

So verwenden Sie die Python-Crawler-Requests-Bibliothek

1. Installieren Sie die Anforderungsbibliothek
Da der Lernprozess die Python-Sprache verwendet, müssen Sie Python 3.8 installieren. Sie können die von Ihnen installierte Python-Version überprüfen. Es wird empfohlen, Python 3. Version X oder höher zu installieren.
Nach der Installation von Python können Sie die Anforderungsbibliothek über den folgenden Befehl direkt installieren.
pip install requests
Ps: Sie können zu inländischen Pip-Quellen wie Alibaba und Douban wechseln, was schnell geht
Um die Funktion zu demonstrieren, habe ich Nginx verwendet, um eine einfache Website zu simulieren.
Führen Sie nach dem Herunterladen einfach das Programm nginx.exe direkt im Stammverzeichnis aus (Hinweis: unter Windows-Umgebung).
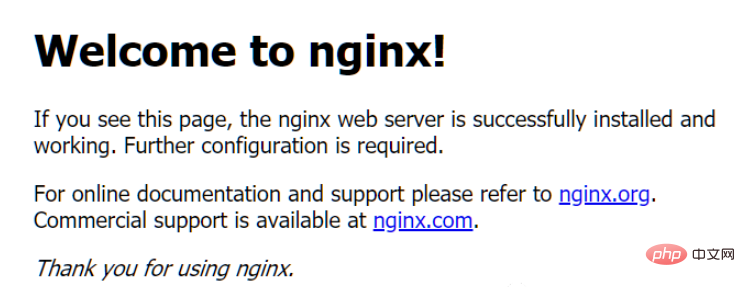
Wenn der lokale Computer zu diesem Zeitpunkt auf http://127.0.0.1 zugreift, wird eine Standardseite von Nginx aufgerufen.
2. Holen Sie sich die Webseite
Als Nächstes beginnen wir mit der Verwendung von Anfragen, um eine Anfrage zu simulieren und den Quellcode der Seite abzurufen.
import requestsr = requests.get('http://127.0.0.1')print(r.text)Die nach der Ausführung erhaltenen Ergebnisse sind wie folgt:
nbsp;html><title>Welcome to nginx!</title><style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; }</style><h2 id="Welcome-to-nginx">Welcome to nginx!</h2><p>If you see this page, the nginx web server is successfully installed andworking. Further configuration is required.</p>
<p>For online documentation and support please refer to<a>nginx.org</a>.<br>Commercial support is available at<a>nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>3. Über Anfragen
Das obige Beispiel verwendet beispielsweise die GET-Anfrage . 4. GET-Anfrage Sehen Sie sich das Rückgabeergebnis an. Die enthaltenen Informationen sind: Header, URL, IP usw.
4.2. Parameter hinzufügen
Normalerweise enthält die URL, die wir besuchen, einige Parameter, wie zum Beispiel: ID ist 100, Name ist YOOAO. Für den normalen Zugriff schreiben wir die folgende URL für den Zugriff: import requests r = requests.get('http://httpbin.org/get') print(r.text)
{"args": {}, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5f846520-19f215aa46213a2b4241c18a" }, "origin": "xxxx", "url": "http://httpbin.org/get"}Dies ist das Ergebnis, das durch die folgende Ausführung des Codes zurückgegeben wird:
http://httpbin.org/get?id=100&name=YOOAO
Durch die Rückgabe des Ergebnisses können wir sehen, dass die über das Wörterbuch übertragenen Parameter automatisch zu einer vollständigen URL erstellt werden und wir diese nicht manuell vervollständigen müssen selbst bauen.
4.3. Verarbeitung des RückgabeergebnissesDas Rückgabeergebnis liegt im JSON-Format vor, sodass wir zum Parsen die Methode zum Aufrufen von JSON verwenden können. Wenn der zurückgegebene Inhalt nicht im JSON-Format vorliegt, meldet dieser Aufruf einen Fehler.
import requests data = { 'id': '100', 'name': 'YOOAO'} r = requests.get('http://httpbin.org/get', params=data) print(r.text)Ergebnisse zurückgeben:
{"args": {"id": "100", "name": "YOOAO" }, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5f84658a-1cd0437b4cf34835410d7161" }, "origin": "xxx.xxxx.xxx.xxx", "url": "http://httpbin.org/get?id=100&name=YOOAO"}Hier verwenden wir einfache reguläre Ausdrücke, um den Inhalt aller -Tags zu erfassen. Der Code lautet wie folgt:
import requests
r = requests.get('http://httpbin.org/get') print(type(r.text)) print(type(r.json()))Ergebnisse abrufen:
<class><class></class></class>
Eine einfache Seitenerfassung und das Crawlen von Inhalten sind hier abgeschlossen,
4.5, Datendatei-DownloadDas obige Beispiel gibt alle Seiteninformationen zurück, wenn wir die Seiteninformationen für Bilder, Audio und Video erhalten möchten Dateien müssen wir lernen, die Binärdaten der Seite zu erfassen. Wir können die open-Methode verwenden, um den Download von Binärdateien wie Bildern abzuschließen:
import requestsimport re
r = requests.get('http://127.0.0.1')pattern = re.compile('<a.>(.*?)', re.S)a_content = re.findall(pattern, r.text)print(a_content)</a.>Bei der open-Methode ist der erste Parameter der Dateiname und der zweite Parameter bedeutet, dass sie in binärer Form geöffnet wird In die Datei schreiben. Binärdaten eingeben. Nachdem der Vorgang abgeschlossen ist, werden die heruntergeladenen Bilder im selben Ordner der laufenden Datei gespeichert. Nach dem gleichen Prinzip können wir Video- und Audiodateien verarbeiten.
4.6. Header hinzufügenIm obigen Beispiel haben wir die Anfrage direkt initiiert, ohne Header hinzuzufügen. Einige Websites verursachen Zugriffsausnahmen, da die Anfragen keine Header-Inhalte enthalten und den Uer hinzufügen -Agent-Inhaltscode in den Headern:
['nginx.org', 'nginx.com']
Ausführungsergebnis: import requests
r = requests.get('http://tu.ossfiles.cn:9186/group3/M00/09/FB/rBpVfl8QFLOAYhhcAAC-pTdNj7g471.jpg')with open('image.jpg', 'wb') as f: f.write(r.content)print('下载完成')
Da wir nun etwas über die GET-Anfrage erfahren haben, sprechen wir über eine weitere gängige Anfragemethode: POST-Anfrage.
使用 requests 实现 POST 请求的代码如下:
import requestsdata = { 'id': '100', 'name': 'YOOAO'}
r = requests.post("http://httpbin.org/post", data=data)print(r.text)结果如下
{"args": {}, "data": "", "files": {}, "form": {"id": "100", "name": "YOOAO" }, "headers": {"Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "17", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5ec8f4a0-affca27a05e320a84ca6535a" }, "json": null, "origin": "xxxx", "url": "http://httpbin.org/post"}从 form 中我们看到了自己提交的数据,可见我们的 POST 请求访问成功。
6、响应
访问URL时,有请求就会有响应,上面的示例使用 text 和 content 获取了响应的内容。除此以外,还有很多属性和方法可以用来获取其他信息,比如状态码、响应头、Cookies 等。
import requests
r = requests.get('http://127.0.0.1/')print(type(r.status_code), r.status_code)print(type(r.headers), r.headers)print(type(r.cookies), r.cookies)print(type(r.url), r.url)print(type(r.history), r.history)关于状态码,requests 还提供了一个内置的状态码查询对象 requests.codes,用法示例如下:
import requestsr = requests.get('http://127.0.0.1/')exit() if not r.status_code == requests.codes.ok else print('Request Successfully')==========执行结果==========Request Successfully这里通过比较返回码和内置的成功的返回码,来保证请求得到了正常响应,输出成功请求的消息,否则程序终止。
这里我们用 requests.codes.ok 得到的是成功的状态码 200。
这样的话,我们就不用再在程序里面写状态码对应的数字了,用字符串表示状态码会显得更加直观。
下面是响应码和查询条件对照信息:
# 信息性状态码 100: ('continue',), 101: ('switching_protocols',), 102: ('processing',), 103: ('checkpoint',), 122: ('uri_too_long', 'request_uri_too_long'),
# 成功状态码 200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\\o/', '✓'), 201: ('created',), 202: ('accepted',), 203: ('non_authoritative_info', 'non_authoritative_information'), 204: ('no_content',), 205: ('reset_content', 'reset'), 206: ('partial_content', 'partial'), 207: ('multi_status', 'multiple_status', 'multi_stati', 'multiple_stati'), 208: ('already_reported',), 226: ('im_used',),
# 重定向状态码 300: ('multiple_choices',), 301: ('moved_permanently', 'moved', '\\o-'), 302: ('found',), 303: ('see_other', 'other'), 304: ('not_modified',), 305: ('use_proxy',), 306: ('switch_proxy',), 307: ('temporary_redirect', 'temporary_moved', 'temporary'), 308: ('permanent_redirect', 'resume_incomplete', 'resume',), # These 2 to be removed in 3.0
# 客户端错误状态码 400: ('bad_request', 'bad'), 401: ('unauthorized',), 402: ('payment_required', 'payment'), 403: ('forbidden',), 404: ('not_found', '-o-'), 405: ('method_not_allowed', 'not_allowed'), 406: ('not_acceptable',), 407: ('proxy_authentication_required', 'proxy_auth', 'proxy_authentication'), 408: ('request_timeout', 'timeout'), 409: ('conflict',), 410: ('gone',), 411: ('length_required',), 412: ('precondition_failed', 'precondition'), 413: ('request_entity_too_large',), 414: ('request_uri_too_large',), 415: ('unsupported_media_type', 'unsupported_media', 'media_type'), 416: ('requested_range_not_satisfiable', 'requested_range', 'range_not_satisfiable'), 417: ('expectation_failed',), 418: ('im_a_teapot', 'teapot', 'i_am_a_teapot'), 421: ('misdirected_request',), 422: ('unprocessable_entity', 'unprocessable'), 423: ('locked',), 424: ('failed_dependency', 'dependency'), 425: ('unordered_collection', 'unordered'), 426: ('upgrade_required', 'upgrade'), 428: ('precondition_required', 'precondition'), 429: ('too_many_requests', 'too_many'), 431: ('header_fields_too_large', 'fields_too_large'), 444: ('no_response', 'none'), 449: ('retry_with', 'retry'), 450: ('blocked_by_windows_parental_controls', 'parental_controls'), 451: ('unavailable_for_legal_reasons', 'legal_reasons'), 499: ('client_closed_request',),
# 服务端错误状态码 500: ('internal_server_error', 'server_error', '/o\\', '✗'), 501: ('not_implemented',), 502: ('bad_gateway',), 503: ('service_unavailable', 'unavailable'), 504: ('gateway_timeout',), 505: ('http_version_not_supported', 'http_version'), 506: ('variant_also_negotiates',), 507: ('insufficient_storage',), 509: ('bandwidth_limit_exceeded', 'bandwidth'), 510: ('not_extended',), 511: ('network_authentication_required', 'network_auth', 'network_authentication')7、SSL 证书验证
现在很多网站都会验证证书,我们可以设置参数来忽略证书的验证。
import requests
response = requests.get('https://XXXXXXXX', verify=False)print(response.status_code)或者制定本地证书作为客户端证书:
import requests
response = requests.get('https://xxxxxx', cert=('/path/server.crt', '/path/server.key'))print(response.status_code)注意:本地私有证书的 key 必须是解密状态,加密状态的 key 是不支持的。
8、设置超时
很多时候我们需要设置超时时间来控制访问的效率,遇到访问慢的链接直接跳过。
示例代码:
import requests# 设置超时时间为 10 秒r = requests.get('https://httpbin.org/get', timeout=10)print(r.status_code)将连接时间和读取时间分开计算:
r = requests.get('https://httpbin.org/get', timeout=(3, 10))不添加参数,默认不设置超时时间,等同于:
r = requests.get('https://httpbin.org/get', timeout=None)9、身份认证
遇到一些网站需要输入用户名和密码,我们可以通过 auth 参数进行设置。
import requests from requests.auth import HTTPBasicAuth # 用户名为 admin ,密码为 admin r = requests.get('https://xxxxxx/', auth=HTTPBasicAuth('admin', 'admin')) print(r.status_code)简化写法:
import requests
r = requests.get('https://xxxxxx', auth=('admin', 'admin'))print(r.status_code)10、设置代理
如果频繁的访问某个网站时,后期会被一些反爬程序识别,要求输入验证信息,或者其他信息,甚至IP被封无法再次访问,这时候,我们可以通过设置代理来避免这样的问题。
import requests
proxies = { "http": "http://10.10.1.10:3128", "https": "http://10.10.1.10:1080",}
requests.get("http://example.org", proxies=proxies)若你的代理需要使用HTTP Basic Auth,可以使用
http://user:password@host/ 语法:
proxies = { "http": "http://user:pass@10.10.1.10:3128/",}要为某个特定的连接方式或者主机设置代理,使用 scheme://hostname 作为 key, 它会针对指定的主机和连接方式进行匹配。
proxies = {'http://10.20.1.128': 'http://10.10.1.10:5323'}Das obige ist der detaillierte Inhalt vonSo verwenden Sie die Python-Crawler-Requests-Bibliothek. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP ist hauptsächlich prozedurale Programmierung, unterstützt aber auch die objektorientierte Programmierung (OOP). Python unterstützt eine Vielzahl von Paradigmen, einschließlich OOP, funktionaler und prozeduraler Programmierung. PHP ist für die Webentwicklung geeignet, und Python eignet sich für eine Vielzahl von Anwendungen wie Datenanalyse und maschinelles Lernen.
 Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
PHP eignet sich für Webentwicklung und schnelles Prototyping, und Python eignet sich für Datenwissenschaft und maschinelles Lernen. 1.PHP wird für die dynamische Webentwicklung verwendet, mit einfacher Syntax und für schnelle Entwicklung geeignet. 2. Python hat eine kurze Syntax, ist für mehrere Felder geeignet und ein starkes Bibliotheksökosystem.
 Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python eignet sich besser für Anfänger mit einer reibungslosen Lernkurve und einer kurzen Syntax. JavaScript ist für die Front-End-Entwicklung mit einer steilen Lernkurve und einer flexiblen Syntax geeignet. 1. Python-Syntax ist intuitiv und für die Entwicklung von Datenwissenschaften und Back-End-Entwicklung geeignet. 2. JavaScript ist flexibel und in Front-End- und serverseitiger Programmierung weit verbreitet.
 Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
VS -Code kann zum Schreiben von Python verwendet werden und bietet viele Funktionen, die es zu einem idealen Werkzeug für die Entwicklung von Python -Anwendungen machen. Sie ermöglichen es Benutzern: Installation von Python -Erweiterungen, um Funktionen wie Code -Abschluss, Syntax -Hervorhebung und Debugging zu erhalten. Verwenden Sie den Debugger, um Code Schritt für Schritt zu verfolgen, Fehler zu finden und zu beheben. Integrieren Sie Git für die Versionskontrolle. Verwenden Sie Tools für die Codeformatierung, um die Codekonsistenz aufrechtzuerhalten. Verwenden Sie das Lining -Tool, um potenzielle Probleme im Voraus zu erkennen.
 Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
VS -Code -Erweiterungen stellen böswillige Risiken dar, wie das Verstecken von böswilligem Code, das Ausbeutetieren von Schwachstellen und das Masturbieren als legitime Erweiterungen. Zu den Methoden zur Identifizierung böswilliger Erweiterungen gehören: Überprüfung von Verlegern, Lesen von Kommentaren, Überprüfung von Code und Installation mit Vorsicht. Zu den Sicherheitsmaßnahmen gehören auch: Sicherheitsbewusstsein, gute Gewohnheiten, regelmäßige Updates und Antivirensoftware.
 PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP entstand 1994 und wurde von Rasmuslerdorf entwickelt. Es wurde ursprünglich verwendet, um Website-Besucher zu verfolgen und sich nach und nach zu einer serverseitigen Skriptsprache entwickelt und in der Webentwicklung häufig verwendet. Python wurde Ende der 1980er Jahre von Guidovan Rossum entwickelt und erstmals 1991 veröffentlicht. Es betont die Lesbarkeit und Einfachheit der Code und ist für wissenschaftliche Computer, Datenanalysen und andere Bereiche geeignet.
 Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
VS -Code kann unter Windows 8 ausgeführt werden, aber die Erfahrung ist möglicherweise nicht großartig. Stellen Sie zunächst sicher, dass das System auf den neuesten Patch aktualisiert wurde, und laden Sie dann das VS -Code -Installationspaket herunter, das der Systemarchitektur entspricht und sie wie aufgefordert installiert. Beachten Sie nach der Installation, dass einige Erweiterungen möglicherweise mit Windows 8 nicht kompatibel sind und nach alternativen Erweiterungen suchen oder neuere Windows -Systeme in einer virtuellen Maschine verwenden müssen. Installieren Sie die erforderlichen Erweiterungen, um zu überprüfen, ob sie ordnungsgemäß funktionieren. Obwohl VS -Code unter Windows 8 möglich ist, wird empfohlen, auf ein neueres Windows -System zu upgraden, um eine bessere Entwicklungserfahrung und Sicherheit zu erzielen.
 So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
Im VS -Code können Sie das Programm im Terminal in den folgenden Schritten ausführen: Erstellen Sie den Code und öffnen Sie das integrierte Terminal, um sicherzustellen, dass das Codeverzeichnis mit dem Terminal Working -Verzeichnis übereinstimmt. Wählen Sie den Befehl aus, den Befehl ausführen, gemäß der Programmiersprache (z. B. Pythons Python your_file_name.py), um zu überprüfen, ob er erfolgreich ausgeführt wird, und Fehler auflösen. Verwenden Sie den Debugger, um die Debugging -Effizienz zu verbessern.
