

Ein Modul kann als eine Sammlung von Funktionen betrachtet werden.
Eine Reihe von Funktionen können in einer Py-Datei platziert werden, sodass eine Py-Datei als Modul betrachtet werden kann.
Wenn der Dateiname dieser py-Datei module.py,模块名则是module ist.
In Python gibt es insgesamt die folgenden vier Formen von Modulen:
Benutzerdefiniertes Modul: Wenn Sie selbst eine Py-Datei schreiben und eine Reihe von Funktionen in die Datei schreiben, dann Es wird als benutzerdefiniertes Modul bezeichnet, d. h. eine in Python geschriebene .py-Datei
Module von Drittanbietern: C- oder C++-Erweiterungen, die als gemeinsam genutzte Bibliotheken oder DLLs kompiliert wurden, wie z. B. Anfragen
Integrierte Module: geschrieben in C Und mit den integrierten Modulen des Python-Interpreters verknüpft, z. B. time
Paket (Ordner): ein Ordner, der eine Reihe von Modulen zusammen organisiert (Hinweis: Unter dem Ordner befindet sich eine Datei __init__.py. was heißt Es ist ein Paket)
Die Verwendung von Modulen von Drittanbietern oder integrierten Modulen ist eine Art Kreditaufnahme, die die Entwicklungseffizienz erheblich verbessern kann.
Benutzerdefinierte Module schreiben die in unseren eigenen Programmen verwendeten öffentlichen Funktionen in eine Python-Datei, und dann kann jede Komponente des Programms durch Import auf die Funktionen des benutzerdefinierten Moduls verweisen.
Im Allgemeinen verwenden wir Import und from...import..., um Module zu importieren.
Nehmen Sie den folgenden Dateicode in spam.py als Beispiel.
# spam.py print('from the spam.py') money = 1000 def read1(): print('spam模块:', money) def read2(): print('spam模块') read1() def change(): global money money = 0
lautet wie folgt:
import module1[, module2[,... moduleN]
Auf das importierte Modul muss mit einem Präfix zugegriffen werden.
Drei Dinge passieren beim ersten Importieren eines Moduls:
Erstellen Sie einen Namensraum des Moduls basierend auf dem Modul.
Führen Sie die dem Modul entsprechende Datei aus und werfen Sie alle während der Ausführung generierten Namen hinein der Namespace des Moduls
Rufen Sie einen Modulnamen in der aktuellen Ausführungsdatei ab
Hinweis: Der wiederholte Import des Moduls verweist direkt auf die zuvor erstellten Ergebnisse und die Datei des Moduls wird nicht wiederholt ausgeführt.
# run.py import spam # from the spam.py import spam money = 111111 spam.read1() # 'spam模块:1000' spam.change() print(spam.money) # 0 print(money) # 111111
# run.py import spam as sm money = 111111 sm.money sm.read1() # 'spam模块:1000' sm.read2 sm.change() print(money) # 1000
import spam, time, os # 推荐使用下述方式 import spam import time import os
Die Syntax lautet wie folgt:
from modname import name1[, name2[, ... nameN]]
Diese Anweisung wird nicht Importieren Sie das gesamte Modul. Es werden nur eine oder mehrere Funktionen aus dem Modul in den aktuellen Namespace eingeführt.
Auf von...import... importierte Module muss nicht mit einem Präfix zugegriffen werden.
von...import...Wenn Sie ein Modul zum ersten Mal importieren, passieren drei Dinge:
Erstellen Sie einen Modul-Namespace basierend auf dem Modul.
Führen Sie die dem Modul entsprechende Datei aus und verwenden Sie die Während der Ausführung generierter Name Wirf sie alle in den Namespace des Moduls
Erhalten Sie einen Namen im Namespace der aktuellen Ausführungsdatei, der direkt auf einen Namen im Modul verweist, was bedeutet, dass er direkt verwendet werden kann, ohne einen Namen hinzuzufügen Präfix
Vorteile: Es müssen keine Präfixe hinzugefügt werden, der Code ist schlanker
Nachteile: Es kann leicht zu Konflikten mit den Namen im Namensraum in der aktuellen Ausführungsdatei kommen
# run.py from spam import money from spam import money,read1 money = 10 print(money) # 10
# spam.py __all__ = ['money', 'read1'] # 只允许导入'money'和'read1' # run.py from spam import * # 导入spam.py内的所有功能,但会受限制于__all__ money = 111111 read1() # 'spam模块:1000' change() read1() # 'spam模块:0' print(money) # 111111
Zirkulärer Import findet in den folgenden Situationen statt:
# m1.py print('from m1.py') from m2 import x y = 'm1' # m2.py print('from m2.py') from m1 import y x = 'm2'
Sie können die Funktion, nur die Syntax in der Funktionsdefinitionsphase zu erkennen, verwenden, um das Problem zu lösen Problem des zirkulären Imports, oder das Problem des zirkulären Imports im Wesentlichen lösen, aber die beste Lösung besteht nicht darin, dass ein zirkulärer Import auftritt.
Option 1:
# m1.py print('from m1.py') def func1(): from m2 import x print(x) y = 'm1' # m2.py print('from m2.py') def func1(): from m1 import y print(y) x = 'm2'
Option 2:
5、# m1.py print('from m1.py') y = 'm1' from m2 import x # m2.py print('from m2.py') x = 'm2' from m1 import y
Die integrierte Funktion dir() kann alle im Modul definierten Namen finden. Wird in Form einer Zeichenfolgenliste zurückgegeben:
dir(sys) ['__displayhook__', '__doc__', '__excepthook__', '__loader__', '__name__', '__package__', '__stderr__', '__stdin__', '__stdout__', '_clear_type_cache', '_current_frames', '_debugmallocstats', '_getframe', '_home', '_mercurial', '_xoptions', 'abiflags', 'api_version', 'argv', 'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder', 'call_tracing', 'callstats', 'copyright', 'displayhook', 'dont_write_bytecode', 'exc_info', 'excepthook', 'exec_prefix', 'executable', 'exit', 'flags', 'float_info', 'float_repr_style', 'getcheckinterval', 'getdefaultencoding', 'getdlopenflags', 'getfilesystemencoding', 'getobjects', 'getprofile', 'getrecursionlimit', 'getrefcount', 'getsizeof', 'getswitchinterval', 'gettotalrefcount', 'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info', 'intern', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path', 'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'ps1', 'setcheckinterval', 'setdlopenflags', 'setprofile', 'setrecursionlimit', 'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdout', 'thread_info', 'version', 'version_info', 'warnoptions']
Wenn keine Parameter angegeben sind, listet die Funktion dir() alle derzeit definierten Namen auf:
a = [1, 2, 3, 4, 5] import fibo fib = fibo.fib print(dir()) # 得到一个当前模块中定义的属性列表 # ['__builtins__', '__name__', 'a', 'fib', 'fibo', 'sys'] b = 5 # 建立一个新的变量 'a' print(dir()) # ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'b'] del b # 删除变量名a print(dir()) # ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a']
# test.py import m1 # 从m1.py文件中导入的,然后会生成m1模块的名称空间 import time # 删除m1.py文件,m1模块的名称空间仍然存在 time.sleep(10) import m1 # 不报错,一定不是从文件中获取了m1模块,而是从内存中获取的
2. Integrierte Module
# time.py print('from time.py') # run.py import time print(time) #
3. Suchen Sie in der Umgebungsvariablen sys.path (Hervorhebung: Der erste Wert von sys.path ist der Ordner, in dem sich die aktuelle Ausführungsdatei befindet)
import sys for n in sys.path: print(n) # C:\PycharmProjects\untitled\venv\Scripts\python.exe C:/PycharmProjects/untitled/hello.py # C:\PycharmProjects\untitled # C:\PycharmProjects\untitled # C:\Python\Python38\python38.zip # C:\Python\Python38\DLLs # C:\Python\Python38\lib # C:\Python\Python38 # C:\PycharmProjects\untitled\venv # C:\PycharmProjects\untitled\venv\lib\site-packages
# run.py import sys sys.path.append(r'C:\PycharmProjects\untitled\day16') print(sys.path) import mmm mmm.f1()
2. Der Suchpfad basiert auf der ausführbaren Datei
而hello和spam.py不是同目录下的,因此run.py的环境变量无法直接找到m2,需要从文件夹导入
from aa import spam print(spam.money)
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
python文件总共有两种用途,一种是执行文件;另一种是被当做模块导入。
每个模块都有一个__name__属性,当其值是'__main__'时,表明该模块自身在运行,否则是被引入。
1、当run.py运行的时候,aaa.py被当做引用模块,它的__name__ == 'aaa'(模块名),会执行aaa.py中的f1()。
# aaa.py x = 1 def f1(): print('from f1') f1() # run.py import aaa
2、aaa.py被当做可执行文件时,加上__name__ == '__main__',单独运行aaa.py才会执行aaa.py中的f1()。 run.py运行时可以防止执行f1()。
# aaa.py x = 1 def f1(): print('from f1') if __name__ == '__main__': f1()
包是一种管理 Python 模块命名空间的形式,包的本质就是一个含有.py的文件的文件夹。
包采用"点模块名称"。比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。
目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包。
在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
导入包发生的三件事:
创建一个包的名称空间
由于包是一个文件夹,无法执行包,因此执行包下的.py文件,将执行过程中产生的名字存放于包名称空间中(即包名称空间中存放的名字都是来自于.py)
在当前执行文件中拿到一个名字aaa,aaa是指向包的名称空间的
导入包就是在导入包下的.py,导入m1就是导入m1中的__init__。
import ... :
import item.subitem.subsubitem 这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。
from ... import...:
当使用 from package import item 这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
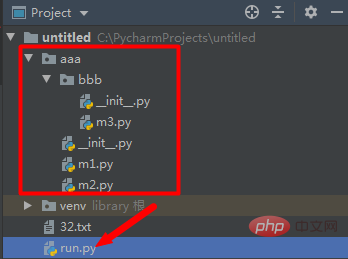
import 可以每次只导入一个包里面的特定模块,他必须使用全名去访问。
import aaa.bbb.m3 print(aaa.bbb.m3.func3())
import方式不能导入函数、变量:import aaa.bbb.m3.f3错误
这种方式不需要那些冗长的前缀进行访问
from aaa.bbb import m3 print(m3.func3())
这种方式不需要那些冗长的前缀进行访问
from aaa.bbb.m3 import func3 print(func3())
# aaa/.py from aaa.m1 import func1 from aaa.m2 import func2
.代表当前被导入文件所在的文件夹
..代表当前被导入文件所在的文件夹的上一级
...代表当前被导入文件所在的文件夹的上一级的上一级
from .m1 import func1 from .m2 import func2
导入语句遵循如下规则:如果包定义文件 __init__.py 存在一个叫做 __all__ 的列表变量,那么在使用 from package import * 的时候就把这个列表中的所有名字作为包内容导入。
这里有一个例子,在:file:sounds/effects/__init__.py中包含如下代码:
__all__ = ["echo", "surround", "reverse"]
这表示当你使用from sound.effects import *这种用法时,你只会导入包里面这三个子模块。
为了提高程序的可读性与可维护性,我们应该为软件设计良好的目录结构,这与规范的编码风格同等重要,简而言之就是把软件代码分文件目录。假设你要写一个ATM软件,你可以按照下面的目录结构管理你的软件代码:
ATM/ |-- core/ | |-- src.py # 业务核心逻辑代码 | |-- api/ | |-- api.py # 接口文件 | |-- db/ | |-- db_handle.py # 操作数据文件 | |-- db.txt # 存储数据文件 | |-- lib/ | |-- common.py # 共享功能 | |-- conf/ | |-- settings.py # 配置相关 | |-- bin/ | |-- run.py # 程序的启动文件,一般放在项目的根目录下,因为在运行时会默认将运行文件所在的文件夹作为sys.path的第一个路径,这样就省去了处理环境变量的步骤 | |-- log/ | |-- log.log # 日志文件 | |-- requirements.txt # 存放软件依赖的外部Python包列表,详见https://pip.readthedocs.io/en/1.1/requirements.html |-- README # 项目说明文件
# settings.py import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) DB_PATH = os.path.join(BASE_DIR, 'db', 'db.txt') LOG_PATH = os.path.join(BASE_DIR, 'log', 'user.log') # print(DB_PATH) # print(LOG_PATH)
# common.py import time from conf import settings def logger(msg): current_time = time.strftime('%Y-%m-%d %X') with open(settings.LOG_PATH, mode='a', encoding='utf-8') as f: f.write('%s %s' % (current_time, msg))
# src.py
from conf import settings
from lib import common
def login():
print('登陆')
def register():
print('注册')
name = input('username>>: ')
pwd = input('password>>: ')
with open(settings.DB_PATH, mode='a', encoding='utf-8') as f:
f.write('%s:%s\n' % (name, pwd))
# 记录日志。。。。。。
common.logger('%s注册成功' % name)
print('注册成功')
def shopping():
print('购物')
def pay():
print('支付')
def transfer():
print('转账')
func_dic = {
'1': login,
'2': register,
'3': shopping,
'4': pay,
'5': transfer,
}
def run():
while True:
print("""
1 登陆
2 注册
3 购物
4 支付
5 转账
6 退出
""")
choice = input('>>>: ').strip()
if choice == '6': break
if choice not in func_dic:
print('输入错误命令,傻叉')
continue
func_dic[choice]()# run.py import sys import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) from core import src if __name__ == '__main__': src.run()
Das obige ist der detaillierte Inhalt vonSo verwenden Sie Python-Basismodule. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



