
 Technologie-Peripheriegeräte
KI
Die KI-Prüfung und die öffentliche Prüfung stehen vor der Tür! Das chinesische Team von Microsoft veröffentlicht den neuen Benchmark AGIEval, der speziell für Untersuchungen am Menschen entwickelt wurde
Technologie-Peripheriegeräte
KI
Die KI-Prüfung und die öffentliche Prüfung stehen vor der Tür! Das chinesische Team von Microsoft veröffentlicht den neuen Benchmark AGIEval, der speziell für Untersuchungen am Menschen entwickelt wurde
Die KI-Prüfung und die öffentliche Prüfung stehen vor der Tür! Das chinesische Team von Microsoft veröffentlicht den neuen Benchmark AGIEval, der speziell für Untersuchungen am Menschen entwickelt wurde

Da Sprachmodelle immer leistungsfähiger werden, sind diese vorhandenen Bewertungsmaßstäbe wirklich etwas kindisch und die Leistung einiger Aufgaben liegt weit hinter der Leistung von Menschen zurück.
Ein wichtiges Merkmal der künstlichen allgemeinen Intelligenz (AGI) ist die Generalisierungsfähigkeit des Modells zur Bewältigung von Aufgaben auf menschlicher Ebene, während herkömmliche Benchmarks, die auf künstlichen Datensätzen basieren, menschliche Fähigkeiten nicht genau wiedergeben.
Kürzlich haben Microsoft-Forscher einen neuen Benchmark AGIEval veröffentlicht, der speziell zur Bewertung grundlegender Modelle in „menschenzentrierten“ standardisierten Prüfungen verwendet wird, wie z. B. Aufnahmeprüfungen für Hochschulen, Prüfungen für den öffentlichen Dienst und Prüfungsleistungen für die Zulassung zu juristischen Fakultäten , Mathematikwettbewerbe und Anwaltsprüfungen.

Paper Link: https://arxiv.org/pdf/2304.06364.pdf
data Link: https://github.com/microsoft/agieval
Forscher verwendeten den AGIEval-Benchmark, um drei hochmoderne Basismodelle zu bewerten, darunter GPT-4, ChatGPT und Text-Davinci-003. Die experimentellen Ergebnisse ergaben, dass GPT-4 den menschlichen Durchschnitt bei SAT, LSAT, übertraf. und Mathematikwettbewerben erreichte die Genauigkeitsrate des SAT-Mathematiktests 95 % und die Genauigkeitsrate des China College Entrance Examination English-Tests erreichte 92,5 %, was auf die außergewöhnliche Leistung des aktuellen Basismodells hinweist.
Aber GPT-4 ist weniger kompetent bei Aufgaben, die komplexes Denken oder domänenspezifisches Wissen erfordern. Eine umfassende Analyse der Modellfähigkeiten (Verstehen, Wissen, Denken und Berechnen) im Artikel zeigt die Stärken und Grenzen dieser auf Modelle.
AGIEval-Datensatz
In den letzten Jahren haben groß angelegte Basismodelle wie GPT-4 in verschiedenen Bereichen sehr leistungsstarke Fähigkeiten gezeigt. Sie können Menschen bei der Bewältigung alltäglicher Ereignisse unterstützen und sogar Dienste in beruflichen Bereichen wie z B. Recht, Medizin und Finanzen. Entscheidungsberatung.
Mit anderen Worten: Künstliche Intelligenzsysteme nähern sich allmählich der künstlichen allgemeinen Intelligenz (AGI) und erreichen diese.
Aber wie kann man mit der allmählichen Integration der KI in das tägliche Leben die menschenzentrierte Generalisierungsfähigkeit von Modellen bewerten, potenzielle Fehler identifizieren und sicherstellen, dass sie komplexe, menschenzentrierte Aufgaben effektiv bewältigen können, und die Argumentationsfähigkeiten bewerten, um dies sicherzustellen? Sie können in verschiedenen Umgebungen eingesetzt werden. Zuverlässigkeit und Vertrauenswürdigkeit sind entscheidend.
Die Forscher erstellten den AGIEval-Datensatz hauptsächlich nach zwei Designprinzipien:
1. Schwerpunkt auf kognitiven Aufgaben auf menschlicher Gehirnebene
Das Hauptziel des „menschenzentrierten“ Designs Die Interaktion mit Menschen konzentriert sich auf Aufgaben, die eng mit Erkenntnis und Problemlösung verbunden sind, und bewertet die Generalisierungsfähigkeit des zugrunde liegenden Modells auf aussagekräftigere und umfassendere Weise.
Um dieses Ziel zu erreichen, wählten die Forscher eine Vielzahl offizieller, öffentlicher Zulassungs- und Eignungstests mit hohem Standard aus, um den Bedürfnissen allgemeiner menschlicher Testteilnehmer gerecht zu werden, darunter Aufnahmeprüfungen für Hochschulen, Aufnahmeprüfungen für juristische Fakultäten, Mathematikprüfungen usw Die Anwaltsprüfung und die Staatsprüfung für den öffentlichen Dienst werden jedes Jahr von Millionen Menschen abgelegt, die eine höhere Ausbildung anstreben oder einen neuen Berufsweg einschlagen möchten.
Durch die Einhaltung dieser offiziell anerkannten Standards zur Bewertung menschlicher Fähigkeiten stellt AGIEval sicher, dass Bewertungen der Modellleistung in direktem Zusammenhang mit der menschlichen Entscheidungsfindung und den kognitiven Fähigkeiten stehen.
2. Relevanz für reale Szenarien
Durch die Auswahl von Aufgaben aus anspruchsvollen Aufnahme- und Eignungsprüfungen können Sie sicherstellen, dass die Bewertungsergebnisse das widerspiegeln, was Einzelpersonen in verschiedenen Bereichen und Kontexten häufig antreffen die Komplexität und Praktikabilität der Herausforderungen.
Diese Methode kann nicht nur die Leistung des Modells im Hinblick auf die kognitiven Fähigkeiten des Menschen messen, sondern auch ein besseres Verständnis der Anwendbarkeit und Wirksamkeit im wirklichen Leben liefern, das heißt, sie kann dabei helfen, zuverlässigere, praktischere, und effektive Modelle künstlicher Intelligenz, die zur Lösung einer Vielzahl realer Probleme geeignet sind.
Basierend auf den oben genannten Gestaltungsprinzipien wählten die Forscher eine Reihe standardisierter, qualitativ hochwertiger Prüfungen aus, bei denen das menschliche Denken und die Relevanz für die Praxis im Vordergrund stehen, darunter:
1. Allgemeine Hochschulzulassungen PRÜFUNG
Die Hochschulaufnahmeprüfung deckt eine Vielzahl von Fächern ab, die kritisches Denken, Problemlösungs- und Analysefähigkeiten erfordern und ist ideal für die Beurteilung der Leistung großer Sprachmodelle in Bezug auf die menschliche Kognition.
Umfasst insbesondere die Graduate Record Examination (GRE), den Academic Assessment Test (SAT) und die China College Entrance Examination (Gaokao), mit denen die allgemeinen Fähigkeiten und fachspezifischen Kenntnisse von Studierenden beurteilt werden können, die eine Zulassung zu Hochschuleinrichtungen anstreben.
Der Datensatz sammelt Prüfungen, die 8 Fächern der chinesischen Hochschulaufnahmeprüfung entsprechen: Geschichte, Mathematik, Englisch, Chinesisch, Geographie, Biologie, Chemie und Physik; ausgewählte Mathematikfragen von GRE; ausgewählte Englisch- und Mathematikfächer von SAT Build ein Benchmark-Datensatz.
2. Zulassungstest für juristische Fakultäten
Der Zulassungstest für juristische Fakultäten ist darauf ausgelegt, die Argumentations- und Analysefähigkeiten angehender Jurastudenten zu messen. Der Testinhalt umfasst logisches Denken und Leseverständnis und analytisches Denken. Diese Aufgaben bewerten die Fähigkeit von Sprachmodellen zum juristischen Denken und Analysieren.
3. Die Anwaltsprüfung
bewertet die juristischen Kenntnisse, analytischen Fähigkeiten und das ethische Verständnis von Personen, die eine juristische Laufbahn anstreben, und deckt ein breites Spektrum juristischer Themen ab, darunter Verfassungsrecht, Vertragsrecht und Strafrecht Recht und Eigentumsrecht und verlangt von den Kandidaten den Nachweis ihrer Fähigkeit, Rechtsgrundsätze und Argumentation effektiv anzuwenden. Die Leistung im Sprachmodell kann im Kontext juristischer Fachkenntnisse und moralischen Urteilsvermögens beurteilt werden.
4. Graduate Management Admission Test (GMAT)
GMAT ist ein standardisierter Test, der die analytischen, quantitativen, verbalen und integrierten Denkfähigkeiten angehender Business School-Absolventen bewertet, die durch analytisches Schreiben beurteilt werden , umfassendes Denken, quantitatives Denken und verbales Denken usw., um die Fähigkeit des Kandidaten zu beurteilen, kritisch zu denken, Daten zu analysieren und effektiv zu kommunizieren. 5. Mathematik-Wettbewerbe für weiterführende Schulen .
Dazu gehören insbesondere der American Mathematics Competition (AMC) und die American Invitational Mathematics Examination (AIME), mit denen die mathematischen Fähigkeiten, die Kreativität und die Problemlösungsfähigkeit der Schüler getestet und die Fähigkeit des Sprachmodells, mit komplexen und komplexen Problemen umzugehen, weiter bewertet werden können kreative mathematische Probleme und die Fähigkeit des Modells, neuartige Lösungen zu generieren.
6. Die inländische Beamtenprüfung
kann die Fähigkeiten und Fertigkeiten von Personen beurteilen, die den Eintritt in den öffentlichen Dienst anstreben. und verschiedene Positionen im öffentlichen Dienst in China. Fachspezifisches Fachwissen über Rollen und Verantwortlichkeiten, mit denen die Leistung von Sprachmodellen in Kontexten der öffentlichen Verwaltung und ihr Potenzial für die Politikentwicklung, Entscheidungsfindung und Prozesse zur Erbringung öffentlicher Dienstleistungen gemessen werden können.
BewertungsergebnisseZu den ausgewählten Modellen gehören:
ChatGPT, ein von OpenAI entwickeltes Konversationsmodell für künstliche Intelligenz, das an Benutzerinteraktionen und dynamischen Dialogen teilnehmen kann, mithilfe eines riesigen Befehlsdatensatzes trainiert wurde und die Verstärkung bestanden hat Lernen mit menschlichem Feedback (RLHF) optimiert es weiter, um kontextrelevante und kohärente Antworten zu liefern, die den menschlichen Erwartungen entsprechen.
GPT-4 enthält als GPT-Modell der vierten Generation eine breitere Wissensbasis und zeigt in vielen Anwendungsszenarien eine Leistung auf menschlicher Ebene. GPT-4 wurde mithilfe von Adversarial Testing und ChatGPT wiederholt optimiert, was zu erheblichen Verbesserungen bei der Faktizität, der Bootfähigkeit und der Einhaltung der Regeln führte.
Text-Davinci-003 ist eine Zwischenversion zwischen GPT-3 und GPT-4 Version, das nach der Feinabstimmung der Anweisungen eine bessere Leistung als GPT-3 erbringt.
Darüber hinaus wurden im Experiment auch die durchschnittliche Punktzahl und die höchste Punktzahl menschlicher Testteilnehmer angegeben, die als menschliche Grenzwerte für jede Aufgabe dienen, aber es sind nicht vollständig repräsentativ für die Bandbreite der Fähigkeiten und Kenntnisse, die ein Mensch besitzen kann.
Zero-Shot/Wenige-Shot-Auswertung
bei Null In der Beispieleinstellung bewertet das Modell das Problem direkt; in der Wenig-Schuss-Aufgabe wird eine kleine Anzahl von Beispielen (z. B. 5) aus derselben Aufgabe eingegeben, bevor die Testprobe bewertet wird.
Um die Argumentationsfähigkeit des Modells weiter zu testen, wurde im Experiment auch die Chain of Thought (CoT)-Eingabeaufforderung eingeführt, d. h. zuerst die Eingabeaufforderung eingeben „Lassen Sie uns Schritt für Schritt denken“ als gegeben Die Frage generiert eine Erklärung und gibt dann die Eingabeaufforderung „Erklärung ist“ ein, um die endgültige Antwort basierend auf der Erklärung zu generieren.
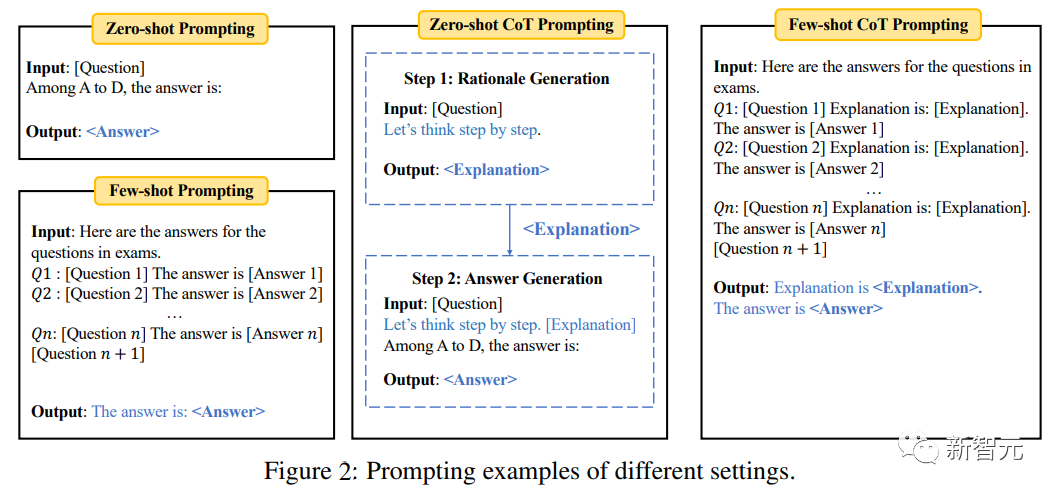
Die „Multiple-Choice-Fragen“ im Benchmark verwenden die Standardklassifizierungsgenauigkeit; „Füllen Sie die Lücken aus“ verwendet Exact Matching (EM) und F1-Indikatoren.
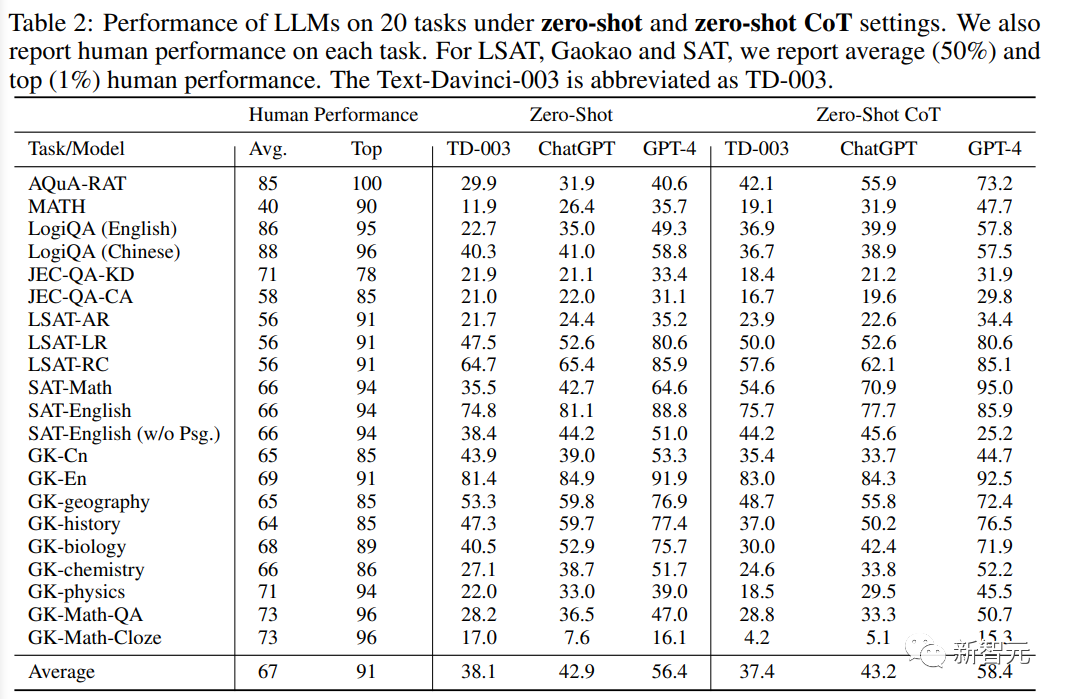
Es kann aus den experimentellen Ergebnissen gefunden werden: # 🎜🎜 #
1. GPT-4 ist in allen Aufgabeneinstellungen deutlich besser als seine ähnlichen Produkte , wobei es auf Gaokao-Englisch eine Genauigkeit von 93,8 % erreichte. erreichte bei SAT-MATH eine Genauigkeit von 95 %, was darauf hinweist, dass GPT-4 über hervorragende allgemeine Fähigkeiten bei der Bewältigung menschenzentrierter Aufgaben verfügt.
2. ChatGPT ist deutlich besser als Text-Davinci-003 bei Aufgaben, die externes Wissen erfordern, wie Geographie, Biologie, Chemie , Physik- und Mathematikaufgaben, was darauf hindeutet, dass ChatGPT über eine stärkere Wissensbasis verfügt und Aufgaben, die ein tiefes Verständnis bestimmter Bereiche erfordern, besser bewältigen kann.
ChatGPT hingegen schneidet in allen Bewertungseinstellungen bei Aufgaben, die reines Verständnis erfordern und nicht stark auf externes Wissen angewiesen sind, wie z. B. Englisch- und LSAT-Aufgaben, leicht ab Text-Davinci-003 oder gleichwertige Ergebnisse. Diese Beobachtung bedeutet, dass beide Modelle in der Lage sind, Aufgaben zu bewältigen, bei denen es um Sprachverständnis und logisches Denken geht, ohne dass spezielle Fachkenntnisse erforderlich sind.
3. Obwohl die Gesamtleistung dieser Modelle gut ist, schneiden alle Sprachmodelle bei komplexen Inferenzaufgaben schlecht ab. Beispiele hierfür sind MATH, LSAT-AR, GK-Physik und GK-Math, was die Einschränkungen dieser Modelle bei der Bewältigung von Aufgaben hervorhebt, die fortgeschrittene Denk- und Problemlösungsfähigkeiten erfordern.
Die beobachteten Schwierigkeiten bei der Handhabung komplexer Inferenzprobleme bieten Möglichkeiten für zukünftige Forschung und Entwicklung mit dem Ziel, die allgemeinen Inferenzfähigkeiten des Modells zu verbessern.4. Im Vergleich zum Zero-Shot-Lernen bringt
Few-Shot-Lernen normalerweise nur eine begrenzte Leistungsverbesserung , was darauf hinweist, dass das Zero-Shot-Lernen derzeit nur begrenzte Leistungsverbesserungen mit sich bringt. Die Lernfähigkeiten großer Sprachmodelle mit wenigen Schüssen nähern sich den Lernfähigkeiten mit wenigen Schüssen an und stellen auch eine große Verbesserung gegenüber dem ursprünglichen GPT-3-Modell dar, als die Leistung mit wenigen Schüssen viel besser war als die Leistung mit null Schüssen.
Eine vernünftige Erklärung für diese Entwicklung ist die Verbesserung menschlicher Anpassungen und instruktiver Anpassungen in aktuellen Sprachmodellen, und diese Verbesserungen ermöglichen es den Modellen, das im Voraus besser zu verstehen Bedeutung und Kontext der Aufgaben, sodass sie auch in Zero-Shot-Situationen gut funktionieren und die Wirksamkeit der Anweisungen beweisen.Das obige ist der detaillierte Inhalt vonDie KI-Prüfung und die öffentliche Prüfung stehen vor der Tür! Das chinesische Team von Microsoft veröffentlicht den neuen Benchmark AGIEval, der speziell für Untersuchungen am Menschen entwickelt wurde. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 startet SSH
Apr 14, 2025 pm 09:00 PM
Der Befehl zum Neustart des SSH -Dienstes lautet: SystemCTL Neustart SSHD. Detaillierte Schritte: 1. Zugriff auf das Terminal und eine Verbindung zum Server; 2. Geben Sie den Befehl ein: SystemCTL Neustart SSHD; 1. Überprüfen Sie den Dienststatus: SystemCTL -Status SSHD.
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
