

###Der erste Schritt, gleichzeitiger Verbrauch###
Schauen Sie sich zuerst den Code an. Der entscheidende Punkt ist, dass wir ConcurrentKafkaListenerContainerFactory verwenden und Factory.setConcurrency(4); festlegen. (Um die Geschwindigkeit zu erhöhen Verbrauch, es wird gleichzeitig sein. Auf 4 gesetzt, das heißt, es gibt 4 KafkaMessageListenerContainer .
###Der zweite Schritt ist der Batch-Verbrauch###
Dann folgt der Batch-Verbrauch. Die wichtigsten Punkte sind Factory.setBatchListener(true);und propsMap.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 50);
Einer besteht darin, den Batch-Verbrauch zu aktivieren, und der andere darin, die maximale Anzahl von Nachrichtendatensätzen festzulegen, die der Batch-Verbrauch jeweils verbrauchen kann Zeit.
Es ist wichtig zu beachten, dass die von uns festgelegte ConsumerConfig.MAX_POLL_RECORDS_CONFIG 50 beträgt, was nicht bedeutet, dass wir weiter warten, wenn 50 Nachrichten nicht erreicht werden. Die offizielle Erklärung lautet: „Die maximale Anzahl von Datensätzen, die in einem einzelnen Aufruf von poll() zurückgegeben werden.“ Das heißt, 50 stellt die maximale Anzahl von Datensätzen dar, die in einer Umfrage zurückgegeben werden.
Sie können dem Startprotokoll entnehmen, dass max.poll.interval.ms = 300000 ist, was bedeutet, dass wir poll einmal in jedem max.poll.interval.ms-Intervall aufrufen. Jede Umfrage gibt bis zu 50 Datensätze zurück. Die offizielle Erklärung von
max.poll.interval.ms lautet „Die maximale Verzögerung zwischen Aufrufen von poll() bei Verwendung der Verbrauchergruppenverwaltung. Dies legt eine Obergrenze für die Zeitspanne fest, die der Verbraucher inaktiv sein kann, bevor er weitere Datensätze abruft. Wenn poll() wird nicht vor Ablauf dieses Timeouts aufgerufen, dann gilt der Consumer als ausgefallen und die Gruppe wird neu ausgeglichen, um die Partitionen einem anderen Mitglied neu zuzuweisen Screenshot der offiziellen Erklärung von .records und max.poll.interval.ms:
###Der dritte Schritt, Partitionsverbrauch###Für ein Thema mit nur einer Partition ist der Partitionsverbrauch nicht erforderlich, da dies der Fall ist ist bedeutungslos. Das folgende Beispiel gilt für den Fall, dass es zwei Partitionen gibt (mein vollständiger Code enthält vier listenPartitionX-Methoden und in meinem Thema sind vier Partitionen festgelegt. Leser können es entsprechend ihrer eigenen Situation anpassen). 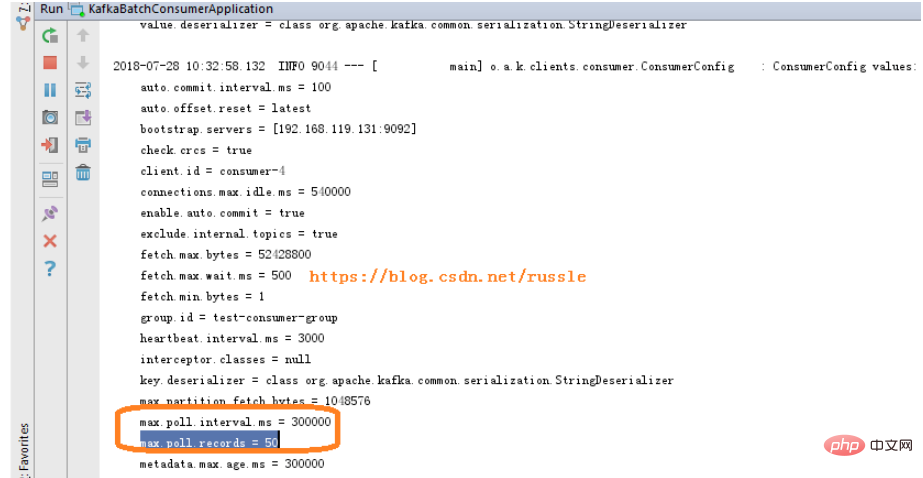
@Bean
KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(4);
factory.setBatchListener(true);
factory.getContainerProperties().setPollTimeout(3000);
return factory;
}Das obige ist der detaillierte Inhalt vonSo verwenden Sie @KafkaListener, um in Spring Boot gleichzeitig Nachrichten in Stapeln zu empfangen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Schritte zur SpringBoot-Projekterstellung
Schritte zur SpringBoot-Projekterstellung
 Was ist der Unterschied zwischen j2ee und springboot?
Was ist der Unterschied zwischen j2ee und springboot?
 Was nützt Bitlocker?
Was nützt Bitlocker?
 So verbinden Sie PHP mit der MSSQL-Datenbank
So verbinden Sie PHP mit der MSSQL-Datenbank
 Welche Währung ist MULTI?
Welche Währung ist MULTI?
 SEO-Seitenbeschreibung
SEO-Seitenbeschreibung
 WLAN ist verbunden, aber es gibt ein Ausrufezeichen
WLAN ist verbunden, aber es gibt ein Ausrufezeichen
 So konfigurieren Sie die Pfadumgebungsvariable in Java
So konfigurieren Sie die Pfadumgebungsvariable in Java








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



