
 Technologie-Peripheriegeräte
KI
mPLUG-Owl der DAMO Academy stellt sein Debüt vor: ein modulares multimodales großes Modell, das mit den multimodalen Fähigkeiten von GPT-4 gleichzieht
Technologie-Peripheriegeräte
KI
mPLUG-Owl der DAMO Academy stellt sein Debüt vor: ein modulares multimodales großes Modell, das mit den multimodalen Fähigkeiten von GPT-4 gleichzieht
mPLUG-Owl der DAMO Academy stellt sein Debüt vor: ein modulares multimodales großes Modell, das mit den multimodalen Fähigkeiten von GPT-4 gleichzieht

Reine Text-Großmodelle sind auf dem Vormarsch, und im multimodalen Bereich hat GPT-4 begonnen, das stärkste an der Oberfläche zu sein, es verfügt über die multimodale Fähigkeit, Bilder zu lesen, war aber noch nicht offen dafür Die Öffentlichkeit sucht nach Erfahrung, daher gibt es keine Forschung. Die Community begann, in dieser Richtung zu recherchieren und Open Source zu veröffentlichen. Kurz nach der Einführung von MiniGPT-4 und LLaVA brachte die Alibaba DAMO Academy mPLUG-Owl auf den Markt, ein großes multimodales Modell, das auf einer modularen Implementierung basiert.
mPLUG-Owl ist das neueste Werk der mPLUG-Reihe der Alibaba Damo Academy. Es führt die modulare Ausbildungsidee der mPLUG-Reihe fort und erweitert das LLM zu einem großen multimodalen Modell. In der mPLUG-Arbeitsreihe wurden die vorherigen E2E-VLP-, mPLUG- und mPLUG-2-Arbeiten von ACL2021, EMNLP2022 bzw. ICML2023 akzeptiert. Unter ihnen stand die mPLUG-Arbeit mit übermenschlichen Ergebnissen an der Spitze der VQA-Liste.
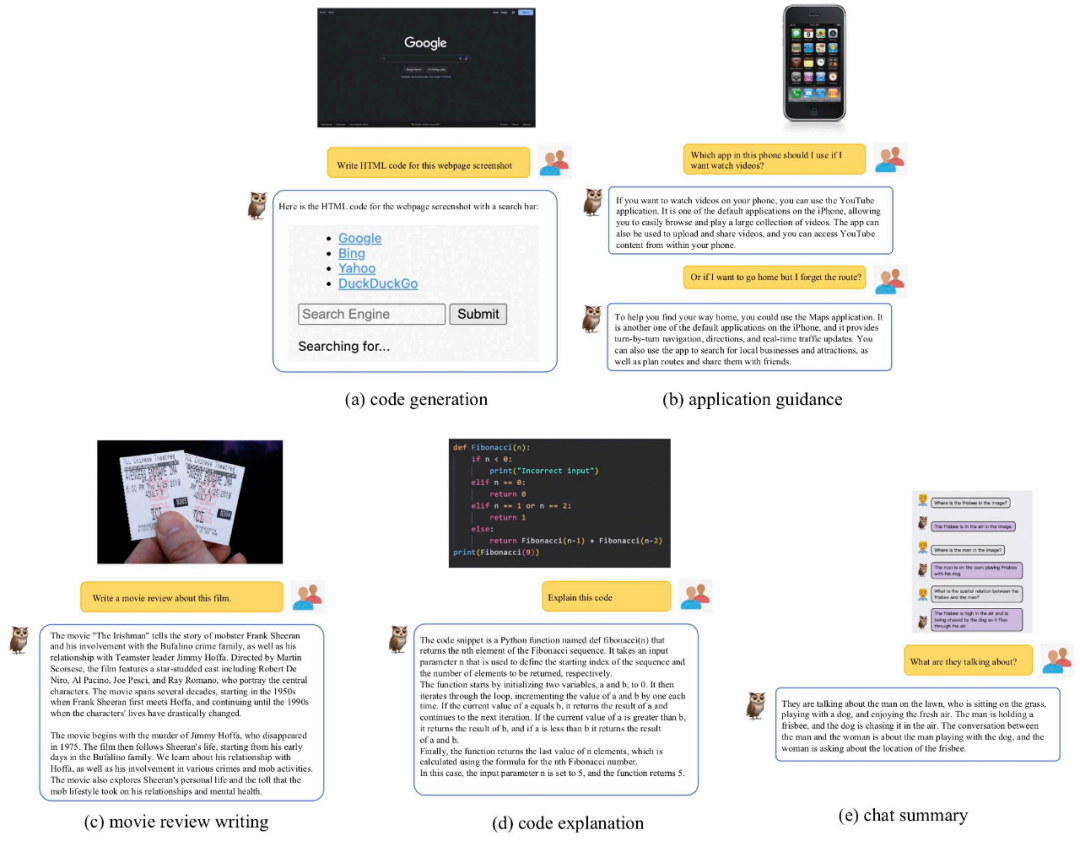
Heute stellen wir mPLUG-Owl vor. Diese Arbeit demonstriert nicht nur hervorragende multimodale Fähigkeiten anhand einer großen Anzahl von Fällen, sondern schlägt auch erstmals einen umfassenden Testsatz OwlEval für das visuelle Unterrichtsverständnis vor, der verglichen wird Durch die Integration bestehender Modelle, einschließlich LLaVA, MiniGPT-4, BLIP-2 und systembasiertem MM-REACT, zeigen experimentelle Ergebnisse, dass mPLUG-Owl bessere multimodale Fähigkeiten aufweist, insbesondere in Bezug auf multimodale Befehlsverständnisfähigkeiten Multimodale Befehlsverständnisfähigkeiten. Hervorragende Leistung in der Fähigkeit, abwechselnd Gespräche zu führen und Wissen zu argumentieren Code-Link: https://github.com/
HuggingFace-Erlebnisadresse:
Multimodale Fähigkeitsdemonstration
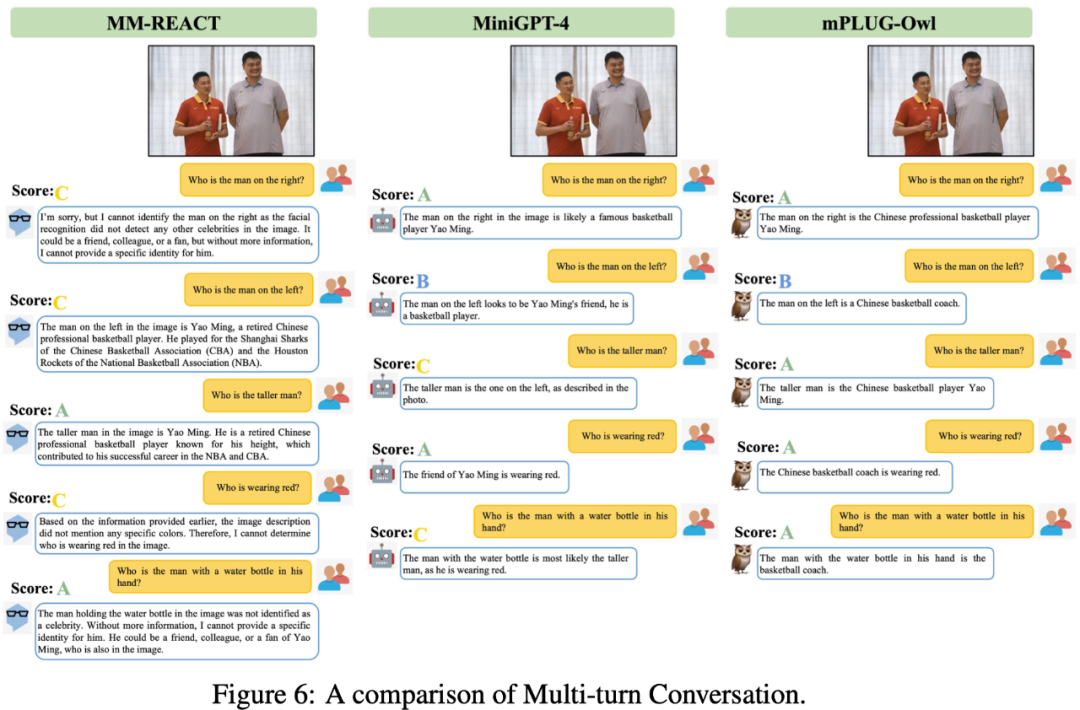
Wir vergleichen mPLUG-Owl mit bestehender Arbeit Um die multimodale Wirkung von mPLUG-Owl zu spüren, ist es erwähnenswert, dass die in dieser Arbeit bewerteten Testproben im Wesentlichen aus bestehenden Arbeiten stammen, wodurch das Rosinenpick-Problem vermieden wird.Abbildung 6 unten zeigt die starken Mehrrunden-Dialogfunktionen von mPLUG-Owl.
Aus Abbildung 7 geht hervor, dass mPLUG-Owl über starke Denkfähigkeiten verfügt.
Abbildung 9 zeigt einige Beispiele für Witzerklärungen.
In dieser Arbeit stellte das Forschungsteam neben der Bewertung und dem Vergleich auch fest, dass mPLUG-Owl zunächst einige unerwartete Fähigkeiten gezeigt hat, wie z. B. die Assoziation mehrerer Bilder, die Mehrsprachigkeit, die Texterkennung usw Dokumentenverständnis und andere Fähigkeiten.
Wie in Abbildung 10 gezeigt, hat mPLUG-Owl bestimmte Multi-Graph-Korrelationsfunktionen demonstriert, obwohl Multi-Graph-Korrelationsdaten während der Trainingsphase nicht trainiert werden.

Obwohl mPLUG-Owl nicht auf annotierte Dokumentdaten trainiert wurde, zeigte es dennoch bestimmte Texterkennungs- und Dokumentverständnisfunktionen Die Testergebnisse sind in Abbildung 12 dargestellt.
Methodeneinführung
Von dieser Arbeit vorgeschlagen Die Gesamtarchitektur von mPLUG-Owl ist in Abbildung 2 dargestellt.
Modellstruktur: Es besteht aus dem visuellen Basismodul #🎜 🎜#
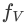
(Open Source ViT-L), visuelles Abstraktionsmodul #🎜🎜 ## 🎜🎜#
 und vorab trainiertes Sprachmodell
und vorab trainiertes Sprachmodell
#🎜🎜 #( LLaMA-7B) Zusammensetzung. Das visuelle Abstraktionsmodul fasst längere, feinkörnigere Bildmerkmale in einer kleinen Anzahl lernbarer Tokens zusammen und erreicht so eine effiziente Modellierung visueller Informationen. Die generierten visuellen Token werden zusammen mit der Textabfrage in das Sprachmodell eingegeben, um entsprechende Antworten zu generieren. 
Modelltraining: mit einer zweistufigen Trainingsmethode
# 🎜🎜#Die erste Stufe: Der Hauptzweck besteht auch darin, zunächst den Kontrast zwischen visuellen und sprachlichen Modalitäten zu lernen. Im Gegensatz zu früheren Arbeiten schlägt mPLUG-Owl vor, dass das Einfrieren des visuellen Basismoduls die Fähigkeit des Modells, visuelles Wissen und Textwissen zu verknüpfen, einschränkt. Daher friert mPLUG-Owl in der ersten Stufe nur die Parameter von LLM ein und verwendet LAION-400M, COYO-700M, CC und MSCOCO, um das visuelle Basismodul und das visuelle Zusammenfassungsmodul zu trainieren.
Phase 2: Owl setzt die Entdeckung fort, dass gemischtes Training verschiedener Modalitäten in mPLUG und mPLUG-2 einander zugute kommt, und verwendet in der zweiten Phase auch Anweisungen zur Feinabstimmung Es werden sowohl Klartext-Anweisungsdaten (52.000 von Alpaca + 90.000 von Vicuna + 50.000 von Baize) als auch multimodale Anweisungendaten (150.000 von LLaVA) verwendet. Durch detaillierte Ablationsexperimente verifizierte der Autor die Vorteile, die sich aus der Einführung reiner Textanweisungen und der Feinabstimmung von Aspekten wie dem Verständnis der Anweisungen ergeben. In der zweiten Stufe werden die Parameter des visuellen Basismoduls, des visuellen Zusammenfassungsmoduls und des ursprünglichen LLM eingefroren. In Bezug auf LoRA wird nur eine Adapterstruktur mit einer kleinen Anzahl von Parametern zur Feinabstimmung der Anweisungen in das LLM eingeführt.
Experimentelle ErgebnisseSOTA-Vergleich
# 🎜 🎜#Um die multimodalen Fähigkeiten verschiedener Modelle zu vergleichen, erstellt diese Arbeit einen multimodalen Befehlsbewertungssatz OwlEval. Da es derzeit keine geeigneten automatisierten Indikatoren gibt, wenden Sie sich an Self-Intruct für die manuelle Bewertung der Antworten des Modells. Die Bewertungsregeln lauten: A = „Richtig und zufriedenstellend“; C = „Verstanden“. Anweisungen, aber die Antworten enthielten offensichtliche Fehler"; D="Völlig irrelevante oder falsche Antworten".
Die Vergleichsergebnisse sind in Abbildung 3 unten dargestellt. Das Experiment beweist, dass Owl besser ist als die vorhandenen OpenFlamingo, BLIP-2, LLaVA, MiniGPT-4.
Mehrdimensionaler Fähigkeitsvergleich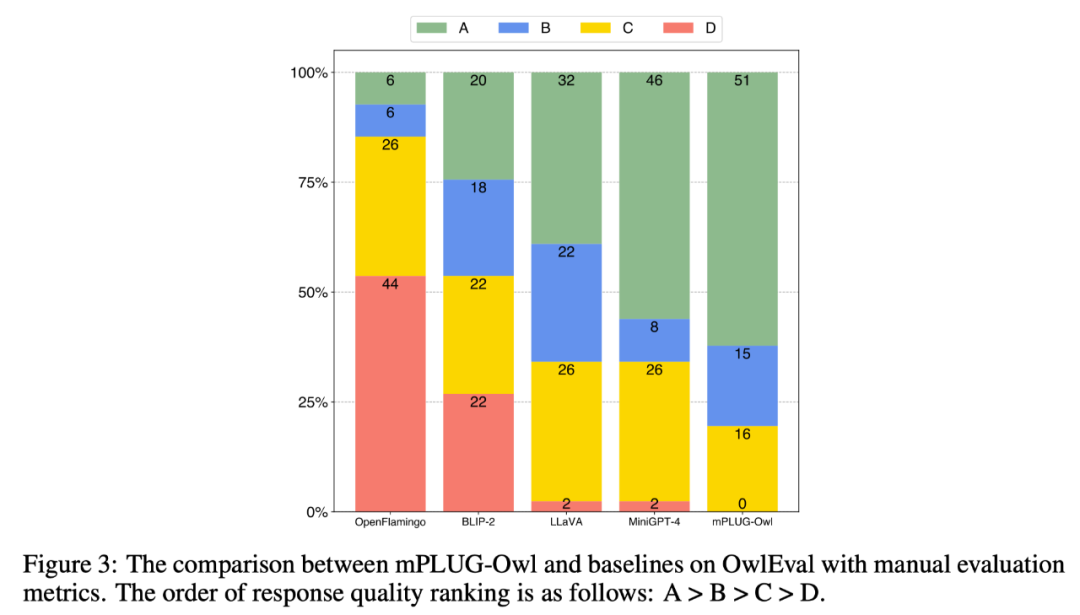 # 🎜 🎜#
# 🎜 🎜#
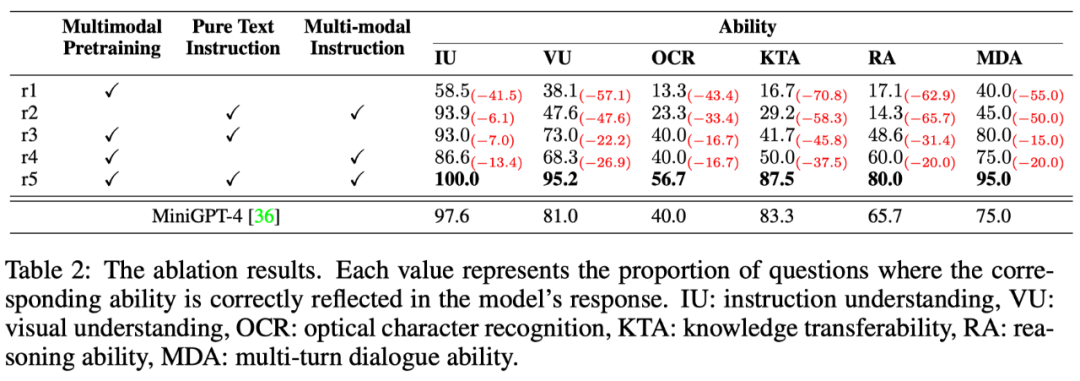
Multimodale Befehlsantwortaufgaben erfordern mehrere Fähigkeiten, wie z. B. Befehlsverständnis, visuelles Verständnis, Textverständnis auf Bildern und Argumentation. Um das Niveau der verschiedenen Fähigkeiten des Modells feinkörnig zu untersuchen, werden in diesem Artikel sechs Hauptfähigkeiten in multimodalen Szenarien weiter definiert und jede Testanweisung von OwlEval manuell mit den relevanten Fähigkeitsanforderungen und den darin reflektierten Antworten versehen das Modell. Welche Fähigkeiten wurden erworben?
Die Ergebnisse sind in Tabelle 6 unten aufgeführt. In diesem Teil des Experiments führte der Autor nicht nur Eulenablationsexperimente durch, sondern überprüfte auch die Wirksamkeit der Trainingsstrategie und multimodale Befehlsfeinabstimmungsdaten werden auch mit der leistungsstärksten Basislinie im vorherigen Experiment verglichen – MiniGPT4. Die Ergebnisse zeigen, dass Owl in allen Leistungsaspekten besser ist als MiniGPT4.
Das obige ist der detaillierte Inhalt vonmPLUG-Owl der DAMO Academy stellt sein Debüt vor: ein modulares multimodales großes Modell, das mit den multimodalen Fähigkeiten von GPT-4 gleichzieht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Was sind die Methoden zur Abstimmung der Leistung von Zookeeper auf CentOS
Apr 14, 2025 pm 03:18 PM
Was sind die Methoden zur Abstimmung der Leistung von Zookeeper auf CentOS
Apr 14, 2025 pm 03:18 PM
Die Zookeper -Leistungsstimmung auf CentOS kann von mehreren Aspekten beginnen, einschließlich Hardwarekonfiguration, Betriebssystemoptimierung, Konfigurationsparameteranpassung, Überwachung und Wartung usw. Hier finden Sie einige spezifische Tuning -Methoden: SSD wird für die Hardwarekonfiguration: Da die Daten von Zookeeper an Disk geschrieben werden, wird empfohlen, SSD zu verbessern, um die I/O -Leistung zu verbessern. Genug Memory: Zookeeper genügend Speicherressourcen zuweisen, um häufige Lesen und Schreiben von häufigen Festplatten zu vermeiden. Multi-Core-CPU: Verwenden Sie Multi-Core-CPU, um sicherzustellen, dass Zookeeper es parallel verarbeiten kann.
 Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Effizientes Training von Pytorch -Modellen auf CentOS -Systemen erfordert Schritte, und dieser Artikel bietet detaillierte Anleitungen. 1.. Es wird empfohlen, YUM oder DNF zu verwenden, um Python 3 und Upgrade PIP zu installieren: Sudoyumupdatepython3 (oder sudodnfupdatepython3), PIP3Install-upgradepip. CUDA und CUDNN (GPU -Beschleunigung): Wenn Sie Nvidiagpu verwenden, müssen Sie Cudatool installieren
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
Bei der Auswahl einer Pytorch -Version unter CentOS müssen die folgenden Schlüsselfaktoren berücksichtigt werden: 1. Cuda -Version Kompatibilität GPU -Unterstützung: Wenn Sie NVIDIA -GPU haben und die GPU -Beschleunigung verwenden möchten, müssen Sie Pytorch auswählen, der die entsprechende CUDA -Version unterstützt. Sie können die CUDA-Version anzeigen, die unterstützt wird, indem Sie den Befehl nvidia-smi ausführen. CPU -Version: Wenn Sie keine GPU haben oder keine GPU verwenden möchten, können Sie eine CPU -Version von Pytorch auswählen. 2. Python Version Pytorch
