
 Backend-Entwicklung
Python-Tutorial
11 mit Python heruntergeladene Haltungen, jede fortgeschrittener als die andere
Backend-Entwicklung
Python-Tutorial
11 mit Python heruntergeladene Haltungen, jede fortgeschrittener als die andere
11 mit Python heruntergeladene Haltungen, jede fortgeschrittener als die andere


Im Folgenden erfahren Sie, wie Sie verschiedene Herausforderungen meistern, auf die Sie möglicherweise stoßen, z. B. das Herunterladen umgeleiteter Dateien, das Herunterladen großer Dateien, das Durchführen eines Multithread-Downloads und andere Strategien.
1. Anfragen verwenden
Sie können das Anfragemodul verwenden, um Dateien von einer URL herunterzuladen.
Bedenken Sie den folgenden Code:

Sie verwenden einfach die get-Methode des Anforderungsmoduls, um die URL abzurufen und zu speichern Ergebnis in eine Variable mit dem Namen „myfile“. Schreiben Sie dann den Inhalt dieser Variablen in die Datei.
2. Verwendung von wget Sie können das Wget-Modul mit pip installieren, indem Sie dem Befehl folgen:
Betrachten Sie den folgenden Code, den wir zum Herunterladen des Logobilds für Python verwenden werden. 
In diesem Code werden die URL und der Pfad (wo das Bild gespeichert wird) an die Download-Methode des Wget-Moduls übergeben.
3. Umgeleitete Dateien herunterladen 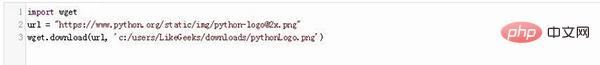
Um diese PDF-Datei herunterzuladen, verwenden Sie den folgenden Code:
 # 🎜🎜#
# 🎜🎜#
 4. Laden Sie große Dateien in Blöcken herunter
4. Laden Sie große Dateien in Blöcken herunter
Betrachten Sie den folgenden Code:
Wir verwenden die Get-Methode des Requests-Moduls wie zuvor, aber dieses Mal setzen wir die Stream-Eigenschaft auf True. Als nächstes erstellen wir eine Datei namens PythonBook.pdf im aktuellen Arbeitsverzeichnis und öffnen sie zum Schreiben. Dann geben wir jedes Mal die Blockgröße an, die heruntergeladen werden soll. Wir haben es auf 1024 Bytes festgelegt, dann jeden Block durchlaufen und diese Blöcke bis zum Ende des Blocks in die Datei geschrieben.
Dann geben wir jedes Mal die Blockgröße an, die heruntergeladen werden soll. Wir haben es auf 1024 Bytes festgelegt, dann jeden Block durchlaufen und diese Blöcke bis zum Ende des Blocks in die Datei geschrieben.
Ist es nicht schön? Keine Sorge, wir zeigen später einen Fortschrittsbalken des Downloadvorgangs an.
5. Mehrere Dateien herunterladen (parallel/Batch-Download)
Um mehrere Dateien gleichzeitig herunterzuladen, importieren Sie bitte das folgende Modul:
#🎜 🎜#
Wir haben die Betriebssystem- und Zeitmodule importiert, um zu überprüfen, wie lange das Herunterladen der Datei dauert. Mit dem ThreadPool-Modul können Sie mehrere Threads oder Prozesse mithilfe eines Pools ausführen.
Erstellen wir eine einfache Funktion, die die Antwort auf eine Datei aufteilt:

Diese URL ist ein zweidimensionales A-Array Gibt den Pfad und die URL der Seite an, die Sie herunterladen möchten.
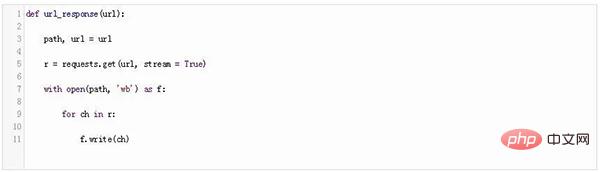 Genau wie im vorherigen Abschnitt übergeben wir diese URL an request.get. Abschließend öffnen wir die Datei (den in der URL angegebenen Pfad) und schreiben den Seiteninhalt.
Genau wie im vorherigen Abschnitt übergeben wir diese URL an request.get. Abschließend öffnen wir die Datei (den in der URL angegebenen Pfad) und schreiben den Seiteninhalt.
Jetzt können wir diese Funktion für jede URL einzeln aufrufen, oder wir können diese Funktion für alle URLs gleichzeitig aufrufen. Rufen wir diese Funktion für jede URL separat in einer for-Schleife auf und achten dabei auf den Timer: 🎜🎜#

Führen Sie das Skript aus.
6. Verwenden Sie den Fortschrittsbalken zum Herunterladen
Der Fortschrittsbalken ist eine UI-Komponente des Clint-Moduls. Geben Sie den folgenden Befehl ein, um das Clint-Modul zu installieren:

Beachten Sie den folgenden Code:
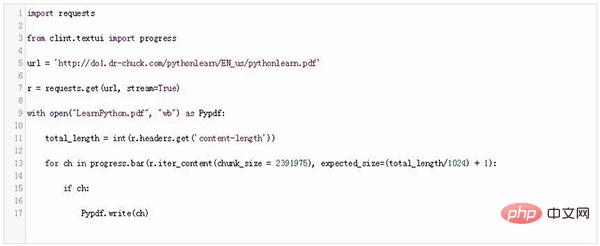 #🎜🎜 ##🎜 🎜#In diesem Code haben wir zuerst das Anforderungsmodul und dann die Fortschrittskomponente aus clint.textui importiert. Der einzige Unterschied besteht in der for-Schleife. Beim Schreiben von Inhalten in eine Datei verwenden wir die Balkenmethode des Fortschrittsbalkenmoduls.
#🎜🎜 ##🎜 🎜#In diesem Code haben wir zuerst das Anforderungsmodul und dann die Fortschrittskomponente aus clint.textui importiert. Der einzige Unterschied besteht in der for-Schleife. Beim Schreiben von Inhalten in eine Datei verwenden wir die Balkenmethode des Fortschrittsbalkenmoduls.
7. Verwenden Sie urllib, um eine Webseite herunterzuladen.
In diesem Abschnitt verwenden wir urllib, um eine Webseite herunterzuladen.
Die urllib-Bibliothek ist die Standardbibliothek von Python, Sie müssen sie also nicht installieren.
Mit den folgenden Codezeilen können Sie ganz einfach eine Webseite herunterladen:
 Geben Sie hier an, welche Datei gespeichert werden soll wofür und wofür Sie es haben möchten. Die URL, wo es gespeichert werden soll.
Geben Sie hier an, welche Datei gespeichert werden soll wofür und wofür Sie es haben möchten. Die URL, wo es gespeichert werden soll.
 In diesem Code verwenden wir die URLretrieve-Methode und übergeben die URL der Datei sowie den Pfad zum Speichern der Datei. Die Dateierweiterung lautet .html.
In diesem Code verwenden wir die URLretrieve-Methode und übergeben die URL der Datei sowie den Pfad zum Speichern der Datei. Die Dateierweiterung lautet .html.
8. Download über Proxy
Wenn Sie zum Herunterladen Ihrer Dateien einen Proxy verwenden müssen, können Sie den ProxyHandler des urllib-Moduls verwenden. Bitte schauen Sie sich den folgenden Code an:
 In diesem Code erstellen wir das Proxy-Objekt und öffnen den Proxy, indem wir die build_opener-Methode von urllib aufrufen und übergeben Proxy-Objekt. Dann erstellen wir eine Anfrage, um die Seite abzurufen.
In diesem Code erstellen wir das Proxy-Objekt und öffnen den Proxy, indem wir die build_opener-Methode von urllib aufrufen und übergeben Proxy-Objekt. Dann erstellen wir eine Anfrage, um die Seite abzurufen.
Darüber hinaus können Sie auch das Anforderungsmodul verwenden, wie in der offiziellen Dokumentation beschrieben:
 Sie müssen nur importieren das Anforderungsmodul und erstellen Sie Ihr Proxy-Objekt. Dann können Sie die Datei erhalten.
Sie müssen nur importieren das Anforderungsmodul und erstellen Sie Ihr Proxy-Objekt. Dann können Sie die Datei erhalten.
9. Verwenden Sie urllib3
urllib3 ist eine verbesserte Version des urllib-Moduls. Sie können es mit pip herunterladen und installieren:
 Wir werden urllib3 verwenden, um eine Webseite abzurufen und sie in einer Textdatei zu speichern.
Wir werden urllib3 verwenden, um eine Webseite abzurufen und sie in einer Textdatei zu speichern.
Importieren Sie die folgenden Module:
 Bei der Verarbeitung von Dateien verwenden wir das Shutil-Modul.
Bei der Verarbeitung von Dateien verwenden wir das Shutil-Modul.
Jetzt initialisieren wir die URL-String-Variable wie folgt:
 Dann verwenden wir den PoolManager von urllib3, der die erforderlichen Verbindungspools erstellt werden verfolgt.
Dann verwenden wir den PoolManager von urllib3, der die erforderlichen Verbindungspools erstellt werden verfolgt.
 Erstellen Sie eine Datei:
Erstellen Sie eine Datei:
 Schließlich senden wir ein GET Fordern Sie an, die URL zu erhalten und eine Datei zu öffnen, und schreiben Sie dann die Antwort auf die Datei:
Schließlich senden wir ein GET Fordern Sie an, die URL zu erhalten und eine Datei zu öffnen, und schreiben Sie dann die Antwort auf die Datei:
 10 Dateien von S3 mit Boto3 herunterladen
10 Dateien von S3 mit Boto3 herunterladen
Um Dateien von Amazon S3 herunterzuladen, können Sie das Python-Boto3-Modul verwenden.
Bevor Sie beginnen, müssen Sie das awscli-Modul mit pip installieren:
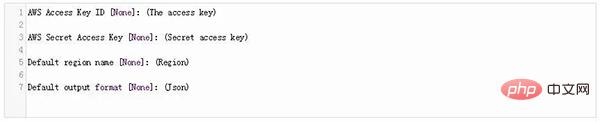
 Führen Sie für die AWS-Konfiguration den folgenden Befehl aus : # 🎜🎜#
Führen Sie für die AWS-Konfiguration den folgenden Befehl aus : # 🎜🎜#
Geben Sie nun Ihre Daten ein, indem Sie den folgenden Befehl drücken:
Um Dateien von Amazon S3 herunterzuladen, müssen Sie boto3 und botocore importieren. Boto3 ist ein Amazon SDK, das Python den Zugriff auf Amazon-Webdienste (wie S3) ermöglicht. Botocore bietet einen Befehlszeilendienst für die Interaktion mit Amazon-Webdiensten.
Botocore wird mit awscli geliefert. Um boto3 zu installieren, führen Sie den folgenden Befehl aus:

Importieren Sie nun diese beiden Module:

Beim Herunterladen der Datei von Amazon benötigen wir drei Parameter:
- Bucket-Name
- Sie müssen The herunterladen Name der Datei
- Der Name der Datei, nachdem sie heruntergeladen wurde
Initialisierungsvariable:

Jetzt initialisieren wir eine Variable, um die Ressourcen der Sitzung zu nutzen. Dazu rufen wir die Methode „resource()“ von boto3 auf und übergeben den Dienst s3:

Zum Schluss laden wir die Datei mit der Methode „download_file“ herunter und übergeben die Variable:

11. Verwenden des asyncio
asyncio-Moduls Wird hauptsächlich zur Verarbeitung von Systemereignissen verwendet. Es funktioniert um eine Ereignisschleife herum, die auf das Eintreten eines Ereignisses wartet und dann auf dieses Ereignis reagiert. Die Reaktion kann darin bestehen, eine andere Funktion aufzurufen. Dieser Vorgang wird als Ereignisverarbeitung bezeichnet. Das Asyncio-Modul verwendet Coroutinen für die Ereignisverarbeitung.
Um die Asyncio-Ereignisbehandlung und die Coroutine-Funktionalität zu nutzen, importieren wir das Asyncio-Modul:

Definieren Sie nun die Asyncio-Coroutine-Methode wie folgt:

Das Schlüsselwort async bedeutet, dass es sich um eine native Asyncio-Coroutine handelt. Innerhalb der Coroutine haben wir ein Schlüsselwort „await“, das einen bestimmten Wert zurückgibt. Wir können auch das Schlüsselwort return verwenden.
Jetzt erstellen wir einen Code, um mithilfe von Coroutine eine Datei von einer Website herunterzuladen:
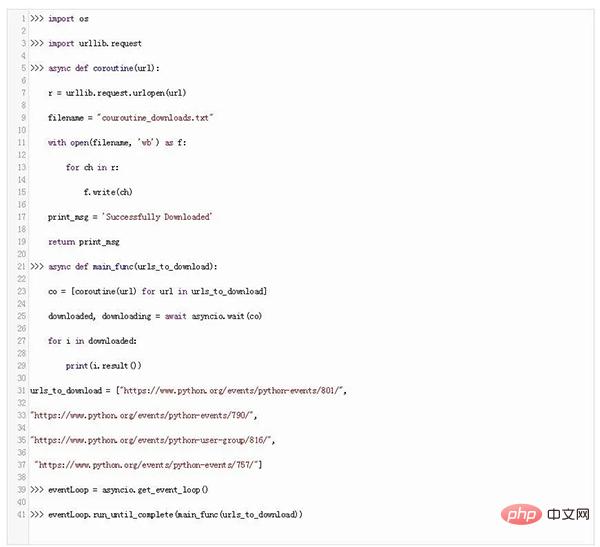
In diesem Code haben wir eine asynchrone Coroutine-Funktion erstellt, die unsere Datei herunterlädt und eine Nachricht zurückgibt.
Dann rufen wir main_func mit einer anderen asynchronen Coroutine auf, die auf URLs wartet und alle URLs in einer Warteschlange gruppiert. Die Wartefunktion von Asyncio wartet auf den Abschluss der Coroutine.
Um nun die Coroutine zu starten, müssen wir die Coroutine mit der Methode get_event_loop() von Asyncio in eine Ereignisschleife versetzen und schließlich diese Ereignisschleife mit der Methode run_until_complete() von Asyncio ausführen.
Das Herunterladen von Dateien mit Python macht Spaß. Ich hoffe, dieses Tutorial ist nützlich für Sie!
Das obige ist der detaillierte Inhalt von11 mit Python heruntergeladene Haltungen, jede fortgeschrittener als die andere. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Minio-Objektspeicherung: Hochleistungs-Bereitstellung im Rahmen von CentOS System Minio ist ein hochleistungsfähiges, verteiltes Objektspeichersystem, das auf der GO-Sprache entwickelt wurde und mit Amazons3 kompatibel ist. Es unterstützt eine Vielzahl von Kundensprachen, darunter Java, Python, JavaScript und Go. In diesem Artikel wird kurz die Installation und Kompatibilität von Minio zu CentOS -Systemen vorgestellt. CentOS -Versionskompatibilitätsminio wurde in mehreren CentOS -Versionen verifiziert, einschließlich, aber nicht beschränkt auf: CentOS7.9: Bietet einen vollständigen Installationshandbuch für die Clusterkonfiguration, die Umgebungsvorbereitung, die Einstellungen von Konfigurationsdateien, eine Festplattenpartitionierung und Mini
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
 So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
Bei der Installation von PyTorch am CentOS -System müssen Sie die entsprechende Version sorgfältig auswählen und die folgenden Schlüsselfaktoren berücksichtigen: 1. Kompatibilität der Systemumgebung: Betriebssystem: Es wird empfohlen, CentOS7 oder höher zu verwenden. CUDA und CUDNN: Pytorch -Version und CUDA -Version sind eng miteinander verbunden. Beispielsweise erfordert Pytorch1.9.0 CUDA11.1, während Pytorch2.0.1 CUDA11.3 erfordert. Die Cudnn -Version muss auch mit der CUDA -Version übereinstimmen. Bestimmen Sie vor der Auswahl der Pytorch -Version unbedingt, dass kompatible CUDA- und CUDNN -Versionen installiert wurden. Python -Version: Pytorch Official Branch
 Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python zeichnet sich in Automatisierung, Skript und Aufgabenverwaltung aus. 1) Automatisierung: Die Sicherungssicherung wird durch Standardbibliotheken wie OS und Shutil realisiert. 2) Skriptschreiben: Verwenden Sie die PSUTIL -Bibliothek, um die Systemressourcen zu überwachen. 3) Aufgabenverwaltung: Verwenden Sie die Zeitplanbibliothek, um Aufgaben zu planen. Die Benutzerfreundlichkeit von Python und die Unterstützung der reichhaltigen Bibliothek machen es zum bevorzugten Werkzeug in diesen Bereichen.
