
 Technologie-Peripheriegeräte
KI
Lösen Sie die ChatGPT-Amnesie vollständig! Durchbrechen der Transformer-Eingabegrenze: Gemessen zur Unterstützung von 2 Millionen gültigen Token
Technologie-Peripheriegeräte
KI
Lösen Sie die ChatGPT-Amnesie vollständig! Durchbrechen der Transformer-Eingabegrenze: Gemessen zur Unterstützung von 2 Millionen gültigen Token
Lösen Sie die ChatGPT-Amnesie vollständig! Durchbrechen der Transformer-Eingabegrenze: Gemessen zur Unterstützung von 2 Millionen gültigen Token

ChatGPT oder das Transformer-Klassenmodell weist einen schwerwiegenden Fehler auf, der zu leicht vergessen wird. Sobald das Token der Eingabesequenz den Schwellenwert des Kontextfensters überschreitet, stimmt der nachfolgende Ausgabeinhalt nicht mit der vorherigen Logik überein .
ChatGPT kann nur die Eingabe von 4000 Token (ca. 3000 Wörter) unterstützen. Selbst das neu veröffentlichte GPT-4 unterstützt nur ein maximales Token-Fenster von 32000. Wenn Sie die Länge der Eingabesequenz weiter erhöhen, wird die Die Berechnung wird auch komplizierter.
Kürzlich haben Forscher von DeepPavlov, AIRI und dem London Mathematical Sciences Institute einen technischen Bericht veröffentlicht, in dem sie den Recurrent Memory Transformer (RMT) verwenden, um die effektive Kontextlänge von BERT auf „beispiellose 2 Millionen Token“ zu erhöhen. , unter Beibehaltung einer hohen Speicherabrufgenauigkeit.
Papierlink: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
Diese Methode kann lokale und globale Informationen speichern und verarbeiten und Schleifen verwenden, um die Informationen zu behalten im Fluss zwischen Segmenten der Eingabesequenz.
Der experimentelle Abschnitt demonstriert die Wirksamkeit dieses Ansatzes, der ein außerordentliches Potenzial zur Verbesserung der langfristigen Abhängigkeitsverarbeitung bei Aufgaben zum Verstehen und Generieren natürlicher Sprache hat und eine groß angelegte Kontextverarbeitung für speicherintensive Anwendungen ermöglicht.
Obwohl RMT den Speicherverbrauch nicht erhöhen kann und auf nahezu unbegrenzte Sequenzlängen erweitert werden kann, besteht immer noch das Problem des Speicherverfalls in RNN und einer längeren Inferenzzeit ist erforderlich.

Aber einige Internetnutzer haben eine Lösung vorgeschlagen: RMT wird für das Langzeitgedächtnis verwendet, großer Kontext wird für das Kurzzeitgedächtnis verwendet und dann modelliert Das Training wird nachts/während der Wartung durchgeführt.
Cyclic Memory Transformer
Im Jahr 2022 schlug das Team das Cyclic Memory Transformer (RMT)-Modell vor, indem der Eingabe- oder Ausgabesequenz ein spezielles Speichertoken hinzugefügt und dann geändert wurde Das Modelltraining zur Steuerung von Speicheroperationen und zur Verarbeitung von Sequenzdarstellungen kann einen neuen Speichermechanismus implementieren, ohne das ursprüngliche Transformer-Modell zu ändern.

Papierlink: https://arxiv.org/abs/2207.06881
Publikationskonferenz: NeurIPS 2022#🎜🎜 #
Im Vergleich zu Transformer-XL benötigt RMT weniger Speicher und kann längere Aufgabensequenzen bewältigen.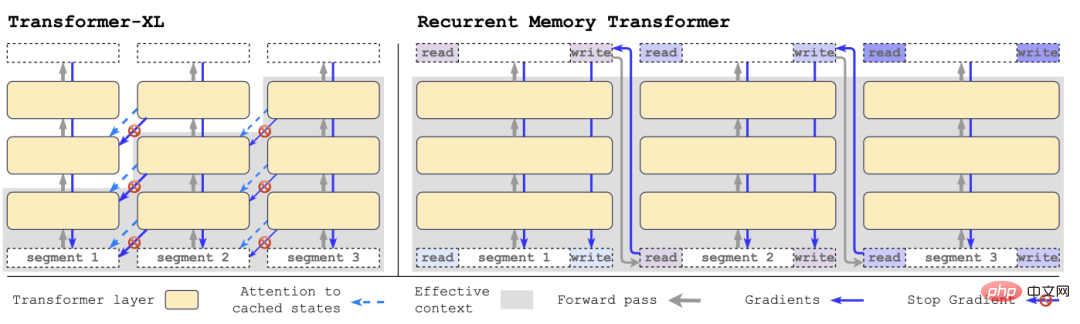
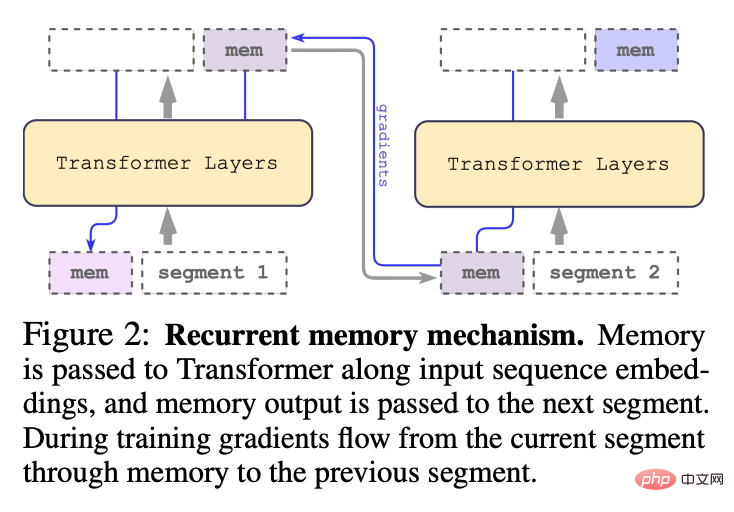
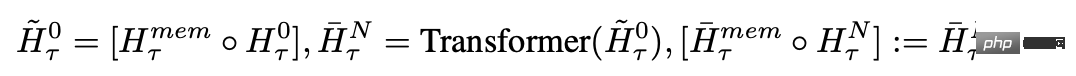 Nachdem der Forscher die Segmente der Eingabesequenz der Reihe nach verarbeitet hat, um eine rekursive Verbindung zu erreichen, übergibt der Forscher die Ausgabe des Speichertokens des aktuellen Segments an die Eingabe des nächsten Segments: #🎜 🎜#
Nachdem der Forscher die Segmente der Eingabesequenz der Reihe nach verarbeitet hat, um eine rekursive Verbindung zu erreichen, übergibt der Forscher die Ausgabe des Speichertokens des aktuellen Segments an die Eingabe des nächsten Segments: #🎜 🎜#
Der Speicher und die Schleife in RMT basieren nur auf globalen Speichertokens, die das Backbone-Transformer-Modell unverändert lassen können, wodurch die Speichererweiterungsfunktion von RMT mit jedem Transformer kompatibel ist Modell. 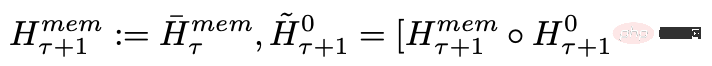
Die lineare Expansion wird erreicht, indem eine Eingabesequenz in mehrere Segmente unterteilt wird und alle Aufmerksamkeitsmatrizen nur innerhalb der Grenzen der Segmente berechnet werden. Die Ergebnisse sind sichtbar Wenn also die Segmentlänge fest ist, steigt die Inferenzgeschwindigkeit von RMT für jede Modellgröße linear an. 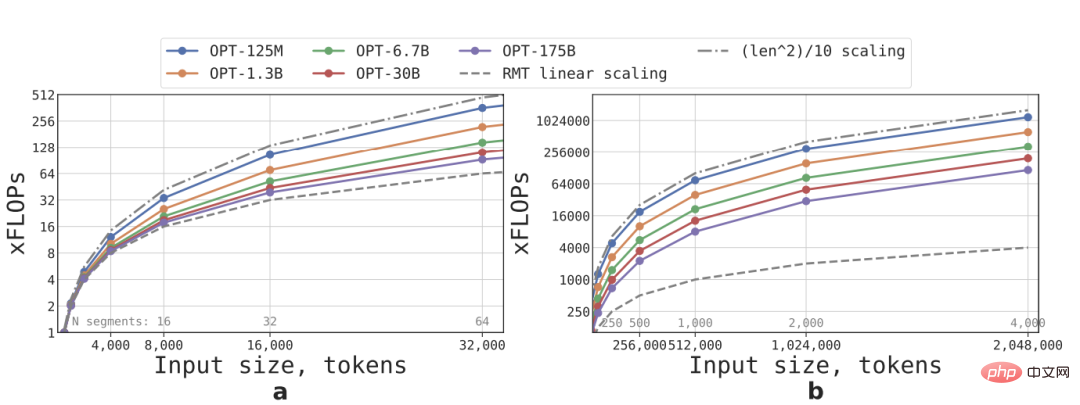
Aufgrund des großen Rechenaufwands der FFN-Schicht zeigen größere Transformer-Modelle tendenziell eine langsamere quadratische Wachstumsrate im Verhältnis zur Sequenzlänge. Bei extrem langen Sequenzen mit einer Länge von mehr als 32.000 kehren FLOPs jedoch zum quadratischen Wachstum zurück .
Für Sequenzen mit mehr als einem Segment (größer als 512 in dieser Studie) hat RMT niedrigere FLOPs als das azyklische Modell und kann die Effizienz von FLOPs bei kleineren Modellen um das bis zu 295-fache steigern Modelle Große Modelle wie OPT-175B können um das 29-fache verbessert werden.
Gedächtnisaufgabe
Um die Gedächtnisfähigkeiten zu testen, erstellten die Forscher einen synthetischen Datensatz, der vom Modell verlangte, sich einfache Fakten und grundlegende Überlegungen zu merken.
Aufgabeneingabe besteht aus einem oder mehreren Fakten und einer Frage, die nur mit all diesen Fakten beantwortet werden kann.
Um den Schwierigkeitsgrad der Aufgabe zu erhöhen, wird der Aufgabe auch Text in natürlicher Sprache hinzugefügt, der nicht mit der Frage oder Antwort zusammenhängt. Diese Texte können als Rauschen angesehen werden, sodass die Aufgabe des Modells tatsächlich darin besteht, die Fakten davon zu trennen den irrelevanten Text und verwenden Sie den Faktentext, um die Frage zu beantworten.

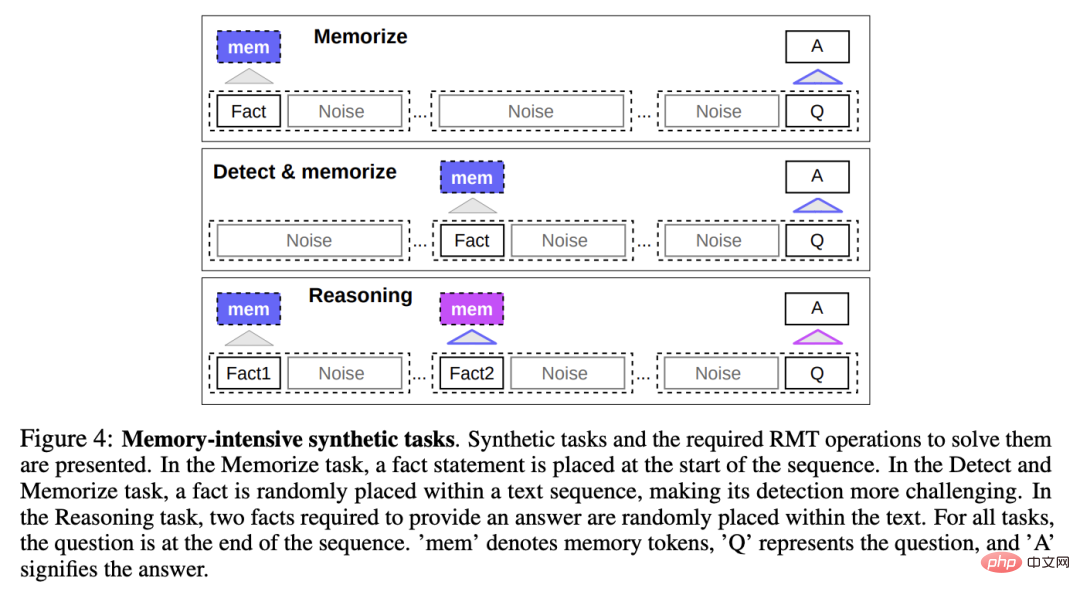
Faktengedächtnis
Testet RMTs Fähigkeit, Informationen über längere Zeiträume zu schreiben und im Gedächtnis zu speichern: Im einfachsten Fall stehen die Fakten am Anfang der Eingabe, die Fragen am Ende der Eingabe und schrittweise Erhöhen Sie die Menge an irrelevantem Text zwischen Fragen und Antworten, bis das Modell nicht mehr alle Eingaben auf einmal akzeptieren kann.

Faktenerkennung und Gedächtnis
Die Tatsachenerkennung erhöht die Schwierigkeit der Aufgabe, indem sie die Tatsache an eine zufällige Position in der Eingabe verschiebt, sodass das Modell die Tatsache zunächst von irrelevantem Text unterscheiden und in den Speicher schreiben muss. Beantworten Sie dann die Frage am Ende.
Argumentation auf der Grundlage von auswendig gelernten Fakten
Eine weitere wichtige Operation des Gedächtnisses besteht darin, auf der Grundlage von auswendig gelernten Fakten und dem aktuellen Kontext zu argumentieren.
Um diese Funktion zu bewerten, führten die Forscher eine komplexere Aufgabe ein, bei der zwei Fakten generiert und zufällig in der Eingabesequenz platziert werden. Eine am Ende der Sequenz gestellte Frage muss ausgewählt werden, um die Frage mit der richtigen Tatsache zu beantworten.

Experimentelle Ergebnisse
Die Forscher verwendeten in allen Experimenten das vorab trainierte Bert-Base-Case-Modell in HuggingFace Transformers als Rückgrat von RMT, und alle Modelle wurden mit einer Speichergröße von 10 erweitert.
Trainieren und evaluieren Sie auf 4–8 NVIDIA 1080Ti-GPUs für längere Sequenzen. Wechseln Sie zu einer einzelnen 40-GB-NVIDIA A100 für eine beschleunigte Evaluierung.
Curriculum Learning
Forscher beobachteten, dass der Einsatz von Trainingsplanung die Genauigkeit und Stabilität der Lösung deutlich verbessern kann.
Beginnen Sie das RMT-Training einfach mit einer kürzeren Version der Aufgabe. Erhöhen Sie nach der Konvergenz des Trainings die Aufgabenlänge, indem Sie ein Segment hinzufügen, und setzen Sie den Kurslernprozess fort, bis die ideale Eingabelänge erreicht ist.
Starten Sie das Experiment mit einer Sequenz, die zu einem einzelnen Segment passt. Die tatsächliche Segmentgröße beträgt 499, da 3 BERT-Spezialtoken und 10 Speicherplatzhalter aus der Modelleingabe beibehalten werden, was eine Gesamtgröße von 512 ergibt.
Es ist zu beobachten, dass RMT nach dem Training kürzerer Aufgaben längere Aufgaben leichter lösen kann, da es mit weniger Trainingsschritten zu einer perfekten Lösung konvergiert.
Extrapolationsfähigkeiten
Um die Generalisierungsfähigkeit von RMT auf unterschiedliche Sequenzlängen zu beobachten, bewerteten die Forscher Modelle, die auf einer unterschiedlichen Anzahl von Segmenten trainiert wurden, um Aufgaben größerer Länge zu lösen.
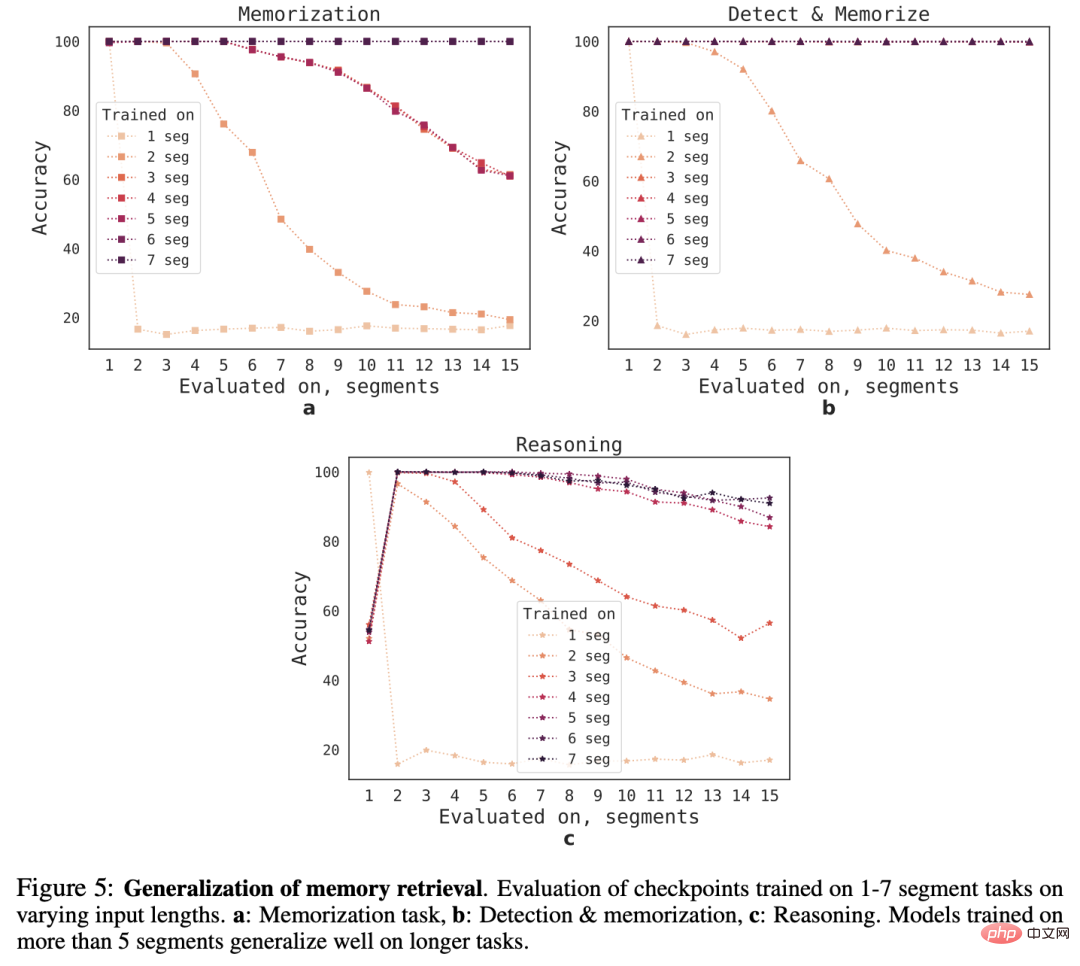
Es ist zu beobachten, dass das Modell bei kürzeren Aufgaben oft eine gute Leistung erbringt, aber nach dem Training des Modells bei längeren Sequenzen wird es schwierig, Einzelsegment-Inferenzaufgaben zu bewältigen.
Eine mögliche Erklärung ist, dass das Modell das Problem im ersten Segment nicht mehr antizipiert, weil die Aufgabengröße ein Segment überschreitet, was zu einer Verschlechterung der Qualität führt.
Interessanterweise zeigt sich mit zunehmender Anzahl der Trainingssegmente auch die Generalisierungsfähigkeit von RMT auf längere Sequenzen. Nach dem Training auf 5 oder mehr Segmenten kann RMT bei Aufgaben fast doppelt so lange arbeiten. Perfekte Generalisierung.
Um die Grenze der Generalisierung zu testen, erhöhten die Forscher die Größe der Verifizierungsaufgabe auf 4096 Segmente (d. h. 2.043.904 Token).
RMT hält sich bei so langen Sequenzen überraschend gut, wobei die Aufgabe „Erkennung und Gedächtnis“ die einfachste und die Inferenzaufgabe die komplexeste ist.
Referenz: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
Das obige ist der detaillierte Inhalt vonLösen Sie die ChatGPT-Amnesie vollständig! Durchbrechen der Transformer-Eingabegrenze: Gemessen zur Unterstützung von 2 Millionen gültigen Token. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
DALL-E 3 wurde im September 2023 offiziell als deutlich verbessertes Modell gegenüber seinem Vorgänger eingeführt. Er gilt als einer der bisher besten KI-Bildgeneratoren und ist in der Lage, Bilder mit komplexen Details zu erstellen. Zum Start war es jedoch exklusiv
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
1. Einleitung In den letzten Jahren haben sich YOLOs aufgrund ihres effektiven Gleichgewichts zwischen Rechenkosten und Erkennungsleistung zum vorherrschenden Paradigma im Bereich der Echtzeit-Objekterkennung entwickelt. Forscher haben das Architekturdesign, die Optimierungsziele, Datenerweiterungsstrategien usw. von YOLO untersucht und erhebliche Fortschritte erzielt. Gleichzeitig behindert die Verwendung von Non-Maximum Suppression (NMS) bei der Nachbearbeitung die End-to-End-Bereitstellung von YOLO und wirkt sich negativ auf die Inferenzlatenz aus. In YOLOs fehlt dem Design verschiedener Komponenten eine umfassende und gründliche Prüfung, was zu erheblicher Rechenredundanz führt und die Fähigkeiten des Modells einschränkt. Es bietet eine suboptimale Effizienz und ein relativ großes Potenzial zur Leistungsverbesserung. Ziel dieser Arbeit ist es, die Leistungseffizienzgrenze von YOLO sowohl in der Nachbearbeitung als auch in der Modellarchitektur weiter zu verbessern. zu diesem Zweck
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
