

So verwenden Sie das Python-Beautifulsoup4-Modul

1. Ergänzende Grundkenntnisse von BeautifulSoup4
BeautifulSoup4 ist eine Python-Parsing-Bibliothek, die hauptsächlich zum Parsen von HTML und XML verwendet wird. Im Crawler-Wissenssystem wird es mehr Parsen von HTML geben Dieser Befehl zur Bibliotheksinstallation lautet wie folgt:BeautifulSoup4 是一款 python 解析库,主要用于解析 HTML 和 XML,在爬虫知识体系中解析 HTML 会比较多一些,
该库安装命令如下:
pip install beautifulsoup4
BeautifulSoup 在解析数据时,需依赖第三方解析器,常用解析器与优势如下所示:
python 标准库 html.parser:python 内置标准库,容错能力强;lxml 解析器:速度快,容错能力强;html5lib:容错性最强,解析方式与浏览器一致。
接下来用一段自定义的 HTML 代码来演示 beautifulsoup4 库的基本使用,测试代码如下:
<html>
<head>
<title>测试bs4模块脚本</title>
</head>
<body>
<h2 id="橡皮擦的爬虫课">橡皮擦的爬虫课</h2>
<p>用一段自定义的 HTML 代码来演示</p>
</body>
</html>使用 BeautifulSoup 对其进行简单的操作,包含实例化 BS 对象,输出页面标签等内容。
from bs4 import BeautifulSoup text_str = """<html> <head> <title>测试bs4模块脚本</title> </head> <body> <h2 id="橡皮擦的爬虫课">橡皮擦的爬虫课</h2> <p>用1段自定义的 HTML 代码来演示</p> <p>用2段自定义的 HTML 代码来演示</p> </body> </html> """ # 实例化 Beautiful Soup 对象 soup = BeautifulSoup(text_str, "html.parser") # 上述是将字符串格式化为 Beautiful Soup 对象,你可以从一个文件进行格式化 # soup = BeautifulSoup(open('test.html')) print(soup) # 输入网页标题 title 标签 print(soup.title) # 输入网页 head 标签 print(soup.head) # 测试输入段落标签 p print(soup.p) # 默认获取第一个
我们可以通过 BeautifulSoup 对象,直接调用网页标签,这里存在一个问题,通过 BS 对象调用标签只能获取排在第一位置上的标签,如上述代码中,只获取到了一个 p 标签,如果想要获取更多内容,请继续阅读。
学习到这里,我们需要了解 BeautifulSoup 中的 4 个内置对象:
BeautifulSoup:基本对象,整个 HTML 对象,一般当做 Tag 对象看即可;Tag:标签对象,标签就是网页中的各个节点,例如 title,head,p;NavigableString:标签内部字符串;Comment:注释对象,爬虫里面使用场景不多。
下述代码为你演示这几种对象出现的场景,注意代码中的相关注释:
from bs4 import BeautifulSoup text_str = """<html> <head> <title>测试bs4模块脚本</title> </head> <body> <h2 id="橡皮擦的爬虫课">橡皮擦的爬虫课</h2> <p>用1段自定义的 HTML 代码来演示</p> <p>用2段自定义的 HTML 代码来演示</p> </body> </html> """ # 实例化 Beautiful Soup 对象 soup = BeautifulSoup(text_str, "html.parser") # 上述是将字符串格式化为 Beautiful Soup 对象,你可以从一个文件进行格式化 # soup = BeautifulSoup(open('test.html')) print(soup) print(type(soup)) # <class 'bs4.BeautifulSoup'> # 输入网页标题 title 标签 print(soup.title) print(type(soup.title)) # <class 'bs4.element.Tag'> print(type(soup.title.string)) # <class 'bs4.element.NavigableString'> # 输入网页 head 标签 print(soup.head)
对于 Tag 对象,有两个重要的属性,是 name 和 attrs
from bs4 import BeautifulSoup text_str = """<html> <head> <title>测试bs4模块脚本</title> </head> <body> <h2 id="橡皮擦的爬虫课">橡皮擦的爬虫课</h2> <p>用1段自定义的 HTML 代码来演示</p> <p>用2段自定义的 HTML 代码来演示</p> <a href="http://www.csdn.net" rel="external nofollow" rel="external nofollow" >CSDN 网站</a> </body> </html> """ # 实例化 Beautiful Soup 对象 soup = BeautifulSoup(text_str, "html.parser") print(soup.name) # [document] print(soup.title.name) # 获取标签名 title print(soup.html.body.a) # 可以通过标签层级获取下层标签 print(soup.body.a) # html 作为一个特殊的根标签,可以省略 print(soup.p.a) # 无法获取到 a 标签 print(soup.a.attrs) # 获取属性
上述代码演示了获取 name 属性和 attrs 属性的用法,其中 attrs 属性得到的是一个字典,可以通过键获取对应的值。
获取标签的属性值,在 BeautifulSoup 中,还可以使用如下方法:
print(soup.a["href"])
print(soup.a.get("href"))获取 NavigableString 对象 获取了网页标签之后,就要获取标签内文本了,通过下述代码进行。
print(soup.a.string)
除此之外,你还可以使用 text 属性和 get_text() 方法获取标签内容。
print(soup.a.string) print(soup.a.text) print(soup.a.get_text())
还可以获取标签内所有文本,使用 strings 和 stripped_strings 即可。
print(list(soup.body.strings)) # 获取到空格或者换行 print(list(soup.body.stripped_strings)) # 去除空格或者换行
扩展标签/节点选择器之遍历文档树
直接子节点
标签(Tag)对象的直接子元素,可以使用 contents 和 children 属性获取。
from bs4 import BeautifulSoup
text_str = """<html>
<head>
<title>测试bs4模块脚本</title>
</head>
<body>
<div id="content">
<h2 id="橡皮擦的爬虫课-span-最棒-span">橡皮擦的爬虫课<span>最棒</span></h2>
<p>用1段自定义的 HTML 代码来演示</p>
<p>用2段自定义的 HTML 代码来演示</p>
<a href="http://www.csdn.net" rel="external nofollow" rel="external nofollow" >CSDN 网站</a>
</div>
<ul class="nav">
<li>首页</li>
<li>博客</li>
<li>专栏课程</li>
</ul>
</body>
</html>
"""
# 实例化 Beautiful Soup 对象
soup = BeautifulSoup(text_str, "html.parser")
# contents 属性获取节点的直接子节点,以列表的形式返回内容
print(soup.div.contents) # 返回列表
# children 属性获取的也是节点的直接子节点,以生成器的类型返回
print(soup.div.children) # 返回 <list_iterator object at 0x00000111EE9B6340>请注意以上两个属性获取的都是直接子节点,例如 h2 标签内的后代标签 span ,不会单独获取到。
如果希望将所有的标签都获取到,使用 descendants 属性,它返回的是一个生成器,所有标签包括标签内的文本都会单独获取。
print(list(soup.div.descendants))
其它节点的获取(了解即可,即查即用)
parent和parents:直接父节点和所有父节点;next_sibling,next_siblings,previous_sibling,previous_siblings:分别表示下一个兄弟节点、下面所有兄弟节点、上一个兄弟节点、上面所有兄弟节点,由于换行符也是一个节点,所有在使用这几个属性时,要注意一下换行符;next_element,next_elements,previous_element,previous_elements:这几个属性分别表示上一个节点或者下一个节点,注意它们不分层次,而是针对所有节点,例如上述代码中div节点的下一个节点是h2,而div节点的兄弟节点是ul。
文档树搜索相关函数
第一个要学习的函数就是 find_all() 函数,原型如下所示:
find_all(name,attrs,recursive,text,limit=None,**kwargs)
name:该参数为 tag 标签的名字,例如find_all('p')是查找所有的pprint(soup.find_all('li')) # 获取所有的 li print(soup.find_all(attrs={'class': 'nav'})) # 传入 attrs 属性 print(soup.find_all(re.compile("p"))) # 传递正则,实测效果不理想 print(soup.find_all(['a','p'])) # 传递列表Nach dem Login kopierenNach dem Login kopierenBeautifulSoupBeim Parsen von Daten müssen Sie sich auf einen Parser eines Drittanbieters verlassen. Häufig verwendete Parser und ihre Vorteile sind wie folgt folgt:🎜< ul class=" list-paddingleft-2">- 🎜
Python-Standardbibliothek html.parser: in Python integrierte Standardbibliothek, starke Fehlertoleranz 🎜< /li> - 🎜
lxml-Parser: schnell und fehlertolerant; 🎜 - 🎜
html5lib: die fehlertoleranteste und beste Analysemethode stimmt mit dem Browser überein. 🎜
beautifulsoup4-Bibliothek zu demonstrieren. Der Testcode lautet wie folgt: 🎜print(soup.body.div.find_all(['a','p'],recursive=False)) # 传递列表
BeautifulSoup< /code> Führen Sie einfache Vorgänge aus, einschließlich der Instanziierung von BS-Objekten, der Ausgabe von Seiten-Tags usw. 🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>print(soup.find_all(text=&#39;首页&#39;)) # [&#39;首页&#39;]
print(soup.find_all(text=re.compile("^首"))) # [&#39;首页&#39;]
print(soup.find_all(text=["首页",re.compile(&#39;课&#39;)])) # [&#39;橡皮擦的爬虫课&#39;, &#39;首页&#39;, &#39;专栏课程&#39;]</pre><div class="contentsignin">Nach dem Login kopieren</div></div><div class="contentsignin">Nach dem Login kopieren</div></div>🎜Wir können Webseiten-Tags direkt über das BeautifulSoup-Objekt aufrufen. Beim Aufrufen von Tags über das BS-Objekt kann beispielsweise nur ein <code>p< an erster Stelle stehen erhalten wird. Wenn Sie mehr Inhalte erhalten möchten, lesen Sie bitte weiter. 🎜🎜<strong>Nachdem wir das gelernt haben, müssen wir die 4 integrierten Objekte in BeautifulSoup verstehen: </strong>🎜<ul class=" list-paddingleft-2"><li>🎜<code>BeautifulSoup</code >: Das Basisobjekt, das gesamte HTML-Objekt, kann im Allgemeinen als Tag-Objekt angezeigt werden. 🎜</li><li>🎜<code>Tag: Tag-Objekt, Tags sind jeder Knoten auf der Webseite. wie Titel, Kopf, p ;🎜NavigableString: Tag-interne Zeichenfolge; 🎜Comment: Kommentarobjekt , Nutzungsszenarien in Crawlern sind nicht gleich viele. 🎜print(soup.find_all(class_ = 'nav')) print(soup.find_all(class_ = 'nav li'))
name und attrs🎜print(soup.select('ul[class^="na"]'))
name erhält Verwendung von Attributen und attrs-Attributen, wobei das attrs-Attribut ein Wörterbuch erhält und der entsprechende Wert per Schlüssel abgerufen werden kann. 🎜🎜Rufen Sie den Attributwert des Tags ab. In BeautifulSoup können Sie auch die folgende Methode verwenden: 🎜print(soup.select('ul[class*="li"]'))
NavigableString-Objekt ab Sie müssen den Text im Tag über den folgenden Code abrufen. 🎜from bs4 import BeautifulSoup
import requests
import logging
logging.basicConfig(level=logging.NOTSET)
def get_html(url, headers) -> None:
try:
res = requests.get(url=url, headers=headers, timeout=3)
except Exception as e:
logging.debug("采集异常", e)
if res is not None:
html_str = res.text
soup = BeautifulSoup(html_str, "html.parser")
imgs = soup.find_all(attrs={'class': 'lazy'})
print("获取到的数据量是", len(imgs))
datas = []
for item in imgs:
name = item.get('alt')
src = item["src"]
logging.info(f"{name},{src}")
# 获取拼接数据
datas.append((name, src))
save(datas, headers)
def save(datas, headers) -> None:
if datas is not None:
for item in datas:
try:
# 抓取图片
res = requests.get(url=item[1], headers=headers, timeout=5)
except Exception as e:
logging.debug(e)
if res is not None:
img_data = res.content
with open("./imgs/{}.jpg".format(item[0]), "wb+") as f:
f.write(img_data)
else:
return None
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36"
}
url_format = "http://www.9thws.com/#p{}"
urls = [url_format.format(i) for i in range(1, 2)]
get_html(urls[0], headers)text und die Methode get_text() verwenden, um den Tag-Inhalt abzurufen. 🎜rrreee🎜Sie können den gesamten Text im Tag auch abrufen, indem Sie strings und stripped_strings verwenden. 🎜rrreee🎜Erweiterter Tag-/Knotenselektor zum Durchlaufen des Dokumentbaums🎜🎜Direkter untergeordneter Knoten🎜🎜Direktes untergeordnetes Element des Tag-Objekts (Tag), Sie können contents und verwenden children-Attributerfassung. 🎜rrreee🎜Bitte beachten Sie, dass die beiden oben genannten Attribute die direkten untergeordneten Knoten erhalten, wie z. B. das Nachkommen-Tag span innerhalb des h2-Tags, und dies auch tun nicht getrennt erhalten werden. 🎜🎜Wenn Sie alle Tags abrufen möchten, verwenden Sie das Attribut descendants, das einen Generator zurückgibt, und alle Tags, einschließlich des Textes innerhalb der Tags, werden separat abgerufen. 🎜rrreee🎜Erwerb anderer Knoten (einfach wissen, überprüfen und verwenden)🎜- 🎜
parentundparents</ code >: direkter übergeordneter Knoten und alle übergeordneten Knoten; 🎜</li><li>🎜<code>next_sibling,next_siblings,previous_sibling,previous_siblings: Stellt den nächsten Geschwisterknoten dar, alle darunter liegenden Geschwisterknoten, den vorherigen Geschwisterknoten und alle darüber liegenden Geschwisterknoten. Achten Sie bei der Verwendung dieser Attribute auf das Newline-Zeichen 🎜 - 🎜
next_element,next_elements,previous_element,previous_elements: Diese Attribute repräsentieren jeweils das vorherige Bitte beachten Sie, dass sie nicht hierarchisch sind, sondern für alle Knoten. Im obigen Code ist der nächste Knoten desdiv-Knotens beispielsweiseh2unddiv-Knotens istul. 🎜
find_all(), der Prototyp ist wie folgt folgt Anzeige:🎜rrreee- 🎜
name: Dieser Parameter ist der Name des Tag-Tags, zum Beispielfind_all ('p')soll allep-Tags finden und kann Tag-Namenszeichenfolgen, reguläre Ausdrücke und Listen akzeptieren 🎜 attrs:传入的属性,该参数可以字典的形式传入,例如attrs={'class': 'nav'},返回的结果是 tag 类型的列表;
上述两个参数的用法示例如下:
print(soup.find_all('li')) # 获取所有的 li
print(soup.find_all(attrs={'class': 'nav'})) # 传入 attrs 属性
print(soup.find_all(re.compile("p"))) # 传递正则,实测效果不理想
print(soup.find_all(['a','p'])) # 传递列表recursive:调用find_all ()方法时,BeautifulSoup 会检索当前 tag 的所有子孙节点,如果只想搜索 tag 的直接子节点,可以使用参数recursive=False,测试代码如下:
print(soup.body.div.find_all(['a','p'],recursive=False)) # 传递列表
text:可以检索文档中的文本字符串内容,与name参数的可选值一样,text参数接受标签名字符串、正则表达式、 列表;
print(soup.find_all(text='首页')) # ['首页']
print(soup.find_all(text=re.compile("^首"))) # ['首页']
print(soup.find_all(text=["首页",re.compile('课')])) # ['橡皮擦的爬虫课', '首页', '专栏课程']limit:可以用来限制返回结果的数量;kwargs:如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作 tag 的属性来搜索。这里要按class属性搜索,因为class是 python 的保留字,需要写作class_,按class_查找时,只要一个 CSS 类名满足即可,如需多个 CSS 名称,填写顺序需要与标签一致。
print(soup.find_all(class_ = 'nav')) print(soup.find_all(class_ = 'nav li'))
还需要注意网页节点中,有些属性在搜索中不能作为kwargs参数使用,比如html5 中的 data-*属性,需要通过attrs参数进行匹配。
与
find_all()方法用户基本一致的其它方法清单如下:
find():函数原型find( name , attrs , recursive , text , **kwargs ),返回一个匹配元素;find_parents(),find_parent():函数原型find_parent(self, name=None, attrs={}, **kwargs),返回当前节点的父级节点;find_next_siblings(),find_next_sibling():函数原型find_next_sibling(self, name=None, attrs={}, text=None, **kwargs),返回当前节点的下一兄弟节点;find_previous_siblings(),find_previous_sibling():同上,返回当前的节点的上一兄弟节点;find_all_next(),find_next(),find_all_previous () ,find_previous ():函数原型find_all_next(self, name=None, attrs={}, text=None, limit=None, **kwargs),检索当前节点的后代节点。
CSS 选择器 该小节的知识点与pyquery有点撞车,核心使用select()方法即可实现,返回数据是列表元组。
通过标签名查找,
soup.select("title");通过类名查找,
soup.select(".nav");通过 id 名查找,
soup.select("#content");通过组合查找,
soup.select("div#content");通过属性查找,
soup.select("div[id='content'"),soup.select("a[href]");
在通过属性查找时,还有一些技巧可以使用,例如:
^=:可以获取以 XX 开头的节点:
print(soup.select('ul[class^="na"]'))
*=:获取属性包含指定字符的节点:
print(soup.select('ul[class*="li"]'))
二、爬虫案例
BeautifulSoup 的基础知识掌握之后,在进行爬虫案例的编写,就非常简单了,本次要采集的目标网站 ,该目标网站有大量的艺术二维码,可以供设计大哥做参考。
下述应用到了 BeautifulSoup 模块的标签检索与属性检索,完整代码如下:
from bs4 import BeautifulSoup
import requests
import logging
logging.basicConfig(level=logging.NOTSET)
def get_html(url, headers) -> None:
try:
res = requests.get(url=url, headers=headers, timeout=3)
except Exception as e:
logging.debug("采集异常", e)
if res is not None:
html_str = res.text
soup = BeautifulSoup(html_str, "html.parser")
imgs = soup.find_all(attrs={'class': 'lazy'})
print("获取到的数据量是", len(imgs))
datas = []
for item in imgs:
name = item.get('alt')
src = item["src"]
logging.info(f"{name},{src}")
# 获取拼接数据
datas.append((name, src))
save(datas, headers)
def save(datas, headers) -> None:
if datas is not None:
for item in datas:
try:
# 抓取图片
res = requests.get(url=item[1], headers=headers, timeout=5)
except Exception as e:
logging.debug(e)
if res is not None:
img_data = res.content
with open("./imgs/{}.jpg".format(item[0]), "wb+") as f:
f.write(img_data)
else:
return None
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36"
}
url_format = "http://www.9thws.com/#p{}"
urls = [url_format.format(i) for i in range(1, 2)]
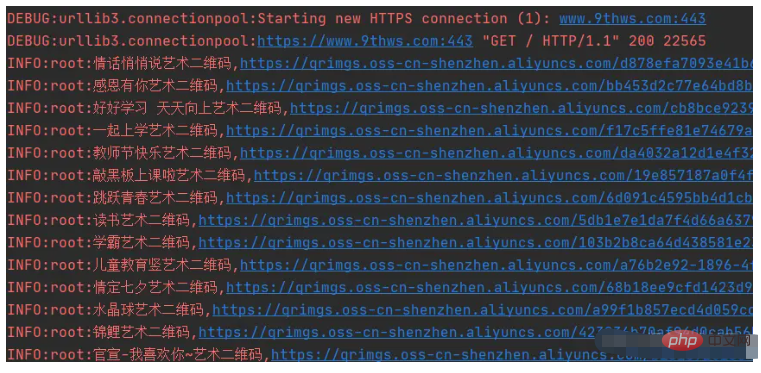
get_html(urls[0], headers)本次代码测试输出采用的 logging 模块实现,效果如下图所示。 测试仅采集了 1 页数据,如需扩大采集范围,只需要修改 main 函数内页码规则即可。 ==代码编写过程中,发现数据请求是类型是 POST,数据返回格式是 JSON,所以本案例仅作为 BeautifulSoup 的上手案例吧==
Das obige ist der detaillierte Inhalt vonSo verwenden Sie das Python-Beautifulsoup4-Modul. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Die MySQL -Download -Datei ist beschädigt und kann nicht installiert werden. Reparaturlösung
Apr 08, 2025 am 11:21 AM
Die MySQL -Download -Datei ist beschädigt und kann nicht installiert werden. Reparaturlösung
Apr 08, 2025 am 11:21 AM
Die MySQL -Download -Datei ist beschädigt. Was soll ich tun? Wenn Sie MySQL herunterladen, können Sie die Korruption der Datei begegnen. Es ist heutzutage wirklich nicht einfach! In diesem Artikel wird darüber gesprochen, wie dieses Problem gelöst werden kann, damit jeder Umwege vermeiden kann. Nach dem Lesen können Sie nicht nur das beschädigte MySQL -Installationspaket reparieren, sondern auch ein tieferes Verständnis des Download- und Installationsprozesses haben, um zu vermeiden, dass Sie in Zukunft stecken bleiben. Lassen Sie uns zunächst darüber sprechen, warum das Herunterladen von Dateien beschädigt wird. Dafür gibt es viele Gründe. Netzwerkprobleme sind der Schuldige. Unterbrechung des Download -Prozesses und der Instabilität im Netzwerk kann zu einer Korruption von Dateien führen. Es gibt auch das Problem mit der Download -Quelle selbst. Die Serverdatei selbst ist gebrochen und natürlich auch unterbrochen, wenn Sie sie herunterladen. Darüber hinaus kann das übermäßige "leidenschaftliche" Scannen einer Antiviren -Software auch zu einer Beschädigung von Dateien führen. Diagnoseproblem: Stellen Sie fest, ob die Datei wirklich beschädigt ist
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
MySQL kann ohne Netzwerkverbindungen für die grundlegende Datenspeicherung und -verwaltung ausgeführt werden. Für die Interaktion mit anderen Systemen, Remotezugriff oder Verwendung erweiterte Funktionen wie Replikation und Clustering ist jedoch eine Netzwerkverbindung erforderlich. Darüber hinaus sind Sicherheitsmaßnahmen (wie Firewalls), Leistungsoptimierung (Wählen Sie die richtige Netzwerkverbindung) und die Datensicherung für die Verbindung zum Internet von entscheidender Bedeutung.
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 Lösungen für den Dienst, der nach der MySQL -Installation nicht gestartet werden kann
Apr 08, 2025 am 11:18 AM
Lösungen für den Dienst, der nach der MySQL -Installation nicht gestartet werden kann
Apr 08, 2025 am 11:18 AM
MySQL hat sich geweigert, anzufangen? Nicht in Panik, lass es uns ausprobieren! Viele Freunde stellten fest, dass der Service nach der Installation von MySQL nicht begonnen werden konnte, und sie waren so ängstlich! Mach dir keine Sorgen, dieser Artikel wird dich dazu bringen, ruhig damit umzugehen und den Mastermind dahinter herauszufinden! Nachdem Sie es gelesen haben, können Sie dieses Problem nicht nur lösen, sondern auch Ihr Verständnis von MySQL -Diensten und Ihren Ideen zur Fehlerbehebungsproblemen verbessern und zu einem leistungsstärkeren Datenbankadministrator werden! Der MySQL -Dienst startete nicht und es gibt viele Gründe, von einfachen Konfigurationsfehlern bis hin zu komplexen Systemproblemen. Beginnen wir mit den häufigsten Aspekten. Grundkenntnisse: Eine kurze Beschreibung des Service -Startup -Prozesses MySQL Service Startup. Einfach ausgedrückt, lädt das Betriebssystem MySQL-bezogene Dateien und startet dann den MySQL-Daemon. Dies beinhaltet die Konfiguration
