
 Technologie-Peripheriegeräte
KI
Hinton ist auf der Liste! Eine Bestandsaufnahme der 10-jährigen Geschichte der KI-Bildsynthese, Artikel und Namen, an die man sich erinnern sollte
Technologie-Peripheriegeräte
KI
Hinton ist auf der Liste! Eine Bestandsaufnahme der 10-jährigen Geschichte der KI-Bildsynthese, Artikel und Namen, an die man sich erinnern sollte
Hinton ist auf der Liste! Eine Bestandsaufnahme der 10-jährigen Geschichte der KI-Bildsynthese, Artikel und Namen, an die man sich erinnern sollte

Jetzt ist das Jahr 2022 zu Ende.
Die Leistung von Deep-Learning-Modellen bei der Generierung von Bildern ist bereits so gut. Offensichtlich wird es uns in Zukunft noch mehr Überraschungen bereiten.

Wie sind wir in zehn Jahren dorthin gekommen, wo wir heute sind?
In der Zeitleiste unten werden wir einige Meilensteine nachzeichnen, nämlich die Zeit, in der die Papiere, Architekturen, Modelle, Datensätze und Experimente veröffentlicht wurden, die die KI-Bildsynthese beeinflusst haben.
Alles beginnt mit dem Sommer vor zehn Jahren.
Der Anfang (2012-2015)
Nach dem Aufkommen tiefer neuronaler Netze erkannten die Menschen, dass sie die Bildklassifizierung revolutionieren würden.
Gleichzeitig begannen Forscher, die entgegengesetzte Richtung zu erforschen: Was würde passieren, wenn die Bilder mit einigen Techniken erstellt würden, die für die Klassifizierung sehr effektiv sind, wie zum Beispiel Faltungsschichten?
Dies ist der Beginn des „Sommers der Künstlichen Intelligenz“.
Dezember 2012
Hier begann alles.
In diesem Jahr wurde der Artikel „ImageNet Classification of Deep Convolutional Neural Networks“ veröffentlicht.

Einer der Autoren des Papiers ist Hinton, einer der „Großen Drei“ der KI.
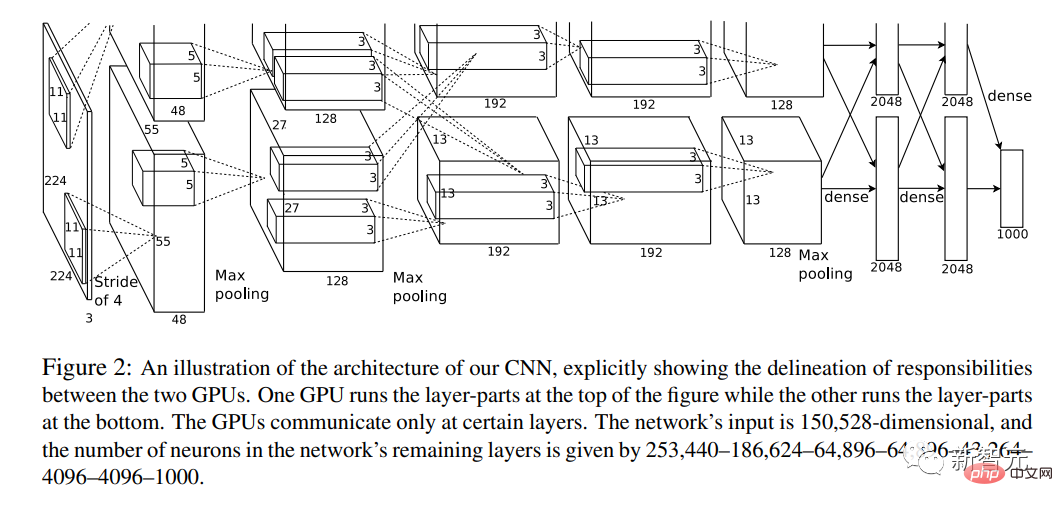
Es kombiniert zum ersten Mal Deep Convolutional Neural Networks (CNN), GPU und einen riesigen Datensatz aus dem Internet (ImageNet).

Im Dezember 2014
Ian Goodfellow und andere KI-Giganten veröffentlichten das epische Papier „Generative Adversarial Networks“.
GAN ist die erste moderne neuronale Netzwerkarchitektur, die sich eher der Bildsynthese als der Analyse widmet (die Definition von „modern“ stammt aus dem Jahr 2012).
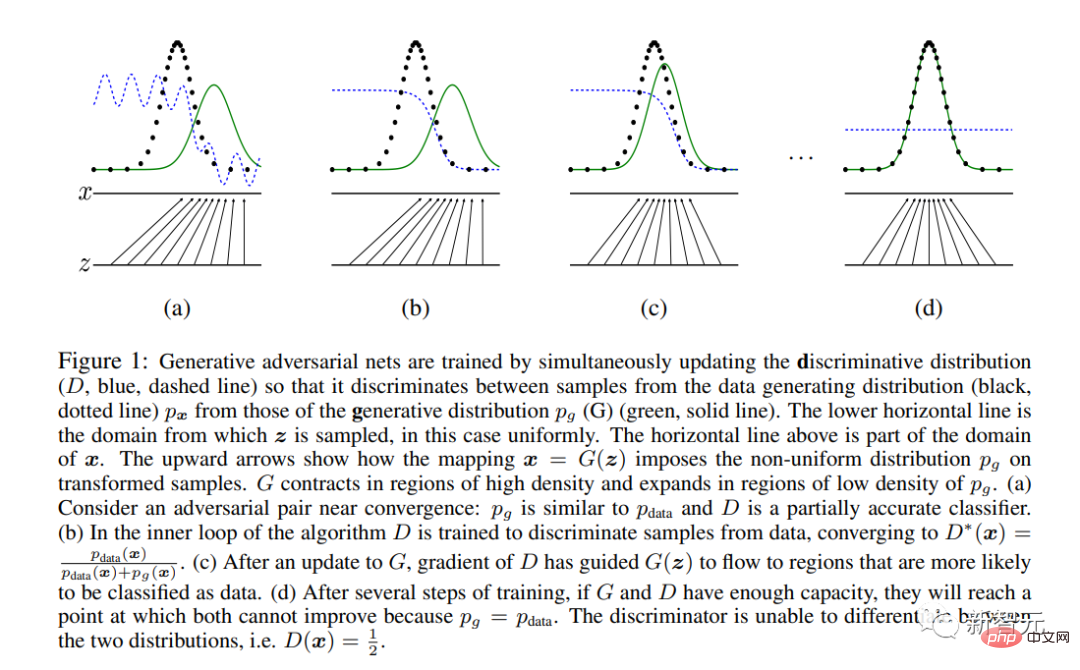
Es stellt eine einzigartige, auf Spieltheorie basierende Lernmethode vor, bei der zwei Subnetzwerke „Generator“ und „Diskriminator“ konkurrieren.
Am Ende bleibt nur der „Generator“ außerhalb des Systems und wird für die Bildsynthese verwendet.
Hallo Welt! GAN generierte Gesichtsproben aus der Arbeit von Goodfellow et al. aus dem Jahr 2014. Das Modell wurde anhand des Toronto Faces-Datensatzes trainiert, der aus dem Internet entfernt wurde
November 2015
Der bahnbrechende Artikel „Using Deep Convolutional Generative Adversarial Networks“ Unsupervised Representative Learning“ wurde veröffentlicht.

In diesem Artikel beschreiben die Autoren die erste praktische GAN-Architektur (DCGAN).
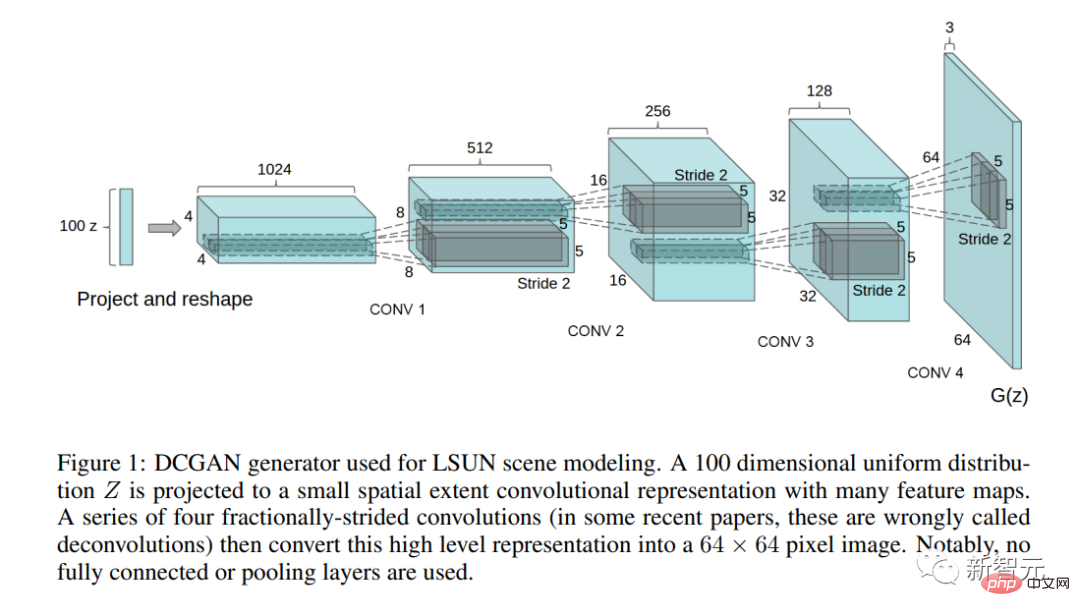
Dieser Artikel wirft auch zum ersten Mal die Frage der Manipulation des latenten Raums auf – lassen sich Konzepte auf Richtungen des latenten Raums abbilden?
Fünf Jahre GAN (2015-2020)
Während dieser fünf Jahre wurde GAN auf verschiedene Bildverarbeitungsaufgaben angewendet, wie z. B. Stilübertragung, Wiederherstellung, Rauschunterdrückung und Superauflösung. Während
begann die Zahl der Veröffentlichungen zur GAN-Architektur zu explodieren.

Projektadresse: https://github.com/nightrome/really-awesome-gan
Zur gleichen Zeit begannen die künstlerischen Experimente von GAN zu steigen, Mike Tyka, Mario Klingenmann, Anna Ridler, Helena Sarin und andere traten auf.
Der erste „KI-Kunst“-Skandal ereignete sich im Jahr 2018. Drei französische Studenten verwendeten „geliehenen“ Code, um ein KI-Porträt zu erstellen, das das erste KI-Porträt war, das bei Christie's versteigert wurde.

Gleichzeitig revolutionierte die Transformer-Architektur das NLP.
Dieses Ding wird in naher Zukunft einen großen Einfluss auf die Bildsynthese haben.
Juni 2017
Papier „Attention Is All You Need“ veröffentlicht.

Eine ausführliche Erklärung finden Sie auch in „Transformers, erklärt: Verstehen Sie das Modell hinter GPT-3, BERT und T5“.
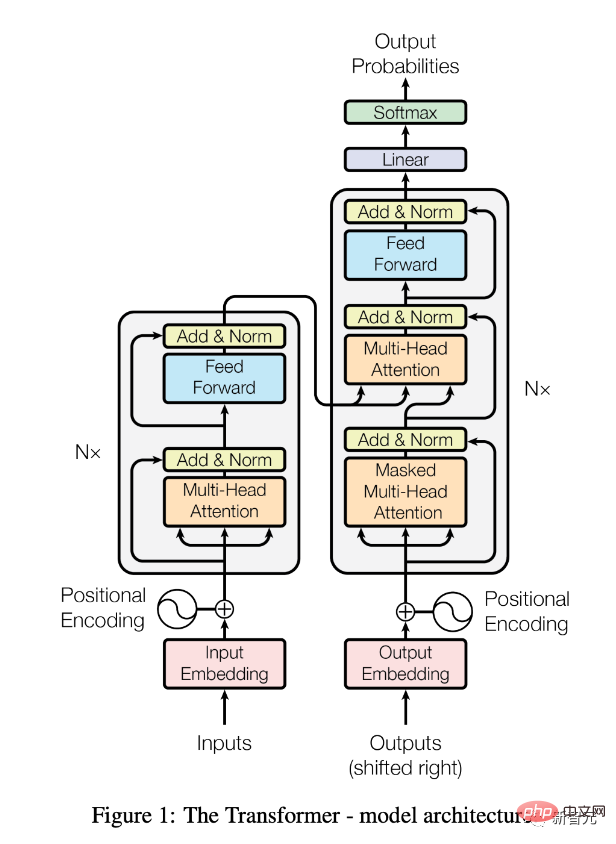
Seitdem hat die Transformer-Architektur (in Form vorab trainierter Modelle wie BERT) den Bereich der Verarbeitung natürlicher Sprache (NLP) revolutioniert.

Juli 2018

Der Artikel „Conceptual Annotation: Cleaning, Superpositioning, and Image Alt Text Dataset for Automatic Image Captioning“ wurde veröffentlicht.
Dieser und andere multimodale Datensätze werden für Modelle wie CLIP und DALL-E äußerst wichtig werden.
In den Jahren 2018-2020
NVIDIA-Forscher haben eine Reihe gründlicher Verbesserungen an der GAN-Architektur vorgenommen.
In dem Artikel „Training Generative Adversarial Networks Using Limited Data“ wird die neueste StyleGAN2-ada vorgestellt.
Zum ersten Mal sind
GAN-generierte Bilder nicht mehr von natürlichen Bildern zu unterscheiden, zumindest für hochoptimierte Datensätze wie Flickr-Faces-HQ (FFHQ).

Mario Klingenmann, Memories of Passerby I, 2018. Die speckigen Gesichter sind typisch für die KI-Kunst in der Region, wo der Nichtrealismus generativer Modelle im Mittelpunkt der künstlerischen Auseinandersetzung steht
2020 5 Monate
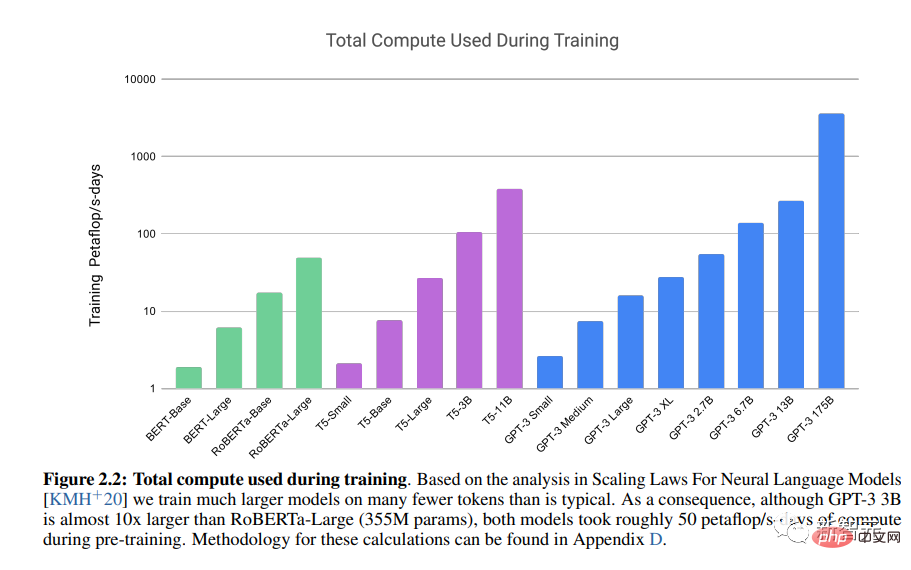
Der Artikel „Language Model is a Small Sample Learner“ wurde veröffentlicht.
OpenAIs LLM Generative Pre-trained Transformer 3 (GPT-3) demonstriert die Leistungsfähigkeit der Transformer-Architektur.
Dezember 2020
Der Artikel „Taming Transformers for High-Resolution Image Synthesis“ wurde veröffentlicht.

ViT zeigt, dass die Transformer-Architektur für Bilder verwendet werden kann.
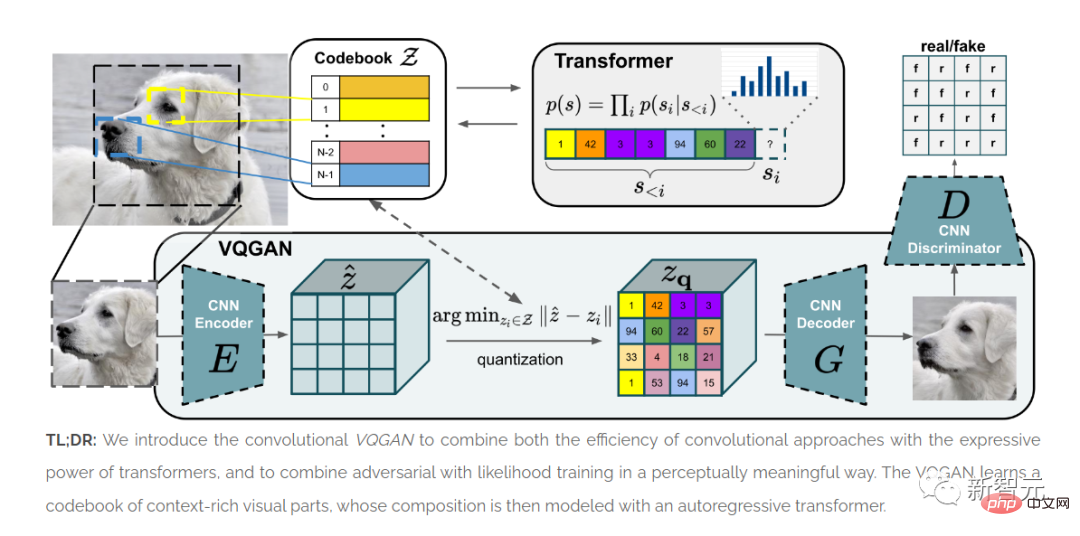
Die in diesem Artikel vorgestellte Methode VQGAN lieferte SOTA-Ergebnisse in Benchmark-Tests.
Die Qualität von GAN-Architekturen aus den späten 2010er Jahren wurde hauptsächlich anhand ausgerichteter Gesichtsbilder bewertet, wobei für heterogenere Datensätze nur begrenzte Ergebnisse erzielt wurden.
Das menschliche Gesicht bleibt daher ein wichtiger Bezugspunkt in akademischen/industriellen und künstlerischen Experimenten.
Die Ära von Transformer (2020-2022)
Das Aufkommen der Transformer-Architektur hat die Geschichte der Bildsynthese völlig neu geschrieben.
Seitdem hat der Bereich der Bildsynthese begonnen, GAN hinter sich zu lassen.
„Multimodales“ Deep Learning integriert NLP- und Computer-Vision-Technologien. „Just-in-Time-Engineering“ ersetzt Modelltraining und -anpassung und wird zu einer künstlerischen Methode der Bildsynthese.
In dem Artikel „Learning Transferable Visual Models from Natural Language Supervision“ wird die CLIP-Architektur vorgeschlagen.

Man kann sagen, dass der aktuelle Trend zur Bildsynthese auf die erstmals von CLIP eingeführte multimodale Funktion zurückzuführen ist.
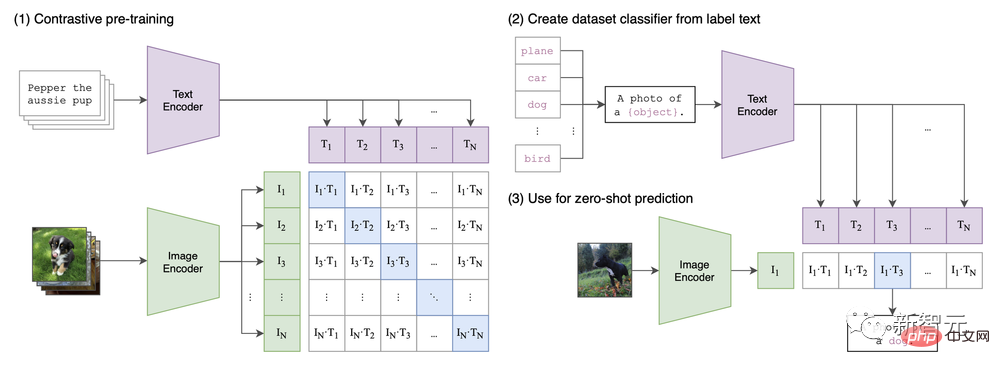
CLIP Architektur in Papier
Januar 2021

Der Artikel „Zero-Sample Text to Image Generation“ wurde veröffentlicht (siehe auch den Blogbeitrag von OpenAI), der die erste Version von DALL-E vorstellte, die kurz vor der Welteinführung steht.
Diese Version kombiniert Text und Bilder (von VAE als „TOKEN“ komprimiert) in einem einzigen Datenstrom.
Dieses Modell „setzt“ den „Satz“ einfach fort.
Die Daten (250 Millionen Bilder) umfassen Text-Bild-Paare aus Wikipedia, Konzeptbeschreibungen und eine gefilterte Teilmenge von YFCM100M.
CLIP legt den Grundstein für den „multimodalen“ Ansatz der Bildsynthese.
Januar 2021
# 🎜 🎜# Der Artikel „Learning Transferable Vision Models from Natural Language Supervision“ wurde veröffentlicht. In dem Artikel wird CLIP vorgestellt, ein multimodales Modell, das ViT und gewöhnlichen Transformer kombiniert.

CLIP lernt den „gemeinsamen latenten Raum“ des Bildes und den Titel, sodass es das Bild beschriften kann .
Das Modell wird anhand eines großen Datensatzes trainiert, der in Anhang A.1 des Dokuments aufgeführt ist. 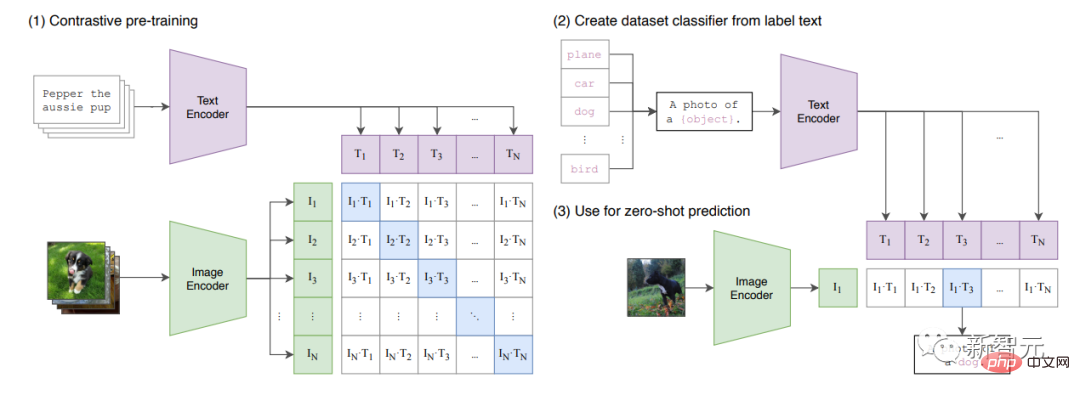
Juni 2021.
#🎜 🎜# Der Artikel „Die Veröffentlichung des Diffusionsmodells schlägt GAN in der Bildsynthese“ wurde veröffentlicht. Das Diffusionsmodell führt eine Bildsynthesemethode ein, die sich von der GAN-Methode unterscheidet. Forscher lernen, indem sie Bilder aus künstlich hinzugefügtem Rauschen rekonstruieren. Sie hängen mit Variational Autoencodern (VAEs) zusammen.
Juli 2021.

#🎜 🎜# DALL-E mini veröffentlicht.

Es ist eine Kopie von DALL-E (kleiner, mit wenigen Anpassungen an Architektur und Daten).
Die Daten umfassen Conceptual 12M, Conceptual Captions und die gleiche gefilterte Teilmenge von YFCM100M, die von OpenAI für das ursprüngliche DALL-E-Modell verwendet wurde.
Da es keine Inhaltsfilter oder API-Einschränkungen gibt, bietet der DALL-E mini ein enormes Potenzial für kreative Erkundungen, was zu Tweets wie „Weird DALL-E“ führt war eine Explosion von Bildern. 2021-2022
# 🎜🎜 #Katherine Crowson hat eine Reihe von CoLab-Notizen veröffentlicht, in denen Methoden zur Erstellung CLIP-gesteuerter generativer Modelle untersucht werden.
Zum Beispiel werden 512x512CLIP-gesteuerte Diffusion und VQGAN-CLIP (Open-Domain-Bildgenerierung und -bearbeitung mit natürlicher Sprachführung) im Jahr 2022 nur als Vorabdrucke veröffentlicht, VQGAN jedoch schon veröffentlicht werden, sobald es veröffentlicht wird) Öffentliche Experimente entstanden).
Genau wie in der frühen GAN-Ära haben Künstler und Entwickler mit sehr begrenzten Mitteln erhebliche Verbesserungen an bestehenden Architekturen vorgenommen, die dann von Unternehmen vereinfacht und schließlich von „Startups“ wie wombo.ai kommerzialisiert wurden.
April 2022
Der Artikel „Hierarchical Text Conditional Image Generation with CLIP Potential“ wurde veröffentlicht.

Dieses Dokument stellt DALL-E 2 vor.

Es baut auf dem erst vor wenigen Wochen veröffentlichten GLIDE-Papier („GLIDE: Realistic Image Generation and Editing Using Text-Guided Diffusion Models“) auf.

Mittlerweile besteht aufgrund des begrenzten Zugangs und der absichtlichen Einschränkungen des DALL-E 2 erneutes Interesse am DALL-E mini.
Laut Modellkarte umfassen die Daten „eine Kombination aus öffentlich verfügbaren Ressourcen und unseren lizenzierten Ressourcen“. .“ Und die vollständigen CLIP- und DALL-E-Datensätze laut Papier.

„Porträtfoto einer Blondine, aufgenommen mit einer DSLR-Kamera, neutraler Hintergrund, hohe Auflösung“, erstellt mit DALL-E 2.Transformer-basierte generative Modelle entsprechen dem Realismus späterer GAN-Architekturen wie StyleGAN 2, ermöglichen jedoch die Erstellung einer Vielzahl von Themen und Mustern Im Juni wurde das Papier „Realistic Text-to-Image Diffusion Model with Deep Language Understanding“ veröffentlicht
In diesen beiden Artikeln werden Imagegen und Parti vorgestellt
 und Googles Antwort auf DALL-E 2.
und Googles Antwort auf DALL-E 2.
「Wissen Sie, warum habe ich Sie heute aufgehalten?“ Erstellt von DALL-E 2, „Prompt Engineering“, ist seitdem die Hauptmethode der künstlerischen Bildsynthese Die schnelle Kommerzialisierung führte auch dazu, dass die Verwendung von Anfang an eingeschränkt war.
 Benutzer probierten weiterhin kleinere Modelle wie DALL-E mini aus. Mit der bahnbrechenden Veröffentlichung von Stable Diffusion änderte sich dies alles .
Benutzer probierten weiterhin kleinere Modelle wie DALL-E mini aus. Mit der bahnbrechenden Veröffentlichung von Stable Diffusion änderte sich dies alles .
Man kann sagen, dass Stable Diffusion den Beginn der „Photoshop-Ära“ der Bildsynthese markiert.

„Stillleben mit vier Weintrauben, bei dem versucht wird, Weintrauben so naturgetreu zu schaffen wie die des antiken Malers Zeuxis Juan El Labrador Fernandez, 1636, Prado, Madrid“ Sechs von Stable Diffusion produzierte Variationen
August 2022
Stability.ai veröffentlicht das Stable Diffusion-Modell.

In dem Artikel „High-Resolution Image Synthesis with Latent Diffusion Model“ stellt Stability.ai stolz Stable Diffusion vor.
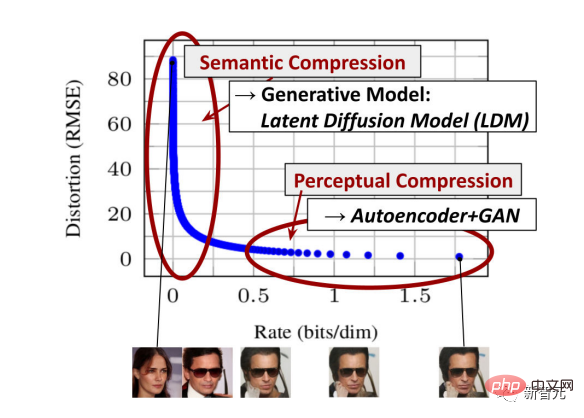
Dieses Modell kann den gleichen Fotorealismus wie DALL-E 2 erreichen.
Zusätzlich zu DALL-E 2 stehen Modelle fast sofort der Öffentlichkeit zur Verfügung und können auf den Plattformen CoLab und Huggingface ausgeführt werden.
Im August 2022
Google veröffentlichte das Papier „DreamBooth: Fine-tuning text-to-image diffusion model for topic-driven generation“.

DreamBooth bietet eine zunehmend feinkörnigere Steuerung des Diffusionsmodells.

Aber auch ohne solche zusätzlichen technischen Eingriffe ist es möglich, generative Modelle wie Photoshop zu verwenden, indem man von einer Skizze ausgeht und Schicht für Schicht generative Modifikationen hinzufügt.
Oktober 2022

Shutterstock, eines der größten Stockfoto-Unternehmen, gab seine Zusammenarbeit mit OpenAI zur Bereitstellung/Lizenzierung generierter Bilder bekannt stark von generativen Modellen wie Stable Diffusion beeinflusst.
Das obige ist der detaillierte Inhalt vonHinton ist auf der Liste! Eine Bestandsaufnahme der 10-jährigen Geschichte der KI-Bildsynthese, Artikel und Namen, an die man sich erinnern sollte. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Bei der Konvertierung von Zeichenfolgen in Objekte in Vue.js wird JSON.Parse () für Standard -JSON -Zeichenfolgen bevorzugt. Bei nicht standardmäßigen JSON-Zeichenfolgen kann die Zeichenfolge durch Verwendung regelmäßiger Ausdrücke verarbeitet und Methoden gemäß dem Format oder dekodierten URL-kodiert reduziert werden. Wählen Sie die entsprechende Methode gemäß dem String -Format aus und achten Sie auf Sicherheits- und Codierungsprobleme, um Fehler zu vermeiden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
Zusammenfassung: Es gibt die folgenden Methoden zum Umwandeln von VUE.JS -String -Arrays in Objektarrays: Grundlegende Methode: Verwenden Sie die Kartenfunktion, um regelmäßige formatierte Daten zu entsprechen. Erweitertes Gameplay: Die Verwendung regulärer Ausdrücke kann komplexe Formate ausführen, müssen jedoch sorgfältig geschrieben und berücksichtigt werden. Leistungsoptimierung: In Betracht ziehen die große Datenmenge, asynchrone Operationen oder effiziente Datenverarbeitungsbibliotheken können verwendet werden. Best Practice: Clear Code -Stil, verwenden Sie sinnvolle variable Namen und Kommentare, um den Code präzise zu halten.
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 Vue- und Element-UI-Kaskaden-Dropdown-Box V-Model-Bindung
Apr 07, 2025 pm 08:06 PM
Vue- und Element-UI-Kaskaden-Dropdown-Box V-Model-Bindung
Apr 07, 2025 pm 08:06 PM
Vue- und Element-UI-kaskadierte Dropdown-Boxen V-Model-Bindung gemeinsame Grubenpunkte: V-Model bindet ein Array, das die ausgewählten Werte auf jeder Ebene des kaskadierten Auswahlfelds darstellt, nicht auf einer Zeichenfolge; Der Anfangswert von ausgewählten Optionen muss ein leeres Array sein, nicht null oder undefiniert. Die dynamische Belastung von Daten erfordert die Verwendung asynchroner Programmierkenntnisse, um Datenaktualisierungen asynchron zu verarbeiten. Für riesige Datensätze sollten Leistungsoptimierungstechniken wie virtuelles Scrollen und fauler Laden in Betracht gezogen werden.
