

Wie SpringBoot Caffeine verwendet, um Caching zu implementieren

Warum Caching zu Anwendungen hinzufügen?
Bevor wir uns damit befassen, wie man Caching zu Anwendungen hinzufügt, stellt sich zunächst die Frage, warum wir Caching in Anwendungen verwenden müssen.
Angenommen, es gibt eine Anwendung, die Kundendaten enthält, und der Benutzer stellt zwei Anfragen, um die Kundendaten abzurufen (ID = 100).
Das passiert ohne Caching.
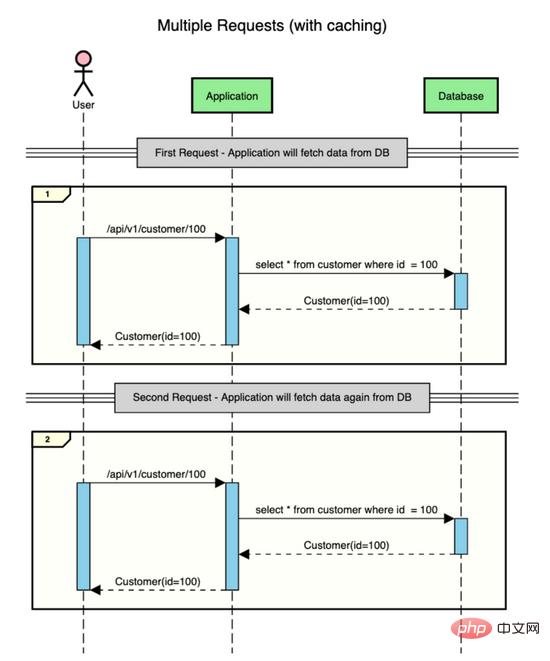
Wie Sie sehen, greift die Anwendung bei jeder Anfrage auf die Datenbank zu, um die Daten abzurufen. Das Abrufen von Daten aus der Datenbank ist ein kostspieliger Vorgang, da es E/A erfordert.
Wenn Sie jedoch in der Mitte einen Cache-Speicher haben, in dem Sie Daten für einen kurzen Zeitraum zwischenspeichern können, können Sie diese Roundtrips zur Datenbank speichern und so IO-Zeit einsparen.
So sieht die obige Interaktion bei Verwendung von Caching aus.
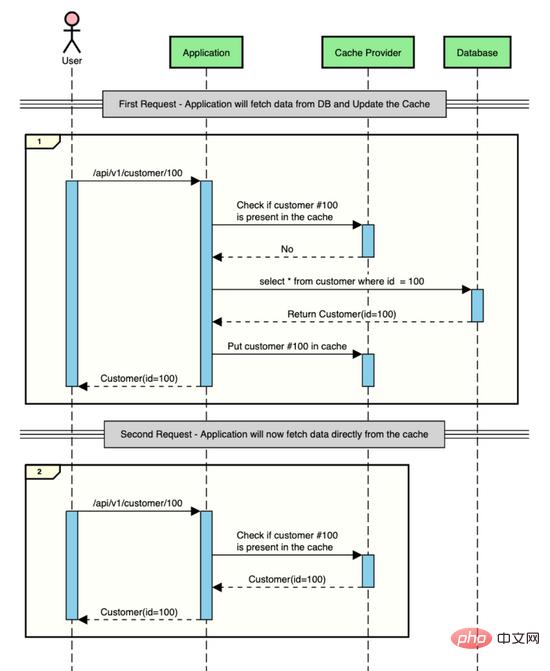
Caching in Spring Boot-Anwendungen implementieren
Welche Caching-Unterstützung bietet SpringBoot?
SpringBoot bietet nur eine Cache-Abstraktion, mit der Sie Ihrer Spring-Anwendung transparent und einfach Cache hinzufügen können.
Es bietet keinen tatsächlichen Cache-Speicher.
Es kann jedoch mit verschiedenen Arten von Cache-Anbietern wie Ehcache, Hazelcast, Redis, Caffee usw. funktionieren.
Die Caching-Abstraktion von SpringBoot kann zu Methoden hinzugefügt werden (mithilfe von Annotationen).
Grundsätzlich prüft das Spring-Framework vor der Ausführung der Methode, ob die Methodendaten bereits zwischengespeichert sind.
Wenn ja, werden sie abgerufen aus dem Cache Daten abrufen von.
Andernfalls wird die Methode ausgeführt und die Daten zwischengespeichert.
Es bietet auch eine Abstraktion zum Aktualisieren oder Löschen von Daten aus dem Cache.
In unserem aktuellen Blog erfahren wir, wie man Caching mit Caffeine hinzufügt, einer leistungsstarken, nahezu optimalen Caching-Bibliothek auf Basis von Java 8.
Sie können angeben, welcher Cache-Anbieter in der Datei application.yaml verwendet werden soll, indem Sie die Eigenschaft spring.cache.type festlegen. application.yaml 文件中指定使用哪个缓存提供程序来设置 spring.cache.type 属性。
但是,如果没有提供属性,Spring将根据添加的库自动检测缓存提供程序。
添加生成依赖项
现在假设您已经启动并运行了基本的Spring boot应用程序,让我们添加缓存依赖项。
打开 build.gradle 文件,并添加以下依赖项以启用Spring Boot的缓存
compile('org.springframework.boot:spring-boot-starter-cache')
接下来我们将添加对Caffeine的依赖
compile group: 'com.github.ben-manes.caffeine', name: 'caffeine', version: '2.8.5'
缓存配置
现在我们需要在Spring Boot应用程序中启用缓存。
为此,我们需要创建一个配置类并提供注释 @EnableCaching 。
@Configuration
@EnableCaching
public class CacheConfig {
}现在这个类是一个空类,但是我们可以向它添加更多配置(如果需要)。
现在我们已经启用了缓存,让我们提供缓存名称和缓存属性的配置,如缓存大小、缓存过期时间等
最简单的方法是在 application.yaml 中添加配置
spring:
cache:
cache-names: customers, users, roles
caffeine:
spec: maximumSize=500, expireAfterAccess=60s上述配置执行以下操作
将可用缓存名称限制为客户、用户和角色。将最大缓存大小设置为500。
当缓存中的对象数达到此限制时,将根据缓存逐出策略从缓存中删除对象。将缓存过期时间设置为1分钟。
这意味着项目将在添加到缓存1分钟后从缓存中删除。
还有另一种配置缓存的方法,而不是在 application.yaml 文件中配置缓存。
您可以在缓存配置类中添加并提供一个 CacheManager Bean,该Bean可以完成与上面在 application.yaml 中的配置完全相同的工作
@Bean
public CacheManager cacheManager() {
Caffeine<Object, Object> caffeineCacheBuilder =
Caffeine.newBuilder()
.maximumSize(500)
.expireAfterAccess(
1, TimeUnit.MINUTES);
CaffeineCacheManager cacheManager =
new CaffeineCacheManager(
"customers", "roles", "users");
cacheManager.setCaffeine(caffeineCacheBuilder);
return cacheManager;
}在我们的代码示例中,我们将使用Java配置。
我们可以在Java中做更多的事情,比如配置 RemovalListener ,当一个项从缓存中删除时执行 RemovalListener ,或者启用缓存统计记录,等等。
缓存方法结果
在我们使用的示例Spring boot应用程序中,我们已经有了以下API GET /API/v1/customer/{id} 来检索客户记录。
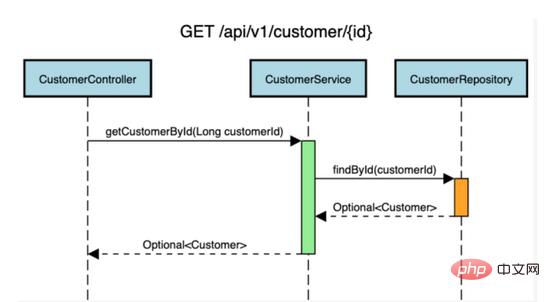
我们将向CustomerService类的 getCustomerByd(longCustomerId) 方法添加缓存。
要做到这一点,我们只需要做两件事
1. 将注释 @CacheConfig(cacheNames=“customers”) 添加到 CustomerService 类
提供此选项将确保 CustomerService
build.gradle und fügen Sie die folgenden Abhängigkeiten hinzu, um den Cache von Spring Boot zu aktivieren Aktivieren Sie das Caching in Boot-Anwendungen. 🎜🎜Dazu müssen wir eine Konfigurationsklasse erstellen und die Annotation @EnableCaching bereitstellen. 🎜@Service
@Log4j2
@CacheConfig(cacheNames = "customers")
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
@Cacheable
public Optional<Customer> getCustomerById(Long customerId) {
log.info("Fetching customer by id: {}", customerId);
return customerRepository.findById(customerId);
}
}application.yaml</ hinzuzufügen. Code> 🎜 <div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> 代码如下:log.info("Fetching customer by id: {}", customerId);</pre><div class="contentsignin">Nach dem Login kopieren</div></div><div class="contentsignin">Nach dem Login kopieren</div></div>🎜Die obige Konfiguration bewirkt Folgendes:🎜🎜🎜🎜Beschränkt die verfügbaren Cache-Namen auf Kunden, Benutzer und Rollen. Legen Sie die maximale Cachegröße auf 500 fest. 🎜🎜🎜🎜Wenn die Anzahl der Objekte im Cache diesen Grenzwert erreicht, werden die Objekte gemäß der Cache-Räumungsrichtlinie aus dem Cache entfernt. Legen Sie die Cache-Ablaufzeit auf 1 Minute fest. 🎜🎜🎜🎜Das bedeutet, dass der Artikel 1 Minute nach dem Hinzufügen zum Cache aus dem Cache entfernt wird. 🎜🎜🎜🎜Es gibt eine andere Möglichkeit, den Cache zu konfigurieren, anstatt den Cache in der Datei <code>application.yaml zu konfigurieren. 🎜🎜Sie können ein CacheManager-Bean in der Cache-Konfigurationsklasse hinzufügen und bereitstellen, das genau die gleiche Aufgabe wie die Konfiguration oben in application.yaml ausführen kann. 🎜@CachePut @cacheexecute
RemovalListener konfigurieren, RemovalListener ausführen, wenn ein Element aus dem Cache entfernt wird, oder die Protokollierung von Cache-Statistiken aktivieren usw. . 🎜🎜Ergebnisse der Cache-Methode🎜🎜In der Beispiel-Spring-Boot-Anwendung, die wir verwenden, verfügen wir bereits über die folgende API GET /API/v1/customer/{id} zum Abrufen von Kundendatensätzen. 🎜🎜🎜🎜Wir werden das anwenden CustomerService-Klasse Die Methode getCustomerByd(longCustomerId) fügt Caching hinzu. 🎜🎜Dazu müssen wir nur zwei Dinge tun🎜🎜1. Fügen Sie der Klasse CustomerService die Annotation @CacheConfig(cacheNames="customers") hinzu Diese Option stellt sicher, dass alle zwischenspeicherbaren Methoden von CustomerService den Cache-Namen „customers“ verwenden 🎜2. 向方法 Optional getCustomerById(Long customerId) 添加注释 @Cacheable
@Service
@Log4j2
@CacheConfig(cacheNames = "customers")
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
@Cacheable
public Optional<Customer> getCustomerById(Long customerId) {
log.info("Fetching customer by id: {}", customerId);
return customerRepository.findById(customerId);
}
}另外,在方法 getCustomerById() 中添加一个 LOGGER 语句,以便我们知道服务方法是否得到执行,或者值是否从缓存返回。
代码如下:log.info("Fetching customer by id: {}", customerId);测试缓存是否正常工作
这就是缓存工作所需的全部内容。现在是测试缓存的时候了。
启动您的应用程序,并点击客户获取url
http://localhost:8080/api/v1/customer/
在第一次API调用之后,您将在日志中看到以下行—“ Fetching customer by id ”。
但是,如果再次点击API,您将不会在日志中看到任何内容。这意味着该方法没有得到执行,并且从缓存返回客户记录。
现在等待一分钟(因为缓存过期时间设置为1分钟)。
一分钟后再次点击GETAPI,您将看到下面的语句再次被记录——“通过id获取客户”。
这意味着客户记录在1分钟后从缓存中删除,必须再次从数据库中获取。
为什么缓存有时会很危险
缓存更新/失效
通常我们缓存 GET 调用,以提高性能。
但我们需要非常小心的是缓存对象的更新/删除。
@CachePut @cacheexecute
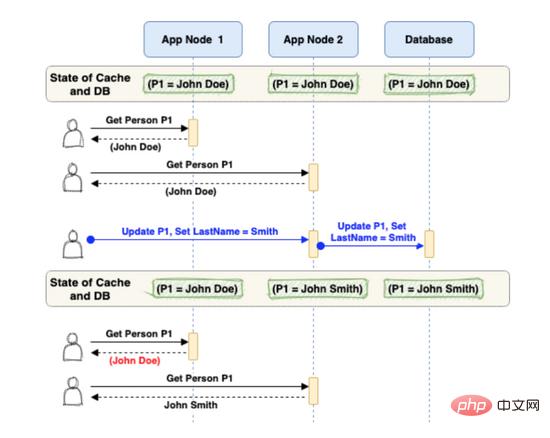
如果未将 @CachePut/@cacheexecute 放入更新/删除方法中,GET调用中缓存返回的对象将与数据库中存储的对象不同。考虑下面的示例场景。
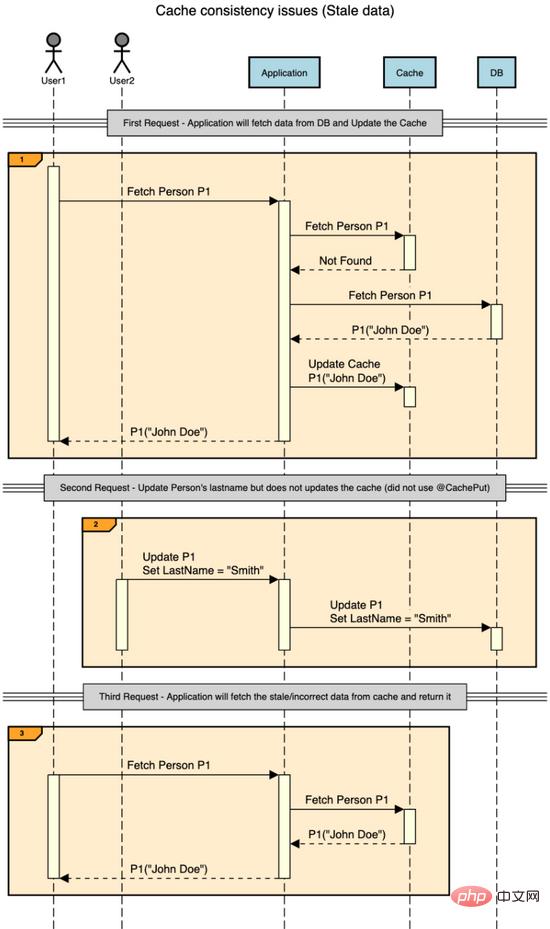
如您所见,第二个请求已将人名更新为“ John Smith ”。但由于它没有更新缓存,因此从此处开始的所有请求都将从缓存中获取过时的个人记录(“ John Doe ”),直到该项在缓存中被删除/更新。
缓存复制
大多数现代web应用程序通常有多个应用程序节点,并且在大多数情况下都有一个负载平衡器,可以将用户请求重定向到一个可用的应用程序节点。
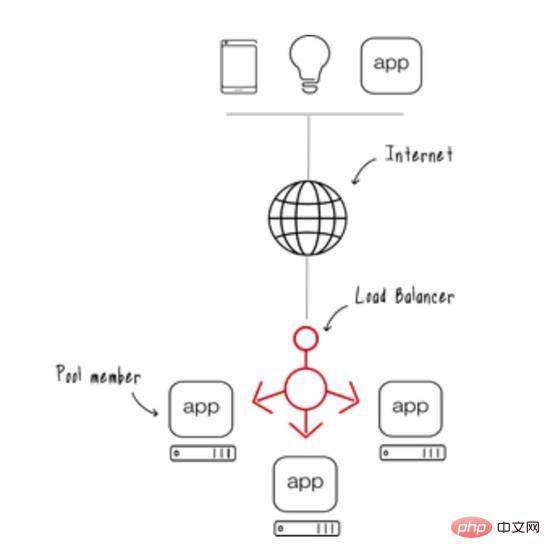
这种类型的部署为应用程序提供了可伸缩性,任何用户请求都可以由任何一个可用的应用程序节点提供服务。
在这些分布式环境(具有多个应用服务器节点)中,缓存可以通过两种方式实现
应用服务器中的嵌入式缓存(正如我们现在看到的)
远程缓存服务器
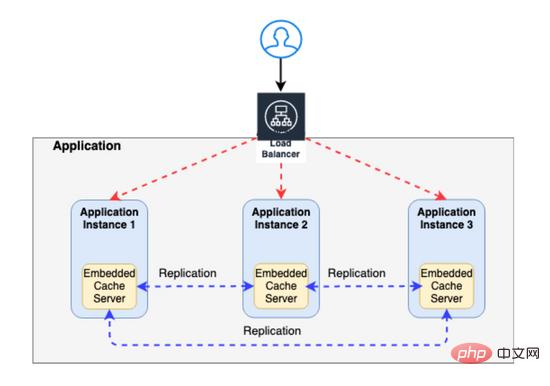
嵌入式缓存
嵌入式缓存驻留在应用程序服务器中,它随应用程序服务器启动/停止。由于每台服务器都有自己的缓存副本,因此对其缓存的任何更改/更新都不会自动反映在其他应用程序服务器的缓存中。
考虑具有嵌入式缓存的多节点应用服务器的下面场景,其中用户可以根据应用服务器为其请求服务而得到不同的结果。
正如您在上面的示例中所看到的,更新请求更新了 Application Node2 的数据库和嵌入式缓存。
但是, Application Node1 的嵌入式缓存未更新,并且包含过时数据。因此, Application Node1 的任何请求都将继续服务于旧数据。
要解决这个问题,您需要实现 CACHE REPLICATION —其中任何一个缓存中的任何更新都会自动复制到其他缓存(下图中显示为蓝色虚线)
远程缓存服务器
解决上述问题的另一种方法是使用远程缓存服务器(如下所示)。

然而,这种方法的最大缺点是增加了响应时间——这是由于从远程缓存服务器获取数据时的网络延迟(与内存缓存相比)
缓存自定义
到目前为止,我们看到的缓存示例是向应用程序添加基本缓存所需的唯一代码。
然而,现实世界的场景可能不是那么简单,可能需要进行一些定制。在本节中,我们将看到几个这样的例子
缓存密钥
我们知道缓存是密钥、值对的存储。
示例1:默认缓存键–具有单参数的方法
最简单的缓存键是当方法只有一个参数,并且该参数成为缓存键时。在下面的示例中, Long customerId 是缓存键

示例2:默认缓存键–具有多个参数的方法
在下面的示例中,缓存键是所有三个参数的SimpleKey– countryId 、 regionId 、 personId 。

示例3:自定义缓存密钥
在下面的示例中,我们将此人的 emailAddress 指定为缓存的密钥

示例4:使用 KeyGenerator 的自定义缓存密钥
让我们看看下面的示例–如果要缓存当前登录用户的所有角色,该怎么办。

该方法中没有提供任何参数,该方法在内部获取当前登录用户并返回其角色。
为了实现这个需求,我们需要创建一个如下所示的自定义密钥生成器

然后我们可以在我们的方法中使用这个键生成器,如下所示。

条件缓存
在某些用例中,我们只希望在满足某些条件的情况下缓存结果
示例1(支持 java.util.Optional –仅当存在时才缓存)
仅当结果中存在 person 对象时,才缓存 person 对象。
@Cacheable( value = "persons", unless = "#result?.id") public Optional<Person> getPerson(Long personId)
示例2(如果需要,by-pass缓存)
@Cacheable(value = "persons", condition="#fetchFromCache") public Optional<Person> getPerson(long personId, boolean fetchFromCache)
仅当方法参数“ fetchFromCache ”为true时,才从缓存中获取人员。通过这种方式,方法的调用方有时可以决定绕过缓存并直接从数据库获取值。
示例3(基于对象属性的条件计算)
仅当价格低于500且产品有库存时,才缓存产品。
@Cacheable( value="products", condition="#product.price<500", unless="#result.outOfStock") public Product findProduct(Product product)
@CachePut
我们已经看到 @Cacheable 用于将项目放入缓存。
但是,如果该对象被更新,并且我们想要更新缓存,该怎么办?
我们已经在前面的一节中看到,不更新缓存post任何更新操作都可能导致从缓存返回错误的结果。
@CachePut(key = "#person.id") public Person update(Person person)
但是如果 @Cacheable 和 @CachePut 都将一个项目放入缓存,它们之间有什么区别?
主要区别在于实际的方法执行
@Cacheable @CachePut
缓存失效
缓存失效与将对象放入缓存一样重要。
当我们想要从缓存中删除一个或多个对象时,有很多场景。让我们看一些例子。
例1
假设我们有一个用于批量导入个人记录的API。
我们希望在调用此方法之前,应该清除整个 person 缓存(因为大多数 person 记录可能会在导入时更新,而缓存可能会过时)。我们可以这样做如下
@CacheEvict( value = "persons", allEntries = true, beforeInvocation = true) public void importPersons()
例2
我们有一个Delete Person API,我们希望它在删除时也能从缓存中删除 Person 记录。
@CacheEvict( value = "persons", key = "#person.emailAddress") public void deletePerson(Person person)
默认情况下 @CacheEvict 在方法调用后运行。
Das obige ist der detaillierte Inhalt vonWie SpringBoot Caffeine verwendet, um Caching zu implementieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Wie Springboot Jasypt integriert, um die Verschlüsselung von Konfigurationsdateien zu implementieren
Jun 01, 2023 am 08:55 AM
Wie Springboot Jasypt integriert, um die Verschlüsselung von Konfigurationsdateien zu implementieren
Jun 01, 2023 am 08:55 AM
Einführung in Jasypt Jasypt ist eine Java-Bibliothek, die es einem Entwickler ermöglicht, seinem Projekt mit minimalem Aufwand grundlegende Verschlüsselungsfunktionen hinzuzufügen und kein tiefes Verständnis der Funktionsweise der Verschlüsselung erfordert. standardbasierte Verschlüsselungstechnologie. Passwörter, Text, Zahlen, Binärdateien verschlüsseln ... Geeignet für die Integration in Spring-basierte Anwendungen, offene API, zur Verwendung mit jedem JCE-Anbieter ... Fügen Sie die folgende Abhängigkeit hinzu: com.github.ulisesbocchiojasypt-spring-boot-starter2 Die Vorteile von Jasypt schützen unsere Systemsicherheit. Selbst wenn der Code durchgesickert ist, kann die Datenquelle garantiert werden.
 Wie SpringBoot Redisson integriert, um eine Verzögerungswarteschlange zu implementieren
May 30, 2023 pm 02:40 PM
Wie SpringBoot Redisson integriert, um eine Verzögerungswarteschlange zu implementieren
May 30, 2023 pm 02:40 PM
Nutzungsszenario 1. Die Bestellung wurde erfolgreich aufgegeben, die Zahlung erfolgte jedoch nicht innerhalb von 30 Minuten. Die Zahlung ist abgelaufen und die Bestellung wurde automatisch storniert. 2. Die Bestellung wurde unterzeichnet und es wurde 7 Tage lang keine Bewertung durchgeführt. Wenn die Bestellung abläuft und nicht ausgewertet wird, wird die Bestellung standardmäßig positiv bewertet. Wenn der Händler die Bestellung innerhalb von 5 Minuten nicht erhält, wird die Bestellung abgebrochen Es wird eine SMS-Erinnerung gesendet ... Für Szenarien mit langen Verzögerungen und geringer Echtzeitleistung können wir die Aufgabenplanung verwenden, um eine regelmäßige Abfrageverarbeitung durchzuführen. Zum Beispiel: xxl-job Heute werden wir auswählen
 So implementieren Sie verteilte Sperren mit Redis in SpringBoot
Jun 03, 2023 am 08:16 AM
So implementieren Sie verteilte Sperren mit Redis in SpringBoot
Jun 03, 2023 am 08:16 AM
1. Redis implementiert das Prinzip der verteilten Sperren und warum verteilte Sperren erforderlich sind. Bevor über verteilte Sperren gesprochen wird, muss erläutert werden, warum verteilte Sperren erforderlich sind. Das Gegenteil von verteilten Sperren sind eigenständige Sperren. Wenn wir Multithread-Programme schreiben, vermeiden wir Datenprobleme, die durch den gleichzeitigen Betrieb einer gemeinsam genutzten Variablen verursacht werden. Normalerweise verwenden wir eine Sperre, um die Richtigkeit der gemeinsam genutzten Variablen sicherzustellen Die gemeinsam genutzten Variablen liegen im gleichen Prozess. Wenn es mehrere Prozesse gibt, die gleichzeitig eine gemeinsam genutzte Ressource betreiben müssen, wie können sie sich dann gegenseitig ausschließen? Heutige Geschäftsanwendungen sind in der Regel Microservice-Architekturen, was auch bedeutet, dass eine Anwendung mehrere Prozesse bereitstellen muss. Wenn mehrere Prozesse dieselbe Datensatzzeile in MySQL ändern müssen, ist eine Verteilung erforderlich, um fehlerhafte Daten zu vermeiden wird zu diesem Zeitpunkt eingeführt. Der Stil ist gesperrt. Punkte erreichen wollen
 So lösen Sie das Problem, dass Springboot nach dem Einlesen in ein JAR-Paket nicht auf die Datei zugreifen kann
Jun 03, 2023 pm 04:38 PM
So lösen Sie das Problem, dass Springboot nach dem Einlesen in ein JAR-Paket nicht auf die Datei zugreifen kann
Jun 03, 2023 pm 04:38 PM
Springboot liest die Datei, kann aber nach dem Packen in ein JAR-Paket nicht auf die neueste Entwicklung zugreifen. Es gibt eine Situation, in der Springboot die Datei nach dem Packen in ein JAR-Paket nicht lesen kann ist ungültig und kann nur über den Stream gelesen werden. Die Datei befindet sich unter resources publicvoidtest(){Listnames=newArrayList();InputStreamReaderread=null;try{ClassPathResourceresource=newClassPathResource("name.txt");Input
 So implementieren Sie Springboot+Mybatis-plus, ohne SQL-Anweisungen zum Hinzufügen mehrerer Tabellen zu verwenden
Jun 02, 2023 am 11:07 AM
So implementieren Sie Springboot+Mybatis-plus, ohne SQL-Anweisungen zum Hinzufügen mehrerer Tabellen zu verwenden
Jun 02, 2023 am 11:07 AM
Wenn Springboot + Mybatis-plus keine SQL-Anweisungen zum Hinzufügen mehrerer Tabellen verwendet, werden die Probleme, auf die ich gestoßen bin, durch die Simulation des Denkens in der Testumgebung zerlegt: Erstellen Sie ein BrandDTO-Objekt mit Parametern, um die Übergabe von Parametern an den Hintergrund zu simulieren dass es äußerst schwierig ist, Multi-Table-Operationen in Mybatis-plus durchzuführen. Wenn Sie keine Tools wie Mybatis-plus-join verwenden, können Sie nur die entsprechende Mapper.xml-Datei konfigurieren und die stinkende und lange ResultMap konfigurieren Schreiben Sie die entsprechende SQL-Anweisung. Obwohl diese Methode umständlich erscheint, ist sie äußerst flexibel und ermöglicht es uns
 Wie SpringBoot Redis anpasst, um die Cache-Serialisierung zu implementieren
Jun 03, 2023 am 11:32 AM
Wie SpringBoot Redis anpasst, um die Cache-Serialisierung zu implementieren
Jun 03, 2023 am 11:32 AM
1. Passen Sie den RedisTemplate1.1-Standard-Serialisierungsmechanismus an. Die API-basierte Redis-Cache-Implementierung verwendet die RedisTemplate-Vorlage für Daten-Caching-Vorgänge. Öffnen Sie hier die RedisTemplate-Klasse und zeigen Sie die Quellcodeinformationen der Klasse publicclassRedisTemplateextendsRedisAccessorimplementsRedisOperations an. Schlüssel deklarieren, verschiedene Serialisierungsmethoden des Werts, der Anfangswert ist leer @NullableprivateRedisSe
 Vergleich und Differenzanalyse zwischen SpringBoot und SpringMVC
Dec 29, 2023 am 11:02 AM
Vergleich und Differenzanalyse zwischen SpringBoot und SpringMVC
Dec 29, 2023 am 11:02 AM
SpringBoot und SpringMVC sind beide häufig verwendete Frameworks in der Java-Entwicklung, es gibt jedoch einige offensichtliche Unterschiede zwischen ihnen. In diesem Artikel werden die Funktionen und Verwendungsmöglichkeiten dieser beiden Frameworks untersucht und ihre Unterschiede verglichen. Lassen Sie uns zunächst etwas über SpringBoot lernen. SpringBoot wurde vom Pivotal-Team entwickelt, um die Erstellung und Bereitstellung von Anwendungen auf Basis des Spring-Frameworks zu vereinfachen. Es bietet eine schnelle und einfache Möglichkeit, eigenständige, ausführbare Dateien zu erstellen
 So erhalten Sie den Wert in application.yml in Springboot
Jun 03, 2023 pm 06:43 PM
So erhalten Sie den Wert in application.yml in Springboot
Jun 03, 2023 pm 06:43 PM
In Projekten werden häufig einige Konfigurationsinformationen benötigt. Diese Informationen können in der Testumgebung und in der Produktionsumgebung unterschiedliche Konfigurationen haben und müssen möglicherweise später basierend auf den tatsächlichen Geschäftsbedingungen geändert werden. Wir können diese Konfigurationen nicht fest im Code codieren. Am besten schreiben Sie sie in die Konfigurationsdatei. Sie können diese Informationen beispielsweise in die Datei application.yml schreiben. Wie erhält oder verwendet man diese Adresse im Code? Es gibt 2 Methoden. Methode 1: Wir können den Wert, der dem Schlüssel in der Konfigurationsdatei (application.yml) entspricht, über den mit @Value versehenen Wert erhalten. Diese Methode eignet sich für Situationen, in denen es relativ wenige Mikrodienste gibt: Tatsächlich Projekte, wenn das Geschäft kompliziert ist, Logik
