

So implementieren Sie Kettenaufrufe in Python

Warum Kettenanrufe?
Verkettete Aufrufe, oder auch Methodenverkettung genannt, bedeuten wörtlich eine Codemethode, die eine Reihe von Operationen oder Funktionsmethoden wie eine Kette aneinanderreiht.
Ich habe die „Schönheit“ von Kettenaufrufen zum ersten Mal erkannt, indem ich den Pipeline-Operator der R-Sprache verwendet habe.
library(tidyverse) mtcars %>% group_by(cyl) %>% summarise(meanmeanOfdisp = mean(disp)) %>% ggplot(aes(x=as.factor(cyl), y=meanOfdisp, fill=as.factor(seq(1,3))))+ geom_bar(stat = 'identity') + guides(fill=F)
Für R-Benutzer kann dieser Codeabschnitt schnell verstehen, was die gesamten Prozessschritte sind. Alles beginnt mit dem Symbol %>% (dem Pipe-Operator).
Durch den Pipe-Operator können wir das Ding auf der linken Seite an das nächste Ding weitergeben. Hier übergebe ich den mtcars-Datensatz an die Funktion group_by, dann übergebe ich das Ergebnis an die Funktion summary und schließlich übergebe ich es zur visuellen Zeichnung an die Funktion ggplot.
Wenn ich Chain Calling nicht gelernt hätte, hätte ich beim ersten Erlernen der R-Sprache so geschrieben:
library(tidyverse) cyl4 <p>Wenn ich den Pipe-Operator nicht verwendet hätte, hätte ich unnötige Zuweisungen vorgenommen und das Original überschrieben Datenobjekte, aber tatsächlich dienen die Zylindernummer und die darin generierten Daten nur dem Diagrammbild, sodass das Problem darin besteht, dass der Code überflüssig wird. </p><p>Verkettete Aufrufe vereinfachen nicht nur den Code erheblich, sondern verbessern auch die Lesbarkeit des Codes. Sie können schnell verstehen, was jeder Schritt bewirkt. Diese Methode ist sehr nützlich für die Datenanalyse oder Datenverarbeitung. Sie kann die Erstellung unnötiger Variablen reduzieren und eine schnelle und einfache Erkundung ermöglichen. </p><p>Sie können an vielen Stellen Kettenaufrufe oder Pipeline-Operationen sehen. Hier werde ich neben der R-Sprache zwei typische Beispiele nennen. </p><p>Eine davon ist die Shell-Anweisung: </p><pre class="brush:php;toolbar:false">echo "`seq 1 100`" | grep -e "^[3-4].*" | tr "3" "*"
Mit dem Pipe-Operator „|“ in der Shell-Anweisung kann ich schnell alle Ganzzahlen von 1 bis 100 drucken und sie dann an die grep-Methode übergeben Alle Teile, die mit 3 oder 4 beginnen, übergeben Sie diesen Teil an die tr-Methode und ersetzen Sie den Teil der Zahl, der 3 enthält, durch ein Sternchen. Die Ergebnisse sind wie folgt:
Das andere ist die Scala-Sprache:
object Test { def main(args: Array[String]): Unit = { val numOfseq = (1 to 100).toList val chain = numOfseq.filter(_%2==0) .map(_*2) .take(10) } }In diesem Beispiel enthält die Variable numOfseq zunächst alle Ganzzahlen von 1 bis 100, und dann habe ich ausgehend vom Kettenteil zunächst die Methode „Filter basierend auf der Methode numOfseq“ aufgerufen Filtern Sie die geraden Teile dieser Zahlen, rufen Sie dann die Map-Methode auf, um die gefilterten Zahlen mit 2 zu multiplizieren, und verwenden Sie schließlich die Take-Methode, um die ersten 10 Zahlen aus den neu gebildeten Zahlen herauszunehmen, und diese Zahlen werden gemeinsam der Kettenvariablen zugewiesen.
Durch die obige Beschreibung können Sie meiner Meinung nach einen ersten Eindruck von Kettenaufrufen gewinnen, aber sobald Sie Kettenaufrufe beherrschen, wird sich nicht nur Ihr Programmierstil ändern, sondern auch Ihr Programmierdenken.
Verkettete Aufrufe in Python
Um einen einfachen verketteten Aufruf in Python zu implementieren, müssen Sie eine Klassenmethode erstellen und das Objekt selbst oder die attributierte Klasse (@classmethod) zurückgeben.
class Chain: def __init__(self, name): self.name = name def introduce(self): print("hello, my name is %s" % self.name) return self def talk(self): print("Can we make a friend?") return self def greet(self): print("Hey! How are you?") return self if __name__ == '__main__': chain = Chain(name = "jobs") chain.introduce() print("-"*20) chain.introduce().talk() print("-"*20) chain.introduce().talk().greet()Hier erstellen wir eine Chain-Klasse, die Sie benötigen Um einen Namenszeichenfolgenparameter zu übergeben, um ein Instanzobjekt zu erstellen, gibt es in dieser Klasse drei Methoden: „Introducing“, „Talk“ und „Greet“.
Da self jedes Mal zurückgegeben wird, können wir die Methoden in der zugehörigen Klasse des Objekts kontinuierlich aufrufen. Die Ergebnisse sind wie folgt:
hello, my name is jobs -------------------- hello, my name is jobs Can we make a friend? -------------------- hello, my name is jobs Can we make a friend? Hey! How are you?
Verwendung von Kettenaufrufen in Pandas
Nachdem wir so viel den Weg geebnet haben, haben wir endlich darüber gesprochen it Gehen Sie zum Teil über Pandas-Kettenaufrufe
Die meisten Methoden in Pandas eignen sich für den Betrieb mit Kettenmethoden, da nach der API-Verarbeitung oft ein Serientyp oder ein DataFrame-Typ zurückgegeben wird, sodass wir die entsprechende Methode direkt aufrufen können. Hier nehme ich als Beispiel die Videodaten der Station Huanong Brothers B, die ich gecrawlt habe, als ich anderen im Februar dieses Jahres eine Falldemonstration gab. Es kann über den Link bezogen werden.
Die Datenfeldinformationen lauten wie folgt, es gibt 300 Daten und 20 Felder:
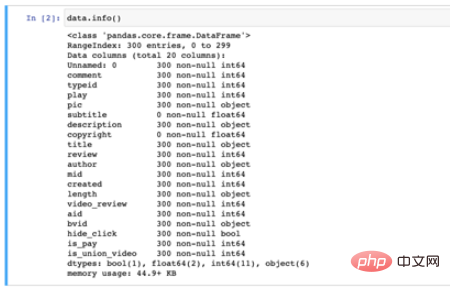
Feldinformationen
Aber bevor wir diesen Teil der Daten verwenden, müssen wir diesen Teil noch vorläufig bereinigen Die Daten, hier habe ich hauptsächlich die folgenden Felder ausgewählt:
Hilfe: die dem Video entsprechende AV-Nummer
Kommentar: Anzahl der Kommentare
Wiedergabe: Wiedergabelautstärke
Titel: Titel
video_review: Anzahl der Sperren
erstellt: Upload-Datum
Länge: Videodauer
1. Datenbereinigung
Die entsprechenden Werte jedes Felds sind wie folgt:
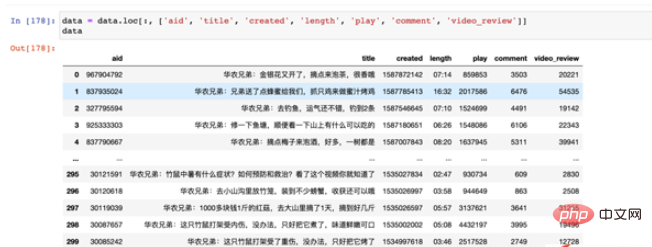
Feldwerte
Aus den Daten, die wir sehen können:
Vor dem Titelfeld stehen vier Wörter „Huanong Brothers“, wenn die Anzahl der Wörter gezählt wird im Voraus entfernt werden;
erstellt Das Upload-Datum scheint als lange Reihe von Werten angezeigt zu werden. Tatsächlich handelt es sich jedoch um einen Zeitstempel von 1970 bis heute, und wir müssen ihn in ein lesbares Jahr, einen Monat und einen Tag umwandeln formatieren;
length 播放量长度只显示了分秒,但是小时并未用「00」来进行补全,因此这里我们一方面需要将其补全,另一方面要将其转换成对应的时间格式
链式调用操作如下:
import re import pandas as pd # 定义字数统计函数 def word_count(text): return len(re.findall(r"[\u4e00-\u9fa5]", text)) tidy_data = ( pd.read_csv('~/Desktop/huanong.csv') .loc[:, ['aid', 'title', 'created', 'length', 'play', 'comment', 'video_review']] .assign(title = lambda df: df['title'].str.replace("华农兄弟:", ""), title_count = lambda df: df['title'].apply(word_count), created = lambda df: df['created'].pipe(pd.to_datetime, unit='s'), created_date = lambda df: df['created'].dt.date, length = lambda df: "00:" + df['length'], video_length = lambda df: df['length'].pipe(pd.to_timedelta).dt.seconds ) )这里首先是通过loc方法挑出其中的列,然后调用assign方法来创建新的字段,新的字段其字段名如果和原来的字段相一致,那么就会进行覆盖,从assign中我们可以很清楚地看到当中字段的产生过程,同lambda 表达式进行交互:
1.title 和title_count:
原有的title字段因为属于字符串类型,可以直接很方便的调用str.* 方法来进行处理,这里我就直接调用当中的replace方法将「华农兄弟:」字符进行清洗
基于清洗好的title 字段,再对该字段使用apply方法,该方法传递我们前面实现定义好的字数统计的函数,对每一条记录的标题中,对属于\u4e00到\u9fa5这一区间内的所有 Unicode 中文字符进行提取,并进行长度计算
2.created和created_date:
对原有的created 字段调用一个pipe方法,该方法会将created 字段传递进pd.to_datetime 参数中,这里需要将unit时间单位设置成s秒才能显示出正确的时间,否则仍以 Unix 时间错的样式显示
基于处理好的created 字段,我们可以通过其属于datetime64 的性质来获取其对应的时间,这里 Pandas 给我们提供了一个很方便的 API 方法,通过dt.*来拿到当中的属性值
3.length 和video_length:
原有的length 字段我们直接让字符串00:和该字段进行直接拼接,用以做下一步转换
基于完整的length时间字符串,我们再次调用pipe方法将该字段作为参数隐式传递到pd.to_timedelta方法中转化,然后同理和create_date字段一样获取到相应的属性值,这里我取的是秒数。
2、播放量趋势图
基于前面稍作清洗后得到的tidy_data数据,我们可以快速地做一个播放量走势的探索。这里我们需要用到created这个属于datetime64的字段为 X 轴,播放量play 字段为 Y 轴做可视化展示。
# 播放量走势 %matplotlib inline %config InlineBackend.figure_format = 'retina' import matplotlib.pyplot as plt (tidy_data[['created', 'play']] .set_index('created') .resample('1M') .sum() .plot( kind='line', figsize=(16, 8), title='Video Play Prend(2018-2020)', grid=True, legend=False ) ) plt.xlabel("") plt.ylabel('The Number Of Playing')这里我们将上传日期和播放量两个选出来后,需要先将created设定为索引,才能接着使用resample重采样的方法进行聚合操作,这里我们以月为统计颗粒度,对每个月播放量进行加总,之后再调用plot 接口实现可视化。
链式调用的一个小技巧就是,可以利用括号作用域连续的特性使整个链式调用的操作不会报错,当然如果不喜欢这种方式也可以手动在每条操作后面追加一个\符号,所以上面的整个操作就会变成这样:
tidy_data[['created', 'play']] \ .set_index('created') \ .resample('1M') .sum() .plot( \ kind='line', \ figsize=(16, 8), \ title='Video Play Prend(2018-2020)', \ grid=True, \ legend=False \ )但是相比于追加一对括号来说,这种尾部追加\符号的方式并不推荐,也不优雅。
但是如果既没有在括号作用域或未追加\ 符号,那么在运行时 Python 解释器就会报错。
3、链式调用性能
通过前两个案例我们可以看出链式调用可以说是比较优雅且快速地能实现一套数据操作的流程,但是链式调用也会因为不同的写法而存在性能上的差异。
这里我们继续基于前面的tidy_data操作,这里我们基于created_date 来对play、comment和video_review进行求和后的数值进一步以 10 为底作对数化。最后需要得到以下结果:
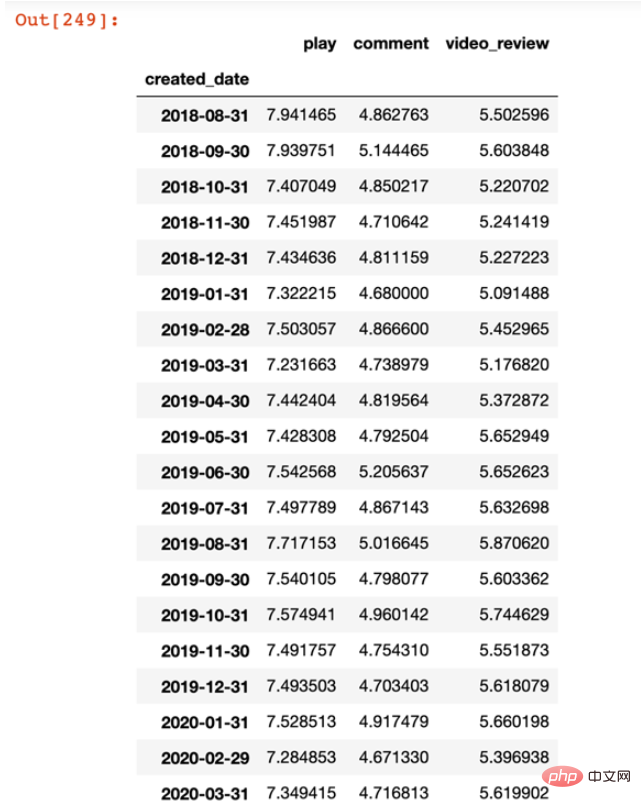
统计表格
写法一:一般写法
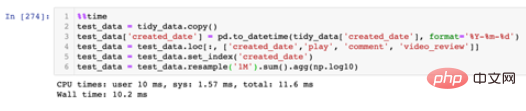
一般写法
这种写法就是基于tidy_data拷贝后进行操作,操作得到的结果会不断地覆盖原有的数据对象
写法二:链式调用写法
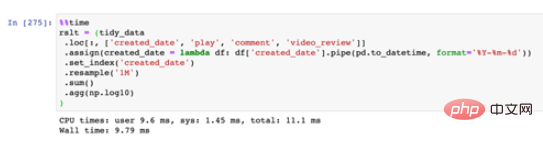
链式调用写法
可以看到,链式调用的写法相比于一般写法而言会快上一点,不过由于数据量比较小,因此二者时间的差异并不大;但链式调用由于不需要额外的中间变量已经覆盖写入步骤,在内存开销上会少一些。
结尾:链式调用的优劣
从本文的只言片语中,你能领略到链式调用使得代码在可读性上大大的增强,同时以尽肯能少的代码量去实现更多操作。
当然,链式调用并不算是完美的,它也存在着一定缺陷。比如说当链式调用的方法超过 10 步以上时,那么出错的几率就会大幅度提高,从而造成调试或 Debug 的困难。比如这样:
(data .method1(...) .method2(...) .method3(...) .method4(...) .method5(...) .method6(...) .method7(...) # Something Error .method8(...) .method9(...) .method10(...) .method11(...) )
Das obige ist der detaillierte Inhalt vonSo implementieren Sie Kettenaufrufe in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, hochrangige skalierbare Python-Datenbank Hadidb (HadIDB) ist eine leichte Datenbank in Python mit einem hohen Maß an Skalierbarkeit. Installieren Sie HadIDB mithilfe der PIP -Installation: PipinstallHadIDB -Benutzerverwaltung erstellen Benutzer: createUser (), um einen neuen Benutzer zu erstellen. Die Authentication () -Methode authentifiziert die Identität des Benutzers. fromHadidb.operationImportUseruser_obj = user ("admin", "admin") user_obj.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
MySQL kann ohne Netzwerkverbindungen für die grundlegende Datenspeicherung und -verwaltung ausgeführt werden. Für die Interaktion mit anderen Systemen, Remotezugriff oder Verwendung erweiterte Funktionen wie Replikation und Clustering ist jedoch eine Netzwerkverbindung erforderlich. Darüber hinaus sind Sicherheitsmaßnahmen (wie Firewalls), Leistungsoptimierung (Wählen Sie die richtige Netzwerkverbindung) und die Datensicherung für die Verbindung zum Internet von entscheidender Bedeutung.
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 Kann sich MySQL Workbench mit Mariadb verbinden?
Apr 08, 2025 pm 02:33 PM
Kann sich MySQL Workbench mit Mariadb verbinden?
Apr 08, 2025 pm 02:33 PM
MySQL Workbench kann eine Verbindung zu MariADB herstellen, vorausgesetzt, die Konfiguration ist korrekt. Wählen Sie zuerst "Mariadb" als Anschlusstyp. Stellen Sie in der Verbindungskonfiguration Host, Port, Benutzer, Kennwort und Datenbank korrekt ein. Überprüfen Sie beim Testen der Verbindung, ob der Mariadb -Dienst gestartet wird, ob der Benutzername und das Passwort korrekt sind, ob die Portnummer korrekt ist, ob die Firewall Verbindungen zulässt und ob die Datenbank vorhanden ist. Verwenden Sie in fortschrittlicher Verwendung die Verbindungspooling -Technologie, um die Leistung zu optimieren. Zu den häufigen Fehlern gehören unzureichende Berechtigungen, Probleme mit Netzwerkverbindung usw. Bei Debugging -Fehlern, sorgfältige Analyse von Fehlerinformationen und verwenden Sie Debugging -Tools. Optimierung der Netzwerkkonfiguration kann die Leistung verbessern
 So lösen Sie MySQL können keine Verbindung zum lokalen Host herstellen
Apr 08, 2025 pm 02:24 PM
So lösen Sie MySQL können keine Verbindung zum lokalen Host herstellen
Apr 08, 2025 pm 02:24 PM
Die MySQL -Verbindung kann auf die folgenden Gründe liegen: MySQL -Dienst wird nicht gestartet, die Firewall fängt die Verbindung ab, die Portnummer ist falsch, der Benutzername oder das Kennwort ist falsch, die Höradresse in my.cnf ist nicht ordnungsgemäß konfiguriert usw. Die Schritte zur Fehlerbehebung umfassen: 1. Überprüfen Sie, ob der MySQL -Dienst ausgeführt wird. 2. Passen Sie die Firewall -Einstellungen an, damit MySQL Port 3306 anhören kann. 3. Bestätigen Sie, dass die Portnummer mit der tatsächlichen Portnummer übereinstimmt. 4. Überprüfen Sie, ob der Benutzername und das Passwort korrekt sind. 5. Stellen Sie sicher, dass die Einstellungen für die Bindungsadresse in my.cnf korrekt sind.
 Benötigt MySQL einen Server?
Apr 08, 2025 pm 02:12 PM
Benötigt MySQL einen Server?
Apr 08, 2025 pm 02:12 PM
Für Produktionsumgebungen ist in der Regel ein Server erforderlich, um MySQL auszuführen, aus Gründen, einschließlich Leistung, Zuverlässigkeit, Sicherheit und Skalierbarkeit. Server haben normalerweise leistungsstärkere Hardware, redundante Konfigurationen und strengere Sicherheitsmaßnahmen. Bei kleinen Anwendungen mit niedriger Last kann MySQL auf lokalen Maschinen ausgeführt werden, aber Ressourcenverbrauch, Sicherheitsrisiken und Wartungskosten müssen sorgfältig berücksichtigt werden. Für eine größere Zuverlässigkeit und Sicherheit sollte MySQL auf Cloud oder anderen Servern bereitgestellt werden. Die Auswahl der entsprechenden Serverkonfiguration erfordert eine Bewertung basierend auf Anwendungslast und Datenvolumen.
