
 Technologie-Peripheriegeräte
KI
Steuerung eines doppelgelenkigen Roboterarms mit dem DDPG-Lernalgorithmus von Actor-Critic
Technologie-Peripheriegeräte
KI
Steuerung eines doppelgelenkigen Roboterarms mit dem DDPG-Lernalgorithmus von Actor-Critic
Steuerung eines doppelgelenkigen Roboterarms mit dem DDPG-Lernalgorithmus von Actor-Critic

In diesem Artikel stellen wir das Training eines intelligenten Agenten zur Steuerung eines zweigelenkigen Roboterarms in der Reacher-Umgebung vor, einem Unity-basierten Simulationsprogramm, das mit dem Unity ML-Agents-Toolkit entwickelt wurde. Unser Ziel ist es, die Zielposition mit hoher Genauigkeit zu erreichen. Daher können wir hier den hochmodernen Deep Deterministic Policy Gradient (DDPG)-Algorithmus verwenden, der für kontinuierliche Zustands- und Aktionsräume entwickelt wurde.

Anwendungen in der realen Welt
Roboterarme spielen in der Fertigung, in Produktionsanlagen, bei der Erforschung des Weltraums sowie bei Such- und Rettungseinsätzen eine Schlüsselrolle . Es ist sehr wichtig, den Roboterarm mit hoher Präzision und Flexibilität zu steuern. Durch den Einsatz von Reinforcement-Learning-Techniken können diese Robotersysteme in die Lage versetzt werden, ihr Verhalten in Echtzeit zu lernen und anzupassen, wodurch Leistung und Flexibilität verbessert werden. Fortschritte beim Reinforcement Learning tragen nicht nur zu unserem Verständnis der künstlichen Intelligenz bei, sondern haben auch das Potenzial, Branchen zu revolutionieren und einen bedeutenden Einfluss auf die Gesellschaft zu haben.
Reacher ist ein Roboterarmsimulator, der häufig für die Entwicklung und das Testen von Steuerungsalgorithmen verwendet wird. Es bietet eine virtuelle Umgebung, die die physikalischen Eigenschaften und Bewegungsgesetze des Roboterarms simuliert und es Entwicklern ermöglicht, Forschung und Experimente zu Steuerungsalgorithmen durchzuführen, ohne dass tatsächliche Hardware erforderlich ist.
Reachers Umgebung besteht hauptsächlich aus den folgenden Teilen:
- Roboterarm: Reacher simuliert einen doppelgelenkigen Roboterarm, einschließlich einer festen Basis und zwei beweglichen Gelenken. Entwickler können die Haltung und Position des Roboterarms ändern, indem sie seine beiden Gelenke steuern.
- Zielpunkt: Innerhalb des Bewegungsbereichs des Roboterarms stellt Reacher einen Zielpunkt bereit und die Position des Zielpunkts wird zufällig generiert. Die Aufgabe des Entwicklers besteht darin, den Roboterarm so zu steuern, dass das Ende des Roboterarms den Zielpunkt berühren kann.
- Physik-Engine: Reacher verwendet eine Physik-Engine, um die physikalischen Eigenschaften und Bewegungsmuster des Roboterarms zu simulieren. Entwickler können verschiedene physische Umgebungen simulieren, indem sie die Parameter der Physik-Engine anpassen.
- Visuelle Schnittstelle: Reacher bietet eine visuelle Schnittstelle, die die Positionen des Roboterarms und Zielpunkte sowie die Haltung und Bewegungsbahn des Roboterarms anzeigen kann. Entwickler können Steuerungsalgorithmen über eine visuelle Schnittstelle debuggen und optimieren.
Der Reacher-Simulator ist ein sehr praktisches Tool, das Entwicklern helfen kann, Steuerungsalgorithmen schnell zu testen und zu optimieren, ohne dass tatsächliche Hardware erforderlich ist.
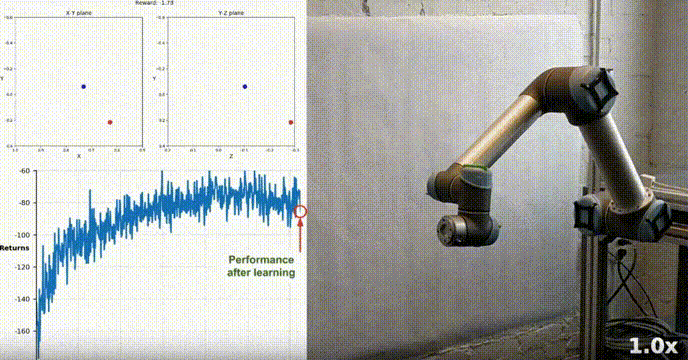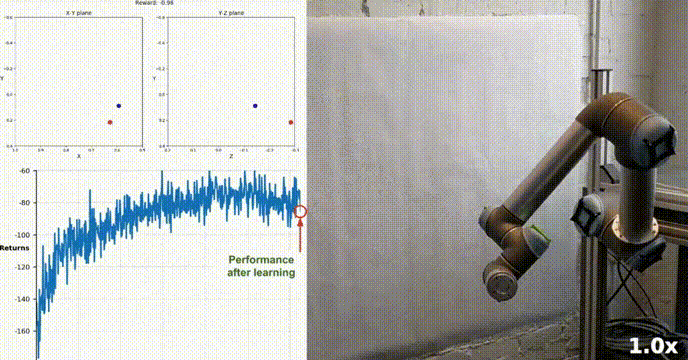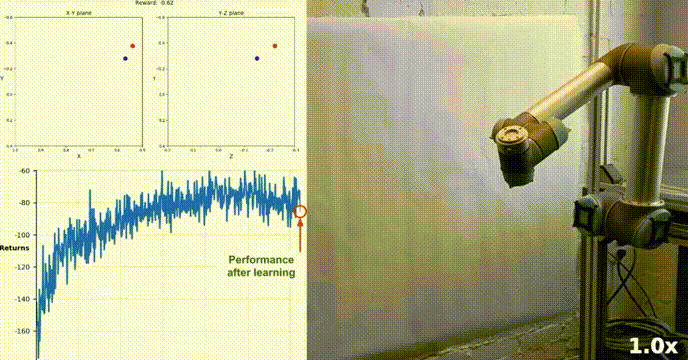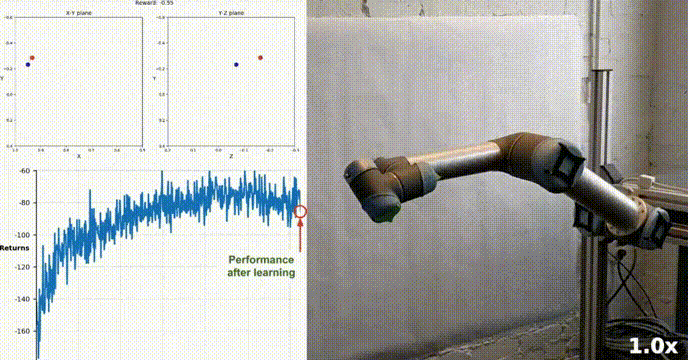
Simulationsumgebung
Reacher wurde mit dem Unity ML-Agents-Toolkit erstellt. Unser Agent kann einen Roboter mit zwei Gelenken steuern Arm. Ziel ist es, den Arm zur Zielposition zu führen und diese möglichst lange im Zielbereich zu halten. Die Umgebung verfügt über 20 synchronisierte Agenten, die jeweils unabhängig voneinander laufen, was dazu beiträgt, während des Trainings effizient Erfahrungen zu sammeln.

Zustands- und Aktionsraum
Zustands- und Aktionsraum zu verstehen ist eine wirksame Verbesserung für Das Design von Lernalgorithmen ist von entscheidender Bedeutung. In der Reacher-Umgebung besteht der Zustandsraum aus 33 kontinuierlichen Variablen, die Informationen über den Roboterarm liefern, beispielsweise seine Position, Rotation, Geschwindigkeit und Winkelgeschwindigkeit. Auch der Aktionsraum ist kontinuierlich, wobei vier Variablen den auf die beiden Gelenke des Roboterarms ausgeübten Drehmomenten entsprechen. Jede Aktionsvariable ist eine reelle Zahl zwischen -1 und 1.
Aufgabentypen und Erfolgskriterien
Reacher-Aufgaben gelten als episodisch, wobei jedes Fragment eine feste Anzahl von Zeitschritten enthält. Das Ziel des Agenten besteht darin, während dieser Schritte seine Gesamtvergütung zu maximieren. Der Armendeffektor erhält einen Bonus von +0,1 für jeden Schritt, den er braucht, um die Zielposition beizubehalten. Als Erfolg gilt, wenn ein Agent bei über 100 aufeinanderfolgenden Vorgängen eine durchschnittliche Punktzahl von 30 oder mehr erreicht.
Um die Umgebung zu verstehen, werden wir im Folgenden den DDPG-Algorithmus, seine Implementierung und wie er kontinuierliche Steuerungsprobleme in dieser Umgebung effektiv löst, untersuchen.
Algorithmusauswahl für kontinuierliche Steuerung: DDPG
Wenn es um kontinuierliche Steuerungsaufgaben wie das Reacher-Problem geht, ist die Wahl des Algorithmus entscheidend für die Erzielung einer optimalen Leistung. In diesem Projekt haben wir uns für den DDPG-Algorithmus entschieden, da es sich um eine akteurskritische Methode handelt, die speziell für die Verarbeitung kontinuierlicher Zustands- und Aktionsräume entwickelt wurde.
Der DDPG-Algorithmus vereint die Vorteile richtlinienbasierter und wertbasierter Ansätze, indem er zwei neuronale Netze kombiniert: Das Akteursnetzwerk bestimmt das beste Verhalten angesichts des aktuellen Zustands und das Kritikernetzwerk (Critic Network) schätzt die Zustands-Verhaltenswert-Funktion (Q-Funktion). Beide Arten von Netzwerken verfügen über Zielnetzwerke, die den Lernprozess stabilisieren, indem sie während des Aktualisierungsprozesses ein festes Ziel bereitstellen.
Durch die Verwendung des Critic-Netzwerks zur Schätzung der q-Funktion und des Actor-Netzwerks zur Bestimmung des optimalen Verhaltens kombiniert der DDPG-Algorithmus effektiv die Vorteile der Policy-Gradienten-Methode und des DQN. Dieser hybride Ansatz ermöglicht es Agenten, in einer kontinuierlichen Kontrollumgebung effizient zu lernen.
<code>import random from collections import deque import torch import torch.nn as nn import numpy as np from actor_critic import Actor, Critic class ReplayBuffer: def __init__(self, buffer_size, batch_size): self.memory = deque(maxlen=buffer_size) self.batch_size = batch_size def add(self, state, action, reward, next_state, done): self.memory.append((state, action, reward, next_state, done)) def sample(self): batch = random.sample(self.memory, self.batch_size) states, actions, rewards, next_states, dones = zip(*batch) return states, actions, rewards, next_states, dones def __len__(self): return len(self.memory) class DDPG: def __init__(self, state_dim, action_dim, hidden_dim, buffer_size, batch_size, actor_lr, critic_lr, tau, gamma): self.actor = Actor(state_dim, hidden_dim, action_dim, actor_lr) self.actor_target = Actor(state_dim, hidden_dim, action_dim, actor_lr) self.critic = Critic(state_dim, action_dim, hidden_dim, critic_lr) self.critic_target = Critic(state_dim, action_dim, hidden_dim, critic_lr) self.memory = ReplayBuffer(buffer_size, batch_size) self.batch_size = batch_size self.tau = tau self.gamma = gamma self._update_target_networks(tau=1)# initialize target networks def act(self, state, noise=0.0): state = torch.tensor(state, dtype=torch.float32).unsqueeze(0) action = self.actor(state).detach().numpy()[0] return np.clip(action + noise, -1, 1) def store_transition(self, state, action, reward, next_state, done): self.memory.add(state, action, reward, next_state, done) def learn(self): if len(self.memory) </code>
Der obige Code verwendet auch Replay Buffer, was die Lerneffizienz und Stabilität verbessern kann. Der Wiederholungspuffer ist im Wesentlichen eine Speicherdatenstruktur, die eine feste Anzahl vergangener Erfahrungen oder Übergänge speichert, bestehend aus Status-, Aktions-, Belohnungs-, nächsten Status- und Abschlussinformationen. Der Hauptvorteil seiner Verwendung besteht darin, dass der Agent Korrelationen zwischen aufeinanderfolgenden Erfahrungen aufbrechen und so die Auswirkungen schädlicher zeitlicher Korrelationen verringern kann.
Durch das Ziehen zufälliger Mini-Erfahrungsmengen aus dem Puffer kann der Agent aus einem anderen Satz von Transformationen lernen, was zur Stabilisierung und Verallgemeinerung des Lernprozesses beiträgt. Replay Buffers ermöglichen es Agenten außerdem, frühere Erfahrungen mehrfach wiederzuverwenden, wodurch die Dateneffizienz erhöht und effektiveres Lernen aus begrenzten Interaktionen mit der Umgebung gefördert wird.
Der DDPG-Algorithmus ist eine gute Wahl, da er kontinuierliche Aktionsräume effizient verarbeiten kann, was in dieser Umgebung ein Schlüsselaspekt ist. Das Design des Algorithmus ermöglicht eine effiziente Nutzung der von mehreren Agenten gesammelten parallelen Erfahrungen, was zu schnellerem Lernen und besserer Konvergenz führt. Genau wie der oben vorgestellte Reacher kann er 20 Agenten gleichzeitig ausführen, sodass wir diese 20 Agenten verwenden können, um Erfahrungen auszutauschen, gemeinsam zu lernen und die Lerngeschwindigkeit zu erhöhen.
Der Algorithmus ist fertig. Als nächstes stellen wir den Hyperparameter-Auswahl- und Trainingsprozess vor.
Der DDPG-Algorithmus funktioniert in der Reacher-Umgebung
Um die Wirksamkeit des Algorithmus in der Umgebung besser zu verstehen, müssen wir uns die Schlüsselkomponenten und Schritte des Lernprozesses genauer ansehen.
Netzwerkarchitektur
DDPG-Algorithmus verwendet zwei neuronale Netze, Akteur und Kritiker. Beide Netzwerke enthalten zwei verborgene Schichten mit jeweils 400 Knoten. Die verborgene Schicht verwendet die ReLU-Aktivierungsfunktion (Rectified Linear Unit), während die Ausgabeschicht des Actor-Netzwerks die Tanh-Aktivierungsfunktion verwendet, um Aktionen im Bereich von -1 bis 1 zu generieren. Die Ausgabeschicht des kritischen Netzwerks hat keine Aktivierungsfunktion, da sie die q-Funktion direkt schätzt.
Das Folgende ist der Code des Netzwerks:
<code>import numpy as np import torch import torch.nn as nn import torch.optim as optim class Actor(nn.Module): def __init__(self, input_dim, hidden_dim, output_dim, learning_rate=1e-4): super(Actor, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, output_dim) self.tanh = nn.Tanh() self.optimizer = optim.Adam(self.parameters(), lr=learning_rate) def forward(self, state): x = torch.relu(self.fc1(state)) x = torch.relu(self.fc2(x)) x = self.tanh(self.fc3(x)) return x class Critic(nn.Module): def __init__(self, state_dim, action_dim, hidden_dim, learning_rate=1e-4): super(Critic, self).__init__() self.fc1 = nn.Linear(state_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim + action_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, 1) self.optimizer = optim.Adam(self.parameters(), lr=learning_rate) def forward(self, state, action): x = torch.relu(self.fc1(state)) x = torch.relu(self.fc2(torch.cat([x, action], dim=1))) x = self.fc3(x) return x</code>
Hyperparameterauswahl
Die ausgewählten Hyperparameter sind entscheidend für effizientes Lernen. In diesem Projekt beträgt die Größe unseres Wiedergabepuffers 200.000 und die Stapelgröße 256. Die Lernrate von Actor beträgt 5e-4, die Lernrate von Critic beträgt 1e-3, der Soft-Update-Parameter (Tau) beträgt 5e-3 und Gamma beträgt 0,995. Schließlich wurde Aktionsgeräusch mit einer anfänglichen Geräuschskala von 0,5 und einer Geräuschdämpfungsrate von 0,998 hinzugefügt.
Trainingsprozess
Der Trainingsprozess beinhaltet eine kontinuierliche Interaktion zwischen den beiden Netzwerken, und mit 20 parallelen Agenten, die sich dasselbe Netzwerk teilen, lernt das Modell gemeinsam aus den von allen Agenten gesammelten Erfahrungen. Dieses Setup beschleunigt den Lernprozess und erhöht die Effizienz.
<code>from collections import deque import numpy as np import torch from ddpg import DDPG def train_ddpg(env, agent, episodes, max_steps, num_agents, noise_scale=0.1, noise_decay=0.99): scores_window = deque(maxlen=100) scores = [] for episode in range(1, episodes + 1): env_info = env.reset(train_mode=True)[brain_name] states = env_info.vector_observations agent_scores = np.zeros(num_agents) for step in range(max_steps): actions = agent.act(states, noise_scale) env_info = env.step(actions)[brain_name] next_states = env_info.vector_observations rewards = env_info.rewards dones = env_info.local_done for i in range(num_agents): agent.store_transition(states[i], actions[i], rewards[i], next_states[i], dones[i]) agent.learn() states = next_states agent_scores += rewards noise_scale *= noise_decay if np.any(dones): break avg_score = np.mean(agent_scores) scores_window.append(avg_score) scores.append(avg_score) if episode % 10 == 0: print(f"Episode: {episode}, Score: {avg_score:.2f}, Avg Score: {np.mean(scores_window):.2f}") # Saving trained Networks torch.save(agent.actor.state_dict(), "actor_final.pth") torch.save(agent.critic.state_dict(), "critic_final.pth") return scores if __name__ == "__main__": env = UnityEnvironment(file_name='Reacher_20.app') brain_name = env.brain_names[0] brain = env.brains[brain_name] state_dim = 33 action_dim = brain.vector_action_space_size num_agents = 20 # Hyperparameter suggestions hidden_dim = 400 batch_size = 256 actor_lr = 5e-4 critic_lr = 1e-3 tau = 5e-3 gamma = 0.995 noise_scale = 0.5 noise_decay = 0.998 agent = DDPG(state_dim, action_dim, hidden_dim=hidden_dim, buffer_size=200000, batch_size=batch_size,actor_lr=actor_lr, critic_lr=critic_lr, tau=tau, gamma=gamma) episodes = 200 max_steps = 1000 scores = train_ddpg(env, agent, episodes, max_steps, num_agents, noise_scale=0.2, noise_decay=0.995)</code>Die wichtigsten Schritte im Trainingsprozess sind wie folgt:
Netzwerk initialisieren: Der Agent initialisiert die gemeinsam genutzten Akteur- und Kritikernetzwerke und ihre jeweiligen Zielnetzwerke mit zufälligen Gewichtungen. Das Zielnetzwerk stellt bei Aktualisierungen stabile Lernziele bereit.
- Interaktion mit der Umgebung: Jeder Agent nutzt ein gemeinsames Akteurnetzwerk, um mit der Umgebung zu interagieren, indem er Aktionen basierend auf seinem aktuellen Zustand auswählt. Um die Erkundung zu fördern, wird den Aktionen in der Anfangsphase des Trainings auch ein Geräuschbegriff hinzugefügt. Nachdem er eine Aktion ausgeführt hat, beobachtet jeder Agent die resultierende Belohnung und den nächsten Zustand.
- Erfahrung speichern: Jeder Agent speichert die beobachtete Erfahrung (Zustand, Aktion, Belohnung, nächster_Zustand) in einem gemeinsamen Wiedergabepuffer. Dieser Puffer enthält eine feste Menge aktueller Erfahrungen, sodass jeder Agent aus verschiedenen von allen Agenten gesammelten Übergängen lernen kann.
- Aus Erfahrung lernen: Ziehen Sie regelmäßig eine Reihe von Erfahrungen aus dem gemeinsamen Wiedergabepuffer. Nutzen Sie die Sampling-Erfahrung, um das gemeinsame Kritikernetzwerk zu aktualisieren, indem Sie den mittleren quadratischen Fehler zwischen dem vorhergesagten Q-Wert und dem Ziel-Q-Wert minimieren.
- Akteurnetzwerk aktualisieren: Das gemeinsam genutzte Akteurnetzwerk wird mithilfe des Richtliniengradienten aktualisiert, der berechnet wird, indem der Ausgabegradient des gemeinsam genutzten kritischen Netzwerks in Bezug auf die ausgewählte Aktion verwendet wird. Das Shared-Actor-Netzwerk lernt, Aktionen auszuwählen, die den erwarteten Q-Wert maximieren.
- Zielnetzwerk aktualisieren: Die gemeinsam genutzten Akteur- und Kritiker-Zielnetzwerke werden mithilfe einer Mischung aus aktuellen und Zielnetzwerkgewichten sanft aktualisiert. Dies gewährleistet einen stabilen Lernprozess.
Ergebnisanzeige
Unser Agent hat erfolgreich gelernt, einen doppelgelenkigen Roboterarm in der Racher-Umgebung mithilfe des DDPG-Algorithmus zu steuern. Während des gesamten Schulungsprozesses überwachen wir die Leistung des Agenten anhand der durchschnittlichen Punktzahl aller 20 Agenten. Während der Agent die Umgebung erkundet und Erfahrungen sammelt, verbessert sich seine Fähigkeit, optimales Verhalten zur Belohnungsmaximierung vorherzusagen, erheblich.
Es ist ersichtlich, dass der Agent eine erhebliche Kompetenz bei der Aufgabe zeigte, wobei die durchschnittliche Punktzahl den zum Lösen der Umgebung erforderlichen Schwellenwert (30+) überstieg, obwohl die Leistung des Agenten während des gesamten Schulungsprozesses unterschiedlich war nach oben, was darauf hinweist, dass der Lernprozess erfolgreich war.
Die Grafik unten zeigt die durchschnittliche Punktzahl von 20 Agenten:
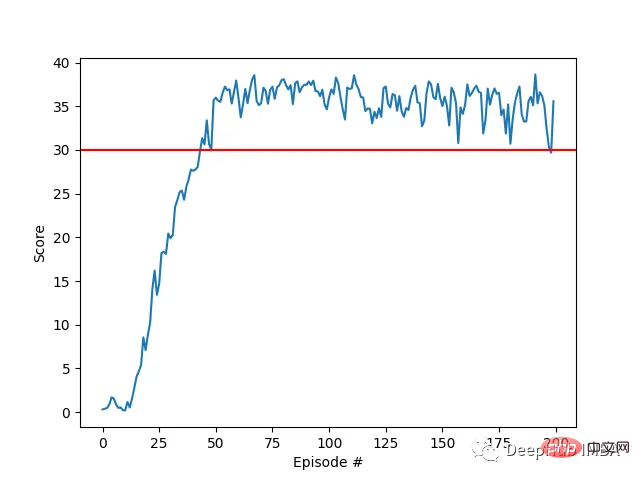
Sie können sehen, dass der von uns implementierte DDPG-Algorithmus das Problem der Racher-Umgebung effektiv gelöst hat. Agenten sind in der Lage, ihr Verhalten anzupassen und die erwartete Leistung bei Aufgaben zu erreichen.
Nächste Schritte
Die Hyperparameter in diesem Projekt wurden auf der Grundlage einer Kombination aus Empfehlungen aus der Literatur und empirischen Tests ausgewählt. Eine weitere Optimierung durch System-Hyperparameter-Tuning kann zu einer besseren Leistung führen.
Multi-Agenten-Paralleltraining: In diesem Projekt nutzen wir 20 Agenten, um gleichzeitig Erfahrungen zu sammeln. Die Auswirkung der Verwendung von mehr Agenten auf den gesamten Lernprozess kann zu einer schnelleren Konvergenz oder einer verbesserten Leistung führen.
Batch-Normalisierung: Um den Lernprozess weiter zu verbessern, lohnt es sich, die Implementierung der Batch-Normalisierung in neuronalen Netzwerkarchitekturen zu untersuchen. Durch die Normalisierung der Eingabemerkmale jeder Schicht während des Trainings kann die Batch-Normalisierung dazu beitragen, interne Kovariatenverschiebungen zu reduzieren, das Lernen zu beschleunigen und möglicherweise die Generalisierung zu verbessern. Das Hinzufügen einer Batch-Normalisierung zu den Netzwerken „Akteur“ und „Kritiker“ kann zu einem stabileren und effizienteren Training führen, erfordert jedoch weitere Tests.
Das obige ist der detaillierte Inhalt vonSteuerung eines doppelgelenkigen Roboterarms mit dem DDPG-Lernalgorithmus von Actor-Critic. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
