
 Technologie-Peripheriegeräte
KI
Das Modell der neuen Generation von OpenAI ist eine Open-Source-Explosion! Schneller und stärker als Diffusion, ein Werk des Tsinghua-Alumnus Song Yang
Technologie-Peripheriegeräte
KI
Das Modell der neuen Generation von OpenAI ist eine Open-Source-Explosion! Schneller und stärker als Diffusion, ein Werk des Tsinghua-Alumnus Song Yang
Das Modell der neuen Generation von OpenAI ist eine Open-Source-Explosion! Schneller und stärker als Diffusion, ein Werk des Tsinghua-Alumnus Song Yang

Der Bereich der Bilderzeugung scheint sich erneut zu verändern.
Gerade hat OpenAI ein Konsistenzmodell als Open-Source-Lösung bereitgestellt, das schneller und besser als das Diffusionsmodell ist:
Sie können qualitativ hochwertige Bilder ohne gegnerisches Training generieren!
Sobald diese Blockbuster-Nachricht veröffentlicht wurde, erregte sie sofort in der akademischen Welt Aufsehen.

Obwohl das Papier selbst im März unauffällig veröffentlicht wurde, glaubten damals alle allgemein, dass es sich nur um eine Spitzenforschung zu OpenAI handelte würde in Zukunft nicht wirklich verwendet werden.

Ich habe dieses Mal nicht direkt mit einer Open Source gerechnet. Einige Internetnutzer begannen sofort, den Effekt zu testen und stellten fest, dass es nur etwa 3,5 Sekunden dauert, um etwa 64 256×256 Bilder zu erzeugen:
Game over!

Das ist der Bildeffekt, der von diesem Internetnutzer erzeugt wurde, er sieht ziemlich gut aus:
#🎜🎜 #


 #🎜 🎜#Basierend auf dieser Idee muss das Konsistenzmodell nicht mehr lange Iterationen durchlaufen, um ein relativ hochwertiges Bild zu generieren, sondern kann in einem Schritt generiert werden.
#🎜 🎜#Basierend auf dieser Idee muss das Konsistenzmodell nicht mehr lange Iterationen durchlaufen, um ein relativ hochwertiges Bild zu generieren, sondern kann in einem Schritt generiert werden.
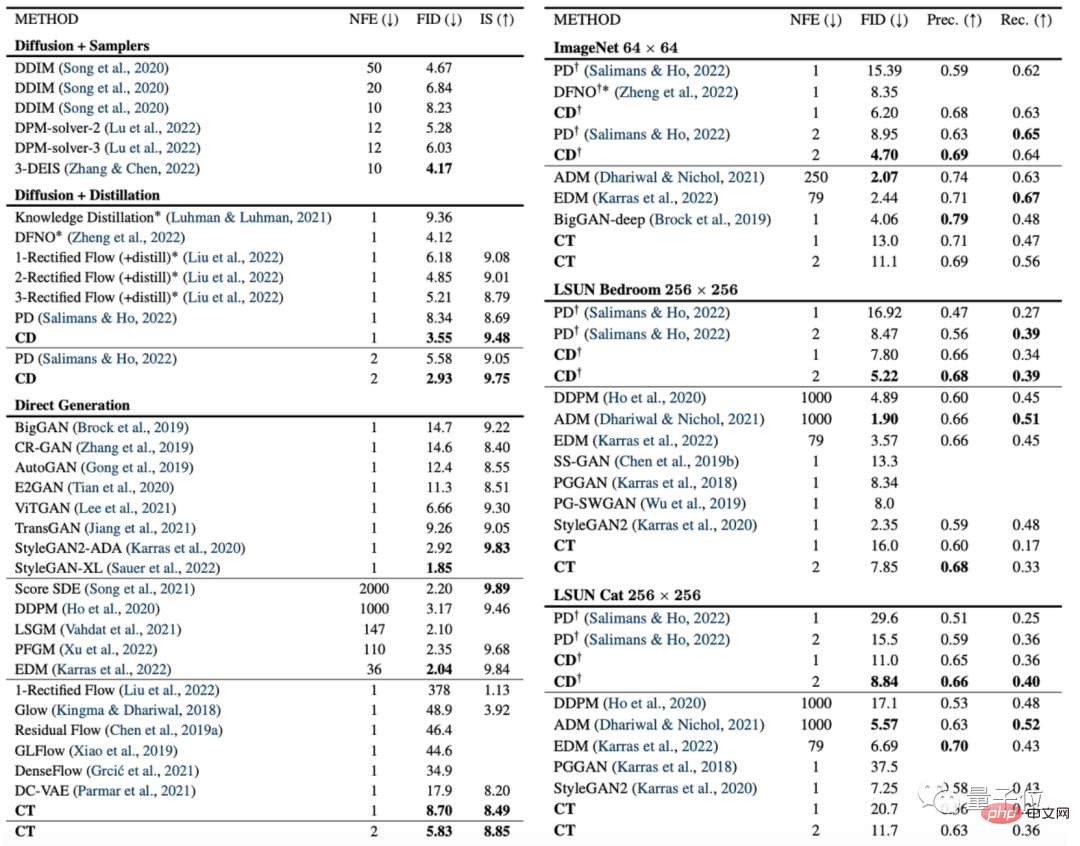
Die folgende Abbildung ist ein Vergleich des Konsistenzmodells (CD) und des Diffusionsmodells (PD) auf dem Bilderzeugungsindex FID.
Unter diesen ist PD die Abkürzung für progressive Destillation (progressive Destillation), eine neueste Diffusionsmodellmethode, die letztes Jahr von Stanford und Google Brain vorgeschlagen wurde, und CD (Konsistenzdestillation) ist die Konsistenzdestillationsmethode.
Es ist ersichtlich, dass der Bilderzeugungseffekt des Konsistenzmodells bei fast allen Datensätzen besser ist als der des Diffusionsmodells. Die einzige Ausnahme ist der 256 × 256-Raumdatensatz: #🎜🎜 #
Darüber hinaus verglichen die Autoren auch Modelle wie Diffusionsmodell, Konsistenzmodell und GAN an verschiedenen anderen Datensätzen: #🎜🎜 #
Einige Internetnutzer erwähnten jedoch, dass die vom Open-Source-KI-Konsistenzmodell generierten Bilder dieses Mal immer noch zu klein sind:
Es ist traurig, dass die von der Open-Source-Version generierten Bilder dieses Mal immer noch zu klein sind Das Generieren einer Open-Source-Version größerer Bilder wäre auf jeden Fall spannend.
Einige Internetnutzer spekulierten auch, dass OpenAI möglicherweise noch nicht trainiert wurde. Aber möglicherweise können wir den Code nach dem Training nicht erhalten (manueller Hundekopf).
Aber bezüglich der Bedeutung dieser Arbeit sagte TechCrunch:
Wenn Sie über eine Reihe von GPUs verfügen, verwenden Sie das Diffusionsmodell, um mehr als 1.500 Mal in ein oder zwei Minuten zu iterieren, und der Effekt der Generierung von Bildern wird natürlich sein exzellent.
Aber wenn Sie Bilder in Echtzeit auf Ihrem Telefon oder während eines Chat-Gesprächs generieren möchten, ist das Diffusionsmodell offensichtlich nicht die beste Wahl.
Konsistenzmodell ist der nächste wichtige Schritt von OpenAI.
Ich freue mich auf OpenAI Open Source, eine Welle von Bilderzeugungs-KI mit höherer Auflösung ~
Tsinghua-Alumnus Song Yang ist der erste Autor
Song Yang ist der erste Autor des Papiers und derzeit wissenschaftlicher Mitarbeiter bei OpenAI.

Als er 14 Jahre alt war, wurde er mit einstimmigem Votum von 17 Richtern in das „Tsinghua University New Centenary Leadership Program“ aufgenommen. Bei der Aufnahmeprüfung für das College im folgenden Jahr wurde er der beste Schüler in Naturwissenschaften in der Stadt Lianyungang und wurde erfolgreich an der Tsinghua-Universität aufgenommen.
Im Jahr 2016 schloss Song Yang den Grundkurs für Mathematik und Physik an der Tsinghua-Universität ab und ging dann zum weiteren Studium nach Stanford. Im Jahr 2022 erhielt Song Yang seinen Doktortitel in Informatik von Stanford und wechselte dann zu OpenAI.
Während seiner Doktorarbeit gewann seine erste Arbeit „Score-Based Generative Modeling through Stochastic Differential Equations“ auch den ICLR 2021 Outstanding Paper Award.

Laut Informationen auf seiner persönlichen Homepage wird Song Yang ab Januar 2024 offiziell als Assistenzprofessor in die Abteilung für Elektronik und Computermathematische Wissenschaften des California Institute of Technology eintreten.
Projektadresse:
https://www.php.cn/link/4845b84d63ea5fa8df6268b8d1616a8f
Papieradresse:
https://www.php.cn/link/5f25fbe144e4a81a1 b00 80b6c1032778
Referenzlink:
[1]https://twitter.com/alfredplpl/status/1646217811898011648
[2]https://twitter.com/_akhaliq/status/1646168119658831874
Das obige ist der detaillierte Inhalt vonDas Modell der neuen Generation von OpenAI ist eine Open-Source-Explosion! Schneller und stärker als Diffusion, ein Werk des Tsinghua-Alumnus Song Yang. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Projektlink vorne geschrieben: https://nianticlabs.github.io/mickey/ Anhand zweier Bilder kann die Kameraposition zwischen ihnen geschätzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere geschätzten Posen sind maßstabsunabhängig. Einige Anwendungen, wie z. B. Instant Augmented Reality jederzeit und überall, erfordern eine Posenschätzung von Skalenmetriken und sind daher auf externe Tiefenschätzer angewiesen, um die Skalierung wiederherzustellen. In diesem Artikel wird MicKey vorgeschlagen, ein Keypoint-Matching-Prozess, mit dem metrische Korrespondenzen im 3D-Kameraraum vorhergesagt werden können. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern können wir auf metrische Relativwerte schließen
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
 Docker schließt die lokale Bereitstellung des großen Open-Source-Modells LLama3 in drei Minuten ab
Apr 26, 2024 am 10:19 AM
Docker schließt die lokale Bereitstellung des großen Open-Source-Modells LLama3 in drei Minuten ab
Apr 26, 2024 am 10:19 AM
Übersicht LLaMA-3 (LargeLanguageModelMetaAI3) ist ein groß angelegtes Open-Source-Modell für generative künstliche Intelligenz, das von Meta Company entwickelt wurde. Im Vergleich zur Vorgängergeneration LLaMA-2 gibt es keine wesentlichen Änderungen in der Modellstruktur. Das LLaMA-3-Modell ist in verschiedene Maßstabsversionen unterteilt, darunter kleine, mittlere und große, um unterschiedlichen Anwendungsanforderungen und Rechenressourcen gerecht zu werden. Die Parametergröße kleiner Modelle beträgt 8 B, die Parametergröße mittlerer Modelle beträgt 70 B und die Parametergröße großer Modelle erreicht 400 B. Beim Training besteht das Ziel jedoch darin, multimodale und mehrsprachige Funktionalität zu erreichen, und die Ergebnisse werden voraussichtlich mit GPT4/GPT4V vergleichbar sein. Ollama installierenOllama ist ein Open-Source-Großsprachenmodell (LL
