
 Technologie-Peripheriegeräte
KI
Ein Artikel zum Verständnis von Computer Vision, voller nützlicher Informationen
Technologie-Peripheriegeräte
KI
Ein Artikel zum Verständnis von Computer Vision, voller nützlicher Informationen
Ein Artikel zum Verständnis von Computer Vision, voller nützlicher Informationen

1. Vorwort
Computer Vision (Computer Vision), üblicherweise als CV bezeichnet, ist ein Forschungsgebiet, das Technologie nutzt, um Computern dabei zu helfen, Bilder zu „sehen“ und zu „verstehen“, beispielsweise beim Erstellen Computer verstehen den Inhalt des Fotos oder Videos.
Dieser Artikel bietet eine allgemeine Einführung in Computer Vision. Dieser Artikel ist in sechs Teile unterteilt:
- Warum Computer Vision wichtig ist
- Was ist Computer Vision
- Computer Vision Die Grundprinzipien von
- Typische Aufgaben von Computer Vision
- Anwendungsszenarien von Computer Vision im täglichen Leben
- Herausforderungen von Computer Vision
2. Warum ist Computer Vision wichtig? Die Informationen werden verarbeitet und geformt. Wir Menschen nutzen das Sehen, um intuitiv die Form und den Zustand der Dinge vor uns zu verstehen. Die meisten von uns verlassen sich auf das Sehen, um das Kochen abzuschließen, Hindernisse zu überwinden, Straßenschilder zu lesen, Videos anzusehen und unzählige andere Aufgaben. Gäbe es da nicht besondere Gruppen wie Blinde, nimmt die überwiegende Mehrheit der Menschen äußere Informationen durch das Sehen auf, und dieser Anteil liegt sogar bei 80 % – dieser Anteil ist nicht unbegründet, so der berühmte Experimentalpsychologe Treicher Durch zahlreiche Experimente wurde bestätigt, dass 83 % der Informationen, die Menschen erhalten, durch Sehen, 11 % durch Hören und die restlichen 6 % durch Geruch, Berührung und Geschmack entstehen. Daher ist das Sehen für den Menschen zweifellos der wichtigste Sinn.
Nicht nur der Mensch ist ein „Sehtier“, sondern für die meisten Tiere spielt auch das Sehen eine sehr wichtige Rolle. Durch das Sehen nehmen Menschen und Tiere die Größe, das Licht und den Schatten, die Farbe und die Bewegung äußerer Objekte wahr und erhalten verschiedene Informationen, die für das Überleben des Körpers wichtig sind. Durch diese Informationen können sie lernen, wie die Welt um sie herum aussieht wie man mit der Welt interagiert.
 Vor dem Aufkommen von Computer Vision befanden sich Bilder für Computer in einem Black-Box-Zustand. Für einen Computer ist ein Bild nur eine Datei oder eine Datenfolge. Der Computer kennt den Inhalt des Bildes nicht, er weiß nur, wie groß das Bild ist, wie viel Speicher es belegt, in welchem Format es vorliegt usw.
Vor dem Aufkommen von Computer Vision befanden sich Bilder für Computer in einem Black-Box-Zustand. Für einen Computer ist ein Bild nur eine Datei oder eine Datenfolge. Der Computer kennt den Inhalt des Bildes nicht, er weiß nur, wie groß das Bild ist, wie viel Speicher es belegt, in welchem Format es vorliegt usw.
 Wenn Computer und künstliche Intelligenz in der realen Welt eine wichtige Rolle spielen wollen, müssen sie Bilder verstehen! Daher versuchen Informatiker seit einem halben Jahrhundert herauszufinden, wie man Computer zum Sehen bringt, und haben so das Gebiet der „Computer Vision“ hervorgebracht.
Wenn Computer und künstliche Intelligenz in der realen Welt eine wichtige Rolle spielen wollen, müssen sie Bilder verstehen! Daher versuchen Informatiker seit einem halben Jahrhundert herauszufinden, wie man Computer zum Sehen bringt, und haben so das Gebiet der „Computer Vision“ hervorgebracht.
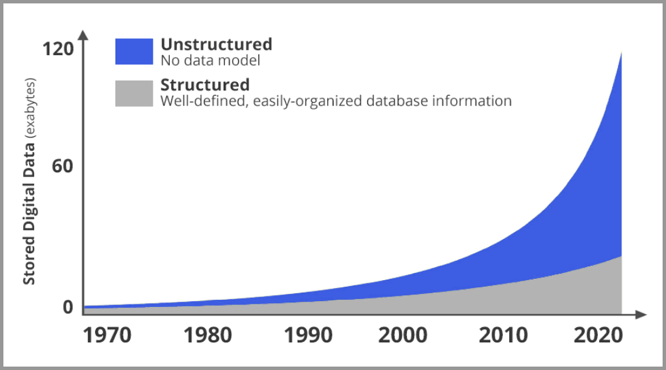
 Durch die rasante Entwicklung des Internets ist auch Computer Vision besonders wichtig geworden. Die folgende Abbildung ist ein Trenddiagramm der Menge neuer Daten im Netzwerk seit 2020. Graue Grafiken sind strukturierte Daten, blaue Grafiken sind unstrukturierte Daten (hauptsächlich Bilder und Videos). Es ist offensichtlich, dass die Anzahl der Bilder und Videos exponentiell wächst.
Durch die rasante Entwicklung des Internets ist auch Computer Vision besonders wichtig geworden. Die folgende Abbildung ist ein Trenddiagramm der Menge neuer Daten im Netzwerk seit 2020. Graue Grafiken sind strukturierte Daten, blaue Grafiken sind unstrukturierte Daten (hauptsächlich Bilder und Videos). Es ist offensichtlich, dass die Anzahl der Bilder und Videos exponentiell wächst.
 Das Internet besteht aus Text und Bildern. Die Suche nach Text ist relativ einfach, aber um nach Bildern zu suchen, muss der Algorithmus wissen, was das Bild enthält. Lange Zeit verfügten Menschen nicht über genügend Technologie, um den Inhalt von Bildern und Videos zu verstehen, und konnten sich nur auf manuelle Anmerkungen verlassen, um Beschreibungen von Bildern oder Videos zu erhalten. Wie Computer in die Lage versetzt werden können, diese Bildinformationen besser zu verstehen, ist eine große Herausforderung für die heutige Computertechnologie. Um Bild- oder Videodaten optimal nutzen zu können, müssen Sie dem Computer ermöglichen, das Bild oder Video zu „sehen“ und den Inhalt zu verstehen.
Das Internet besteht aus Text und Bildern. Die Suche nach Text ist relativ einfach, aber um nach Bildern zu suchen, muss der Algorithmus wissen, was das Bild enthält. Lange Zeit verfügten Menschen nicht über genügend Technologie, um den Inhalt von Bildern und Videos zu verstehen, und konnten sich nur auf manuelle Anmerkungen verlassen, um Beschreibungen von Bildern oder Videos zu erhalten. Wie Computer in die Lage versetzt werden können, diese Bildinformationen besser zu verstehen, ist eine große Herausforderung für die heutige Computertechnologie. Um Bild- oder Videodaten optimal nutzen zu können, müssen Sie dem Computer ermöglichen, das Bild oder Video zu „sehen“ und den Inhalt zu verstehen.
3. Was ist Computer Vision?
Computer Vision ist ein wichtiger Zweig im Bereich der künstlichen Intelligenz. Das Problem besteht darin, Computern den Inhalt von Bildern oder Videos verstehen zu lassen. Zum Beispiel: Ist das Haustier auf dem Bild eine Katze oder ein Hund? Ist die Person auf dem Bild Lao Zhang oder Lao Wang? Was machen die Personen im Video? Darüber hinaus bezieht sich Computer Vision auf die Verwendung von Kameras und Computern anstelle des menschlichen Auges, um Ziele zu identifizieren, zu verfolgen und zu messen und die weitere Grafikverarbeitung durchzuführen, um Bilder zu erhalten, die besser für die Beobachtung mit dem menschlichen Auge oder die Übertragung an Instrumente zur Erkennung geeignet sind. Als wissenschaftliche Disziplin untersucht Computer Vision verwandte Theorien und Technologien und versucht, Systeme der künstlichen Intelligenz aufzubauen, die aus Bildern oder mehrdimensionalen Daten Informationen auf hoher Ebene gewinnen können. Aus technischer Sicht zielt es darauf ab, automatisierte Systeme zu nutzen, um das menschliche visuelle System zur Erledigung von Aufgaben nachzuahmen. Das ultimative Ziel von Computer Vision besteht darin, Computern die Möglichkeit zu geben, die Welt durch Sehen zu beobachten und zu verstehen, wie es Menschen tun, und die Fähigkeit zu haben, sich autonom an die Umgebung anzupassen. Aber es ist sehr schwierig, wirklich zu erkennen, dass ein Computer die Welt durch eine Kamera wahrnehmen kann, denn obwohl die von der Kamera aufgenommenen Bilder die gleichen sind wie das, was wir normalerweise sehen, ist jedes Bild für den Computer nur eine Anordnung und Kombination von Pixeln Werte. Ein Haufen starrer Zahlen. Wie es Computern ermöglicht wird, aus diesen starren Zahlen aussagekräftige visuelle Hinweise zu lesen, ist ein Problem, das durch Computer Vision gelöst werden sollte.
4. Grundprinzipien des Computer-Sehens
Jeder, der eine Kamera oder ein Mobiltelefon verwendet hat, weiß, dass Computer gut darin sind, Fotos mit erstaunlicher Genauigkeit und Details aufzunehmen. In gewissem Maße ist das künstliche „Sehen“ von Computern besser Die Sehfähigkeit des Menschen ist von Geburt an viel stärker. Aber so wie wir normalerweise sagen: „Hören bedeutet nicht Verstehen“, bedeutet „Sehen“ nicht „Verstehen“. Wenn Sie möchten, dass ein Computer Bilder wirklich „versteht“, ist das keine einfache Sache. Ein Bild ist ein großes Pixelraster, und jedes Pixel hat eine Farbe, die eine Kombination aus drei Primärfarben ist: Rot, Grün und Blau. Durch die Kombination der Intensitäten von drei Farben – sogenannte RGB-Werte – können wir jede beliebige Farbe erhalten. Der einfachste und am besten geeignete Computer-Vision-Algorithmus für den Einstieg ist: Um ein farbiges Objekt, beispielsweise einen rosa Ball, zu verfolgen, notieren wir zunächst die Farbe des Balls, speichern den RGB-Wert des mittleren Pixels und geben das Bild dann an den program , sodass das Programm das Pixel finden kann, das dieser Farbe am nächsten kommt. Der Algorithmus kann in der oberen linken Ecke beginnen, jedes Pixel untersuchen und den Unterschied zur Zielfarbe berechnen. Nachdem jedes Pixel überprüft wurde, ist der nächstgelegene Teil der Pixel wahrscheinlich das Pixel, in dem sich der Ball befindet. Dieser Algorithmus ist nicht auf die Ausführung auf diesem einzelnen Bild beschränkt, wir können den Algorithmus auch auf jedem Bild des Videos ausführen, um die Position des Balls zu verfolgen. Natürlich wird sich die Farbe des Balls aufgrund des Einflusses von Licht, Schatten und anderen Faktoren ändern. Sie entspricht nicht genau dem von uns gespeicherten RGB-Wert, kommt aber sehr nahe. In einigen extremen Fällen, beispielsweise bei einem Fußballspiel in der Nacht, kann der Tracking-Effekt jedoch sehr schlecht sein, und wenn eines der Trikots die gleiche Farbe wie der Ball hat, gerät der Algorithmus völlig in Ohnmacht. Sofern die Umgebung nicht streng kontrolliert werden kann, werden solche Farbverfolgungsalgorithmen daher selten in die Praxis umgesetzt. Heutzutage umfassen immer mehr Computer-Vision-Algorithmen im Allgemeinen „Deep Learning“-Methoden und -Technologien. Unter ihnen ist das Convolutional Neural Network (CNN) aufgrund seiner überlegenen Leistung am weitesten verbreitet. Da das Wissen, das mit „Deep Learning“ verbunden ist, zu umfangreich ist, wird in diesem Artikel nicht näher darauf eingegangen. Wenn Sie mehr über „Deep Learning“ erfahren möchten, können Sie sich auch den Einführungskurs zur KI ansehen – „Intel® OpenVINO™ Tool Suite Elementary Course“. Es beginnt mit den Grundkonzepten der KI, führt in relevantes Wissen über künstliche Intelligenz und Bildverarbeitungsanwendungen ein und hilft Benutzern, die Grundkonzepte und Anwendungsszenarien der Intel® OpenVINO™-Tool-Suite schnell zu verstehen. Der gesamte Kurs umfasst Videoverarbeitung, Kenntnisse im Zusammenhang mit Deep Learning, Inferenzbeschleunigung für Anwendungen der künstlichen Intelligenz und Demo-Demonstrationen der Intel® OpenVINO™-Tool-Suite. Er führt Sie Schritt für Schritt durch die Beherrschung von Deep Learning von der oberflächlichen zur tieferen Ebene.
5. Typische Aufgaben der Computer Vision
- Die Bildklassifizierung besteht darin, verschiedene Kategorien von Bildern anhand ihrer semantischen Informationen zu unterscheiden. Sie ist der Kern der Computer Vision und dient der Objekterkennung, Bildsegmentierung und Objektverfolgung sowie Verhaltensanalyse, Gesichtserkennung und andere anspruchsvolle visuelle Aufgaben. Im Bild unten erkennt der Computer beispielsweise durch Bildklassifizierung Personen, Bäume, Gras und Himmel im Bild.
Die Bildklassifizierung wird in vielen Bereichen häufig verwendet, beispielsweise bei der Gesichtserkennung und intelligenten Videoanalyse im Sicherheitsbereich, bei der Erkennung von Verkehrsszenen im Transportbereich, bei der inhaltsbasierten Bildabfrage und bei der automatischen Klassifizierung von Fotoalben im Internet Bereich, Bilderkennung im medizinischen Bereich usw. 
- Objekterkennung
Das Ziel der Objekterkennungsaufgabe besteht darin, ein Bild oder einen Videorahmen zu erstellen und den Computer die Positionen aller darin enthaltenen Objekte ermitteln zu lassen und Geben Sie für jedes Ziel spezifische Kategorien an. Wie in der folgenden Abbildung dargestellt, werden am Beispiel der Erkennung und Erkennung von Personen die Ränder verwendet, um die Positionen aller Personen im Bild zu markieren.

Bei der Zielerkennung mit mehreren Kategorien werden im Allgemeinen Rahmen unterschiedlicher Farbe verwendet, um die Positionen verschiedener erkannter Objekte zu markieren, wie in der Abbildung unten dargestellt.

- Semantische Segmentierung
Semantische Segmentierung ist eine grundlegende Aufgabe in der Computer Vision Wir müssen den visuellen Input in verschiedene semantisch interpretierbare Kategorien unterteilen. Es unterteilt das gesamte Bild in Pixelgruppen, die dann beschriftet und klassifiziert werden. Beispielsweise müssen wir möglicherweise alle Pixel in einem Bild unterscheiden, die zu Autos gehören, und diese Pixel blau einfärben. Wie unten gezeigt, ist das Bild in die Beschriftungen „Personen“ (rot), „Bäume“ (dunkelgrün), „Gras“ (hellgrün) und „Himmel“ (blau) unterteilt.
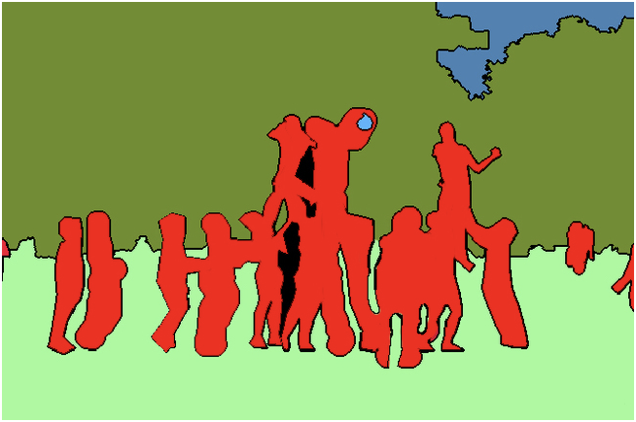
Instanzsegmentierung ist eine Kombination aus Zielerkennung und semantischer Segmentierung. Das Ziel wird im Bild erkannt (Zielerkennung) und dann jedes Pixel ist Etikettierung (semantische Segmentierung). Wenn wir die Abbildungen oben und unten vergleichen, können wir sehen, dass bei der Verwendung menschlicher Ziele die semantische Segmentierung nicht zwischen verschiedenen Instanzen derselben Kategorie unterscheidet (alle Personen sind rot markiert), während die Instanzsegmentierung verschiedene Instanzen derselben Kategorie unterscheidet (verschieden). Farben werden verwendet, um verschiedene Menschen zu unterscheiden).

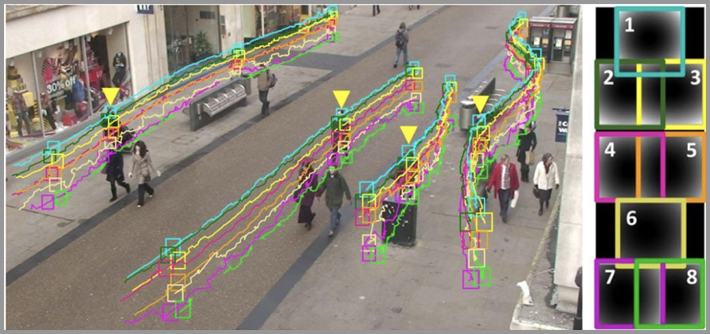
Zielverfolgung bezieht sich auf das Erkennen, Extrahieren, Identifizieren und Verfolgen bewegter Ziele in Bildsequenzen, das Erhalten der Bewegungsparameter der sich bewegenden Ziele und die Durchführung Verarbeitung und Analyse zur Erlangung eines Verhaltensverständnisses bei sich bewegenden Zielen zur Erledigung übergeordneter Erkennungsaufgaben.
6. Anwendungsszenarien von Computer Vision im täglichen Leben
Die Anwendungsszenarien von Computer Vision sind sehr breit, hier sind ein paar Ein häufiges Anwendungsszenario im Leben. ·Gesichtserkennung bei Zugangskontrolle und Alipay

- Kennzeichenerkennung auf Parkplätzen und Mautstationen

- Risikoerkennung beim Hochladen von Videos auf Websites oder APPs
 #🎜 🎜#
#🎜 🎜#
#🎜 🎜# 7. Herausforderungen für Computer Vision
Das obige ist der detaillierte Inhalt vonEin Artikel zum Verständnis von Computer Vision, voller nützlicher Informationen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Die CSRankings National Computer Science Rankings 2024 sind veröffentlicht! CMU dominiert die Liste, MIT fällt aus den Top 5
Mar 25, 2024 pm 06:01 PM
Die CSRankings National Computer Science Rankings 2024 sind veröffentlicht! CMU dominiert die Liste, MIT fällt aus den Top 5
Mar 25, 2024 pm 06:01 PM
Die 2024CSRankings National Computer Science Major Rankings wurden gerade veröffentlicht! In diesem Jahr gehört die Carnegie Mellon University (CMU) im Ranking der besten CS-Universitäten in den Vereinigten Staaten zu den Besten des Landes und im Bereich CS, während die University of Illinois at Urbana-Champaign (UIUC) einen der besten Plätze belegt sechs Jahre in Folge den zweiten Platz belegt. Georgia Tech belegte den dritten Platz. Dann teilten sich die Stanford University, die University of California in San Diego, die University of Michigan und die University of Washington den vierten Platz weltweit. Es ist erwähnenswert, dass das Ranking des MIT zurückgegangen ist und aus den Top 5 herausgefallen ist. CSRankings ist ein globales Hochschulrankingprojekt im Bereich Informatik, das von Professor Emery Berger von der School of Computer and Information Sciences der University of Massachusetts Amherst initiiert wurde. Die Rangfolge erfolgt objektiv
 Remotedesktop kann die Identität des Remotecomputers nicht authentifizieren
Feb 29, 2024 pm 12:30 PM
Remotedesktop kann die Identität des Remotecomputers nicht authentifizieren
Feb 29, 2024 pm 12:30 PM
Mit dem Windows-Remotedesktopdienst können Benutzer aus der Ferne auf Computer zugreifen, was für Personen, die aus der Ferne arbeiten müssen, sehr praktisch ist. Es können jedoch Probleme auftreten, wenn Benutzer keine Verbindung zum Remotecomputer herstellen können oder Remotedesktop die Identität des Computers nicht authentifizieren kann. Dies kann durch Netzwerkverbindungsprobleme oder einen Fehler bei der Zertifikatsüberprüfung verursacht werden. In diesem Fall muss der Benutzer möglicherweise die Netzwerkverbindung überprüfen, sicherstellen, dass der Remote-Computer online ist, und versuchen, die Verbindung wiederherzustellen. Außerdem ist es wichtig, sicherzustellen, dass die Authentifizierungsoptionen des Remotecomputers richtig konfiguriert sind, um das Problem zu lösen. Solche Probleme mit den Windows-Remotedesktopdiensten können normalerweise durch sorgfältiges Überprüfen und Anpassen der Einstellungen behoben werden. Aufgrund eines Zeit- oder Datumsunterschieds kann Remote Desktop die Identität des Remotecomputers nicht überprüfen. Bitte stellen Sie Ihre Berechnungen sicher
 Das Gruppenrichtlinienobjekt kann auf diesem Computer nicht geöffnet werden
Feb 07, 2024 pm 02:00 PM
Das Gruppenrichtlinienobjekt kann auf diesem Computer nicht geöffnet werden
Feb 07, 2024 pm 02:00 PM
Gelegentlich kann es bei der Verwendung eines Computers zu Fehlfunktionen des Betriebssystems kommen. Das Problem, auf das ich heute gestoßen bin, bestand darin, dass das System beim Zugriff auf gpedit.msc mitteilte, dass das Gruppenrichtlinienobjekt nicht geöffnet werden könne, weil möglicherweise die richtigen Berechtigungen fehlten. Das Gruppenrichtlinienobjekt auf diesem Computer konnte nicht geöffnet werden: 1. Beim Zugriff auf gpedit.msc meldet das System, dass das Gruppenrichtlinienobjekt auf diesem Computer aufgrund fehlender Berechtigungen nicht geöffnet werden kann. Details: Das System kann den angegebenen Pfad nicht finden. 2. Nachdem der Benutzer auf die Schaltfläche „Schließen“ geklickt hat, wird das folgende Fehlerfenster angezeigt. 3. Überprüfen Sie sofort die Protokolleinträge und kombinieren Sie die aufgezeichneten Informationen, um festzustellen, dass das Problem in der Datei C:\Windows\System32\GroupPolicy\Machine\registry.pol liegt
 Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Der Artikel von StableDiffusion3 ist endlich da! Dieses Modell wurde vor zwei Wochen veröffentlicht und verwendet die gleiche DiT-Architektur (DiffusionTransformer) wie Sora. Nach seiner Veröffentlichung sorgte es für großes Aufsehen. Im Vergleich zur Vorgängerversion wurde die Qualität der von StableDiffusion3 generierten Bilder erheblich verbessert. Es unterstützt jetzt Eingabeaufforderungen mit mehreren Themen, und der Textschreibeffekt wurde ebenfalls verbessert, und es werden keine verstümmelten Zeichen mehr angezeigt. StabilityAI wies darauf hin, dass es sich bei StableDiffusion3 um eine Reihe von Modellen mit Parametergrößen von 800 M bis 8 B handelt. Durch diesen Parameterbereich kann das Modell direkt auf vielen tragbaren Geräten ausgeführt werden, wodurch der Einsatz von KI deutlich reduziert wird
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
In diesem Artikel wird das Problem der genauen Erkennung von Objekten aus verschiedenen Blickwinkeln (z. B. Perspektive und Vogelperspektive) beim autonomen Fahren untersucht, insbesondere wie die Transformation von Merkmalen aus der Perspektive (PV) in den Raum aus der Vogelperspektive (BEV) effektiv ist implementiert über das Modul Visual Transformation (VT). Bestehende Methoden lassen sich grob in zwei Strategien unterteilen: 2D-zu-3D- und 3D-zu-2D-Konvertierung. 2D-zu-3D-Methoden verbessern dichte 2D-Merkmale durch die Vorhersage von Tiefenwahrscheinlichkeiten, aber die inhärente Unsicherheit von Tiefenvorhersagen, insbesondere in entfernten Regionen, kann zu Ungenauigkeiten führen. Während 3D-zu-2D-Methoden normalerweise 3D-Abfragen verwenden, um 2D-Features abzutasten und die Aufmerksamkeitsgewichte der Korrespondenz zwischen 3D- und 2D-Features über einen Transformer zu lernen, erhöht sich die Rechen- und Bereitstellungszeit.
 Daten können nicht vom Remote-Desktop auf den lokalen Computer kopiert werden
Feb 19, 2024 pm 04:12 PM
Daten können nicht vom Remote-Desktop auf den lokalen Computer kopiert werden
Feb 19, 2024 pm 04:12 PM
Wenn Sie Probleme beim Kopieren von Daten von einem Remote-Desktop auf Ihren lokalen Computer haben, kann Ihnen dieser Artikel bei der Lösung helfen. Mithilfe der Remote-Desktop-Technologie können mehrere Benutzer auf virtuelle Desktops auf einem zentralen Server zugreifen und so Datenschutz und Anwendungsverwaltung gewährleisten. Dies trägt zur Gewährleistung der Datensicherheit bei und ermöglicht es Unternehmen, ihre Anwendungen effizienter zu verwalten. Benutzer können bei der Verwendung des Remote-Desktops auf Herausforderungen stoßen. Eine davon ist die Unfähigkeit, Daten vom Remote-Desktop auf den lokalen Computer zu kopieren. Dies kann durch verschiedene Faktoren verursacht werden. Daher bietet dieser Artikel Hinweise zur Lösung dieses Problems. Warum kann ich nicht vom Remote-Desktop auf meinen lokalen Computer kopieren? Wenn Sie eine Datei auf Ihren Computer kopieren, wird sie vorübergehend an einem Ort namens Zwischenablage gespeichert. Wenn Sie diese Methode nicht zum Kopieren von Daten vom Remote-Desktop auf Ihren lokalen Computer verwenden können
 „Minecraft' verwandelt sich in eine KI-Stadt und NPC-Bewohner spielen Rollenspiele wie echte Menschen
Jan 02, 2024 pm 06:25 PM
„Minecraft' verwandelt sich in eine KI-Stadt und NPC-Bewohner spielen Rollenspiele wie echte Menschen
Jan 02, 2024 pm 06:25 PM
Bitte beachten Sie, dass dieser kantige Mann die Stirn runzelt und über die Identität der „ungebetenen Gäste“ vor ihm nachdenkt. Es stellte sich heraus, dass sie sich in einer gefährlichen Situation befand, und als ihr dies klar wurde, begann sie schnell mit der mentalen Suche nach einer Strategie zur Lösung des Problems. Letztendlich entschloss sie sich, vom Unfallort zu fliehen, dann so schnell wie möglich Hilfe zu suchen und sofort Maßnahmen zu ergreifen. Gleichzeitig dachte die Person auf der Gegenseite das Gleiche wie sie... In „Minecraft“ gab es eine solche Szene, in der alle Charaktere von künstlicher Intelligenz gesteuert wurden. Jeder von ihnen hat eine einzigartige Identität. Das zuvor erwähnte Mädchen ist beispielsweise eine 17-jährige, aber kluge und mutige Kurierin. Sie haben die Fähigkeit, sich zu erinnern und zu denken und in dieser kleinen Stadt in Minecraft wie Menschen zu leben. Was sie antreibt, ist ein brandneues,
