

Entscheidungsbäume sind ein wesentlicher Bestandteil der leistungsstärksten Methoden des überwachten Lernens von heute. Ein Entscheidungsbaum ist im Grunde ein Flussdiagramm eines Binärbaums, in dem jeder Knoten eine Reihe von Beobachtungen basierend auf einer charakteristischen Variablen aufteilt.
Das Ziel eines Entscheidungsbaums besteht darin, Daten in Gruppen zu unterteilen, sodass jedes Element in einer Gruppe zur gleichen Kategorie gehört. Entscheidungsbäume können auch zur Approximation kontinuierlicher Zielvariablen verwendet werden. In diesem Fall wird der Baum so aufgeteilt, dass jede Gruppe den kleinsten mittleren quadratischen Fehler aufweist.
Eine wichtige Eigenschaft von Entscheidungsbäumen ist, dass sie leicht interpretierbar sind. Sie müssen überhaupt nicht mit Techniken des maschinellen Lernens vertraut sein, um zu verstehen, was Entscheidungsbäume tun. Entscheidungsbaumdiagramme sind leicht zu interpretieren.Vor- und Nachteile
Die Vorteile der Entscheidungsbaummethode sind:#🎜 🎜#Entscheidungsbaum Fähigkeit, verständliche Regeln zu generieren.
Schritt 1: Paket importieren
Die wichtigsten Softwarepakete, die wir zum Erstellen von Modellen verwenden, sind Pandas, Scikit Learn und NumPy. Folgen Sie dem Code, um die erforderlichen Pakete in Python zu importieren.
import pandas as pd # 数据处理 import numpy as np # 使用数组 import matplotlib.pyplot as plt # 可视化 from matplotlib import rcParams # 图大小 from termcolor import colored as cl # 文本自定义 from sklearn.tree import DecisionTreeClassifier as dtc # 树算法 from sklearn.model_selection import train_test_split # 拆分数据 from sklearn.metrics import accuracy_score # 模型准确度 from sklearn.tree import plot_tree # 树图 rcParams['figure.figsize'] = (25, 20)
Nachdem wir alle zum Erstellen unseres Modells erforderlichen Pakete importiert haben, ist es an der Zeit, die Daten zu importieren und eine EDA darauf durchzuführen.
Schritt 2: Daten und EDA importierenIn diesem Schritt verwenden wir zum Importieren und Ausführen das in Python bereitgestellte Paket „Pandas“. etwas EDA drauf. Wir werden unser Entscheidungsbaummodell auf einem Datensatz von Medikamenten aufbauen, die Patienten basierend auf bestimmten Kriterien verschrieben werden. Lassen Sie uns die Daten mit Python importieren! Set hat ein klares Konzept. Nachdem wir die Daten importiert haben, nutzen wir die Funktion „Info“, um einige grundlegende Informationen zu den Daten zu erhalten. Zu den von dieser Funktion bereitgestellten Informationen gehören die Anzahl der Einträge, die Indexnummer, der Spaltenname, die Anzahl der Nicht-Null-Werte, der Attributtyp usw.
Python-Implementierung:
df = pd.read_csv('drug.csv') df.drop('Unnamed: 0', axis = 1, inplace = True) print(cl(df.head(), attrs = ['bold']))Ausgabe:
Age Sex BP Cholesterol Na_to_K Drug 0 23 F HIGH HIGH 25.355 drugY 1 47 M LOW HIGH 13.093 drugC 2 47 M LOW HIGH 10.114 drugC 3 28 F NORMAL HIGH 7.798 drugX 4 61 F LOW HIGH 18.043 drugY
Schritt 3: Datenverarbeitung#🎜 🎜#
Wir können sehen, dass Attribute wie Geschlecht, Blutdruck und Cholesterin kategorialer Natur sind und Objekttypen sind. Das Problem besteht darin, dass der Entscheidungsbaumalgorithmus in scikit-learn von Natur aus keine X-Variablen (Features) vom Typ „Objekt“ unterstützt. Daher ist es notwendig, diese „Objekt“-Werte in „binäre“ Werte umzuwandeln. Lassen Sie uns Python verwenden, umPython-Implementierung zu implementieren:
df.info()
<class> RangeIndex: 200 entries, 0 to 199 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Age 200 non-null int64 1 Sex 200 non-null object 2 BP 200 non-null object 3 Cholesterol 200 non-null object 4 Na_to_K 200 non-null float64 5 Drug 200 non-null object dtypes: float64(1), int64(1), object(4) memory usage: 9.5+ KB</class>
Schritt 4: Daten aufteilen
Nachdem wir unsere Daten in die richtige Struktur verarbeitet haben, setzen wir nun die Variable „X“ ( Unabhängige Variable ), „Y“-Variable (abhängige Variable). Lassen Sie es uns in Python implementieren Der „train_test_split“-Algorithmus in Learn teilt die Daten in einen Trainingssatz und einen Testsatz auf, die die von uns definierten X- und Y-Variablen enthalten. Befolgen Sie den Code, um Daten in Python aufzuteilen.Python-Implementierung:
for i in df.Sex.values: if i == 'M': df.Sex.replace(i, 0, inplace = True) else: df.Sex.replace(i, 1, inplace = True) for i in df.BP.values: if i == 'LOW': df.BP.replace(i, 0, inplace = True) elif i == 'NORMAL': df.BP.replace(i, 1, inplace = True) elif i == 'HIGH': df.BP.replace(i, 2, inplace = True) for i in df.Cholesterol.values: if i == 'LOW': df.Cholesterol.replace(i, 0, inplace = True) else: df.Cholesterol.replace(i, 1, inplace = True) print(cl(df, attrs = ['bold']))
Age Sex BP Cholesterol Na_to_K Drug 0 23 1 2 1 25.355 drugY 1 47 1 0 1 13.093 drugC 2 47 1 0 1 10.114 drugC 3 28 1 1 1 7.798 drugX 4 61 1 0 1 18.043 drugY .. ... ... .. ... ... ... 195 56 1 0 1 11.567 drugC 196 16 1 0 1 12.006 drugC 197 52 1 1 1 9.894 drugX 198 23 1 1 1 14.020 drugX 199 40 1 0 1 11.349 drugX [200 rows x 6 columns]
Schritt 5: Modell und Vorhersage erstellen
Mit Hilfe des vom scikit-Lernpaket bereitgestellten „DecisionTreeClassifier“-Algorithmus ist dies machbar um einen Entscheidungsbaum zu erstellen. Anschließend können wir unser trainiertes Modell verwenden, um unsere Daten vorherzusagen. Schließlich kann die Genauigkeit unserer Vorhersageergebnisse mithilfe der Bewertungsmetrik „Genauigkeit“ berechnet werden. Lassen Sie uns Python verwenden, um diesen Prozess abzuschließen!Accuracy of the model is 88%
在代码的第一步中,我们定义了一个名为“model”变量的变量,我们在其中存储DecisionTreeClassifier模型。接下来,我们将使用我们的训练集对模型进行拟合和训练。之后,我们定义了一个变量,称为“pred_model”变量,其中我们将模型预测的所有值存储在数据上。最后,我们计算了我们的预测值与实际值的精度,其准确率为88%。
步骤6:可视化模型
现在我们有了决策树模型,让我们利用python中scikit learn包提供的“plot_tree”函数来可视化它。按照代码从python中的决策树模型生成一个漂亮的树图。
Python实现:
feature_names = df.columns[:5] target_names = df['Drug'].unique().tolist() plot_tree(model, feature_names = feature_names, class_names = target_names, filled = True, rounded = True) plt.savefig('tree_visualization.png')输出:
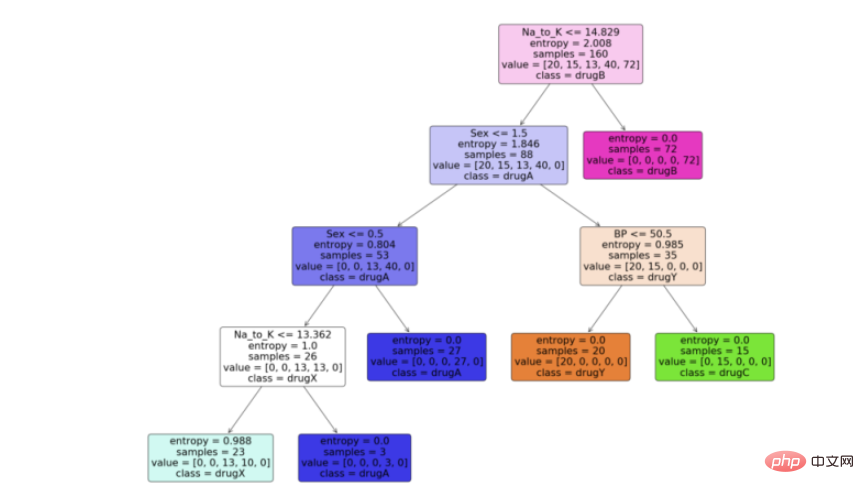
结论
有很多技术和其他算法用于优化决策树和避免过拟合,比如剪枝。虽然决策树通常是不稳定的,这意味着数据的微小变化会导致最优树结构的巨大变化,但其简单性使其成为广泛应用的有力候选。在神经网络流行之前,决策树是机器学习中最先进的算法。其他一些集成模型,比如随机森林模型,比普通决策树模型更强大。
决策树由于其简单性和可解释性而非常强大。决策树和随机森林在用户注册建模、信用评分、故障预测、医疗诊断等领域有着广泛的应用。我为本文提供了完整的代码。
完整代码:
import pandas as pd # 数据处理 import numpy as np # 使用数组 import matplotlib.pyplot as plt # 可视化 from matplotlib import rcParams # 图大小 from termcolor import colored as cl # 文本自定义 from sklearn.tree import DecisionTreeClassifier as dtc # 树算法 from sklearn.model_selection import train_test_split # 拆分数据 from sklearn.metrics import accuracy_score # 模型准确度 from sklearn.tree import plot_tree # 树图 rcParams['figure.figsize'] = (25, 20) df = pd.read_csv('drug.csv') df.drop('Unnamed: 0', axis = 1, inplace = True) print(cl(df.head(), attrs = ['bold'])) df.info() for i in df.Sex.values: if i == 'M': df.Sex.replace(i, 0, inplace = True) else: df.Sex.replace(i, 1, inplace = True) for i in df.BP.values: if i == 'LOW': df.BP.replace(i, 0, inplace = True) elif i == 'NORMAL': df.BP.replace(i, 1, inplace = True) elif i == 'HIGH': df.BP.replace(i, 2, inplace = True) for i in df.Cholesterol.values: if i == 'LOW': df.Cholesterol.replace(i, 0, inplace = True) else: df.Cholesterol.replace(i, 1, inplace = True) print(cl(df, attrs = ['bold'])) X_var = df[['Sex', 'BP', 'Age', 'Cholesterol', 'Na_to_K']].values # 自变量 y_var = df['Drug'].values # 因变量 print(cl('X variable samples : {}'.format(X_var[:5]), attrs = ['bold'])) print(cl('Y variable samples : {}'.format(y_var[:5]), attrs = ['bold'])) X_train, X_test, y_train, y_test = train_test_split(X_var, y_var, test_size = 0.2, random_state = 0) print(cl('X_train shape : {}'.format(X_train.shape), attrs = ['bold'], color = 'red')) print(cl('X_test shape : {}'.format(X_test.shape), attrs = ['bold'], color = 'red')) print(cl('y_train shape : {}'.format(y_train.shape), attrs = ['bold'], color = 'green')) print(cl('y_test shape : {}'.format(y_test.shape), attrs = ['bold'], color = 'green')) model = dtc(criterion = 'entropy', max_depth = 4) model.fit(X_train, y_train) pred_model = model.predict(X_test) print(cl('Accuracy of the model is {:.0%}'.format(accuracy_score(y_test, pred_model)), attrs = ['bold'])) feature_names = df.columns[:5] target_names = df['Drug'].unique().tolist() plot_tree(model, feature_names = feature_names, class_names = target_names, filled = True, rounded = True) plt.savefig('tree_visualization.png')Das obige ist der detaillierte Inhalt vonSo erstellen Sie einen Entscheidungsbaum in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



