwerkverbindungsmethoden zwischen Servern.
Automatische Parallelität
Bevor die große Modelltrainingsaufgabe ausgeführt wird, kann Fei Paddle basierend auf den Topologieerkennungsfunktionen der Baidu Baige-Plattform einen einheitlichen verteilten Ressourcengraphen für den Cluster erstellen. Gleichzeitig bildet das Flugpaddel eine einheitliche logische Berechnungsansicht basierend auf dem zu trainierenden großen Modell.
Basierend auf diesen beiden Bildern sucht Feipiao automatisch nach der optimalen Modellsegmentierungs- und Hardwarekombinationsstrategie für das Modell und weist Modellparameter, Verläufe und Optimiererstatus entsprechend der optimalen Strategie zu GPU/XPU, Vervollständigen Sie die Platzierung von KI-Aufgaben, um die Trainingsleistung zu verbessern.
Zum Beispiel die Platzierung modellparalleler KI-Aufgaben auf verschiedenen GPUs auf demselben Server, und diese GPUs werden über den NVSwitch innerhalb des Servers verbunden. Platzieren Sie datenparallele und Pipeline-parallele KI-Aufgaben auf gleich vielen GPUs auf verschiedenen Servern, und diese GPUs werden über IB oder RoCE verbunden. Durch diese Methode, KI-Aufgaben entsprechend der Art der KI-Aufgaben zu platzieren, können Clusterressourcen effizient genutzt und das Training großer Modelle beschleunigt werden.
End-to-End-adaptives Training
Wenn sich während der Ausführung der Trainingsaufgabe der Cluster ändert, z. B. ein Ressourcenausfall, oder sich die Clustergröße ändert, Baidu Baidu Ge führt einen fehlertoleranten Ersatz oder eine elastische Expansion und Kontraktion durch. Da sich die Standorte der an der Berechnung beteiligten Knoten geändert haben, ist der Kommunikationsmodus zwischen ihnen möglicherweise nicht mehr optimal. Flying Paddle kann die Modellsegmentierung und KI-Aufgabenplatzierungsstrategien basierend auf den neuesten Clusterinformationen automatisch anpassen. Gleichzeitig führt Baidu Baige die Planung entsprechender Aufgaben und Ressourcen durch.
Die einheitliche Ressourcen- und Rechenansicht und die automatischen Parallelfunktionen von Fei Paddle ermöglichen in Kombination mit den elastischen Planungsfunktionen von Baidu Baige ein durchgängiges adaptives verteiltes Training großer Modelle, das den gesamten Lebenszyklus des Cluster-Trainings abdecken kann.
Dies ist eine tiefgreifende Interaktion zwischen dem KI-Framework und der heterogenen KI-Rechenleistungsplattform. Es realisiert die Systemoptimierung der Dreifaltigkeit von Rechenleistung, Framework und Algorithmus und unterstützt die Automatisches und flexibles Training großer Modelle. Durch die 2,1-fache Leistungsverbesserung wird die Effizienz groß angelegter Schulungen sichergestellt.
Trainingsoptimierung
Nach Abschluss der Aufteilung des Modells und der Platzierung von KI-Aufgaben während des Trainingsprozesses, um sicherzustellen, dass der Bediener in verschiedenen Mainstream-Anwendungen eingesetzt werden kann KI-Frameworks wie Feipiao und Pytorch können auf verschiedenen Computerkarten beschleunigt werden, und die Baidu-Baige-Plattform verfügt über eine integrierte KI-Beschleunigungssuite. Die KI-Beschleunigungssuite umfasst die Speicherbeschleunigung der Datenschicht, die Trainings- und Inferenzbeschleunigungsbibliothek AIAK, die eine vollständige Linkoptimierung aus den Dimensionen Datenladen, Modellberechnung, verteilte Kommunikation und anderen Dimensionen durchführt.
Unter anderem kann die Optimierung des Datenladens und der Modellberechnung die Betriebseffizienz einer einzelnen Karte effektiv verbessern, kombiniert mit Hochleistungsnetzwerken wie Clustered IB oder RoCE und einer speziell optimierten Kommunikationstopologie. sowie sinnvolle KI-Aufgaben. Legen Sie Strategien zur gemeinsamen Lösung von Kommunikationswandproblemen fest.
Das Multi-Card-Beschleunigungsverhältnis von Baidu Baige in einem Kilocard-Cluster hat 90 % erreicht, sodass die gesamte Rechenleistung des Clusters vollständig freigegeben werden kann.
In den im November 2022 veröffentlichten Testergebnissen von MLPerf Training v2.1 belegten die von Baidu mit Fei Paddle plus Baidu Baige eingereichten Modelltrainingsleistungsergebnisse unter derselben GPU-Konfiguration den ersten Platz weltweit Die Trainingszeit und der Trainingsdurchsatz übertreffen das NGC PyTorch-Framework.
5.2 Ressourcenmanagement und Aufgabenplanung
Ressourcenmanagement
Baidu Baige kann verschiedene Computer-, Netzwerk-, Speicher- und andere KI-Ressourcen bereitstellen, darunter der elastische Bare-Metal-Server BBC von Baidu Taihang, das IB-Netzwerk, das RoCE-Netzwerk und verschiedene Clouds Rechenressourcen, die für das Training großer Modelle geeignet sind, wie z. B. paralleler Dateispeicher PFS, Objektspeicher BOS und Data-Lake-Speicherbeschleunigung RapidFS.
Wenn eine Aufgabe ausgeführt wird, können diese Hochleistungsressourcen sinnvoll kombiniert werden, um die Effizienz von KI-Operationen weiter zu verbessern und eine Rechenbeschleunigung von KI-Aufgaben während des gesamten Prozesses zu realisieren. Bevor die KI-Aufgabe beginnt, können die Trainingsdaten im Objektspeicher BOS aufgewärmt werden und die Daten können über das elastische RDMA-Netzwerk in den Data Lake Storage Acceleration RapidFS geladen werden. Das elastische RDMA-Netzwerk kann die Kommunikationslatenz im Vergleich zu herkömmlichen Netzwerken um das Zwei- bis Dreifache reduzieren und beschleunigt das Lesen von KI-Aufgabendaten basierend auf Hochleistungsspeicher. Schließlich werden KI-Aufgabenberechnungen über den leistungsstarken elastischen Bare-Metal-Server BBC von Baidu Taihang oder den Cloud-Server BCC durchgeführt.
Elastic Fault Tolerance
Wenn KI-Aufgaben ausgeführt werden, erfordern sie nicht nur Hochleistungsressourcen, sondern stellen auch die Stabilität des Clusters sicher und minimieren das Auftreten von Ressourcenausfällen Vermeiden Sie es, das Training zu unterbrechen. Allerdings können Ressourcenausfälle nicht absolut vermieden werden. Das KI-Framework und der Trainingscluster müssen gemeinsam sicherstellen, dass die Trainingsaufgabe nach einer Unterbrechung vom neuesten Stand wiederhergestellt werden kann, um so eine zuverlässige Umgebung für das langfristige Training großer Mengen bereitzustellen Modelle.
Baidus selbst entwickelte heterogene Sammlungsbibliothek ECCL unterstützt die Kommunikation zwischen Kunlun-Kernen und anderen heterogenen Chips und unterstützt die Wahrnehmung langsamer und fehlerhafter Knoten. Durch die Ressourcenelastizität und Fehlertoleranzstrategie von Baidu Baige werden langsame Knoten und fehlerhafte Knoten eliminiert, und die neueste Architekturtopologie wird an Feipiao zurückgemeldet, um Aufgaben neu anzuordnen und entsprechende Trainingsaufgaben anderen XPU/GPUs zuzuweisen, um einen reibungslosen Trainingsablauf zu gewährleisten effizient.
6. KI-Inklusivität im Zeitalter großer Modelle
Die gute Beherrschung großer Modelle ist der Schlüssel zur Vollendung Der intelligente Upgrade-Pfad Erforderliche Fragen. Ultragroße Rechenleistung und integrierte Full-Stack-Softwareoptimierung sind die besten Antworten auf diese Frage, die man unbedingt beantworten muss.
Um Gesellschaft und Industrie dabei zu unterstützen, schnell ihre eigenen großen Modelle zu trainieren und die Chancen der Zeit zu nutzen, veröffentlichte Baidu Intelligent Cloud Ende 2022 das Yangquan Intelligent Computing Center, ausgestattet mit dem Full-Stack Fähigkeiten von Baidus „AI Big Base“. Es kann 4 EFLOPS heterogene Rechenleistung bereitstellen. Dies ist derzeit das größte und technologisch fortschrittlichste Rechenzentrum in Asien.
Derzeit hat Baidu Smart Cloud alle Funktionen der „AI Big Base“ für die Außenwelt geöffnet und integrative KI im Zeitalter der großen Modelle durch die zentrale Cloud, Edge Cloud BEC usw. realisiert lokaler Computing-Cluster LCC in jeder Region, privater Cloud-ABC-Stack und andere Bereitstellungsformen, die es Gesellschaft und Industrie ermöglichen, problemlos intelligente Dienste zu erhalten.
Das obige ist der detaillierte Inhalt vonAI Large Base, die Antwort auf die Ära der großen Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So konfigurieren Sie das Debian Apache -Protokollformat
Apr 12, 2025 pm 11:30 PM
So konfigurieren Sie das Debian Apache -Protokollformat
Apr 12, 2025 pm 11:30 PM
In diesem Artikel wird beschrieben, wie das Protokollformat von Apache auf Debian -Systemen angepasst wird. Die folgenden Schritte führen Sie durch den Konfigurationsprozess: Schritt 1: Greifen Sie auf die Apache -Konfigurationsdatei zu. Die Haupt -Apache -Konfigurationsdatei des Debian -Systems befindet sich normalerweise in /etc/apache2/apache2.conf oder /etc/apache2/httpd.conf. Öffnen Sie die Konfigurationsdatei mit Root -Berechtigungen mit dem folgenden Befehl: Sudonano/etc/apache2/apache2.conf oder sudonano/etc/apache2/httpd.conf Schritt 2: Definieren Sie benutzerdefinierte Protokollformate, um zu finden oder zu finden oder
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 Wie Tomcat -Protokolle bei der Fehlerbehebung bei Speicherlecks helfen
Apr 12, 2025 pm 11:42 PM
Wie Tomcat -Protokolle bei der Fehlerbehebung bei Speicherlecks helfen
Apr 12, 2025 pm 11:42 PM
Tomcat -Protokolle sind der Schlüssel zur Diagnose von Speicherleckproblemen. Durch die Analyse von Tomcat -Protokollen können Sie Einblicke in das Verhalten des Speicherverbrauchs und des Müllsammlung (GC) erhalten und Speicherlecks effektiv lokalisieren und auflösen. Hier erfahren Sie, wie Sie Speicherlecks mit Tomcat -Protokollen beheben: 1. GC -Protokollanalyse zuerst aktivieren Sie eine detaillierte GC -Protokollierung. Fügen Sie den Tomcat-Startparametern die folgenden JVM-Optionen hinzu: -xx: printgCDetails-xx: printgCDatESTAMPS-XLOGGC: GC.Log Diese Parameter generieren ein detailliertes GC-Protokoll (GC.Log), einschließlich Informationen wie GC-Typ, Recycling-Objektgröße und Zeit. Analyse gc.log
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
In diesem Artikel wird beschrieben, wie Sie Firewall -Regeln mit Iptables oder UFW in Debian -Systemen konfigurieren und Syslog verwenden, um Firewall -Aktivitäten aufzuzeichnen. Methode 1: Verwenden Sie IptableSiptables ist ein leistungsstarkes Befehlszeilen -Firewall -Tool im Debian -System. Vorhandene Regeln anzeigen: Verwenden Sie den folgenden Befehl, um die aktuellen IPTables-Regeln anzuzeigen: Sudoiptables-L-N-V Ermöglicht spezifische IP-Zugriff: ZBELTE IP-Adresse 192.168.1.100 Zugriff auf Port 80: sudoiptables-ainput-ptcp--dort80-s192.16
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
