
 Technologie-Peripheriegeräte
KI
Transformer schlägt Diffusion erneut! Google veröffentlicht Muse, eine neue Generation eines Text-Bild-Generierungsmodells: Die Generierungseffizienz wurde verzehnfacht
Technologie-Peripheriegeräte
KI
Transformer schlägt Diffusion erneut! Google veröffentlicht Muse, eine neue Generation eines Text-Bild-Generierungsmodells: Die Generierungseffizienz wurde verzehnfacht
Transformer schlägt Diffusion erneut! Google veröffentlicht Muse, eine neue Generation eines Text-Bild-Generierungsmodells: Die Generierungseffizienz wurde verzehnfacht

Vor kurzem hat Google ein neues Text-Bild-Generierungsmodell veröffentlicht. Es verwendet nicht das derzeit beliebte Diffusionsmodell, sondern das klassische Transformer-Modell, um die fortschrittlichste Bildgenerierungsleistung zu erzielen Die Effizienz des autoregressiven Modells und des Muse-Modells wurde ebenfalls erheblich verbessert.

Papierlink: https://arxiv.org/pdf/2301.00704.pdf
Projektlink: https://muse-model.github.io/
Muse wird auf einem diskreten Token-Raum mit einer maskierten Modellierungsaufgabe trainiert: Bei gegebenen Texteinbettungen, die aus einem vorab trainierten großen Sprachmodell (LLM) extrahiert wurden, besteht der Trainingsprozess von Muse darin, zufällig maskierte Bild-Tokens vorherzusagen.
Im Vergleich zu Pixelraumdiffusionsmodellen (wie Imagen und DALL-E 2) erfordert Muse nur weniger Abtastiterationen, sodass die Effizienz erheblich verbessert wird.
Mit autoregressiven Modellen verglichen (wie Parti) ist Muse effizienter, da es parallele Decodierung verwendet.

Durch die Verwendung von vorab trainiertem LLM kann ein feinkörniges Sprachverständnis erreicht werden, das sich in einer hochauflösenden Bilderzeugung und einem Verständnis visueller Konzepte wie Objekten, räumlichen Beziehungen, Körperhaltungen, Kardinalität usw. niederschlägt.
In den experimentellen Ergebnissen erreichte das Muse-Modell mit nur 900 Millionen Parametern eine neue SOTA-Leistung auf CC3M mit einem FID-Score von 6,06.
Das parametrische Modell Muse 3B erreichte in der Zero-Shot-COCO-Bewertung einen FID von 7,88 und erreichte gleichzeitig einen CLIP-Score von 0,32.

Muse kann einige Bildbearbeitungsanwendungen auch direkt implementieren, ohne das Modell fein abzustimmen oder umzukehren: Inpainting, Outpainting und maskenfreie Bearbeitung.
Muse-Modell
Das Framework des Muse-Modells enthält mehrere Komponenten. Die Trainingspipeline besteht aus einem vorab trainierten T5-XXL-Text-Encoder, einem Basismodell und einem Superauflösungsmodell.
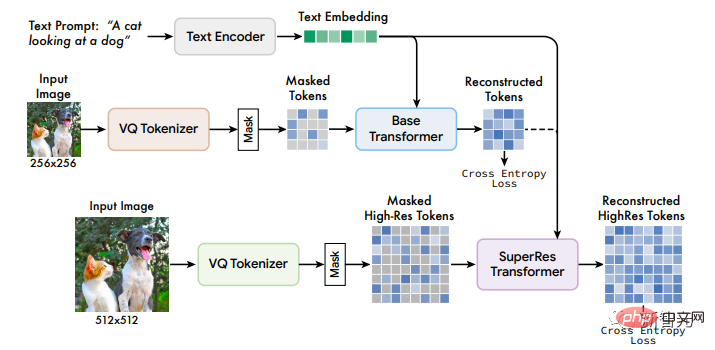
1. Vorab trainierter Textencoder
Ähnlich wie in früheren Studien fanden Forscher heraus, dass die Verwendung vorab trainierter großer Sprachmodelle (LLM) zur Verbesserung der hohen Qualität beiträgt Ergebnisse der Bildgenerierung.
Zum Beispiel enthält die aus dem Sprachmodell T5-XXL extrahierte Einbettung Informationen über Objekte (Substantive), Aktionen (Verben), visuelle Attribute (Adjektive), räumliche Beziehungen (Präpositionen) und andere Attribute (wie Kardierbarkeit und Zusammensetzung) reichhaltige Informationen.
Daher stellen die Forscher eine Hypothese auf: Das Muse-Modell lernt, diese reichhaltigen visuellen und semantischen Konzepte in den LLM-Einbettungen auf die generierten Bilder abzubilden.
Einige neuere Arbeiten haben gezeigt, dass die von LLM gelernte konzeptionelle Darstellung und die von dem auf die visuelle Aufgabe trainierten Modell gelernte konzeptionelle Darstellung grob „linear abgebildet“ werden können.
Bei einem Eingabetexttitel führt die Übergabe an den T5-XXL-Encoder mit eingefrorenen Parametern zu einem 4096-dimensionalen Spracheinbettungsvektor. Diese Vektoren werden dann linear auf das Transformer-Modell projiziert (Basis- und Superauflösungsrate). ) in der verborgenen Größendimension.
2. Verwenden Sie VQGAN für die semantische Tokenisierung
Das VQGAN-Modell besteht aus einem Encoder und einem Decoder, wobei die Quantisierungsschicht das Eingabebild aus einer erlernten Codebuchsequenz in ein Token abbildet.
Dann sind Encoder und Decoder vollständig aus Faltungsschichten aufgebaut, um die Codierung von Bildern unterschiedlicher Auflösung zu unterstützen.
Der Encoder enthält mehrere Downsampling-Blöcke, um die räumliche Dimension der Eingabe zu reduzieren, während der Decoder über eine entsprechende Anzahl von Upsampling-Blöcken verfügt, um die Latentdaten wieder auf die ursprüngliche Bildgröße abzubilden.
Die Forscher trainierten zwei VQGAN-Modelle: eines mit einer Downsampling-Rate f=16, und das Modell erhielt die Beschriftungen des Basismodells auf einem Bild von 256×256 Pixeln, was zu einer Beschriftung mit einer räumlichen Größe von 16× führte 16; der andere Es ist die Downsampling-Rate f = 8, und das Token des Superauflösungsmodells wird auf dem 512 × 512-Bild erhalten, und die entsprechende räumliche Größe beträgt 64 × 64.
Das nach der Codierung erhaltene diskrete Token kann die High-Level-Semantik des Bildes erfassen und gleichzeitig Low-Level-Rauschen eliminieren. Basierend auf der Diskretion des Tokens kann Kreuzentropieverlust am Ausgabeende verwendet werden Sagen Sie das maskierte Token in der nächsten Stufe voraus Setzen Sie alle Texteinbettungen auf unmaskiert. Nachdem Sie einen Teil verschiedener Bild-Tokens zufällig ausgeblendet haben, verwenden Sie eine spezielle [MASK]-Markierung, um das Original-Token zu ersetzen.
Dann wird das Bild-Token linear der erforderlichen Transformer-Eingabe oder versteckten Größe zugeordnet Dimensionieren Sie die Bildeingabeeinbettung und lernen Sie gleichzeitig die 2D-PositionseinbettungDasselbe wie die ursprüngliche Transformer-Architektur, einschließlich mehrerer Transformer-Ebenen, wobei Selbstaufmerksamkeitsblöcke, Queraufmerksamkeitsblöcke und MLP-Blöcke zum Extrahieren von Merkmalen verwendet werden.
Verwenden Sie in der Ausgabeschicht einen MLP, um jede maskierte Bildeinbettung in einen Satz von Logits umzuwandeln (entsprechend der Größe des VQGAN-Codebuchs) und verwenden Sie Kreuzentropieverlust, um das Ground-Truth-Token anzuvisieren.
In der Trainingsphase besteht das Trainingsziel des Basismodells darin, alle mskierten Token bei jedem Schritt vorherzusagen. In der Inferenzphase wird die Maskenvorhersage jedoch iterativ durchgeführt, was die Qualität erheblich verbessern kann.
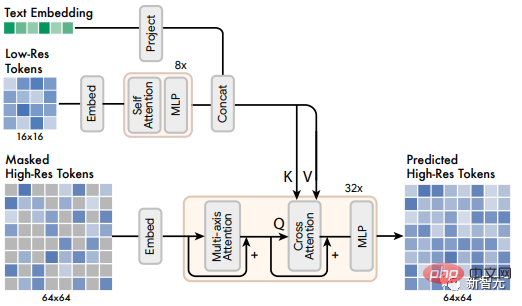
4. Super-Resolution-Modell
Forscher fanden heraus, dass die direkte Vorhersage von Bildern mit einer Auflösung von 512×512 dazu führte, dass sich das Modell auf Details auf niedriger Ebene statt auf Semantik auf hoher Ebene konzentrierte.
Die Verwendung einer Kaskade von Modellen kann diese Situation verbessern:
Verwenden Sie zuerst ein Basismodell, das eine latente 16×16-Karte generiert (entsprechend einem 256×256-Bild); die grundlegende latente Karte auf 64×64 (entsprechend einem 512×512-Bild). Das Training des Superauflösungsmodells erfolgt nach Abschluss des grundlegenden Modelltrainings.
Wie bereits erwähnt, trainierten die Forscher insgesamt zwei VQGAN-Modelle, eines mit einer latenten Auflösung von 16×16 und einer räumlichen Auflösung von 256×256 und das andere mit einer latenten Auflösung von 64×64 und einer räumlichen Auflösung von 512×512 .
Da das Basismodell ein Token ausgibt, das der latenten 16×16-Karte entspricht, lernt das Superauflösungsmodul, die latente Karte mit niedriger Auflösung in eine latente Karte mit hoher Auflösung zu „übersetzen“ und übergibt dann die latente Karte mit hoher Auflösung. Auflösungs-VQGAN-Dekodierung, um das endgültige hochauflösende Bild zu erhalten; das Übersetzungsmodell wird auch mit Textkonditionierung und Kreuzaufmerksamkeit auf ähnliche Weise wie das Basismodell trainiert.
5. Decoder-Feinabstimmung
Um die Fähigkeit des Modells, Details zu generieren, weiter zu verbessern, entschieden sich die Forscher dafür, die Kapazität des VQGAN-Decoders zu erhöhen, indem sie weitere Restschichten und Kanäle hinzufügten, während die Kapazität des Encoders unverändert blieb.
Dann optimieren Sie den neuen Decoder, während die Gewichte, das Codebuch und die Transformer (d. h. Basismodell und Superauflösungsmodell) des VQGAN-Encoders unverändert bleiben. Dieser Ansatz verbessert die visuelle Qualität der generierten Bilder, ohne dass andere Modellkomponenten neu trainiert werden müssen (da die visuellen Token fest bleiben).

Wie Sie sehen können, wurde der Decoder optimiert, um mehr und klarere Details zu rekonstruieren.
6. Variable Maskierungsrate
Die Forscher verwendeten eine variable Maskierungsrate basierend auf der Csoine-Planung, um das Modell zu trainieren: Extrahieren Sie für jedes Trainingsbeispiel eine Maskierungsrate r∈[0 , 1] und seine Dichtefunktion ist wie folgt. Der erwartete Wert der Maskenrate beträgt 0,64, was bedeutet, dass eine höhere Maskenrate bevorzugt wird, was die Vorhersage erschwert.
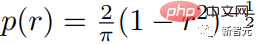 Randomisierte Maskenraten sind nicht nur für parallele Stichprobenschemata von entscheidender Bedeutung, sondern ermöglichen auch einige verstreute, sofort einsatzbereite Bearbeitungsfunktionen. 7. Classifier Free Guidance (CFG)
Randomisierte Maskenraten sind nicht nur für parallele Stichprobenschemata von entscheidender Bedeutung, sondern ermöglichen auch einige verstreute, sofort einsatzbereite Bearbeitungsfunktionen. 7. Classifier Free Guidance (CFG)
Während des Trainings werden Textbedingungen aus 10 % der zufällig ausgewählten Stichproben entfernt und der Aufmerksamkeitsmechanismus auf die Selbstaufmerksamkeit des Bildtokens selbst reduziert.
In der Inferenzphase werden ein bedingter Logit lc und ein unbedingter Logit lu für jedes maskierte Token berechnet, und dann wird der endgültige Logit LG gebildet, indem eine Menge t aus dem unbedingten Logit als Orientierungsmaßstab entfernt wird:
Intuitiv tauscht CFG Diversität gegen Treue, aber im Gegensatz zu früheren Methoden erhöht Muse die Führungsskala t während des Sampling-Prozesses linear, um den Diversitätsverlust zu reduzieren, sodass frühe Token unter niedriger Führung verwendet werden können oder freier abgetastet werden können ohne Anleitung, erhöht aber auch die Auswirkung bedingter Eingabeaufforderungen auf spätere Token.
Die Forscher machten sich diesen Mechanismus auch zunutze, um die Generierung von Bildern mit Merkmalen im Zusammenhang mit positiven Eingabeaufforderungen zu fördern, indem sie das unbedingte Logit Lu durch ein Logit ersetzten, das an die negative Eingabeaufforderung gebunden war.
8. Iterative parallele Dekodierung während der Inferenz
Ein wichtiger Teil der Verbesserung der Zeiteffizienz der Modellinferenz ist die Verwendung paralleler Dekodierung zur Vorhersage mehrerer Ausgabe-Tokens in einem einzelnen Vorwärtskanal dass Mal-Kov-Eigenschaft, das heißt, viele Token sind bedingt unabhängig von anderen gegebenen Token.
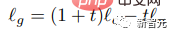
Die Dekodierung wird gemäß dem Kosinusplan durchgeführt und die Maske mit der höchsten Konfidenz in einem festen Verhältnis wird für die Vorhersage ausgewählt, wobei der Token in den verbleibenden Schritten auf „unmaskiert“ gesetzt wird und die maskierten Token entsprechend reduziert werden.
Nach dem obigen Prozess können im Basismodell nur 24 Dekodierungsschritte verwendet werden, um 256 Token abzuleiten, und im Superauflösungsmodell können 8 Dekodierungsschritte verwendet werden, um 4096 Token abzuleiten 256 oder 4096 Schritte, und Diffusionsmodelle erfordern Hunderte von Schritten.
Obwohl einige neuere Forschungen, einschließlich der progressiven Destillation und eines besseren ODE-Lösers, die Abtastschritte von Diffusionsmodellen erheblich reduziert haben, wurden diese Methoden bei der groß angelegten Text-zu-Bild-Generierung nicht umfassend validiert.
Experimentelle Ergebnisse
Die Forscher trainierten eine Reihe grundlegender Transformer-Modelle basierend auf T5-XXL mit unterschiedlichen Parametermengen (von 600M bis 3B).
Die Qualität der generierten Bilder
Das Experiment testete die Fähigkeit des Muse-Modells für Textaufforderungen mit unterschiedlichen Attributen, einschließlich des grundlegenden Verständnisses der Kardinalität. Für nicht singuläre Objekte generierte Muse nicht dasselbe Der Text wird mehrfach um Pixel erweitert, es werden jedoch Kontextänderungen hinzugefügt, wodurch das gesamte Bild realistischer wird.

Zum Beispiel die Größe und Richtung des Elefanten, die Farbe der Weinflaschenverpackung, die Drehung des Tennisballs usw.
Quantitativer Vergleich
Die Forscher führten experimentelle Vergleiche mit anderen Forschungsmethoden an den CC3M- und COCO-Datensätzen durch. Zu den Metriken gehören die Frechet Inception Distance (FID), die die Probenqualität und -vielfalt misst, sowie der Bild-/CLIP-Score für Textausrichtung.
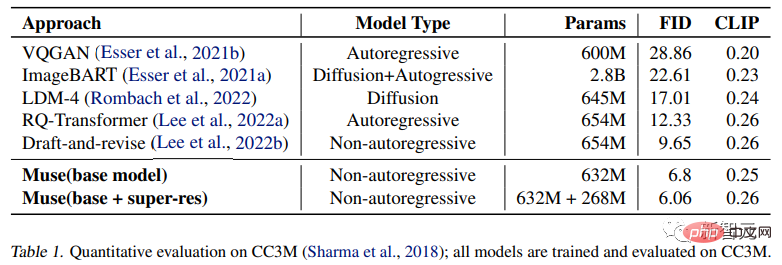
Experimentelle Ergebnisse belegen, dass das 632M Muse-Modell SOTA-Ergebnisse auf CC3M erreicht, den FID-Score verbessert und gleichzeitig den hochmodernen CLIP-Score erreicht.
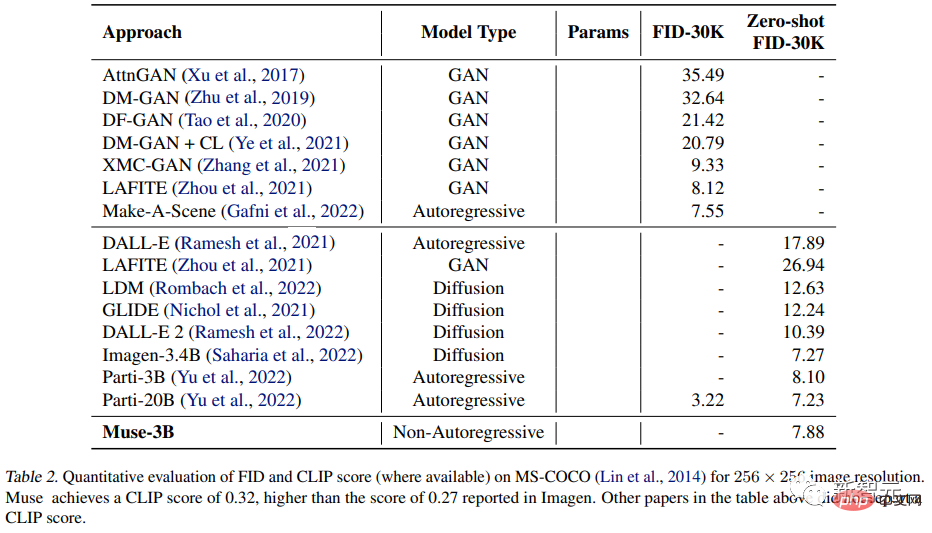
Auf dem MS-COCO-Datensatz erreichte das 3B-Modell einen FID-Score von 7,88, was etwas besser ist als der 8,1, den das Parti-3B-Modell mit einer ähnlichen Parametermenge erzielte.
Das obige ist der detaillierte Inhalt vonTransformer schlägt Diffusion erneut! Google veröffentlicht Muse, eine neue Generation eines Text-Bild-Generierungsmodells: Die Generierungseffizienz wurde verzehnfacht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Deepseek ist ein leistungsstarkes Informations -Abruf -Tool. .
 So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
Deepseek ist eine proprietäre Suchmaschine, die nur schneller und genauer in einer bestimmten Datenbank oder einem bestimmten System sucht. Bei der Verwendung wird den Benutzern empfohlen, das Dokument zu lesen, verschiedene Suchstrategien auszuprobieren, Hilfe und Feedback zur Benutzererfahrung zu suchen, um die Vorteile optimal zu nutzen.
 Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
In diesem Artikel wird der Registrierungsprozess der Webversion Sesam Open Exchange (GATE.IO) und die Gate Trading App im Detail vorgestellt. Unabhängig davon, ob es sich um eine Webregistrierung oder eine App -Registrierung handelt, müssen Sie die offizielle Website oder den offiziellen App Store besuchen, um die Genuine App herunterzuladen, und dann den Benutzernamen, das Kennwort, die E -Mail, die Mobiltelefonnummer und die anderen Informationen eingeben und eine E -Mail- oder Mobiltelefonüberprüfung abschließen.
 Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden? Bitbit ist eine Kryptowährungsbörse, die den Benutzern Handelsdienste anbietet. Die mobilen Apps der Exchange können aus den folgenden Gründen nicht direkt über AppStore oder Googleplay heruntergeladen werden: 1. App Store -Richtlinie beschränkt Apple und Google daran, strenge Anforderungen an die im App Store zulässigen Anwendungsarten zu haben. Kryptowährungsanträge erfüllen diese Anforderungen häufig nicht, da sie Finanzdienstleistungen einbeziehen und spezifische Vorschriften und Sicherheitsstandards erfordern. 2. Die Einhaltung von Gesetzen und Vorschriften In vielen Ländern werden Aktivitäten im Zusammenhang mit Kryptowährungstransaktionen reguliert oder eingeschränkt. Um diese Vorschriften einzuhalten, kann die Bitbit -Anwendung nur über offizielle Websites oder andere autorisierte Kanäle verwendet werden
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Es ist wichtig, einen formalen Kanal auszuwählen, um die App herunterzuladen und die Sicherheit Ihres Kontos zu gewährleisten.
 Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Eine detaillierte Einführung in den Anmeldungsbetrieb der Sesame Open Exchange -Webversion, einschließlich Anmeldeschritte und Kennwortwiederherstellungsprozess.
 Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Dieser Artikel empfiehlt die Top Ten Ten Cryptocurrency -Handelsplattformen, die es wert sind, auf Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI und Xbit -dezentrale Börsen geachtet zu werden. Diese Plattformen haben ihre eigenen Vorteile in Bezug auf Transaktionswährungsmenge, Transaktionstyp, Sicherheit, Konformität und Besonderheiten. Die Auswahl einer geeigneten Plattform erfordert eine umfassende Überlegung, die auf eigener Handelserfahrung, Risikotoleranz und Investitionspräferenzen basiert. Ich hoffe, dieser Artikel hilft Ihnen dabei, den besten Anzug für sich selbst zu finden
 Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Befolgen Sie diese einfachen Schritte, um auf die neueste Version des Binance -Website -Login -Portals zuzugreifen. Gehen Sie zur offiziellen Website und klicken Sie in der oberen rechten Ecke auf die Schaltfläche "Anmeldung". Wählen Sie Ihre vorhandene Anmeldemethode. Geben Sie Ihre registrierte Handynummer oder E -Mail und Kennwort ein und vervollständigen Sie die Authentifizierung (z. B. Mobilfifizierungscode oder Google Authenticator). Nach einer erfolgreichen Überprüfung können Sie auf das neueste Version des offiziellen Website -Login -Portals von Binance zugreifen.
