
 Betrieb und Instandhaltung
Betrieb und Wartung von Linux
So verwenden Sie die automatisierten Linux-Build-Tools make und Makefile
Betrieb und Instandhaltung
Betrieb und Wartung von Linux
So verwenden Sie die automatisierten Linux-Build-Tools make und Makefile
So verwenden Sie die automatisierten Linux-Build-Tools make und Makefile

1. Die Rolle von make und Makefile
Die Quelldateien in einem Projekt werden nicht gezählt, je nach Typ, Funktion und Modul. Das Makefile definiert eine Reihe von Regeln, um anzugeben, welche Dateien gespeichert werden müssen Zuerst kompiliert, welche Dateien nachkompiliert werden müssen, welche Dateien neu kompiliert werden müssen und noch komplexere Funktionsvorgänge können ausgeführt werden.
Der Vorteil von Makefile ist also: „Automatisierte Kompilierung“ Nach dem Schreiben ist nur ein Make-Befehl erforderlich und das gesamte Projekt wird vollständig automatisch kompiliert, was die Effizienz der Softwareentwicklung erheblich verbessert.
make ist ein Befehlstool, das die Anweisungen im Makefile interpretiert. Im Allgemeinen verfügen die meisten IDEs über diesen Befehl, z. B. make von Delphi, nmake von Visual C++ und make von GNU. Es ist ersichtlich, dass Makefile zu einer Kompilierungsmethode im Engineering geworden ist. make ist ein Befehl und makefile ist eine Datei. Bei gemeinsamer Verwendung können Sie die automatisierte Erstellung des Projekts abschließen.
2. Verwendung von make und Makefile
Bevor wir Abhängigkeiten und Abhängigkeitsmethoden verstehen, schreiben wir ein kleines Programm in C-Sprache.
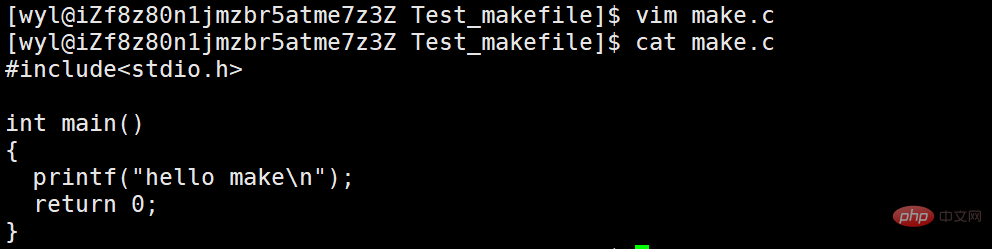
Wir haben eine make.c-Datei erstellt und einen Hello-Make-Code geschrieben.
Dann erstellen wir ein weiteres Makefile (Makefile ist auch möglich, aber nicht empfohlen).
Dann bearbeiten wir das Makefile und schreiben den folgenden Code:
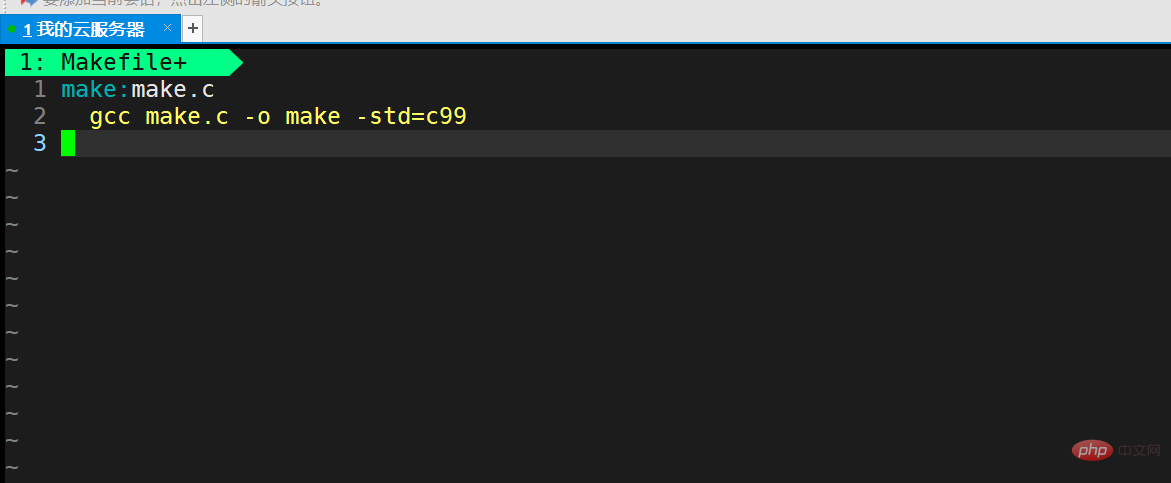
Dann speichern und beenden wir.
Dann können wir den Make-Befehl ausführen. Wenn die Meldung erscheint, dass make nicht vorhanden ist, liegt das daran, dass es nicht installiert ist. Sie können zur Installation als Root wechseln. Installationscode: yum install make oder sudo install make. yum install make 或者 sudo install make。
正常执行make后会出现如下显示。
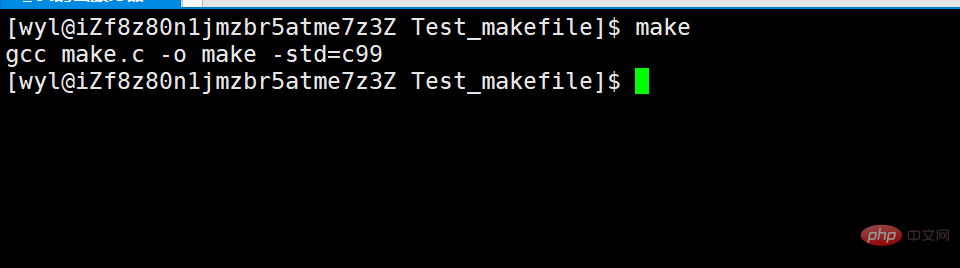
然后我们ll来查看当前目录下的文件。
我们可以发现多了一个可执行程序make。那我们运行用 ./make 运行试试。
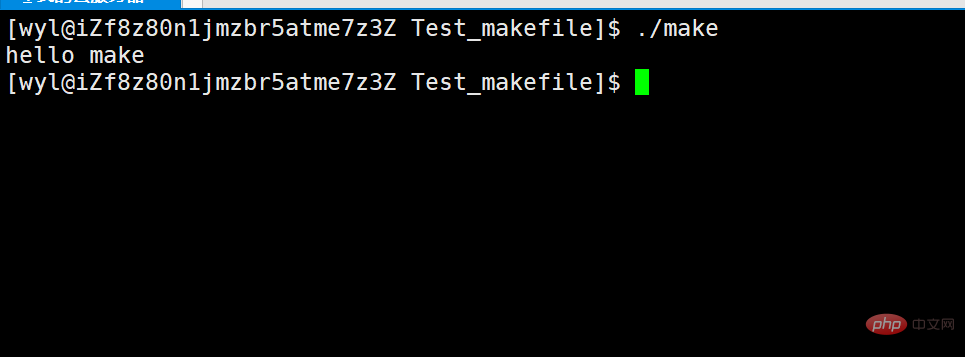
我们会发现这个可执行程序输出make。
这就是我们的自动化构建工具,只需要在Makefile里面配置一下。往后直接输入make即可编译代码。那我们再输入一次make试试。

提示我们 make程序是最新的。 也就是说,如果你没有修改或者更新程序的话。 那么则不会为你编译,因为你程序都没动呀,编译它干嘛。
那么此时我们回过来分析一下 Makefile里面写的代码。

首先我们把它分为三部分
make
make.c
gcc make.c -o make -std=c99
这三者的关系就是, make 是依赖于 make.c 产生的。 它们两者有依赖关系 , 而gcc make.c -o make -std=c99则是 make 依赖于 make.c的方法,叫依赖方法。
什么是依赖关系和依赖方法?
打个比方。
月底了,你的生活费用光了。 这个时候你给你爸爸打电话,和他说:“爸,月底了。我没钱了。"。此时你的爸爸就知道了,会给你打生活费。 这里面,你和你的父亲是父子关系,所以你依赖于你的父亲,你们之间有依赖关系。而你的父亲给你生活费,这是你依赖父亲的一种方式,所以这就是依赖方法。如果此时你给你室友的父亲打电话要生活费,他会直接让你滚。因为你们根本不构成依赖关系,不构成依赖关系就没有依赖方法。
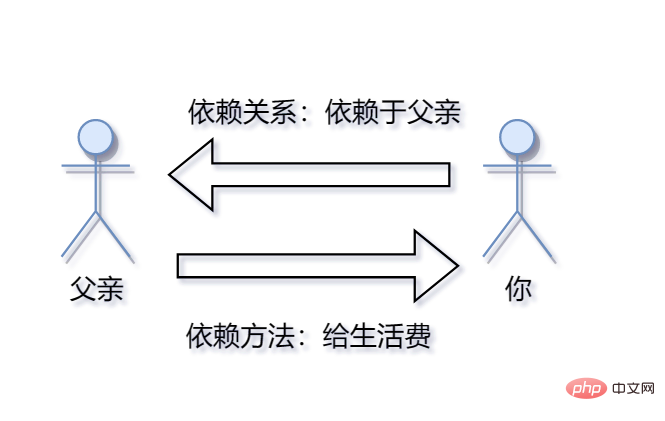
所以我的程序也是一样的。 make 是生成的可执行程序。 而它依赖于make.c,因为它是从 make.c编译来的。而依赖方法则是 执行 gcc make.c -o make -std=c99
Wir können feststellen, dass es ein zusätzliches ausführbares Programm gibt. Versuchen wir dann,
./makeauszuführen.🎜 Wir werden dieses ausführbare Programm als Ausgabe erstellen. 🎜🎜Dies ist unser automatisiertes Build-Tool, Sie müssen es nur im Makefile konfigurieren. Geben Sie dann direkt make ein, um den Code zu kompilieren. Versuchen wir dann noch einmal, make einzugeben. 🎜🎜
🎜🎜 Fordern Sie uns auf. Das Make-Programm ist auf dem neuesten Stand. Das heißt, wenn Sie das Programm nicht geändert oder aktualisiert haben. Dann wird es nicht für Sie kompiliert, weil Ihr Programm nicht berührt wurde. Warum es kompilieren? 🎜🎜Jetzt gehen wir zurück und analysieren den im Makefile geschriebenen Code. 🎜🎜
make🎜🎜make.c🎜🎜gcc make.c -o make -std=c99🎜 🎜 Die Beziehung zwischen den dreien besteht darin, dassmakevonmake.cabhängig ist. Die beiden haben eine 🎜Abhängigkeitsbeziehung🎜, undgcc make.c -o make -std=c99ist eine Methode von make, die von make.c abhängt, was als 🎜Abhängigkeitsmethode🎜 bezeichnet wird . 🎜🎜🎜Was sind Abhängigkeiten und Abhängigkeitsmethoden?🎜🎜🎜Eine Analogie. 🎜🎜Es ist das Ende des Monats und Ihre Lebenshaltungskosten sind weg. Zu diesem Zeitpunkt rufst du deinen Vater an und sagst ihm: „Papa, es ist das Ende des Monats. Ich habe kein Geld.“ Dein Vater wird es zu diesem Zeitpunkt wissen und dir die Lebenshaltungskosten zahlen. Hier haben Sie und Ihr Vater eine Vater-Sohn-Beziehung, Sie sind also von Ihrem Vater abhängig und es besteht eine „Abhängigkeitsbeziehung“ zwischen Ihnen. Und dein Vater zahlt dir die Lebenshaltungskosten, was für dich eine Möglichkeit ist, dich auf deinen Vater zu verlassen, also ist das die „Abhängigkeitsmethode“🎜. Wenn Sie zu diesem Zeitpunkt den Vater Ihres Mitbewohners anrufen und nach den Lebenshaltungskosten fragen, wird er Ihnen sagen, dass Sie aussteigen sollen. Weil Sie überhaupt keine Abhängigkeitsbeziehung haben. Wenn Sie keine Abhängigkeitsbeziehung haben, gibt es keine Abhängigkeitsmethode. 🎜🎜gcc make.c -o make -std=c99auszuführen. 🎜🎜🎜Das Prinzip der Abhängigkeit🎜🎜🎜🎜🎜🎜make sucht im aktuellen Verzeichnis nach einer Datei mit dem Namen „Makefile“ oder „makefile“. 🎜Wenn gefunden, wird die erste Zieldatei (Ziel) in der Datei gefunden. Im obigen Beispiel wird die Datei „Hallo“ gefunden und diese Datei als Endziel verwendet Datei.
Wenn die Hallo-Datei nicht existiert oder die Dateiänderungszeit der nachfolgenden test.o-Datei, von der Hallo abhängt, neuer ist als die Testdatei (können Sie verwenden). Zum Testen berühren), dann führt er den später definierten Befehl aus, um die Testdatei zu generieren.
Wenn die test.o-Datei, von der der Test abhängt, nicht existiert, sucht make nach der Abhängigkeit der Zieldatei test.o in der aktuellen Datei und Wenn es gefunden wird, wird die Datei test.o basierend auf dieser Regel generiert. (Dies ist ein bisschen wie ein Stapelprozess)
Natürlich sind Ihre C- und H-Dateien vorhanden, also generiert make die test.o-Datei und verwendet sie dann die Datei test.o, um die ultimative Aufgabe von make zu deklarieren, die darin besteht, den Dateitest auszuführen.
Dies ist die Abhängigkeit des gesamten Make. Make sucht Schicht für Schicht nach Dateiabhängigkeiten, bis die erste Zieldatei schließlich kompiliert ist.
Wenn während des Suchvorgangs ein Fehler auftritt, z. B. wenn die letzte abhängige Datei nicht gefunden werden kann, wird make direkt beendet und meldet einen Fehler für das definierte Make Fehler im Befehl oder fehlgeschlagene Kompilierung werden einfach ignoriert.
make kümmert sich nur um Dateiabhängigkeiten, das heißt, wenn die Datei nach dem Doppelpunkt immer noch nicht da ist, nachdem ich die Abhängigkeiten gefunden habe, dann tut mir leid, ich habe gewonnen Funktioniert nicht.
Reinigung
Wenn wir normalerweise Code schreiben, müssen wir den Code oft wiederholt kompilieren und ausführen.
Bevor Sie das nächste Mal neu kompilieren, müssen Sie das beim letzten Mal generierte ausführbare Programm bereinigen. Es kann jedoch sein, dass Sie beim Bereinigen einen Fehler machen und die Quelldatei versehentlich löschen, was wiederum zu Problemen führen kann.
Haben wir also eine Lösung? Die Antwort ist natürlich.
Wir bearbeiten weiterhin das Makefile.
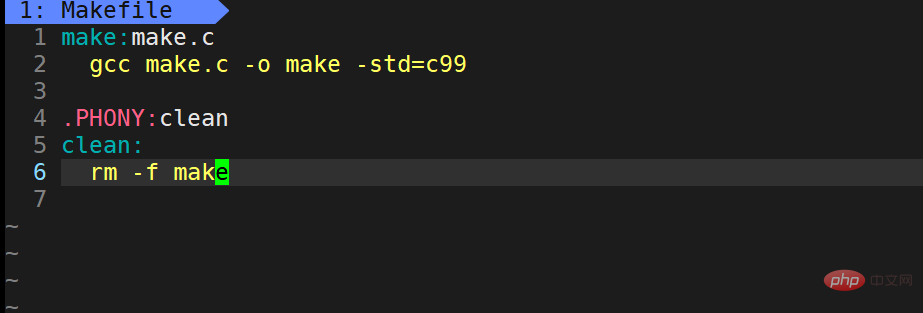
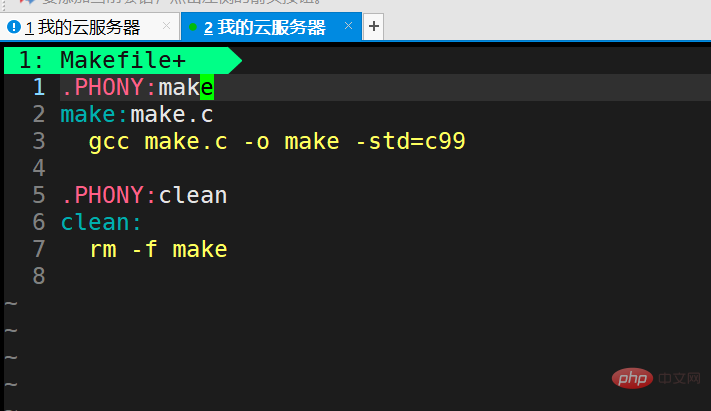
Wir haben
.PHONY:clean clean: rm -f make
auf der ursprünglichen Basis hinzugefügt.
.PHONY modifiziert ein Pseudoziel, das immer ausgeführt wird. clean ist ein selbstdefinierter Make-Befehl. Die Verwendungsmethode lautet make clean.PHONY修饰的是一个伪目标的,伪目标总是被执行的。clean是自己定义的一条make指令,使用方法为 make clean
那我们来试试吧这条指令
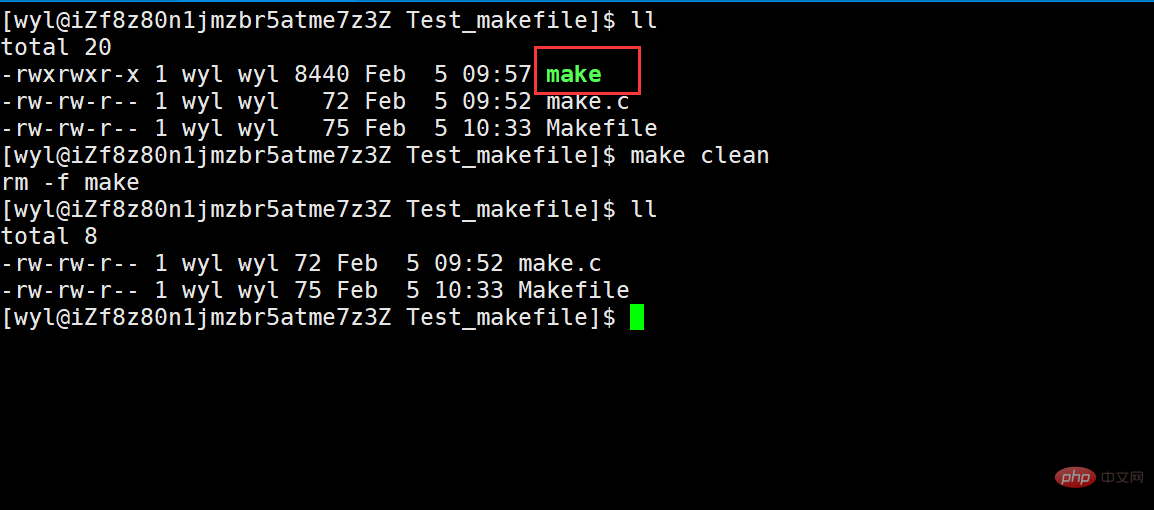
我们可以看到它被清理了,那为什么说伪目标它总是被执行的呢?我们多次执行它看看。
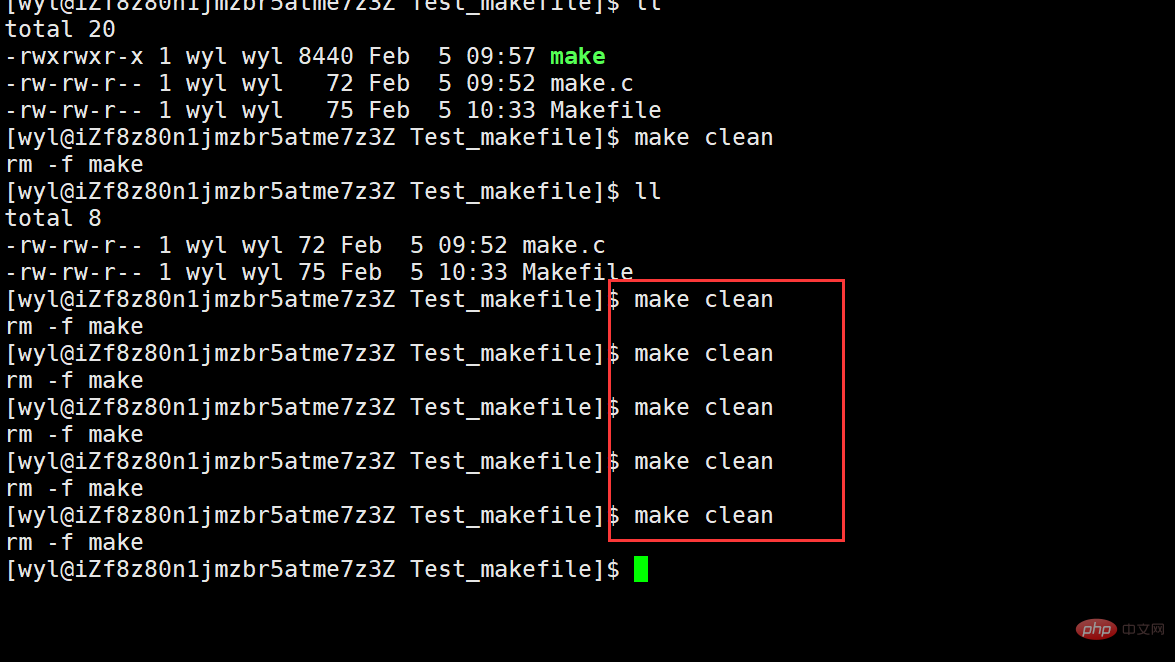
我们可以一直执行它,那么我们多次执行make呢?
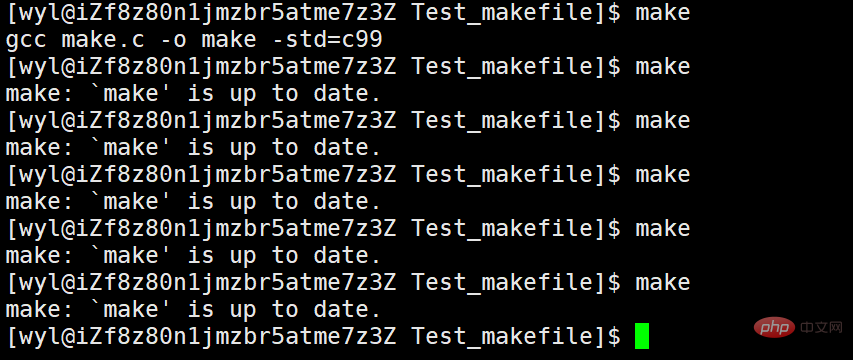
我们会发现,make执行了一次,就无法执行了,因为没有被.PHONY修饰。那么我用.PHONY修饰它再试试。
然后我们保存退出,多次执行make
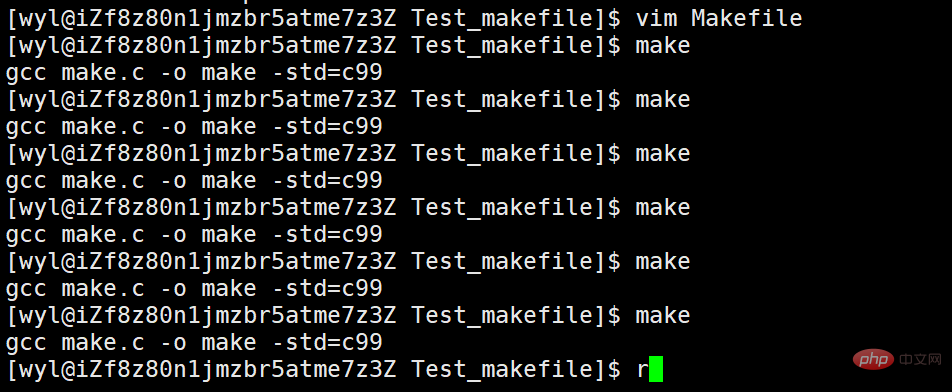
我们就可以看到它被多次执行了。但我觉得没有这个必要,因为文件没有被修改的话。重新编译没有意义,所以自动化编译不建议加上.PHONY
我们保存退出,多次执行make
我们就可以看到它被多次执行了。但我觉得没有这个必要,因为文件没有被修改的话。重新编译没有意义,所以自动化编译不建议加上.PHONY
 #🎜🎜##🎜🎜#Wir können sehen dass es bereinigt wurde, warum wird das Pseudoziel immer ausgeführt? Lassen Sie es uns mehrmals ausführen und sehen. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Wir können es ständig ausführen, aber was ist, wenn wir
#🎜🎜##🎜🎜#Wir können sehen dass es bereinigt wurde, warum wird das Pseudoziel immer ausgeführt? Lassen Sie es uns mehrmals ausführen und sehen. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Wir können es ständig ausführen, aber was ist, wenn wir make mehrmals ausführen? #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Wir werden feststellen, dass make nach einmaliger Ausführung nicht ausgeführt werden kann, da es nicht durch .PHONY geändert wird. Dann ändere ich es mit .PHONY und versuche es erneut. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Dann speichern und beenden wir, führen make mehrmals aus #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Wir können sehen, dass es mehrmals ausgeführt wird . Ich glaube jedoch nicht, dass dies notwendig ist, da die Datei nicht geändert wurde. Eine Neukompilierung macht keinen Sinn, daher wird nicht empfohlen, .PHONY#🎜🎜##🎜🎜# zur automatischen Kompilierung hinzuzufügen. Wir speichern und beenden und führen make#🎜 aus 🎜##🎜 mehrmals 🎜##🎜🎜# #🎜🎜#Wir können sehen, dass es mehrmals ausgeführt wird. Ich glaube jedoch nicht, dass dies notwendig ist, da die Datei nicht geändert wurde. Eine Neukompilierung macht keinen Sinn, daher wird nicht empfohlen, .PHONY#🎜🎜# zur automatischen Kompilierung hinzuzufügen.Das obige ist der detaillierte Inhalt vonSo verwenden Sie die automatisierten Linux-Build-Tools make und Makefile. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
Die Schritte zum Starten von Apache sind wie folgt: Installieren Sie Apache (Befehl: sudo apt-Get-Get-Installieren Sie Apache2 oder laden Sie ihn von der offiziellen Website herunter). (Optional, Linux: sudo systemctl
 Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Wenn der Port -80 -Port der Apache 80 besetzt ist, lautet die Lösung wie folgt: Finden Sie den Prozess, der den Port einnimmt, und schließen Sie ihn. Überprüfen Sie die Firewall -Einstellungen, um sicherzustellen, dass Apache nicht blockiert ist. Wenn die obige Methode nicht funktioniert, konfigurieren Sie Apache bitte so, dass Sie einen anderen Port verwenden. Starten Sie den Apache -Dienst neu.
 So überwachen Sie die NGINX SSL -Leistung auf Debian
Apr 12, 2025 pm 10:18 PM
So überwachen Sie die NGINX SSL -Leistung auf Debian
Apr 12, 2025 pm 10:18 PM
In diesem Artikel wird beschrieben, wie die SSL -Leistung von NGINX -Servern auf Debian -Systemen effektiv überwacht wird. Wir werden Nginxexporter verwenden, um Nginx -Statusdaten in Prometheus zu exportieren und sie dann visuell über Grafana anzeigen. Schritt 1: Konfigurieren von Nginx Erstens müssen wir das Modul stub_status in der nginx -Konfigurationsdatei aktivieren, um die Statusinformationen von Nginx zu erhalten. Fügen Sie das folgende Snippet in Ihre Nginx -Konfigurationsdatei hinzu (normalerweise in /etc/nginx/nginx.conf oder deren inklusive Datei): location/nginx_status {stub_status
 So richten Sie im Debian -System einen Recyclingbehälter ein
Apr 12, 2025 pm 10:51 PM
So richten Sie im Debian -System einen Recyclingbehälter ein
Apr 12, 2025 pm 10:51 PM
In diesem Artikel werden zwei Methoden zur Konfiguration eines Recycling -Bin in einem Debian -System eingeführt: eine grafische Schnittstelle und eine Befehlszeile. Methode 1: Verwenden Sie die grafische Schnittstelle Nautilus, um den Dateimanager zu öffnen: Suchen und starten Sie den Nautilus -Dateimanager (normalerweise als "Datei") im Menü Desktop oder Anwendungen. Suchen Sie den Recycle Bin: Suchen Sie nach dem Ordner recycelner Behälter in der linken Navigationsleiste. Wenn es nicht gefunden wird, klicken Sie auf "Andere Speicherort" oder "Computer", um sie zu suchen. Konfigurieren Sie Recycle Bin-Eigenschaften: Klicken Sie mit der rechten Maustaste auf "Recycle Bin" und wählen Sie "Eigenschaften". Im Eigenschaftenfenster können Sie die folgenden Einstellungen einstellen: Maximale Größe: Begrenzen Sie den im Recycle -Behälter verfügbaren Speicherplatz. Aufbewahrungszeit: Legen Sie die Erhaltung fest, bevor die Datei automatisch im Recyclingbehälter gelöscht wird
 So starten Sie den Apache -Server neu
Apr 13, 2025 pm 01:12 PM
So starten Sie den Apache -Server neu
Apr 13, 2025 pm 01:12 PM
Befolgen Sie die folgenden Schritte, um den Apache -Server neu zu starten: Linux/MacOS: Führen Sie sudo systemCTL RESTART APache2 aus. Windows: Net Stop Apache2.4 und dann Net Start Apache2.4 ausführen. Führen Sie Netstat -a | Findstr 80, um den Serverstatus zu überprüfen.
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
 So lösen Sie das Problem, dass Apache nicht gestartet werden kann
Apr 13, 2025 pm 01:21 PM
So lösen Sie das Problem, dass Apache nicht gestartet werden kann
Apr 13, 2025 pm 01:21 PM
Apache kann aus den folgenden Gründen nicht beginnen: Konfigurationsdatei -Syntaxfehler. Konflikt mit anderen Anwendungsports. Berechtigungen Ausgabe. Aus dem Gedächtnis. Prozess -Deadlock. Dämonversagen. Selinux -Berechtigungen Probleme. Firewall -Problem. Software -Konflikt.
