
 Betrieb und Instandhaltung
Sicherheit
Welche Gefahren birgt die Zweitveröffentlichung von C-Sprachquellcode?
Betrieb und Instandhaltung
Sicherheit
Welche Gefahren birgt die Zweitveröffentlichung von C-Sprachquellcode?
Welche Gefahren birgt die Zweitveröffentlichung von C-Sprachquellcode?

1. Sekundäre Freigabe
Ein einfaches Verständnis der sekundären Freigabe besteht darin, dass der Speicher, auf den derselbe Zeiger zeigt, zweimal freigegeben wird. Bei C-Sprachquellcode werden free()-Operationen zweimal für denselben Zeiger ausgeführt In zwei Versionen beschreibt der fehlerhafte Code in Kapitel 3.1 dieses Artikels eine solche Situation. In der C++-Sprache ist ein unsachgemäßer flacher Kopiervorgang eine der häufigsten Ursachen für die sekundäre Veröffentlichung. Beispiel: Wenn Sie den Zuweisungsoperator oder den Kopierkonstruktor einmal aufrufen, verweisen die Datenelemente der beiden Objekte auf denselben dynamischen Speicher. Zu diesem Zeitpunkt wird der Referenzzählmechanismus sehr wichtig. Wenn die Referenzzählung falsch ist und ein Objekt den Gültigkeitsbereich verlässt, gibt der Destruktor den von den beiden Objekten gemeinsam genutzten Speicher frei. Das entsprechende Datenelement in einem anderen Objekt zeigt auf die freigegebene Speicheradresse. Wenn dieses Objekt ebenfalls den Gültigkeitsbereich verlässt, versucht sein Destruktor, den Speicher erneut freizugeben, was zu einem sekundären Freigabeproblem führt. Weitere Informationen finden Sie unter CWE ID 415: Double Free.
2. Der Schaden einer sekundären Freigabe
Die zweite Freigabe von Speicher kann zu Anwendungsabstürzen, Denial-of-Service-Angriffen und anderen Problemen führen. Dies ist eine der häufigsten Schwachstellen in C/C++. Von Januar bis November 2018 gab es in CVE insgesamt 38 diesbezügliche Schwachstelleninformationen. Einige der Schwachstellen sind wie folgt:
| CVE-Nummer | Übersicht |
|---|---|
| CVE-2018-18751 | 'def der Datei read-catalog.c in der GNU gettext.-Version 0,19. 8 aultaddmessage'-Funktion Es besteht eine sekundäre Release-Schwachstelle. |
| CVE-2018-17097 | Olli Parviainen SoundTouch Version 2.0 enthält eine Sicherheitslücke in der WavFileBase-Klasse der Datei WavFile.cpp, die es einem Remote-Angreifer ermöglichen könnte, einen Denial-of-Service zu verursachen (sekundäre Version). |
| CVE-2018-16425 | OpenSC-Versionen vor 0.19.0-rc1 weisen eine sekundäre freie Schwachstelle in der Funktion „scpkcs15emuschsminit“ der Datei libopensc/pkcs15-sc-hsm.c auf. Ein Angreifer könnte diese Sicherheitslücke ausnutzen, um mithilfe einer speziell gestalteten Smartcard einen Denial-of-Service (Anwendungsabsturz) auszulösen. |
| CVE-2018-16402 | elfutils Version 0.173 enthält ein Sicherheitsproblem in der Datei libelf/elf_end.c, das es einem Remote-Angreifer ermöglichen könnte, einen Denial-of-Service (sekundäre Veröffentlichung und Anwendungsabsturz) zu verursachen. |
3. Beispielcode
Das Beispiel stammt aus der Samate Juliet Test Suite für C/C++ v1.3 (https://samate.nist.gov/SARD/testsuite.php), Name der Quelldatei: CWE415_Double_Free__malloc_free_char_17 .c.
3.1 fehlerhafter Code

Im obigen Beispielcode verwenden Sie malloc() für die Speicherzuweisung in Zeile 32 und In Verwenden Sie in Zeile 36 free(), um den zugewiesenen Speicher freizugeben. In Zeile 38 for-Schleifenanweisung wird der freigegebene Speicher Daten noch einmal freigegeben, was ein sekundäres Freigabeproblem verursacht. malloc() 进行内存分配,并在第36行使用 free() 对分配的内存进行了释放,在第38行 for 循环语句中,又对已经释放的内存 data 进行了一次释放,导致二次释放问题。
使用360代码卫士对上述示例代码进行检测,可以检出“二次释放”缺陷,显示等级为中。如图1所示:
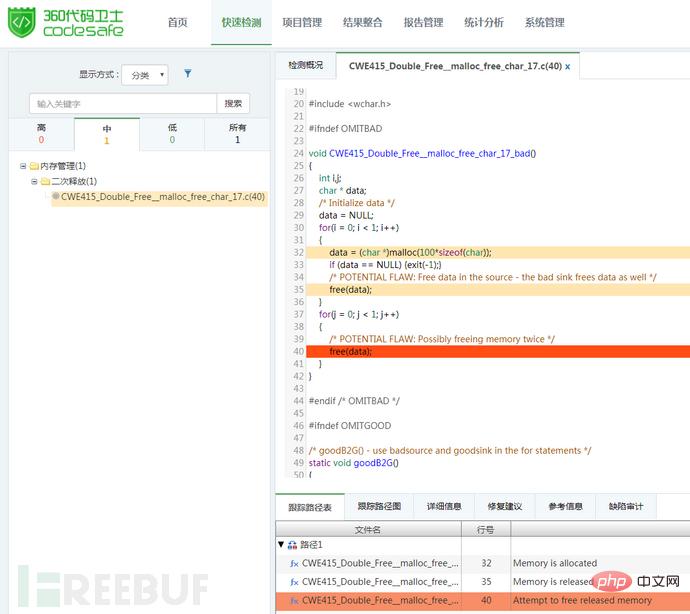
图1:二次释放检测示例
3.2 修复代码

在上述修复代码中,Samate 给出的修复方式为: 在第32行使用 malloc() 进行内存分配,并在第36行处使用 free() 进行释放,释放后不在对该内存进行释放操作。
使用360代码卫士对修复后的代码进行检测,可以看到已不存在“二次释放”缺陷。如图2:

图2:修复后检测结果
4 、如何避免二次释放
要避免二次释放,需要注意以下几点:
🎜🎜3.2 Reparaturcode🎜🎜🎜🎜(1)野指针是导致二次释放和释放后使用的重要原因之一,消除野指针的有效方式是在释放指针之后立即把它设置为
Verwenden Sie 360 Code Guard, um den obigen Beispielcode zu erkennen. Sie können den Fehler „Sekundärversion“ erkennen und die Anzeigeebene ist mittel. Wie in Abbildung 1 dargestellt:NULLAbbildung 1: Beispiel für die Erkennung sekundärer Veröffentlichungen
🎜🎜Im obigen Reparaturcode lautet die von Samate angegebene Reparaturmethode: Verwenden Sie malloc(), um Speicher zu reservieren, und verwenden Sie free(), um ihn in Zeile 36 freizugeben. Nach der Veröffentlichung , wird der Speicher nicht mehr freigegeben. 🎜🎜Verwenden Sie 360 Code Guard, um den reparierten Code zu erkennen, und Sie können sehen, dass kein „sekundärer Release“-Defekt vorliegt. Wie in Abbildung 2 dargestellt: 🎜🎜🎜🎜🎜Abbildung 2: Erkennungsergebnisse nach der Reparatur🎜🎜🎜4. So vermeiden Sie eine sekundäre Veröffentlichung🎜🎜🎜Um eine sekundäre Veröffentlichung zu vermeiden, müssen Sie auf die folgenden Punkte achten:🎜🎜(1 ) Wilde Zeiger führen zu sekundären Veröffentlichungen. Einer der wichtigen Gründe für die Veröffentlichung und Verwendung nach der Veröffentlichung ist, sie auf NULL zu setzen Setzen Sie es sofort nach der Freigabe auf einen Zeiger. Ein weiteres zulässiges Objekt. 🎜🎜(2) Für das sekundäre Release-Problem, das durch flache C++-Kopie verursacht wird, ist die ständige Durchführung einer tiefen Kopie eine gute Lösung. 🎜🎜(3) Mithilfe statischer Quellcode-Analysetools können Sie mögliche sekundäre Release-Probleme im Programm automatisch erkennen. 🎜🎜Das obige ist der detaillierte Inhalt vonWelche Gefahren birgt die Zweitveröffentlichung von C-Sprachquellcode?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 C Sprachdatenstruktur: Datenrepräsentation und Betrieb von Bäumen und Grafiken
Apr 04, 2025 am 11:18 AM
C Sprachdatenstruktur: Datenrepräsentation und Betrieb von Bäumen und Grafiken
Apr 04, 2025 am 11:18 AM
C Sprachdatenstruktur: Die Datenrepräsentation des Baumes und des Diagramms ist eine hierarchische Datenstruktur, die aus Knoten besteht. Jeder Knoten enthält ein Datenelement und einen Zeiger auf seine untergeordneten Knoten. Der binäre Baum ist eine besondere Art von Baum. Jeder Knoten hat höchstens zwei Kinderknoten. Die Daten repräsentieren structTreenode {intdata; structTreenode*links; structTreenode*rechts;}; Die Operation erstellt einen Baumtraversalbaum (Vorbereitung, in Ordnung und späterer Reihenfolge) Suchbauminsertion-Knoten Lösches Knotendiagramm ist eine Sammlung von Datenstrukturen, wobei Elemente Scheitelpunkte sind, und sie können durch Kanten mit richtigen oder ungerechten Daten miteinander verbunden werden, die Nachbarn darstellen.
 Die Wahrheit hinter dem Problem der C -Sprachdatei
Apr 04, 2025 am 11:24 AM
Die Wahrheit hinter dem Problem der C -Sprachdatei
Apr 04, 2025 am 11:24 AM
Die Wahrheit über Probleme mit der Dateibetrieb: Dateiöffnung fehlgeschlagen: unzureichende Berechtigungen, falsche Pfade und Datei besetzt. Das Schreiben von Daten fehlgeschlagen: Der Puffer ist voll, die Datei ist nicht beschreibbar und der Speicherplatz ist nicht ausreichend. Andere FAQs: Langsame Dateitraversal, falsche Textdateicodierung und Binärdatei -Leser -Fehler.
 Wie man einen Countdown in der C -Sprache ausgibt
Apr 04, 2025 am 08:54 AM
Wie man einen Countdown in der C -Sprache ausgibt
Apr 04, 2025 am 08:54 AM
Wie gibt ich einen Countdown in C aus? Antwort: Verwenden Sie Schleifenanweisungen. Schritte: 1. Definieren Sie die Variable N und speichern Sie die Countdown -Nummer in der Ausgabe. 2. Verwenden Sie die while -Schleife, um n kontinuierlich zu drucken, bis n weniger als 1 ist; 3. Drucken Sie im Schleifenkörper den Wert von n aus; 4. Am Ende der Schleife subtrahieren Sie N um 1, um den nächsten kleineren gegenseitigen gegenseitigen gegenseitigen gegenseitig auszugeben.
 C Sprach -Multithread -Programmierung: Ein Anfängerleitfaden und Fehlerbehebung
Apr 04, 2025 am 10:15 AM
C Sprach -Multithread -Programmierung: Ein Anfängerleitfaden und Fehlerbehebung
Apr 04, 2025 am 10:15 AM
C Sprachmultithreading -Programmierhandbuch: Erstellen von Threads: Verwenden Sie die Funktion pThread_create (), um Thread -ID, Eigenschaften und Threadfunktionen anzugeben. Threadsynchronisation: Verhindern Sie den Datenwettbewerb durch Mutexes, Semaphoren und bedingte Variablen. Praktischer Fall: Verwenden Sie Multi-Threading, um die Fibonacci-Nummer zu berechnen, mehrere Threads Aufgaben zuzuweisen und die Ergebnisse zu synchronisieren. Fehlerbehebung: Lösen Sie Probleme wie Programmabstürze, Thread -Stop -Antworten und Leistungs Engpässe.
 CS-Woche 3
Apr 04, 2025 am 06:06 AM
CS-Woche 3
Apr 04, 2025 am 06:06 AM
Algorithmen sind die Anweisungen zur Lösung von Problemen, und ihre Ausführungsgeschwindigkeit und Speicherverwendung variieren. Bei der Programmierung basieren viele Algorithmen auf der Datensuche und Sortierung. In diesem Artikel werden mehrere Datenabruf- und Sortieralgorithmen eingeführt. Die lineare Suche geht davon aus, dass es ein Array gibt [20.500,10,5,100, 1,50] und die Nummer 50 ermitteln muss. Der lineare Suchalgorithmus prüft jedes Element im Array Eins nach eins nach dem anderen, bis der Zielwert gefunden oder das vollständige Array durchquert wird. Der Algorithmus-Flussdiagramm lautet wie folgt: Der Pseudo-Code für die lineare Suche lautet wie folgt: Überprüfen Sie jedes Element: Wenn der Zielwert gefunden wird: Return Return Falsch C-Sprache Implementierung: #includeIntmain (void) {i
 Konzept der C -Sprachfunktion
Apr 03, 2025 pm 10:09 PM
Konzept der C -Sprachfunktion
Apr 03, 2025 pm 10:09 PM
C -Sprachfunktionen sind wiederverwendbare Codeblöcke. Sie erhalten Input, führen Vorgänge und Rückgabergebnisse aus, die modular die Wiederverwendbarkeit verbessert und die Komplexität verringert. Der interne Mechanismus der Funktion umfasst Parameterübergabe-, Funktionsausführung und Rückgabeteile. Der gesamte Prozess beinhaltet eine Optimierung wie die Funktion inline. Eine gute Funktion wird nach dem Prinzip der einzigen Verantwortung, der geringen Anzahl von Parametern, den Benennungsspezifikationen und der Fehlerbehandlung geschrieben. Zeiger in Kombination mit Funktionen können leistungsstärkere Funktionen erzielen, z. B. die Änderung der externen Variablenwerte. Funktionszeiger übergeben Funktionen als Parameter oder speichern Adressen und werden verwendet, um dynamische Aufrufe zu Funktionen zu implementieren. Das Verständnis von Funktionsmerkmalen und Techniken ist der Schlüssel zum Schreiben effizienter, wartbarer und leicht verständlicher C -Programme.
 Fehlerbehebungstipps für die Verarbeitung von Dateien in der C -Sprache
Apr 04, 2025 am 11:15 AM
Fehlerbehebungstipps für die Verarbeitung von Dateien in der C -Sprache
Apr 04, 2025 am 11:15 AM
Fehlerbehebungstipps für C -Sprachverarbeitungsdateien Wenn Dateien in der C -Sprache verarbeitet werden, können Sie auf verschiedene Probleme stoßen. Das Folgende sind häufig zu Problemen und entsprechende Lösungen: Problem 1: Der Dateicode kann nicht geöffnet werden: Datei*fp = fopen ("myFile.txt", "r"); if (fp == null) {// Datei Öffnen fehlgeschlagen} Grund} Grund: Dateipfad -Fehler -Datei nicht vorhandener Datei -Read -Lösung vorhanden. Charbuffer [100]; size_tread_bytes = fread (Puffer, 1, Siz
 C Sprachdatenstruktur: Die Schlüsselrolle von Datenstrukturen in der künstlichen Intelligenz
Apr 04, 2025 am 10:45 AM
C Sprachdatenstruktur: Die Schlüsselrolle von Datenstrukturen in der künstlichen Intelligenz
Apr 04, 2025 am 10:45 AM
C Sprachdatenstruktur: Überblick über die Schlüsselrolle der Datenstruktur in der künstlichen Intelligenz im Bereich der künstlichen Intelligenz sind Datenstrukturen für die Verarbeitung großer Datenmengen von entscheidender Bedeutung. Datenstrukturen bieten eine effektive Möglichkeit, Daten zu organisieren und zu verwalten, Algorithmen zu optimieren und die Programmeffizienz zu verbessern. Gemeinsame Datenstrukturen, die häufig verwendete Datenstrukturen in der C -Sprache sind: Arrays: Eine Reihe von nacheinander gespeicherten Datenelementen mit demselben Typ. Struktur: Ein Datentyp, der verschiedene Arten von Daten zusammen organisiert und ihnen einen Namen gibt. Linked List: Eine lineare Datenstruktur, in der Datenelemente durch Zeiger miteinander verbunden werden. Stack: Datenstruktur, die dem LEST-In-First-Out-Prinzip (LIFO) folgt. Warteschlange: Datenstruktur, die dem First-In-First-Out-Prinzip (FIFO) folgt. Praktischer Fall: Die benachbarte Tabelle in der Graphentheorie ist künstliche Intelligenz
