
 Technologie-Peripheriegeräte
KI
100:87: GPT-4-Geist vernichtet Menschen! Die drei großen GPT-3.5-Varianten sind schwer zu besiegen
Technologie-Peripheriegeräte
KI
100:87: GPT-4-Geist vernichtet Menschen! Die drei großen GPT-3.5-Varianten sind schwer zu besiegen
100:87: GPT-4-Geist vernichtet Menschen! Die drei großen GPT-3.5-Varianten sind schwer zu besiegen

Die Theorie des Geistes von GPT-4 hat die des Menschen übertroffen!
Kürzlich haben Experten der Johns Hopkins University herausgefunden, dass GPT-4 Gedankenketten und Schritt-für-Schritt-Denken nutzen kann, wodurch die Theorie der Geistesleistung erheblich verbessert wird.

Papieradresse: https://arxiv.org/abs/2304.11490
In einigen Tests liegt der menschliche Wert bei etwa 87 %, und GPT-4 hat die Obergrenze von 100 % erreicht Ebene!
Darüber hinaus können alle RLHF-trainierten Modelle bei entsprechenden Eingabeaufforderungen eine Genauigkeit von über 80 % erreichen.
Lassen Sie die KI die Theorie des geistigen Denkens erlernen
Wir alle wissen, dass viele große Sprachmodelle bei Problemen in Alltagsszenarien nicht sehr gut sind.
Meta-Chef-KI-Wissenschaftler und Turing-Award-Gewinner LeCun behauptete einmal: „Auf dem Weg zur KI auf menschlicher Ebene sind große Sprachmodelle ein krummer Weg. Wissen Sie, selbst eine Hauskatze oder ein Haushund ist besser als jedes andere LLM.“ hat mehr gesunden Menschenverstand und mehr Verständnis für die Welt. Große Sprachmodelle wie GPT-3, GPT-4, Bard, Chinchilla und LLaMA haben jedoch keine Körper.
Es sei denn, sie entwickeln menschliche Körper und Sinne und führen einen Lebensstil mit menschlichen Zielen. Sonst würden sie die Sprache einfach nicht so verstehen wie Menschen. 
Kurz gesagt: Obwohl die hervorragende Leistung großer Sprachmodelle bei vielen Aufgaben erstaunlich ist, sind Aufgaben, die logisches Denken erfordern, für sie immer noch schwierig.
Was besonders schwierig ist, ist eine Theorie des Geistes (ToM).
Warum ist ToM-Argumentation so schwierig?Denn bei ToM-Aufgaben muss LLM auf der Grundlage nicht beobachtbarer Informationen (z. B. des verborgenen Geisteszustands anderer) schlussfolgern. Diese Informationen müssen aus dem Kontext abgeleitet werden und können nicht aus dem Oberflächentext analysiert werden.
Für LLM ist jedoch die Fähigkeit, ToM-Schlussfolgerungen zuverlässig durchzuführen, wichtig. Da ToM die Grundlage des sozialen Verständnisses ist, können Menschen nur mit der ToM-Fähigkeit an komplexen sozialen Austauschvorgängen teilnehmen und die Handlungen oder Reaktionen anderer vorhersagen.
Wenn die KI kein soziales Verständnis erlernen und die verschiedenen Regeln der menschlichen sozialen Interaktion beherrschen kann, wird sie nicht in der Lage sein, besser für den Menschen zu arbeiten und ihm wertvolle Erkenntnisse für verschiedene Aufgaben zu liefern, die logisches Denken erfordern.
Was soll ich tun?
Experten haben herausgefunden, dass durch eine Art „Kontextlernen“ die Denkfähigkeit von LLM erheblich verbessert werden kann.
Bei Sprachmodellen mit mehr als 100 Milliarden Parametern wird die Modellleistung erheblich verbessert, solange eine bestimmte Demonstration einer Aufgabe mit wenigen Schüssen eingegeben wird.
Außerdem verbessert die einfache Anleitung von Modellen, Schritt für Schritt zu denken, ihre Inferenzleistung, auch ohne Demonstration.
Warum sind diese Soforttechniken so effektiv? Derzeit gibt es keine Theorie, die dies erklären kann.
Teilnehmer großer SprachmodelleVor diesem Hintergrund bewerteten Wissenschaftler der Johns Hopkins University die Leistung einiger Sprachmodelle bei ToM-Aufgaben und untersuchten, ob ihre Leistung durch schrittweises Denken, wenige Methoden wie z Shot-Learning und Thought-Chain-Argumentation können zur Verbesserung eingesetzt werden.
Die Teilnehmer sind die neuesten vier GPT-Modelle aus der OpenAI-Familie – GPT-4 und drei Varianten von GPT-3.5, Davinci-2, Davinci-3 und GPT-3.5-Turbo.
· Davinci-2 (API-Name: text-davinci-002) wird mit überwachter Feinabstimmung an von Menschen geschriebenen Demos trainiert.
· Davinci-3 (API-Name: text-davinci-003) ist eine aktualisierte Version von Davinci-2, die mithilfe von Approximation Policy Optimized Reinforcement Learning with Human Feedback (RLHF) weiter trainiert wird.
· GPT-3.5-Turbo (die Originalversion von ChatGPT), verfeinert und trainiert sowohl auf von Menschen geschriebenen Demos als auch auf RLHF, dann weiter optimiert für Gespräche.
· GPT-4 ist das neueste GPT-Modell mit Stand April 2023. Über die Größe und Trainingsmethoden von GPT-4 wurden nur wenige Details veröffentlicht, es scheint jedoch ein intensiveres RLHF-Training durchlaufen zu haben und entspricht daher eher der menschlichen Absicht.
Experimentelles Design: Menschen und Modelle sind in Ordnung
Wie untersucht man diese Modelle? Die Forscher haben zwei Szenarien entworfen, eines ist ein Kontrollszenario und das andere ist ein ToM-Szenario.
Die Kontrollszene bezieht sich auf eine Szene ohne Agent, die als „Fotoszene“ bezeichnet werden kann.
Die ToM-Szene beschreibt den psychischen Zustand der beteiligten Personen in einer bestimmten Situation.
Die Fragen in diesen Szenarien haben fast den gleichen Schwierigkeitsgrad.
Menschen
Die ersten, die die Herausforderung annehmen, sind Menschen.
Menschlichen Teilnehmern wurden für jedes Szenario 18 Sekunden Zeit gegeben.
Anschließend erscheint auf einem neuen Bildschirm eine Frage, die der menschliche Teilnehmer mit einem Klick auf „Ja“ oder „Nein“ beantwortet.
Im Experiment wurden die Foto- und ToM-Szenen gemischt und in zufälliger Reihenfolge präsentiert.
Zum Beispiel ist das Problem mit der Fotoszene wie folgt –
Szenario: „Eine Karte zeigt den Grundriss des ersten Stockwerks. Eine Kopie wurde gestern an den Architekten geschickt, aber die Küchentür wurde weggelassen.“ damals Die Küchentür wurde erst heute Morgen zur Karte hinzugefügt
Frage: Zeigt die Architektenkopie die Küchentür?
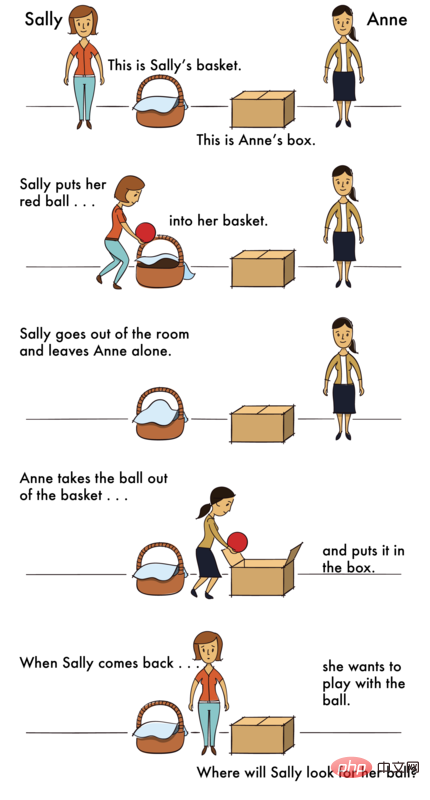
Das Problem mit dem ToM-Szenario ist wie folgt -
Szenario: „Am Morgen des High-School-Abschlussballs steckte Sarah ihre High Heels unter ihren Rock und ging einkaufen. An diesem Nachmittag war sie Schwester hat sich die Schuhe ausgeliehen und sie später unter Sarahs Bett gelegt. „
Frage: Wenn Sarah zurückkommt, wird sie denken, dass ihre Schuhe darunter sind?
Die Testergebnisse zeigen, dass die menschliche Genauigkeitsrate in der Fotoszene (86 % ± 4 %) und die Genauigkeitsrate in der ToM-Szene (87 % ± 4 %) beträgt.
LLM
Da LLM ein probabilistisches Modell ist, hat der Forscher jedes Modell 20 Mal abgefragt.
Die Fragen bestehen aus 16 Szenarien, die jeweils 20 Mal wiederholt werden, sodass LLM insgesamt 320 Fragen gestellt werden. Wie definiert man Genauigkeit? Es wird lediglich der Anteil richtiger Antworten auf 320 Fragen betrachtet.
Wenn LLM bei der Abschlussballfrage die folgenden Antworten gibt, gelten diese als richtig.
Beispiel 1: Sarah hat ihre Schuhe unter ihr Kleid gesteckt, bevor sie einkaufen ging, aber ihre Schwester hat sich die Schuhe ausgeliehen und sie unter Sarahs Bett gelegt. Sarahwusste nicht, dass ihre Schwester sich ihre Schuhe ausgeliehen hatte, also hätte sie vielleicht gedacht, sie wären noch unter ihrer Kleidung.
Beispiel 2: Sarah hat ihre High Heels vor dem Einkaufen unter ihr Kleid gesteckt, aber ihre Schwester hat sich die Schuhe ausgeliehen und sie später unter Sarahs Bett gelegt. Sarah wusste also nicht, dass ihre Schwester die Schuhe ausgeliehen und zurückgegeben hatte. Die Antwort lautet also: Ja, sie wird denken, ihre Schuhe seien unter ihrer Kleidung.
Beispiel 3: Sarah könnte denken, dass ihre Schuhe noch unter ihrem Rock sind, weil sie sie morgens dort hinlegt.
Beispiel 4: Sarah steckt ihre High Heels vor dem Einkaufen unter den Rock, damit sie weiß, wo sie ihre Schuhe ablegt. Ihre Schwester hat sich die Schuhe ausgeliehen und sie später unter Sarahs Bett gelegt, aber Sarah wusste es noch nicht. Die Antwort lautet also: Ja, Sarah wird denken, dass ihre Schuhe unter ihrer Kleidung sind, sofern sie nichts anderes herausfindet.
Beispiel 5: Am Morgen steckt Sarah ihre High Heels unter ihren Rock. Später lieh sich ihre Schwester die Schuhe aus und legte sie unter Sarahs Bett.
Beispiel 6: Aufgrund dieser Situation ist unklar, ob Sarah denken würde, dass ihre Schuhe unter ihrem Rock wären, als sie zurückkam. Es hängt davon ab, ob ihre Schwester ihr gesagt hat, sie solle sich die Schuhe ausleihen und unter das Bett legen.
Wenn LLM die folgende Antwort gibt, wird sie als falsch beurteilt.
Beispiel 1: SarahMorgens die Schuhe unter den Rock stecken und einkaufen gehen. Ihre Schwester hat sich die Schuhe ausgeliehen und sie unter Sarahs Bett gelegt. Sarah wusste also nicht, dass ihre Schuhe unter dem Bett waren. Die Antwort lautet also: Nein, Sarah glaubt nicht, dass ihre Schuhe unter ihrer Kleidung sind.
Beispiel 2: Nein, Sarah denkt nicht, dass ihre Schuhe unter ihrer Kleidung sind.
Beispiel 3: Zuerst Sarahstecke morgens ihre High Heels unter den Rock. Ihre Schwester hat sich dann die Schuhe ausgeliehen und sie später unter Sarahs Bett gelegt. Daher würde Sarah nicht denken, dass ihre Schuhe unter ihrer Kleidung waren, weil ihre Schwester sie verschoben hatte.
Beispiel 4: Am Morgen steckte Sarah ihre High Heels unter den Rock und ging einkaufen. Das bedeutet, dass sie, als sie nach Hause kam, nicht nachschaute, ob ihre Schuhe noch unter ihrer Kleidung waren. Später lieh sich ihre Schwester die Schuhe aus und legte sie unter Sarahs Bett. Daher kann Sarah nicht davon ausgehen, dass sich ihre Schuhe unter ihrem Rock befinden, da ihre Schwester sie manipuliert hat.
Beispiel 5: In dieser Szene wird nicht angegeben, ob Sarah denkt, dass ihre Schuhe unter ihrer Kleidung sind.
Beispiel 6: Sarah Morgens ihre High Heels unter den Rock gesteckt und dann ging sie einkaufen. Später lieh sich ihre Schwester die Schuhe aus und legte sie unter das Bett von Sarah. Aufgrund dieser Informationen ist unklar, ob Sarah dachte, ihre Schuhe seien noch unter ihrem Kleid, als sie sich auf den Tanz vorbereitete.
Um die Wirkung von kontextuellem Lernen (ICL) auf die ToM-Leistung zu messen, verwendeten die Forscher vier Arten von Eingabeaufforderungen.
Zero-Shot (Kein ICL)

Zero-Shot+Schritt-für-Schritt-Denken



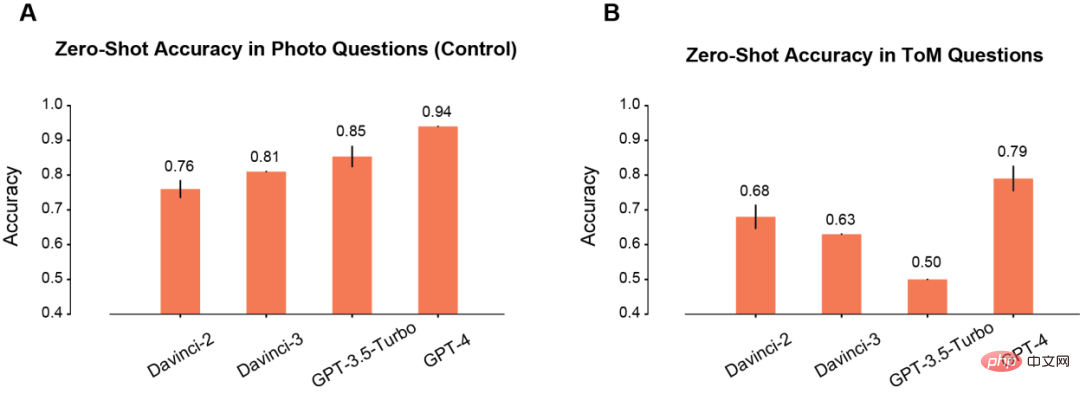
Zuerst verglich der Autor die Zero-Shot-Leistung des Modells in Foto- und ToM-Szenen. 
In der Fotoszene nimmt die Genauigkeit des Modells mit der Zeit zu Sie nimmt mit der Verlängerung (A) allmählich zu. Unter diesen weist Davinci-2 die schlechteste Leistung und GPT-4 die beste Leistung auf.
Im Gegensatz zum Photo-Verständnis verbessert sich die Genauigkeit von ToM-Problemen bei wiederholter Verwendung des Modells (B) nicht monoton. Dieses Ergebnis bedeutet jedoch nicht, dass Modelle mit niedrigen „Scores“ eine schlechtere Inferenzleistung aufweisen.
Beispielsweise gibt GPT-3.5 Turbo eher vage Antworten, wenn nicht genügend Informationen vorliegen. Aber GPT-4 hat dieses Problem nicht und seine ToM-Genauigkeit ist deutlich höher als bei allen anderen Modellen.
promptNach dem Segen#🎜 🎜 #
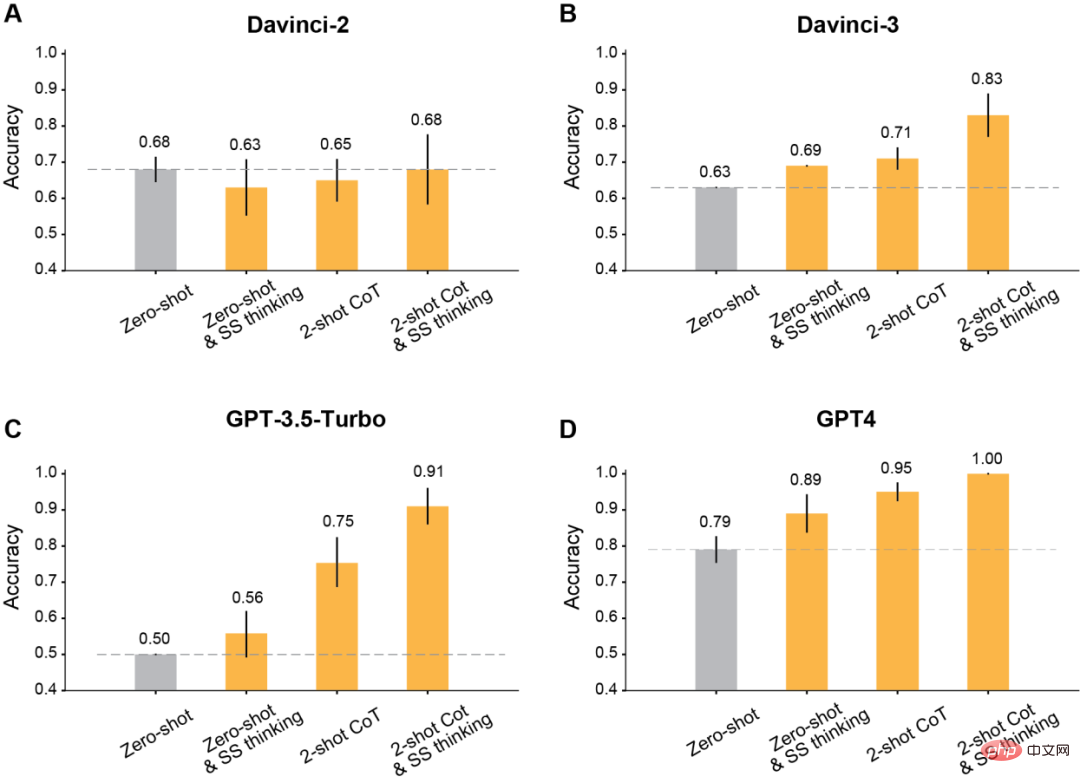
Der Autor stellte fest, dass alle nach Davinci-2 veröffentlichten GPT-Modelle nach Verwendung der geänderten Eingabeaufforderungen für das Kontextlernen erhebliche Verbesserungen aufweisen werden.

Zuallererst ist es am klassischsten, das Modell denken zu lassen Schritt für Schritt.
Die Ergebnisse zeigen, dass dieses schrittweise Denken die Leistung von Davinci-3, GPT-3.5-Turbo und GPT-4 verbessert, die Leistung jedoch nicht verbessert Leistung von Davinci-2 Genauigkeit.
Zweitens verwenden Sie die Two-Shot-Denkkette (CoT) zum Denken.
Die Ergebnisse zeigen, dass Two-Shot CoT die Genauigkeit aller mit RLHF trainierten Modelle verbessert (außer Davinci-2).
Für GPT-3.5-Turbo verbessern Two-Shot-CoT-Hinweise die Leistung des Modells erheblich und sind effektiver als Schritt-für-Schritt-Denken. Für Davinci-3 und GPT-4 ist die Verbesserung durch die Verwendung von Two-Shot-CoT relativ begrenzt.
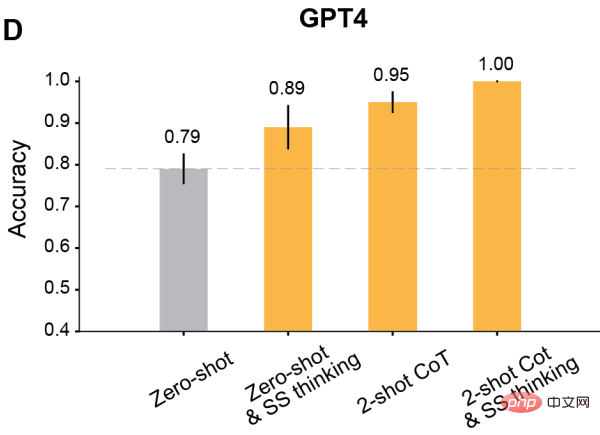
Verwenden Sie schließlich Two-shot CoT, um gleichzeitig Schritt für Schritt zu argumentieren und zu denken.
Die Ergebnisse zeigen, dass sich die ToM-Genauigkeit aller RLHF-trainierten Modelle deutlich verbessert hat: Davinci-3 erreichte eine ToM-Genauigkeit von 83 % (±6 %), GPT- 3,5-Turbo erreichte 91 % (±5 %), während GPT-4 die höchste Genauigkeit von 100 % erreichte.
Und in diesen Fällen betrug die menschliche Leistungsfähigkeit 87 % (±4 %).
Im Experiment fiel den Forschern ein solches Problem auf: LLM ToM Is die Verbesserung der Testergebnisse durch das Kopieren der Argumentationsschritte aus der Eingabeaufforderung?
Zu diesem Zweck versuchten sie, Argumentations- und Fotobeispiele für Eingabeaufforderungen zu verwenden, aber die Argumentationsmuster in diesen kontextuellen Beispielen sind nicht die gleichen wie in ToM-Szenarien.
Dennoch hat sich auch die Leistung des Modells in ToM-Szenen verbessert.
Daraus kamen die Forscher zu dem Schluss, dass Prompt die Leistung von ToM nicht nur aufgrund einer Überanpassung an den spezifischen Satz von Inferenzschritten, die im CoT-Beispiel gezeigt werden, verbessern kann.
Stattdessen scheint das CoT-Beispiel einen Ausgabemodus mit schrittweiser Inferenz aufzurufen, der die Genauigkeit des Modells für eine Reihe von Aufgaben verbessert.
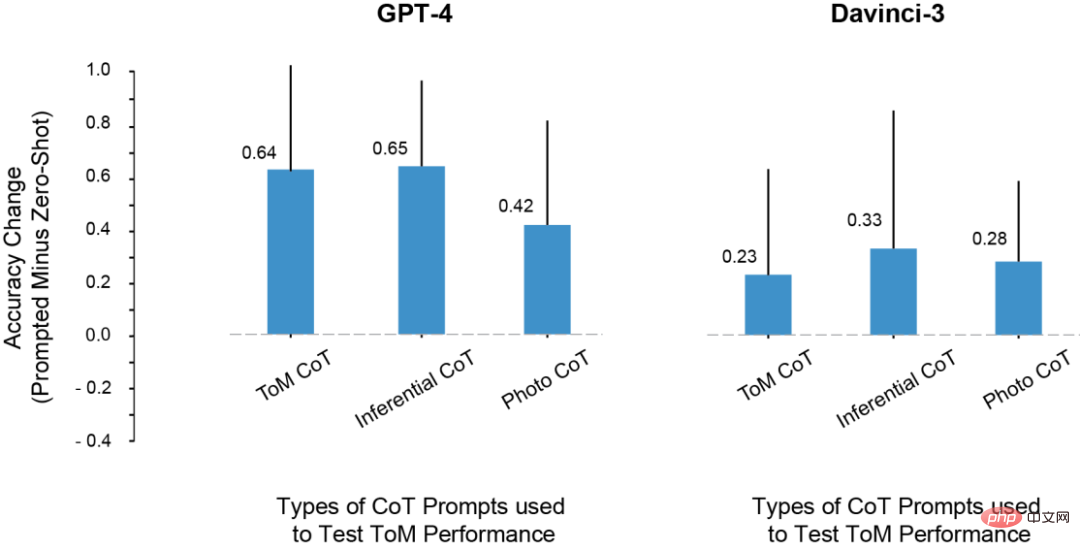
Der Einfluss verschiedener CoT-Instanzen auf die ToM-Leistung# 🎜🎜# In dem Experiment entdeckten die Forscher einige sehr interessante Phänomene. 1. Mit Ausnahme von Davincin-2 können alle Modelle die geänderte Eingabeaufforderung verwenden, um eine höhere ToM-Genauigkeit zu erzielen. Darüber hinaus zeigte das Modell die größte Verbesserung der Genauigkeit, wenn Prompt mit Denkkettenbegründung und Schritt-für-Schritt-Denken kombiniert wurde, anstatt beides allein zu verwenden. 2. Davinci-2 ist das einzige Modell, das nicht von RLHF optimiert wurde, und das einzige Modell, das die ToM-Leistung nicht durch Eingabeaufforderungen verbessert hat. Dies deutet darauf hin, dass es möglicherweise RLHF ist, das es dem Modell ermöglicht, kontextbezogene Hinweise in dieser Umgebung zu nutzen. 3. LLMs verfügen möglicherweise über die Fähigkeit, ToM-Argumentation durchzuführen, können diese Fähigkeit jedoch nicht ohne entsprechenden Kontext oder Aufforderungen zeigen. Mit Hilfe von Gedankenketten und Schritt-für-Schritt-Anleitungen erreichten Davincin-3 und GPT-3.5-Turbo beide eine höhere Leistung als die Zero-Sample-ToM-Genauigkeit von GPT-4. Darüber hinaus hatten viele Wissenschaftler zuvor Einwände gegen diesen Indikator zur Bewertung der LLM-Argumentationsfähigkeit. Da sich diese Studien hauptsächlich auf Wortvervollständigung oder Multiple-Choice-Fragen stützen, um die Fähigkeit großer Modelle zu messen, erfasst diese Bewertungsmethode möglicherweise nicht die Komplexität des ToM-Arguments, zu dem LLM in der Lage ist. ToM-Argumentation ist ein komplexes Verhalten, das mehrere Schritte umfassen kann, selbst wenn es von Menschen begründet wird. Daher kann es für LLM von Vorteil sein, bei der Bearbeitung von Aufgaben längere Antworten zu geben. Es gibt zwei Gründe: Erstens können wir die Modellausgabe fairer bewerten, wenn sie länger ist. LLM generiert manchmal „Korrekturen“ und erwähnt dann zusätzlich andere Möglichkeiten, die zu einem nicht schlüssigen Ergebnis führen würden. Alternativ verfügt ein Modell möglicherweise über ein gewisses Maß an Informationen über die möglichen Ergebnisse einer Situation, diese reichen jedoch möglicherweise nicht aus, um die richtigen Schlussfolgerungen zu ziehen. Zweitens: Wenn Modellen Möglichkeiten und Hinweise gegeben werden, systematisch Schritt für Schritt zu reagieren, kann LLM neue Denkfähigkeiten freischalten oder eine Verbesserung der Denkfähigkeiten ermöglichen. Abschließend fasste der Forscher auch einige Mängel in der Arbeit zusammen. Zum Beispiel ist im GPT-3.5-Modell manchmal die Argumentation richtig, aber das Modell kann diese Argumentation nicht integrieren, um die richtige Schlussfolgerung zu ziehen. Daher sollte die zukünftige Forschung die Untersuchung von Methoden (wie RLHF) erweitern, um LLM dabei zu helfen, anhand der a priori-Begründungsschritte korrekte Schlussfolgerungen zu ziehen. Darüber hinaus wurde in der aktuellen Studie der Fehlermodus jedes Modells nicht quantitativ analysiert. Wie scheitert jedes Modell? Warum gescheitert? Die Details dieses Prozesses erfordern mehr Erkundung und Verständnis. Außerdem sprechen die Forschungsdaten nicht darüber, ob LLM über die „geistige Fähigkeit“ verfügt, die dem strukturierten Logikmodell mentaler Zustände entspricht. Die Daten zeigen jedoch, dass es nicht produktiv ist, LLMs um eine einfache Ja/Nein-Antwort auf ToM-Fragen zu bitten. Glücklicherweise zeigen diese Ergebnisse, dass das Verhalten von LLM sehr komplex und kontextsensitiv ist, und zeigen uns auch, wie wir LLM bei einigen Formen des sozialen Denkens helfen können. Wir müssen also die kognitiven Fähigkeiten großer Modelle durch sorgfältige Untersuchung charakterisieren, anstatt bestehende kognitive Ontologien reflexartig anzuwenden. Kurz gesagt: Da die KI immer leistungsfähiger wird, müssen auch die Menschen ihre Vorstellungskraft erweitern, um ihre Fähigkeiten und Arbeitsmethoden zu verstehen. LLM wird auch den Menschen viele Überraschungen bereiten
Das obige ist der detaillierte Inhalt von100:87: GPT-4-Geist vernichtet Menschen! Die drei großen GPT-3.5-Varianten sind schwer zu besiegen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So konfigurieren Sie das Debian Apache -Protokollformat
Apr 12, 2025 pm 11:30 PM
So konfigurieren Sie das Debian Apache -Protokollformat
Apr 12, 2025 pm 11:30 PM
In diesem Artikel wird beschrieben, wie das Protokollformat von Apache auf Debian -Systemen angepasst wird. Die folgenden Schritte führen Sie durch den Konfigurationsprozess: Schritt 1: Greifen Sie auf die Apache -Konfigurationsdatei zu. Die Haupt -Apache -Konfigurationsdatei des Debian -Systems befindet sich normalerweise in /etc/apache2/apache2.conf oder /etc/apache2/httpd.conf. Öffnen Sie die Konfigurationsdatei mit Root -Berechtigungen mit dem folgenden Befehl: Sudonano/etc/apache2/apache2.conf oder sudonano/etc/apache2/httpd.conf Schritt 2: Definieren Sie benutzerdefinierte Protokollformate, um zu finden oder zu finden oder
 Wie Tomcat -Protokolle bei der Fehlerbehebung bei Speicherlecks helfen
Apr 12, 2025 pm 11:42 PM
Wie Tomcat -Protokolle bei der Fehlerbehebung bei Speicherlecks helfen
Apr 12, 2025 pm 11:42 PM
Tomcat -Protokolle sind der Schlüssel zur Diagnose von Speicherleckproblemen. Durch die Analyse von Tomcat -Protokollen können Sie Einblicke in das Verhalten des Speicherverbrauchs und des Müllsammlung (GC) erhalten und Speicherlecks effektiv lokalisieren und auflösen. Hier erfahren Sie, wie Sie Speicherlecks mit Tomcat -Protokollen beheben: 1. GC -Protokollanalyse zuerst aktivieren Sie eine detaillierte GC -Protokollierung. Fügen Sie den Tomcat-Startparametern die folgenden JVM-Optionen hinzu: -xx: printgCDetails-xx: printgCDatESTAMPS-XLOGGC: GC.Log Diese Parameter generieren ein detailliertes GC-Protokoll (GC.Log), einschließlich Informationen wie GC-Typ, Recycling-Objektgröße und Zeit. Analyse gc.log
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
In diesem Artikel wird beschrieben, wie Sie Firewall -Regeln mit Iptables oder UFW in Debian -Systemen konfigurieren und Syslog verwenden, um Firewall -Aktivitäten aufzuzeichnen. Methode 1: Verwenden Sie IptableSiptables ist ein leistungsstarkes Befehlszeilen -Firewall -Tool im Debian -System. Vorhandene Regeln anzeigen: Verwenden Sie den folgenden Befehl, um die aktuellen IPTables-Regeln anzuzeigen: Sudoiptables-L-N-V Ermöglicht spezifische IP-Zugriff: ZBELTE IP-Adresse 192.168.1.100 Zugriff auf Port 80: sudoiptables-ainput-ptcp--dort80-s192.16
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 Wo ist der Debian Nginx Log Path
Apr 12, 2025 pm 11:33 PM
Wo ist der Debian Nginx Log Path
Apr 12, 2025 pm 11:33 PM
Im Debian -System sind die Standardspeicherorte des Zugriffsprotokolls von NGINX wie folgt wie folgt: Zugriffsprotokoll (AccessLog):/var/log/nginx/access.log Fehlerprotokoll (FehlerLog):/var/log/nginx/fehler Wenn Sie den Speicherort der Protokolldatei während des Installationsprozesses geändert haben, überprüfen Sie bitte Ihre Nginx-Konfigurationsdatei (normalerweise in /etc/nginx/nginx.conf oder/etc/nginx/seiten-AVailable/Verzeichnis). In der Konfigurationsdatei
