
 Backend-Entwicklung
Python-Tutorial
So implementieren Sie das Kopieren von Objekten und das Speicherlayout in Python
Backend-Entwicklung
Python-Tutorial
So implementieren Sie das Kopieren von Objekten und das Speicherlayout in Python
So implementieren Sie das Kopieren von Objekten und das Speicherlayout in Python

Vorwort
Kennen Sie die Ausgabeergebnisse einiger der folgenden Programmausschnitte?
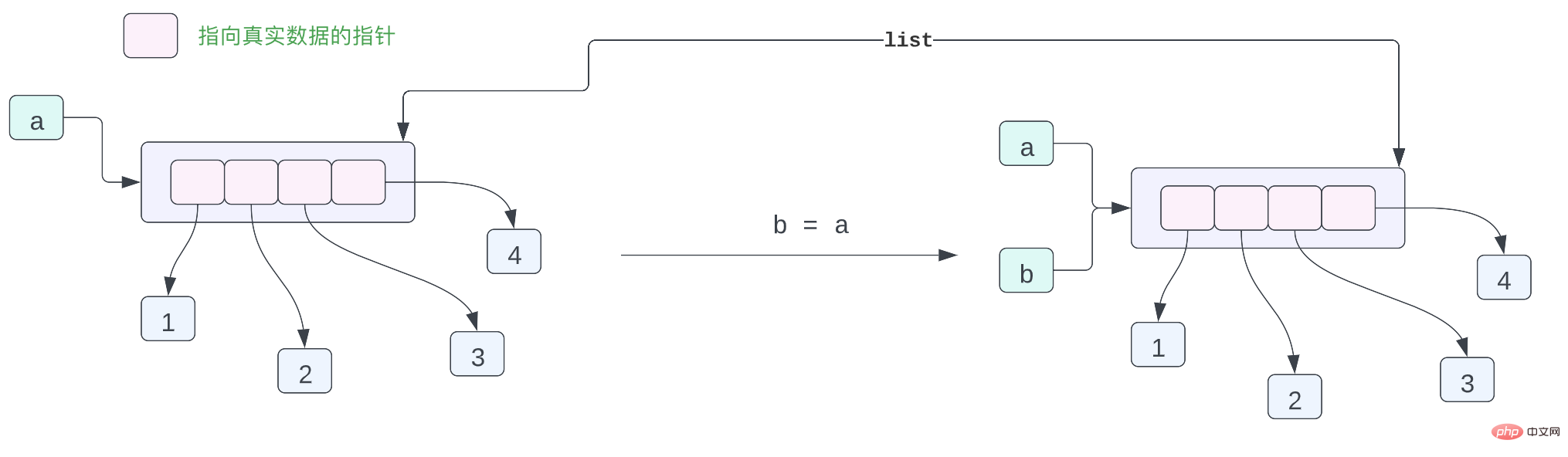
a = [1, 2, 3, 4]
b = a
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")a = [1, 2, 3, 4]
b = a.copy()
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")a = [[1, 2, 3], 2, 3, 4]
b = a.copy()
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")a = [[1, 2, 3], 2, 3, 4]
b = copy.copy(a)
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")a = [[1, 2, 3], 2, 3, 4]
b = copy.deepcopy(a)
print(f"{a = } \t|\t {b = }")
a[0][0] = 100
print(f"{a = } \t|\t {b = }")Speicherlayout von Python-Objekten
Wie sollen wir die Speicheradresse eines Objekts in Python bestimmen? Python stellt uns eine eingebettete Funktion id() zur Verfügung, um die Speicheradresse eines Objekts abzurufen:
a = [1, 2, 3, 4]
b = a
print(f"{a = } \t|\t {b = }")
a[0] = 100
print(f"{a = } \t|\t {b = }")
print(f"{id(a) = } \t|\t {id(b) = }")
# 输出结果
# a = [1, 2, 3, 4] | b = [1, 2, 3, 4]
# a = [100, 2, 3, 4] | b = [100, 2, 3, 4]
# id(a) = 4393578112 | id(b) = 4393578112Tatsächlich liegt ein Problem mit dem Speicherlayout des oben genannten Objekts vor, oder es ist nicht genau genug, aber es kann trotzdem sein ausgedrückt Schauen wir uns die Beziehung zwischen den einzelnen Objekten genauer an. In Cpython können Sie sich jede Variable als Zeiger vorstellen, der auf die dargestellten Daten zeigt. Dieser Zeiger speichert die Speicheradresse des Python-Objekts.
In Python speichert die Liste tatsächlich Zeiger auf jedes Python-Objekt, nicht die tatsächlichen Daten. Daher kann der obige kleine Codeabschnitt verwendet werden, um das Layout der Objekte im Speicher wie folgt darzustellen:
Variablen a zeigt auf die Liste [1, 2, 3, 4] im Speicher. Diese vier Daten sind Zeiger, und diese vier Zeiger zeigen auf 1, 2 im Speicher 3,4 diese vier Daten. Sie haben vielleicht Fragen, ist das nicht ein Problem? Da es sich bei allen um ganzzahlige Daten handelt, warum sollten wir die ganzzahligen Daten nicht direkt in der Liste speichern? Warum müssen wir einen Zeiger hinzufügen, der auf diese Daten zeigt? [1, 2, 3, 4],列表当中有 4 个数据,这四个数据都是指针,而这四个指针指向内存当中 1,2,3,4 这四个数据。可能你会有疑问,这不是有问题吗?都是整型数据为什么不直接在列表当中存放整型数据,为啥还要加一个指针,再指向这个数据呢?
事实上在 Python 当中,列表当中能够存放任何 Python 对象,比如下面的程序是合法的:
data = [1, {1:2, 3:4}, {'a', 1, 2, 25.0}, (1, 2, 3), "hello world"]在上面的列表当中第一个到最后一个数据的数据类型为:整型数据,字典,集合,元祖,字符串,现在来看为了实现 Python 的这个特性,指针的特性是不是符合要求呢?每个指针所占用的内存是一样的,因此可以使用一个数组去存储 Python 对象的指针,然后再将这个指针指向真正的 Python 对象!
牛刀小试
在经过上面的分析之后,我们来看一下下面的代码,他的内存布局是什么情况:
data = [[1, 2, 3], 4, 5, 6] data_assign = data data_copy = data.copy()
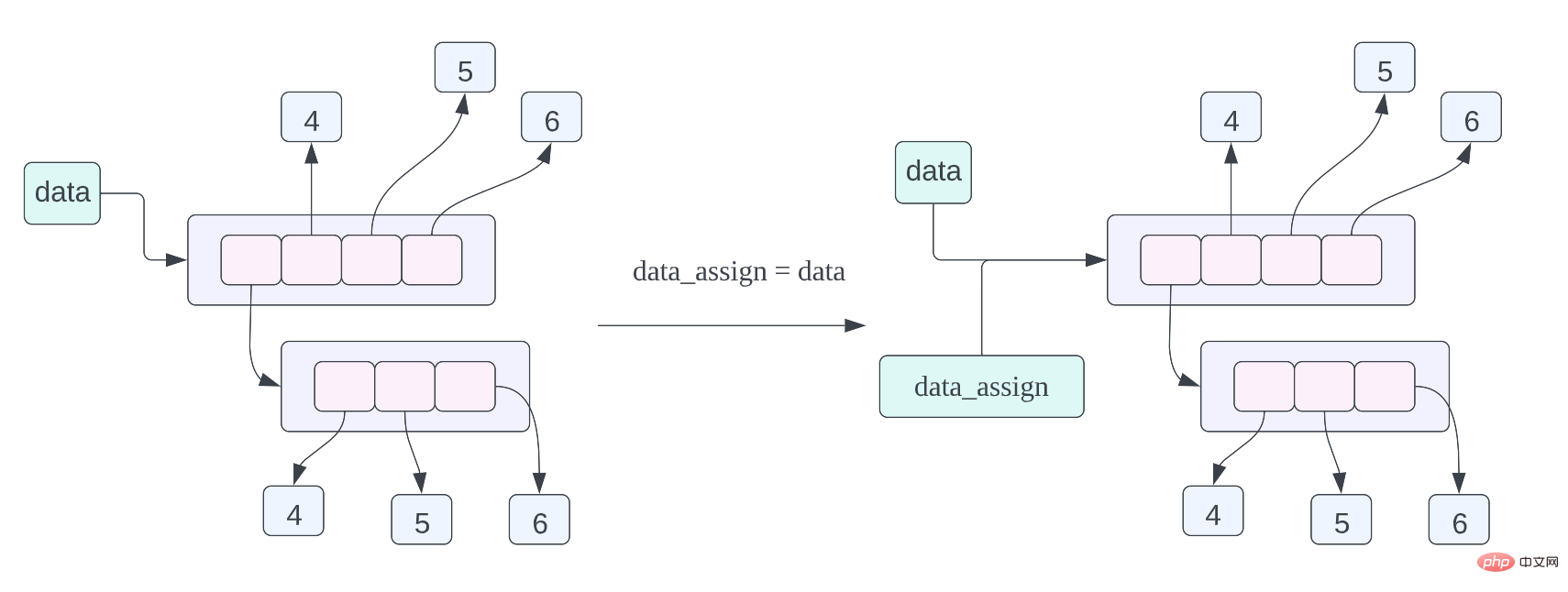
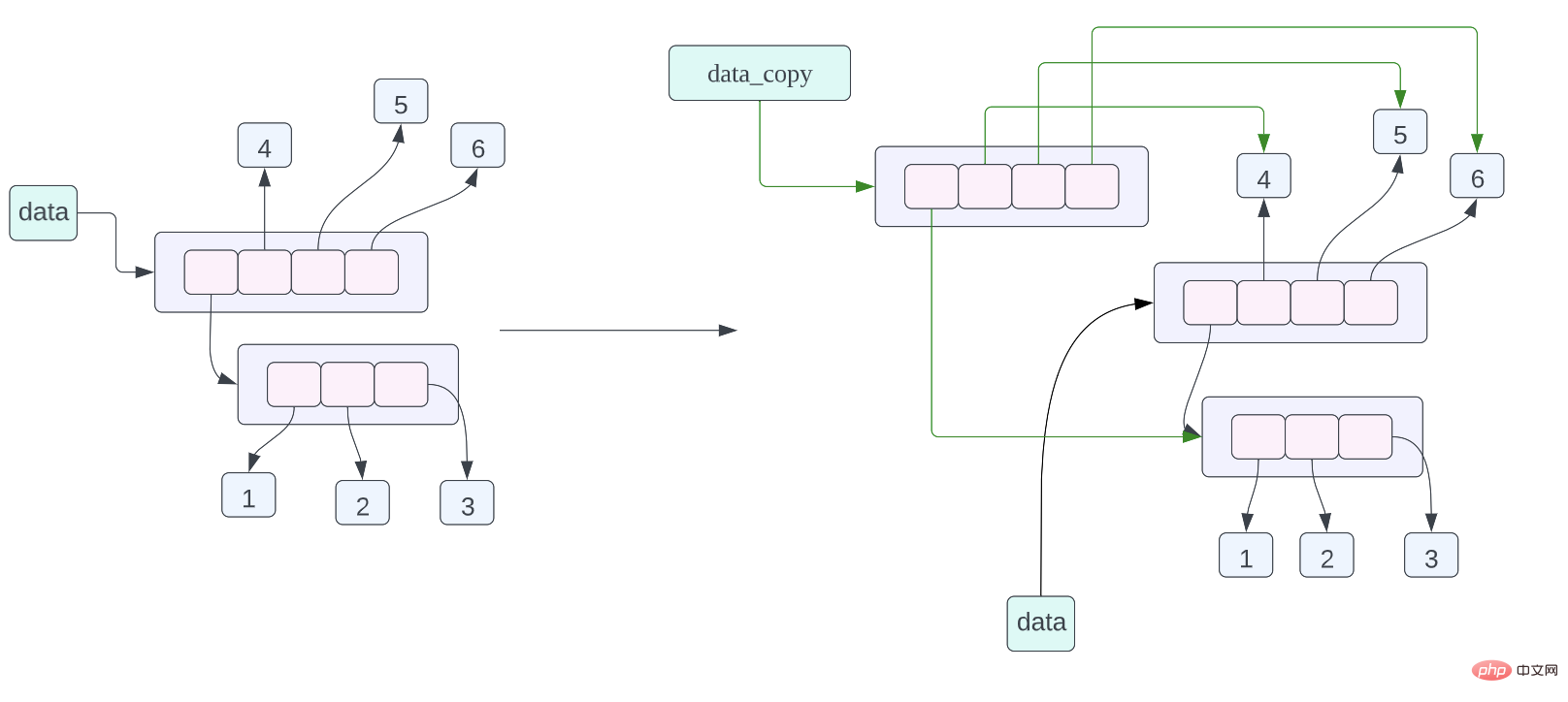
data_assign = data,关于这个赋值语句的内存布局我们在之前已经谈到过了,不过我们也再复习一下,这个赋值语句的含义就是 data_assign 和 data 指向的数据是同一个数据,也就是同一个列表。
Tatsächlich kann in Python jedes Python-Objekt in einer Liste gespeichert werden. Beispielsweise ist das folgende Programm zulässig:data_copy = data.copy()
a = [1, 2, 3]
b = a
print(f"{id(a) = } {id(b) = }")
for i in range(len(a)):
print(f"{i = } {id(a[i]) = } {id(b[i]) = }")Schnelltest
Nach der obigen Analyse werfen wir einen Blick auf das Speicherlayout des folgenden Codes: a = [[1, 2, 3], 4, 5]
b = a.copy()
print(f"{id(a) = } {id(b) = }")
for i in range(len(a)):
print(f"{i = } {id(a[i]) = } {id(b[i]) = }")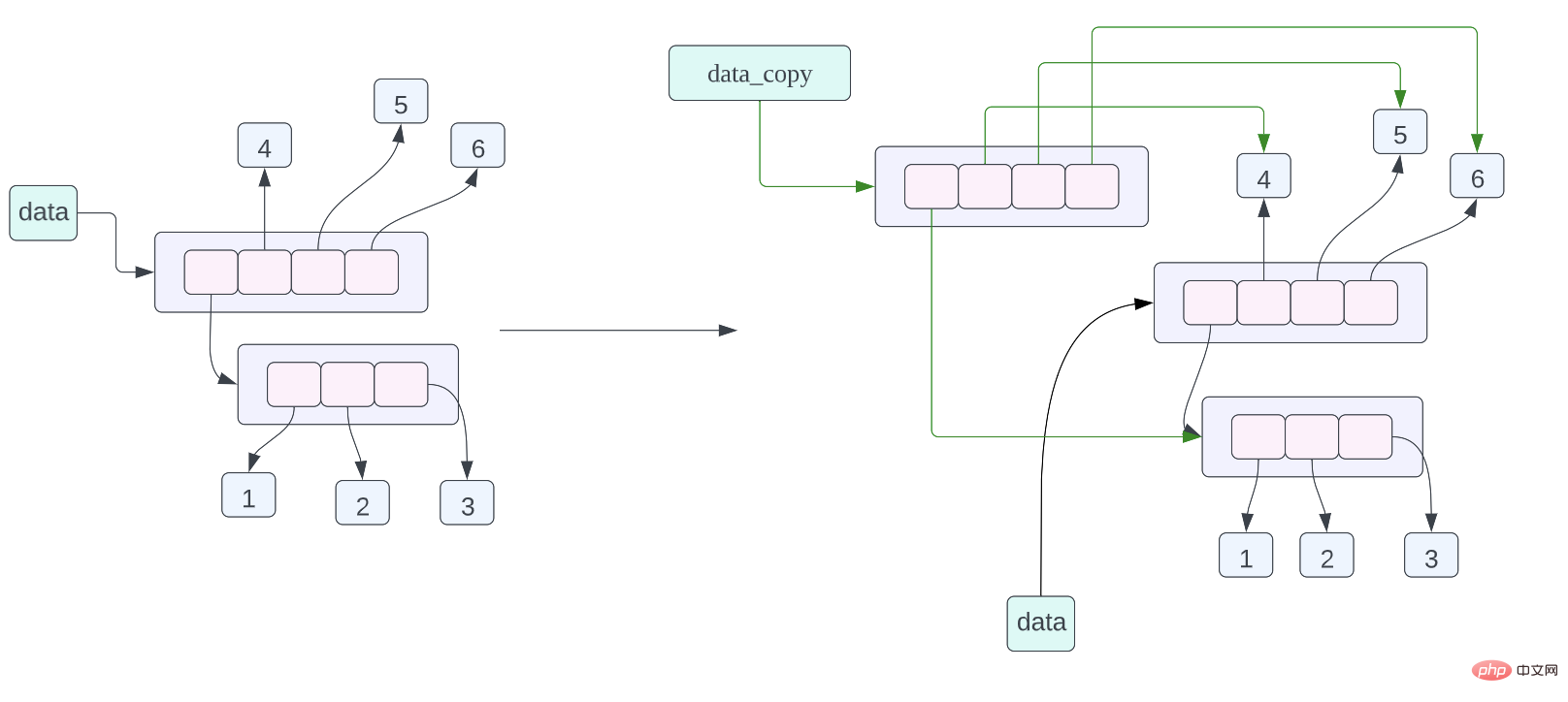
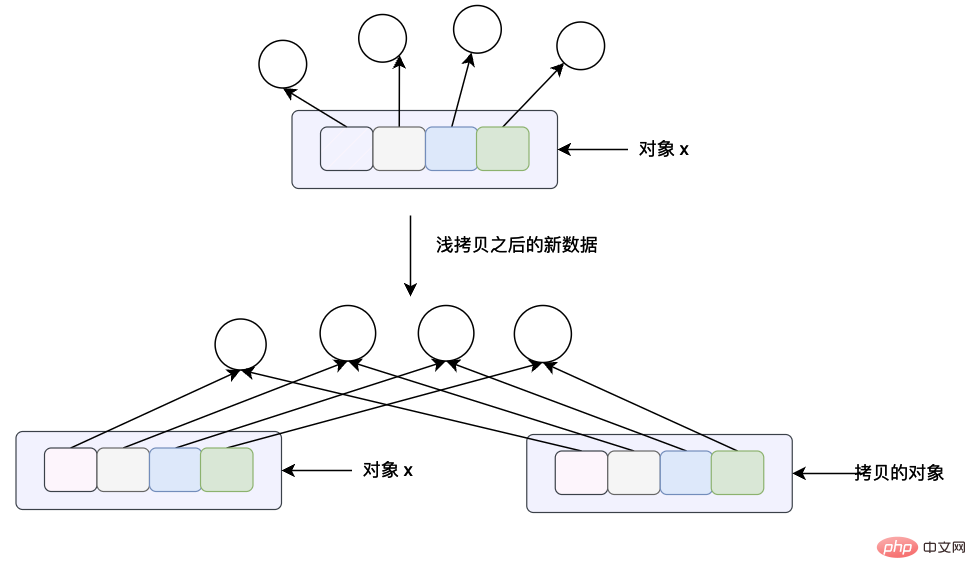
data_assign = data< /code >, wir haben bereits über das Speicherlayout dieser Zuweisungsanweisung gesprochen, aber schauen wir uns das noch einmal an. Die Bedeutung dieser Zuweisungsanweisung besteht darin, dass die Daten, auf die data_assign und data zeigen, dieselben Daten sind, also dieselbe Liste. <blockquote><p><li><br/><code>data_copy = data.copy(), die Bedeutung dieser Zuweisungsanweisung besteht darin, eine flache Kopie der Daten zu erstellen, auf die data zeigt, und dann data_copy auf die kopierten Daten zeigen zu lassen , die flache Kopie hier Was bedeutet, dass jeder Zeiger in der Liste kopiert wird, aber die Daten, auf die der Zeiger in der Liste zeigt, werden kopiert. Aus dem Speicherlayoutdiagramm des obigen Objekts können wir erkennen, dass data_copy auf eine neue Liste zeigt, die Daten, auf die der Zeiger in der Liste zeigt, jedoch dieselben sind wie die Daten, auf die der Zeiger in der Datenliste zeigt dargestellt durch einen grünen Pfeil, Daten. Verwenden Sie schwarze Pfeile, um dies anzuzeigen.
Sehen Sie sich die Speicheradresse des Objekts anIm vorherigen Artikel haben wir hauptsächlich das Speicherlayout des Objekts analysiert. In diesem Abschnitt verwenden wir Python, um uns ein sehr effektives Tool zur Verfügung zu stellen, um dies zu überprüfen. In Python können wir id() verwenden, um die Speicheradresse eines Objekts anzuzeigen. id(a) dient dazu, die Speicheradresse des Objekts anzuzeigen, auf das Objekt a zeigt. Sehen Sie sich die Ausgabe des Programms unten an: 🎜🎜Nach unserer vorherigen Analyse zeigen a und b auf denselben Speicher, was bedeutet, dass die beiden Variablen auf dasselbe Python-Objekt zeigen, sodass das Obige die Ausgabe-ID The hat Ergebnisse a und b sind gleich. Das obige Ausgabeergebnis ist wie folgt: 🎜🎜🎜id(a) = 4392953984 id(b) = 4392953984🎜i = 0 id(a[i]) = 4312613104 id(b[i] ) = 4312613104🎜i = 1 id(a[i]) = 4312613136 id(b[i]) = 4312613136🎜i = 2 id(a[i]) = 4312613168 id(b[i]) = 4312613168🎜🎜 🎜 Schauen Sie hier die Speicheradresse der flachen Kopie: 🎜id(a) = 4392953984 id(b) = 4393050112 # 两个对象的输出结果不相等 i = 0 id(a[i]) = 4393045632 id(b[i]) = 4393045632 # 指向的是同一个内存对象因此内存地址相等 下同 i = 1 id(a[i]) = 4312613200 id(b[i]) = 4312613200 i = 2 id(a[i]) = 4312613232 id(b[i]) = 4312613232
Nach dem Login kopierenNach dem Login kopieren🎜Nach unserer vorherigen Analyse besteht die Kopiermethode zum Aufrufen der Liste selbst darin, eine flache Kopie der Liste durchzuführen. Sie kopiert nur die Zeigerdaten der Liste und kopiert sie nicht Kopieren Sie die realen Daten, auf die der Zeiger zeigt, in der Liste. Wenn wir also die Daten in der Liste durchlaufen, um die Adresse des angezeigten Objekts zu erhalten, sind die von Liste a und Liste b zurückgegebenen Ergebnisse dieselben, unterscheiden sich jedoch Das vorherige Beispiel zeigt, dass die Adressen der Listen, auf die a und b verweisen, unterschiedlich sind (Da Daten kopiert werden, können Sie sich zum Verständnis auf die Ergebnisse des flachen Kopierens unten beziehen). 🎜a = 10 a = 100 a = "hello" a = "world"
Nach dem Login kopierenNach dem Login kopieren
可以结合下面的输出结果和上面的文字进行理解:
id(a) = 4392953984 id(b) = 4393050112 # 两个对象的输出结果不相等 i = 0 id(a[i]) = 4393045632 id(b[i]) = 4393045632 # 指向的是同一个内存对象因此内存地址相等 下同 i = 1 id(a[i]) = 4312613200 id(b[i]) = 4312613200 i = 2 id(a[i]) = 4312613232 id(b[i]) = 4312613232
Nach dem Login kopierenNach dem Login kopierencopy模块
在 python 里面有一个自带的包 copy ,主要是用于对象的拷贝,在这个模块当中主要有两个方法 copy.copy(x) 和 copy.deepcopy()。
copy.copy(x) 方法主要是用于浅拷贝,这个方法的含义对于列表来说和列表本身的 x.copy() 方法的意义是一样的,都是进行浅拷贝。这个方法会构造一个新的 python 对象并且会将对象 x 当中所有的数据引用(指针)拷贝一份。
copy.deepcopy(x) 这个方法主要是对对象 x 进行深拷贝,这里的深拷贝的含义是会构造一个新的对象,会递归的查看对象 x 当中的每一个对象,如果递归查看的对象是一个不可变对象将不会进行拷贝,如果查看到的对象是可变对象的话,将重新开辟一块内存空间,将原来的在对象 x 当中的数据拷贝的新的内存当中。(关于可变和不可变对象我们将在下一个小节仔细分析)
根据上面的分析我们可以知道深拷贝的花费是比浅拷贝多的,尤其是当一个对象当中有很多子对象的时候,会花费很多时间和内存空间。
对于 python 对象来说进行深拷贝和浅拷贝的区别主要在于复合对象(对象当中有子对象,比如说列表,元祖、类的实例等等)。这一点主要是和下一小节的可变和不可变对象有关系。
可变和不可变对象与对象拷贝
在 python 当中主要有两大类对象,可变对象和不可变对象,所谓可变对象就是对象的内容可以发生改变,不可变对象就是对象的内容不能够发生改变。
可变对象:比如说列表(list),字典(dict),集合(set),字节数组(bytearray),类的实例对象。
不可变对象:整型(int),浮点型(float),复数(complex),字符串,元祖(tuple),不可变集合(frozenset),字节(bytes)。
看到这里你可能会有疑问了,整数和字符串不是可以修改吗?
a = 10 a = 100 a = "hello" a = "world"
Nach dem Login kopierenNach dem Login kopieren比如下面的代码是正确的,并不会发生错误,但是事实上其实 a 指向的对象是发生了变化的,第一个对象指向整型或者字符串的时候,如果重新赋一个新的不同的整数或者字符串对象的话,python 会创建一个新的对象,我们可以使用下面的代码进行验证:
a = 10 print(f"{id(a) = }") a = 100 print(f"{id(a) = }") a = "hello" print(f"{id(a) = }") a = "world" print(f"{id(a) = }")Nach dem Login kopieren上面的程序的输出结果如下所示:
id(a) = 4365566480
id(a) = 4365569360
id(a) = 4424109232
id(a) = 4616350128可以看到的是当重新赋值之后变量指向的内存对象是发生了变化的(因为内存地址发生了变化),这就是不可变对象,虽然可以对变量重新赋值,但是得到的是一个新对象并不是在原来的对象上进行修改的!
我们现在来看一下可变对象列表发生修改之后内存地址是怎么发生变化的:
data = [] print(f"{id(data) = }") data.append(1) print(f"{id(data) = }") data.append(1) print(f"{id(data) = }") data.append(1) print(f"{id(data) = }") data.append(1) print(f"{id(data) = }")Nach dem Login kopieren上面的代码输出结果如下所示:
id(data) = 4614905664
id(data) = 4614905664
id(data) = 4614905664
id(data) = 4614905664
id(data) = 4614905664从上面的输出结果来看可以知道,当我们往列表当中加入新的数据之后(修改了列表),列表本身的地址并没有发生变化,这就是可变对象。
我们在前面谈到了深拷贝和浅拷贝,我们现在来分析一下下面的代码:
data = [1, 2, 3] data_copy = copy.copy(data) data_deep = copy.deepcopy(data) print(f"{id(data ) = } | {id(data_copy) = } | {id(data_deep) = }") print(f"{id(data[0]) = } | {id(data_copy[0]) = } | {id(data_deep[0]) = }") print(f"{id(data[1]) = } | {id(data_copy[1]) = } | {id(data_deep[1]) = }") print(f"{id(data[2]) = } | {id(data_copy[2]) = } | {id(data_deep[2]) = }")Nach dem Login kopieren上面的代码输出结果如下所示:
id(data ) = 4620333952 | id(data_copy) = 4619860736 | id(data_deep) = 4621137024
id(data[0]) = 4365566192 | id(data_copy[0]) = 4365566192 | id(data_deep[0]) = 4365566192
id(data[1]) = 4365566224 | id(data_copy[1]) = 4365566224 | id(data_deep[1]) = 4365566224
id(data[2]) = 4365566256 | id(data_copy[2]) = 4365566256 | id(data_deep[2]) = 4365566256看到这里你肯定会非常疑惑,为什么深拷贝和浅拷贝指向的内存对象是一样的呢?前列我们可以理解,因为浅拷贝拷贝的是引用,因此他们指向的对象是同一个,但是为什么深拷贝之后指向的内存对象和浅拷贝也是一样的呢?这正是因为列表当中的数据是整型数据,他是一个不可变对象,如果对 data 或者 data_copy 指向的对象进行修改,那么将会指向一个新的对象并不会直接修改原来的对象,因此对于不可变对象其实是不用开辟一块新的内存空间在重新赋值的,因为这块内存中的对象是不会发生改变的。
我们再来看一个可拷贝的对象:
data = [[1], [2], [3]] data_copy = copy.copy(data) data_deep = copy.deepcopy(data) print(f"{id(data ) = } | {id(data_copy) = } | {id(data_deep) = }") print(f"{id(data[0]) = } | {id(data_copy[0]) = } | {id(data_deep[0]) = }") print(f"{id(data[1]) = } | {id(data_copy[1]) = } | {id(data_deep[1]) = }") print(f"{id(data[2]) = } | {id(data_copy[2]) = } | {id(data_deep[2]) = }")Nach dem Login kopieren上面的代码输出结果如下所示:
id(data ) = 4619403712 | id(data_copy) = 4617239424 | id(data_deep) = 4620032640
id(data[0]) = 4620112640 | id(data_copy[0]) = 4620112640 | id(data_deep[0]) = 4620333952
id(data[1]) = 4619848128 | id(data_copy[1]) = 4619848128 | id(data_deep[1]) = 4621272448
id(data[2]) = 4620473280 | id(data_copy[2]) = 4620473280 | id(data_deep[2]) = 4621275840从上面程序的输出结果我们可以看到,当列表当中保存的是一个可变对象的时候,如果我们进行深拷贝将创建一个全新的对象(深拷贝的对象内存地址和浅拷贝的不一样)。
代码片段分析
经过上面的学习对于在本篇文章开头提出的问题对于你来说应该是很简单的,我们现在来分析一下这几个代码片段:
a = [1, 2, 3, 4] b = a print(f"{a = } \t|\t {b = }") a[0] = 100 print(f"{a = } \t|\t {b = }")Nach dem Login kopierenNach dem Login kopieren这个很简单啦,a 和 b 不同的变量指向同一个列表,a 中间的数据发生变化,那么 b 的数据也会发生变化,输出结果如下所示:
a = [1, 2, 3, 4] | b = [1, 2, 3, 4]
a = [100, 2, 3, 4] | b = [100, 2, 3, 4]
id(a) = 4614458816 | id(b) = 4614458816我们再来看一下第二个代码片段
a = [1, 2, 3, 4] b = a.copy() print(f"{a = } \t|\t {b = }") a[0] = 100 print(f"{a = } \t|\t {b = }")Nach dem Login kopierenNach dem Login kopieren因为 b 是 a 的一个浅拷贝,所以 a 和 b 指向的是不同的列表,但是列表当中数据的指向是相同的,但是由于整型数据是不可变数据,当a[0] 发生变化的时候,并不会修改原来的数据,而是会在内存当中创建一个新的整型数据,因此列表 b 的内容并不会发生变化。因此上面的代码输出结果如下所示:
a = [1, 2, 3, 4] | b = [1, 2, 3, 4] a = [100, 2, 3, 4] | b = [1, 2, 3, 4]
Nach dem Login kopieren再来看一下第三个片段:
a = [[1, 2, 3], 2, 3, 4] b = a.copy() print(f"{a = } \t|\t {b = }") a[0][0] = 100 print(f"{a = } \t|\t {b = }")Nach dem Login kopierenNach dem Login kopieren这个和第二个片段的分析是相似的,但是 a[0] 是一个可变对象,因此进行数据修改的时候,a[0] 的指向没有发生变化,因此 a 修改的内容会影响 b。
a = [[1, 2, 3], 2, 3, 4] | b = [[1, 2, 3], 2, 3, 4] a = [[100, 2, 3], 2, 3, 4] | b = [[100, 2, 3], 2, 3, 4]
Nach dem Login kopieren最后一个片段:
a = [[1, 2, 3], 2, 3, 4] b = copy.deepcopy(a) print(f"{a = } \t|\t {b = }") a[0][0] = 100 print(f"{a = } \t|\t {b = }")Nach dem Login kopierenNach dem Login kopieren深拷贝会在内存当中重新创建一个和a[0]相同的对象,并且让 b[0] 指向这个对象,因此修改 a[0],并不会影响 b[0],因此输出结果如下所示:
a = [[1, 2, 3], 2, 3, 4] | b = [[1, 2, 3], 2, 3, 4] a = [[100, 2, 3], 2, 3, 4] | b = [[1, 2, 3], 2, 3, 4]
Nach dem Login kopieren撕开 Python 对象的神秘面纱
我们现在简要看一下 Cpython 是如何实现 list 数据结构的,在 list 当中到底定义了一些什么东西:
typedef struct { PyObject_VAR_HEAD /* Vector of pointers to list elements. list[0] is ob_item[0], etc. */ PyObject **ob_item; /* ob_item contains space for 'allocated' elements. The number * currently in use is ob_size. * Invariants: * 0 <= ob_size <= allocated * len(list) == ob_size * ob_item == NULL implies ob_size == allocated == 0 * list.sort() temporarily sets allocated to -1 to detect mutations. * * Items must normally not be NULL, except during construction when * the list is not yet visible outside the function that builds it. */ Py_ssize_t allocated; } PyListObject;Nach dem Login kopieren在上面定义的结构体当中 :
allocated 表示分配的内存空间的数量,也就是能够存储指针的数量,当所有的空间用完之后需要再次申请内存空间。
ob_item 指向内存当中真正存储指向 python 对象指针的数组,比如说我们想得到列表当中第一个对象的指针的话就是 list->ob_item[0],如果要得到真正的数据的话就是 *(list->ob_item[0])。
PyObject_VAR_HEAD 是一个宏,会在结构体当中定一个子结构体,这个子结构体的定义如下:
typedef struct { PyObject ob_base; Py_ssize_t ob_size; /* Number of items in variable part */ } PyVarObject;Nach dem Login kopieren这里我们不去谈对象 PyObject 了,主要说一下 ob_size,他表示列表当中存储了多少个数据,这个和 allocated 不一样,allocated 表示 ob_item 指向的数组一共有多少个空间,ob_size 表示这个数组存储了多少个数据 ob_size
在了解列表的结构体之后我们现在应该能够理解之前的内存布局了,所有的列表并不存储真正的数据而是存储指向这些数据的指针。
Das obige ist der detaillierte Inhalt vonSo implementieren Sie das Kopieren von Objekten und das Speicherlayout in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Effizientes Training von Pytorch -Modellen auf CentOS -Systemen erfordert Schritte, und dieser Artikel bietet detaillierte Anleitungen. 1.. Es wird empfohlen, YUM oder DNF zu verwenden, um Python 3 und Upgrade PIP zu installieren: Sudoyumupdatepython3 (oder sudodnfupdatepython3), PIP3Install-upgradepip. CUDA und CUDNN (GPU -Beschleunigung): Wenn Sie Nvidiagpu verwenden, müssen Sie Cudatool installieren
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
Bei der Auswahl einer Pytorch -Version unter CentOS müssen die folgenden Schlüsselfaktoren berücksichtigt werden: 1. Cuda -Version Kompatibilität GPU -Unterstützung: Wenn Sie NVIDIA -GPU haben und die GPU -Beschleunigung verwenden möchten, müssen Sie Pytorch auswählen, der die entsprechende CUDA -Version unterstützt. Sie können die CUDA-Version anzeigen, die unterstützt wird, indem Sie den Befehl nvidia-smi ausführen. CPU -Version: Wenn Sie keine GPU haben oder keine GPU verwenden möchten, können Sie eine CPU -Version von Pytorch auswählen. 2. Python Version Pytorch
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
 So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
Die Installation von CentOS-Installationen erfordert die folgenden Schritte: Installieren von Abhängigkeiten wie Entwicklungstools, PCRE-Devel und OpenSSL-Devel. Laden Sie das Nginx -Quellcode -Paket herunter, entpacken Sie es, kompilieren Sie es und installieren Sie es und geben Sie den Installationspfad als/usr/local/nginx an. Erstellen Sie NGINX -Benutzer und Benutzergruppen und setzen Sie Berechtigungen. Ändern Sie die Konfigurationsdatei nginx.conf und konfigurieren Sie den Hörport und den Domänennamen/die IP -Adresse. Starten Sie den Nginx -Dienst. Häufige Fehler müssen beachtet werden, z. B. Abhängigkeitsprobleme, Portkonflikte und Konfigurationsdateifehler. Die Leistungsoptimierung muss entsprechend der spezifischen Situation angepasst werden, z. B. das Einschalten des Cache und die Anpassung der Anzahl der Arbeitsprozesse.
