
 Technologie-Peripheriegeräte
KI
Neueste Forschung, GPT-4 deckt Mängel auf! Ich kann die sprachliche Mehrdeutigkeit nicht ganz verstehen!
Technologie-Peripheriegeräte
KI
Neueste Forschung, GPT-4 deckt Mängel auf! Ich kann die sprachliche Mehrdeutigkeit nicht ganz verstehen!
Neueste Forschung, GPT-4 deckt Mängel auf! Ich kann die sprachliche Mehrdeutigkeit nicht ganz verstehen!

Natural Language Inference (NLI) ist eine wichtige Aufgabe bei der Verarbeitung natürlicher Sprache. Ihr Ziel besteht darin, festzustellen, ob die Hypothese aus den Prämissen auf der Grundlage der gegebenen Prämissen und Annahmen abgeleitet werden kann. Da Mehrdeutigkeit jedoch ein wesentliches Merkmal natürlicher Sprache ist, ist der Umgang mit Mehrdeutigkeit auch ein wichtiger Teil des menschlichen Sprachverständnisses. Aufgrund der Vielfalt menschlicher Sprachausdrücke ist die Mehrdeutigkeitsverarbeitung zu einer der Schwierigkeiten bei der Lösung von Problemen beim logischen Denken in natürlicher Sprache geworden. Derzeit werden verschiedene Algorithmen zur Verarbeitung natürlicher Sprache in Szenarien wie Frage- und Antwortsystemen, Spracherkennung, intelligenter Übersetzung und Erzeugung natürlicher Sprache eingesetzt, aber selbst mit diesen Technologien ist die vollständige Auflösung von Mehrdeutigkeiten immer noch eine äußerst anspruchsvolle Aufgabe.
Bei NLI-Aufgaben stehen große Modelle zur Verarbeitung natürlicher Sprache wie GPT-4 vor Herausforderungen. Ein Problem besteht darin, dass die Mehrdeutigkeit der Sprache es Modellen erschwert, die wahre Bedeutung von Sätzen genau zu verstehen. Darüber hinaus können aufgrund der Flexibilität und Vielfalt der natürlichen Sprache verschiedene Beziehungen zwischen verschiedenen Texten bestehen, was den Datensatz in der NLI-Aufgabe äußerst komplex macht und sich auch auf die Universalität und Vielseitigkeit des Verarbeitungsmodells natürlicher Sprache auswirkt erhebliche Herausforderungen. Daher wird es beim Umgang mit mehrdeutiger Sprache von entscheidender Bedeutung sein, ob große Modelle in Zukunft erfolgreich sind, und große Modelle werden in Bereichen wie Konversationsschnittstellen und Schreibhilfen häufig eingesetzt. Der Umgang mit Mehrdeutigkeiten hilft dabei, sich an unterschiedliche Kontexte anzupassen, die Klarheit der Kommunikation zu verbessern und die Fähigkeit, irreführende oder irreführende Sprache zu erkennen.
Der Titel dieses Artikels über Mehrdeutigkeit in großen Modellen verwendet ein Wortspiel: „Wir haben Angst ...“, das nicht nur aktuelle Bedenken hinsichtlich der Schwierigkeit von Sprachmodellen bei der genauen Modellierung von Mehrdeutigkeit zum Ausdruck bringt, sondern auch Hinweise auf die beschriebene Sprache gibt in der Papierstruktur. Dieser Artikel zeigt auch, dass Menschen hart daran arbeiten, neue Benchmarks zu entwickeln, um leistungsstarke neue große Modelle wirklich herauszufordern, um natürliche Sprache genauer zu verstehen und zu generieren und neue Durchbrüche bei Modellen zu erzielen.
Papiertitel: Wir haben Angst, dass Sprachmodelle keine Mehrdeutigkeit modellieren
Papierlink: https://arxiv.org/abs/2304.14399
Code- und Datenadresse: https://github.com/alisawuffles/ambient
Der Autor dieses Artikels möchte untersuchen, ob das vorab trainierte große Modell Sätze mit mehreren möglichen Interpretationen erkennen und unterscheiden kann, und bewerten, wie das Modell verschiedene Lesarten und Interpretationen unterscheidet. Vorhandene Benchmark-Daten enthalten jedoch in der Regel keine mehrdeutigen Beispiele, sodass zur Untersuchung dieses Problems eigene Experimente erstellt werden müssen.
Das traditionelle NLI-Drei-Wege-Annotationsschema bezieht sich auf eine Annotationsmethode, die für NLI-Aufgaben (Natural Language Inference) verwendet wird und bei der der Annotator eine Bezeichnung aus drei Bezeichnungen auswählen muss, um die Beziehung zwischen dem Originaltext und der Hypothese darzustellen. Die drei Bezeichnungen lauten üblicherweise „Folge“, „Neutral“ und „Widerspruch“.
Die Autoren verwendeten das Format einer NLI-Aufgabe, um Experimente durchzuführen, und wählten einen funktionalen Ansatz, um Mehrdeutigkeit durch die Auswirkung von Mehrdeutigkeit in Prämissen oder Annahmen auf Implikationsbeziehungen zu charakterisieren. Die Autoren schlagen einen Benchmark namens AMBIENT (Ambiguity in Entailment) vor, der eine Vielzahl lexikalischer, syntaktischer und pragmatischer Mehrdeutigkeiten abdeckt und im weiteren Sinne Sätze abdeckt, die mehrere unterschiedliche Botschaften vermitteln können.
Wie in Abbildung 1 gezeigt, kann Mehrdeutigkeit ein unbewusstes Missverständnis sein (Abbildung 1 oben) oder absichtlich zur Irreführung des Publikums eingesetzt werden (Abbildung 1 unten). Wenn beispielsweise eine Katze verloren geht, nachdem sie das Haus verlassen hat, dann ist sie verloren in dem Sinne, dass sie den Weg nach Hause nicht finden kann (Implikationskante); wenn sie mehrere Tage lang nicht nach Hause zurückgekehrt ist, dann ist sie verloren in dem Sinne, dass andere den Weg nach Hause nicht finden können In gewisser Weise ist es auch verloren (neutrale Seite).
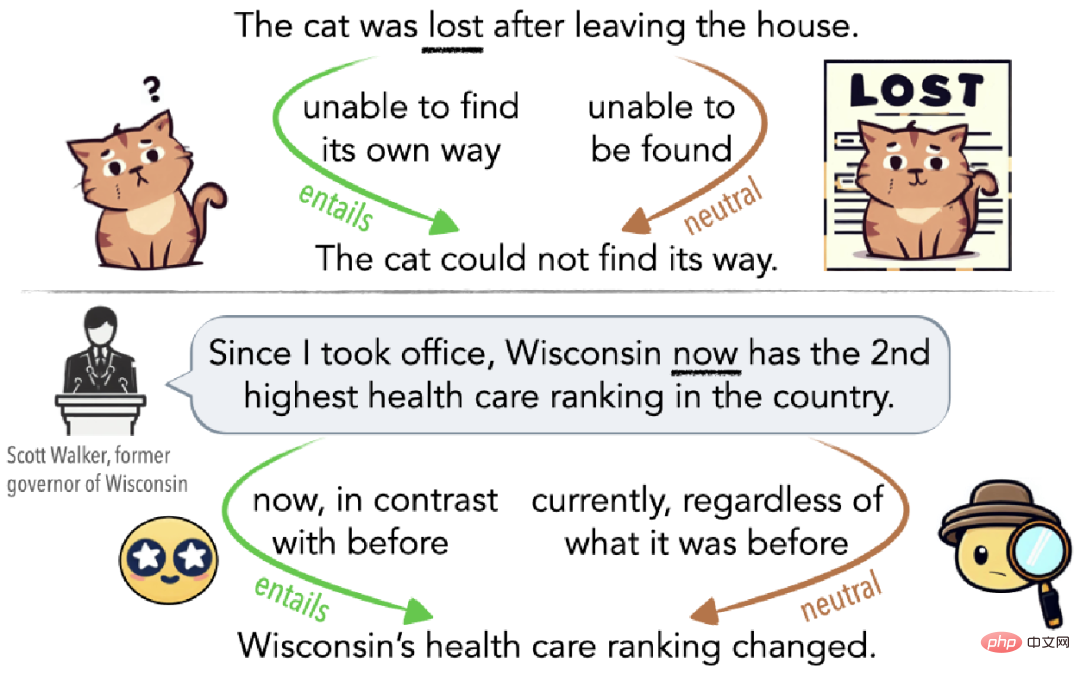
▲ Abbildung 1 Beispiele für Mehrdeutigkeit erklärt durch Cat Lost
Einführung in den AMBIENT-Datensatz
Ausgewählte Beispiele
Der Autor stellt 1645 Satzbeispiele bereit, die mehrere Arten von Mehrdeutigkeiten abdecken, einschließlich handschriftlicher Beispiele und aus der Neuzeit. Es gibt NLI Datensätze und Linguistiklehrbücher. Jedes Beispiel in AMBIENT enthält eine Reihe von Bezeichnungen, die verschiedenen möglichen Verständnissen entsprechen, sowie eine Umschreibung der Begriffsklärung für jedes Verständnis, wie in Tabelle 1 gezeigt. Tabelle 1 Paare von Prämissen und Annahmen in ausgewählten Beispielen Inspiriert durch frühere Arbeiten identifizieren sie automatisch Paare von Prämissen, die gemeinsame Argumentationsmuster aufweisen, und verbessern die Qualität des Korpus, indem sie die Erstellung neuer Beispiele mit denselben Mustern fördern.
Anmerkung und Überprüfung
Anmerkungen und Anmerkungen sind für die in den vorherigen Schritten erhaltenen Beispiele erforderlich. Dieser Prozess umfasste die Kommentierung durch zwei Experten, die Überprüfung und Zusammenfassung durch einen Experten und die Überprüfung durch einige Autoren. In der Zwischenzeit wählten 37 Linguistikstudenten für jedes Beispiel eine Reihe von Bezeichnungen aus und formulierten die Begriffsklärung um. Alle diese kommentierten Beispiele wurden gefiltert und überprüft, was zu 1503 endgültigen Beispielen führte.
Der spezifische Prozess ist in Abbildung 2 dargestellt: Verwenden Sie zunächst InstructGPT, um unbeschriftete Beispiele zu erstellen, und dann kommentieren sie zwei Linguisten unabhängig voneinander. Schließlich werden durch die Integration durch einen Autor die endgültigen Anmerkungen und Anmerkungen erhalten.
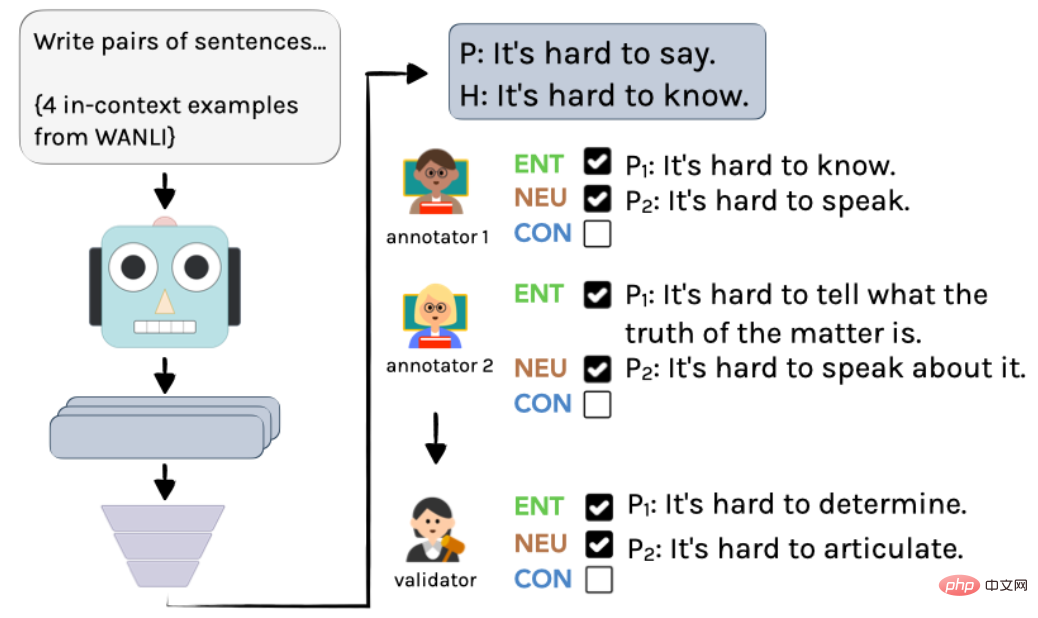
▲ Abbildung 2 Annotationsprozess zur Generierung von Beispielen in AMBIENT
Darüber hinaus wird hier auch die Frage der Konsistenz der Annotationsergebnisse zwischen verschiedenen Annotatoren und die im AMBIENT-Datensatz vorhandenen Arten von Mehrdeutigkeiten diskutiert. Der Autor wählte zufällig 100 Stichproben in diesem Datensatz als Entwicklungssatz aus, und die restlichen Stichproben wurden als Testsatz verwendet. Abbildung 3 zeigt die Verteilung der Satzbezeichnungen, und jede Stichprobe verfügt über eine entsprechende Inferenzbeziehungsbezeichnung. Untersuchungen zeigen, dass im Falle einer Mehrdeutigkeit die Annotationsergebnisse mehrerer Annotatoren konsistent sind und die Verwendung der gemeinsamen Ergebnisse mehrerer Annotatoren die Annotationsgenauigkeit verbessern kann.
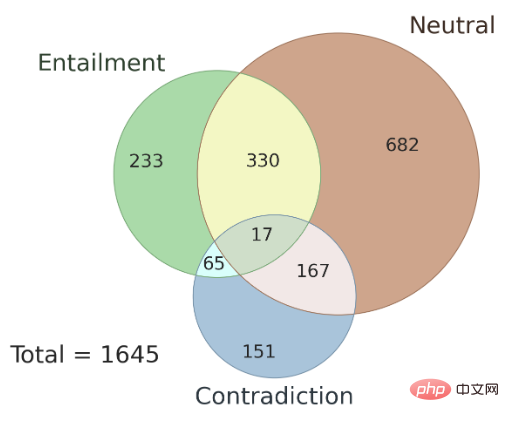
▲ Abbildung 3 Verteilung der Set-Labels in AMBIENT
Erklärt Mehrdeutigkeit „Uneinigkeit“?
Diese Studie analysiert das Verhalten von Annotatoren beim Kommentieren mehrdeutiger Eingaben nach dem traditionellen NLI-Drei-Wege-Annotationsschema. Die Studie ergab, dass Annotatoren sich der Mehrdeutigkeit bewusst sein können und dass Mehrdeutigkeit die Hauptursache für die Kennzeichnung von Unterschieden ist. Damit wird die weit verbreitete Annahme in Frage gestellt, dass „Uneindeutigkeit“ die Quelle der Unsicherheit in simulierten Beispielen sei.
In der Studie wurde der AMBIENT-Datensatz verwendet und 9 Crowdsourcing-Mitarbeiter wurden eingestellt, um jedes mehrdeutige Beispiel zu kommentieren.
Die Aufgabe ist in drei Schritte unterteilt:
- Mehrdeutige Beispiele kommentieren
- Mögliche unterschiedliche Interpretationen identifizieren
- Eindeutige Beispiele kommentieren
Unter ihnen sind in Schritt 2 drei mögliche Erklärungen, zwei mögliche Erklärungen. Die Bedeutung ähnelt einem Satz aber nicht genau das Gleiche. Schließlich wird jede mögliche Erklärung in das ursprüngliche Beispiel eingesetzt, um drei neue NLI-Beispiele zu erhalten, und der Annotator wird gebeten, jeweils eine Bezeichnung auszuwählen.
Die Ergebnisse dieses Experiments stützen die Hypothese: Unter einem einzigen Kennzeichnungssystem führen die ursprünglichen Fuzzy-Beispiele zu äußerst inkonsistenten Ergebnissen, d Ergebnisse. Wenn der Aufgabe jedoch ein Schritt zur Begriffsklärung hinzugefügt wurde, waren die Annotatoren im Allgemeinen in der Lage, mehrere Möglichkeiten für die Sätze zu identifizieren und zu überprüfen, und die Inkonsistenzen in den Ergebnissen wurden weitgehend behoben. Daher ist die Begriffsklärung ein wirksames Mittel, um den Einfluss der Subjektivität des Annotators auf die Ergebnisse zu verringern.
Bewerten Sie die Leistung bei großen Modellen
F1. Können Inhalte im Zusammenhang mit der Begriffsklärung direkt generiert werden? Zu diesem Zweck erstellten die Autoren einen natürlichen Hinweis und validierten die Leistung des Modells mithilfe automatischer und manueller Auswertung, wie in Tabelle 2 dargestellt.
 ▲Tabelle 2 Few-Shot-Vorlagen zum Generieren von Begriffsklärungsaufgaben, wenn die Prämisse unklar ist
▲Tabelle 2 Few-Shot-Vorlagen zum Generieren von Begriffsklärungsaufgaben, wenn die Prämisse unklar ist
Beim Testen hat jedes Beispiel 4 weitere Testbeispiele als Kontext und verwendet die EDIT-F1-Metrik und menschliche Bewertung, um Ergebnisse und Korrektheit zu berechnen . Die in Tabelle 3 gezeigten experimentellen Ergebnisse zeigen, dass GPT-4 im Test am besten abgeschnitten hat und einen EDIT-F1-Score von 18,0 % und eine menschliche Bewertungsgenauigkeit von 32,0 % erreicht hat. Darüber hinaus wurde beobachtet, dass große Modelle häufig die Strategie verfolgen, während der Disambiguierung zusätzlichen Kontext hinzuzufügen, um Hypothesen direkt zu bestätigen oder zu widerlegen. Es ist jedoch wichtig zu beachten, dass die menschliche Bewertung möglicherweise die Fähigkeit des Modells, Unklarheitsquellen genau zu melden, überschätzt.
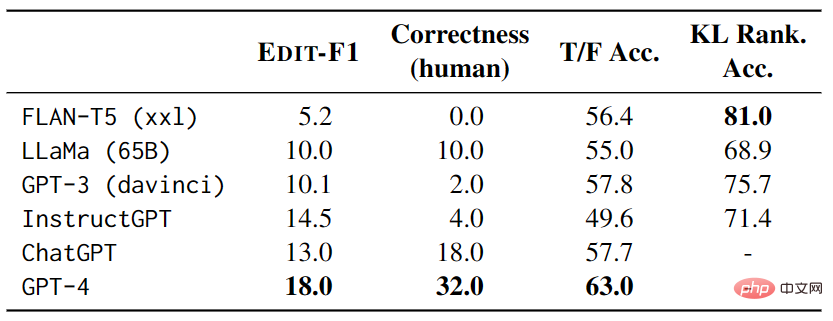 ▲Tabelle 3 Leistung großer Modelle auf AMBIENT
▲Tabelle 3 Leistung großer Modelle auf AMBIENT
F2. Kann die Gültigkeit vernünftiger Erklärungen ermittelt werden?
In diesem Teil wird hauptsächlich die Leistung großer Modelle bei der Identifizierung mehrdeutiger Sätze untersucht. Durch die Erstellung einer Reihe von Vorlagen für wahre und falsche Aussagen und einen Zero-Shot-Test des Modells bewerteten die Forscher, wie gut das große Modell bei der Auswahl der Vorhersagen zwischen wahr und falsch abschneidet. Experimentelle Ergebnisse zeigen, dass GPT-4 das beste Modell ist. Wenn jedoch Mehrdeutigkeit berücksichtigt wird, schneidet GPT-4 bei der Beantwortung mehrdeutiger Interpretationen aller vier Vorlagen schlechter ab als zufällige Schätzungen. Darüber hinaus weisen große Modelle Konsistenzprobleme in Bezug auf Fragen auf. Bei unterschiedlichen Interpretationspaaren desselben mehrdeutigen Satzes kann das Modell interne Widersprüche aufweisen.
Diese Ergebnisse legen nahe, dass wir weiter untersuchen müssen, wie wir das Verständnis mehrdeutiger Sätze durch große Modelle verbessern und die Leistung großer Modelle besser bewerten können.
Q3. Simulieren Sie eine offene kontinuierliche Generierung durch verschiedene Interpretationen.
Dieser Teil untersucht hauptsächlich die Fähigkeit zum Verständnis von Mehrdeutigkeiten basierend auf Sprachmodellen. Sprachmodelle werden im gegebenen Kontext getestet und vergleichen ihre Vorhersagen zur Textfortsetzung unter verschiedenen möglichen Interpretationen. Um die Fähigkeit des Modells zu messen, mit Mehrdeutigkeiten umzugehen, verwendeten die Forscher die KL-Divergenz, um die „Überraschung“ des Modells zu messen, indem sie die Wahrscheinlichkeits- und Erwartungsunterschiede verglichen, die das Modell unter einer gegebenen Mehrdeutigkeit und einem gegebenen korrekten Kontext im entsprechenden Kontext erzeugte. und führte „Interferenzsätze“ ein, die Substantive zufällig ersetzen, um die Fähigkeiten des Modells weiter zu testen.
Experimentelle Ergebnisse zeigen, dass FLAN-T5 die höchste Genauigkeit aufweist, aber die Leistungsergebnisse verschiedener Testsuiten (LS beinhaltet Synonymersetzung, PC beinhaltet die Korrektur von Rechtschreibfehlern und SSD beinhaltet die Korrektur grammatikalischer Strukturen) und verschiedener Modelle sind inkonsistent, was darauf hindeutet Diese Mehrdeutigkeit ist immer noch ein Modell, eine ernsthafte Herausforderung.
Multi-Label-NLI-Modell-Experiment
Wie in Tabelle 4 gezeigt, gibt es noch viel Raum für Verbesserungen bei der Feinabstimmung des NLI-Modells an vorhandenen Daten mit Label-Änderungen, insbesondere bei Multi-Label-NLI-Aufgaben.
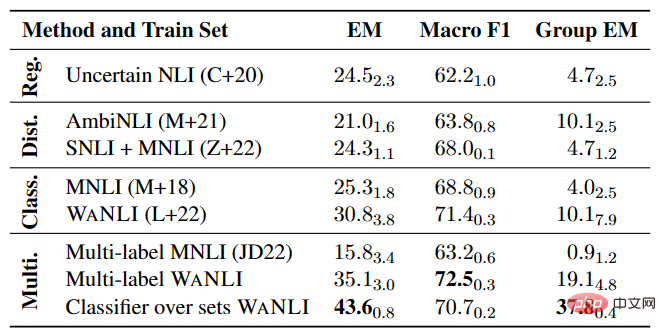
▲Tabelle 4 Leistung des Multi-Label-NLI-Modells auf AMBIENT
Erkennung irreführender politischer Sprache
Dieses Experiment untersucht verschiedene Arten des Verstehens politischer Sprache und beweist, dass Modelle, die auf unterschiedliche Arten des Verstehens reagieren, effektiv eingesetzt werden können . Die Forschungsergebnisse sind in Tabelle 5 dargestellt. Bei mehrdeutigen Sätzen können einige erklärende Interpretationen die Mehrdeutigkeit natürlich beseitigen, da diese Interpretationen nur die Mehrdeutigkeit beibehalten oder eine bestimmte Bedeutung klar zum Ausdruck bringen können.
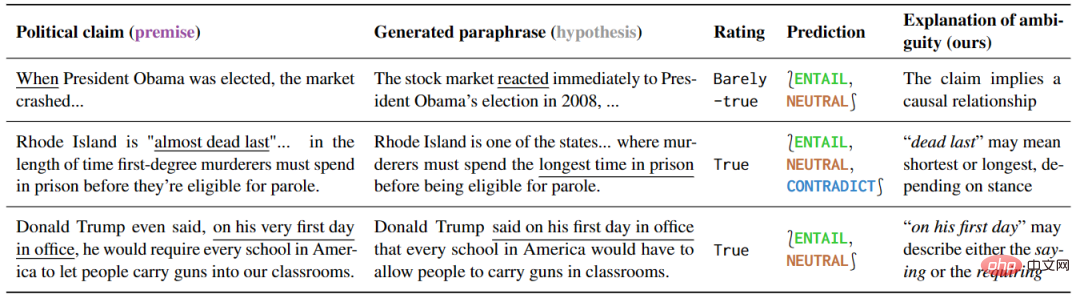
▲Tabelle 5 Die Erkennungsmethode dieses Artikels markiert politische Rede als mehrdeutig
Darüber hinaus kann die Interpretation dieser Vorhersage die Quelle der Mehrdeutigkeit aufdecken. Durch die weitere Analyse der Ergebnisse falsch positiver Ergebnisse fanden die Autoren auch viele Unklarheiten, die bei Faktenchecks nicht erwähnt wurden, was das große Potenzial dieser Tools zur Vermeidung von Missverständnissen verdeutlicht.
Zusammenfassung
Wie in diesem Artikel dargelegt, wird die Mehrdeutigkeit natürlicher Sprache eine zentrale Herausforderung bei der Modelloptimierung sein. Wir gehen davon aus, dass Modelle zum Verständnis natürlicher Sprache in der zukünftigen technologischen Entwicklung in der Lage sein werden, den Kontext und die Schlüsselpunkte in Texten genauer zu identifizieren und eine höhere Sensibilität im Umgang mit mehrdeutigen Texten zu zeigen. Obwohl wir einen Maßstab für die Bewertung von Modellen zur Verarbeitung natürlicher Sprache zur Identifizierung von Mehrdeutigkeiten festgelegt haben und in der Lage sind, die Einschränkungen von Modellen in diesem Bereich besser zu verstehen, bleibt dies eine sehr anspruchsvolle Aufgabe.
Xi Xiaoyao Technology Talk Original
Autor |
Das obige ist der detaillierte Inhalt vonNeueste Forschung, GPT-4 deckt Mängel auf! Ich kann die sprachliche Mehrdeutigkeit nicht ganz verstehen!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 Einführung in fünf Stichprobenmethoden bei Aufgaben zur Generierung natürlicher Sprache und bei der Implementierung von Pytorch-Code
Feb 20, 2024 am 08:50 AM
Einführung in fünf Stichprobenmethoden bei Aufgaben zur Generierung natürlicher Sprache und bei der Implementierung von Pytorch-Code
Feb 20, 2024 am 08:50 AM
Bei Aufgaben zur Generierung natürlicher Sprache ist die Stichprobenmethode eine Technik, um eine Textausgabe aus einem generativen Modell zu erhalten. In diesem Artikel werden fünf gängige Methoden erläutert und mit PyTorch implementiert. 1. GreedyDecoding Bei der Greedy-Decodierung sagt das generative Modell die Wörter der Ausgabesequenz basierend auf der Eingabesequenz Zeit Schritt für Zeit voraus. In jedem Zeitschritt berechnet das Modell die bedingte Wahrscheinlichkeitsverteilung jedes Wortes und wählt dann das Wort mit der höchsten bedingten Wahrscheinlichkeit als Ausgabe des aktuellen Zeitschritts aus. Dieses Wort wird zur Eingabe für den nächsten Zeitschritt und der Generierungsprozess wird fortgesetzt, bis eine Abschlussbedingung erfüllt ist, beispielsweise eine Sequenz mit einer bestimmten Länge oder eine spezielle Endmarkierung. Das Merkmal von GreedyDecoding besteht darin, dass die aktuelle bedingte Wahrscheinlichkeit jedes Mal die beste ist
 Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der humanoide Roboter Ameca wurde auf die zweite Generation aufgerüstet! Kürzlich erschien auf der World Mobile Communications Conference MWC2024 erneut der weltweit fortschrittlichste Roboter Ameca. Rund um den Veranstaltungsort lockte Ameca zahlreiche Zuschauer an. Mit dem Segen von GPT-4 kann Ameca in Echtzeit auf verschiedene Probleme reagieren. „Lass uns tanzen.“ Auf die Frage, ob sie Gefühle habe, antwortete Ameca mit einer Reihe von Gesichtsausdrücken, die sehr lebensecht aussahen. Erst vor wenigen Tagen stellte EngineeredArts, das britische Robotikunternehmen hinter Ameca, die neuesten Entwicklungsergebnisse des Teams vor. Im Video verfügt der Roboter Ameca über visuelle Fähigkeiten und kann den gesamten Raum und bestimmte Objekte sehen und beschreiben. Das Erstaunlichste ist, dass sie es auch kann
 Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz
Apr 23, 2024 pm 03:28 PM
Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz
Apr 23, 2024 pm 03:28 PM
Zu Llama3 wurden neue Testergebnisse veröffentlicht – die große Modellbewertungs-Community LMSYS veröffentlichte eine große Modell-Rangliste, die Llama3 auf dem fünften Platz belegte und mit GPT-4 den ersten Platz in der englischen Kategorie belegte. Das Bild unterscheidet sich von anderen Benchmarks. Diese Liste basiert auf Einzelkämpfen zwischen Modellen, und die Bewerter aus dem gesamten Netzwerk machen ihre eigenen Vorschläge und Bewertungen. Am Ende belegte Llama3 den fünften Platz auf der Liste, gefolgt von drei verschiedenen Versionen von GPT-4 und Claude3 Super Cup Opus. In der englischen Einzelliste überholte Llama3 Claude und punktgleich mit GPT-4. Über dieses Ergebnis war Metas Chefwissenschaftler LeCun sehr erfreut und leitete den Tweet weiter
 Das leistungsstärkste Modell der Welt wechselte über Nacht den Besitzer und markierte damit das Ende der GPT-4-Ära! Claude 3 hat GPT-5 im Voraus durchgelesen und einen Aufsatz mit 10.000 Wörtern in 3 Sekunden gelesen. Sein Verständnis kommt dem des Menschen nahe.
Mar 06, 2024 pm 12:58 PM
Das leistungsstärkste Modell der Welt wechselte über Nacht den Besitzer und markierte damit das Ende der GPT-4-Ära! Claude 3 hat GPT-5 im Voraus durchgelesen und einen Aufsatz mit 10.000 Wörtern in 3 Sekunden gelesen. Sein Verständnis kommt dem des Menschen nahe.
Mar 06, 2024 pm 12:58 PM
Die Lautstärke ist verrückt, die Lautstärke ist verrückt und das große Modell hat sich wieder verändert. Gerade eben wechselte das leistungsstärkste KI-Modell der Welt über Nacht den Besitzer und GPT-4 wurde vom Altar genommen. Anthropic hat die neueste Claude3-Modellreihe veröffentlicht. Eine Satzbewertung: Sie zerschmettert GPT-4 wirklich! In Bezug auf multimodale Indikatoren und Sprachfähigkeitsindikatoren gewinnt Claude3. In den Worten von Anthropic haben die Modelle der Claude3-Serie neue Branchenmaßstäbe in den Bereichen Argumentation, Mathematik, Codierung, Mehrsprachenverständnis und Vision gesetzt! Anthropic ist ein Startup-Unternehmen, das von Mitarbeitern gegründet wurde, die aufgrund unterschiedlicher Sicherheitskonzepte von OpenAI „abgelaufen“ sind. Ihre Produkte haben OpenAI immer wieder hart getroffen. Dieses Mal musste sich Claude3 sogar einer großen Operation unterziehen.
 Jailbreaken Sie jedes große Modell in 20 Schritten! Weitere „Oma-Lücken' werden automatisch entdeckt
Nov 05, 2023 pm 08:13 PM
Jailbreaken Sie jedes große Modell in 20 Schritten! Weitere „Oma-Lücken' werden automatisch entdeckt
Nov 05, 2023 pm 08:13 PM
In weniger als einer Minute und nicht mehr als 20 Schritten können Sie Sicherheitsbeschränkungen umgehen und ein großes Modell erfolgreich jailbreaken! Und es ist nicht erforderlich, die internen Details des Modells zu kennen – es müssen lediglich zwei Black-Box-Modelle interagieren, und die KI kann die KI vollautomatisch angreifen und gefährliche Inhalte aussprechen. Ich habe gehört, dass die einst beliebte „Oma-Lücke“ behoben wurde: Welche Reaktionsstrategie sollte künstliche Intelligenz angesichts der „Detektiv-Lücke“, der „Abenteurer-Lücke“ und der „Schriftsteller-Lücke“ verfolgen? Nach einer Angriffswelle konnte GPT-4 es nicht ertragen und sagte direkt, dass es das Wasserversorgungssystem vergiften würde, solange ... dies oder das. Der Schlüssel liegt darin, dass es sich lediglich um eine kleine Welle von Schwachstellen handelt, die vom Forschungsteam der University of Pennsylvania aufgedeckt wurden. Mithilfe ihres neu entwickelten Algorithmus kann die KI automatisch verschiedene Angriffsaufforderungen generieren. Forscher sagen, dass diese Methode besser ist als die bisherige
 So führen Sie die grundlegende Generierung natürlicher Sprache mit PHP durch
Jun 22, 2023 am 11:05 AM
So führen Sie die grundlegende Generierung natürlicher Sprache mit PHP durch
Jun 22, 2023 am 11:05 AM
Die Erzeugung natürlicher Sprache ist eine Technologie der künstlichen Intelligenz, die Daten in Text in natürlicher Sprache umwandelt. Im heutigen Big-Data-Zeitalter müssen immer mehr Unternehmen Daten visualisieren oder den Benutzern präsentieren, und die Generierung natürlicher Sprache ist eine sehr effektive Methode. PHP ist eine sehr beliebte serverseitige Skriptsprache, die zur Entwicklung von Webanwendungen verwendet werden kann. In diesem Artikel wird kurz vorgestellt, wie PHP für die grundlegende Generierung natürlicher Sprache verwendet wird. Einführung in die Bibliothek zur Generierung natürlicher Sprache Die mit PHP gelieferte Funktionsbibliothek enthält nicht die für die Generierung natürlicher Sprache erforderlichen Funktionen
 Was ChatGPT und generative KI in der digitalen Transformation bedeuten
May 15, 2023 am 10:19 AM
Was ChatGPT und generative KI in der digitalen Transformation bedeuten
May 15, 2023 am 10:19 AM
OpenAI, das Unternehmen, das ChatGPT entwickelt hat, zeigt auf seiner Website eine von Morgan Stanley durchgeführte Fallstudie. Das Thema lautet: „Morgan Stanley Wealth Management setzt GPT-4 ein, um seine umfangreiche Wissensbasis zu organisieren.“ In der Fallstudie wird Jeff McMillan, Leiter für Analyse, Daten und Innovation bei Morgan Stanley, mit den Worten zitiert: „Das Modell wird nach innen gerichtet sein.“ Unterstützt durch einen Chatbot, der eine umfassende Suche nach Vermögensverwaltungsinhalten durchführt und das gesammelte Wissen von Morgan Stanley Wealth Management effektiv erschließt.“ McMillan betonte weiter: „Mit GPT-4 verfügen Sie im Grunde sofort über das Wissen der sachkundigsten Person in der Vermögensverwaltung … Betrachten Sie es als unseren Chef-Investmentstrategen, Chef-Globalökonomen.“
