
 Backend-Entwicklung
Python-Tutorial
So entwickeln Sie mit Python ein benutzerdefiniertes Web-Framework
Backend-Entwicklung
Python-Tutorial
So entwickeln Sie mit Python ein benutzerdefiniertes Web-Framework
So entwickeln Sie mit Python ein benutzerdefiniertes Web-Framework

Entwickeln Sie ein benutzerdefiniertes Web-Framework
Empfangen Sie dynamische Ressourcenanforderungen vom Webserver und stellen Sie dem Webserver Dienste zur Verarbeitung dynamischer Ressourcenanforderungen zur Verfügung. Bestimmen Sie anhand des Suffixnamens des angeforderten Ressourcenpfads:
Wenn der Suffixname des angeforderten Ressourcenpfads .html ist, handelt es sich um eine dynamische Ressourcenanforderung, und lassen Sie sie vom Web-Framework-Programm verarbeiten.
Andernfalls handelt es sich um eine statische Ressourcenanforderung. Lassen Sie das Webserverprogramm damit umgehen.
1. Entwickeln Sie das Hauptprogramm des Webservers
1. Akzeptieren Sie die Client-HTTP-Anfrage (die unterste Ebene ist TCP)
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
from socket import *
import threading
# 开发自己的Web服务器主类
class MyHttpWebServer(object):
def __init__(self, port):
# 创建 HTTP服务的 TCP套接字
server_socket = socket(AF_INET, SOCK_STREAM)
# 设置端口号互用,程序退出之后不需要等待,直接释放端口
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, True)
# 绑定 ip和 port
server_socket.bind(('', port))
# listen使套接字变为了被动连接
server_socket.listen(128)
self.server_socket = server_socket
# 处理请求函数
@staticmethod # 静态方法
def handle_browser_request(new_socket):
# 接受客户端发来的数据
recv_data = new_socket.recv(4096)
# 如果没有数据,那么请求无效,关闭套接字,直接退出
if len(recv_data) == 0:
new_socket.close()
return
# 启动服务器,并接受客户端请求
def start(self):
# 循环并多线程来接收客户端请求
while True:
# accept等待客户端连接
new_socket, ip_port = self.server_socket.accept()
print("客户端ip和端口", ip_port)
# 一个客户端的请求交给一个线程来处理
sub_thread = threading.Thread(target=MyHttpWebServer.handle_browser_request, args=(new_socket, ))
# 设置当前线程为守护线程
sub_thread.setDaemon(True)
sub_thread.start() # 启动子线程
# Web 服务器程序的入口
def main():
web_server = MyHttpWebServer(8080)
web_server.start()
if __name__ == '__main__':
main()2 . Bestimmen Sie, ob es sich bei der Anfrage um statische Ressourcen oder dynamische Ressourcen handelt
# 对接收的字节数据进行转换为字符数据
request_data = recv_data.decode('utf-8')
print("浏览器请求的数据:", request_data)
request_array = request_data.split(' ', maxsplit=2)
# 得到请求路径
request_path = request_array[1]
print("请求的路径是:", request_path)
if request_path == "/":
# 如果请求路径为根目录,自动设置为:/index.html
request_path = "/index.html"
# 判断是否为:.html 结尾
if request_path.endswith(".html"):
"动态资源请求"
pass
else:
"静态资源请求"
pass3. Wie gehe ich mit statischen Ressourcen um?
"静态资源请求"
# 根据请求路径读取/static 目录中的文件数据,相应给客户端
response_body = None # 响应主体
response_header = None # 响应头的第一行
response_first_line = None # 响应头内容
response_type = 'test/html' # 默认响应类型
try:
# 读取 static目录中相对应的文件数据,rb模式是一种兼容模式,可以打开图片,也可以打开js
with open('static'+request_path, 'rb') as f:
response_body = f.read()
if request_path.endswith('.jpg'):
response_type = 'image/webp'
response_first_line = 'HTTP/1.1 200 OK'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: ' + response_type + '; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 浏览器读取的文件可能不存在
except Exception as e:
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容
# 响应头
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Content-Length:'+str(len(response_body))+'\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 最后都会执行的代码
finally:
# 组成响应数据发送给(客户端)浏览器
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response)
# 关闭套接字
new_socket.close()
Statische Ressourcenanforderungsüberprüfung:
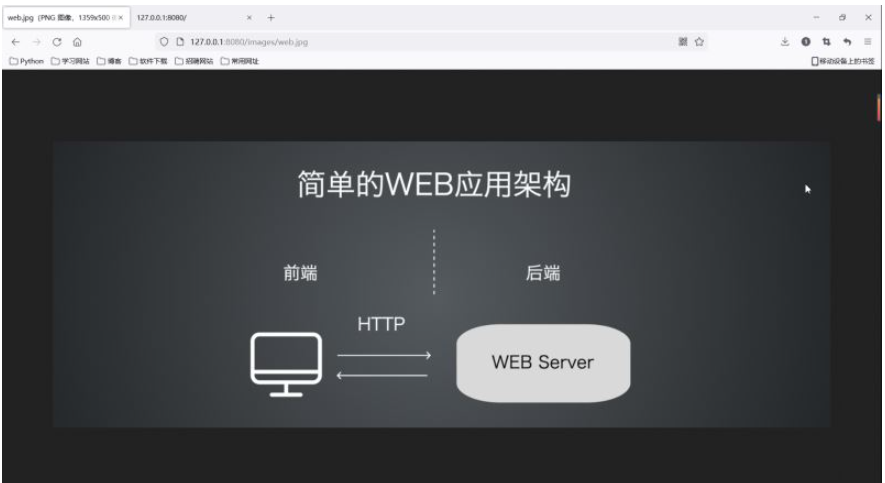
4. Was tun, wenn dynamische Ressourcen vorhanden sind?
if request_path.endswith(".html"):
"动态资源请求"
# 动态资源的处理交给Web框架来处理,需要把请求参数交给Web框架,可能会有多个参数,采用字典结构
params = {
'request_path': request_path
}
# Web框架处理动态资源请求后,返回一个响应
response = MyFramework.handle_request(params)
new_socket.send(response)
new_socket.close()5. Schließen Sie die Gesamtcodeanzeige des Webservers : #🎜🎜 #
new_socket.close()
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
import sys
import time
from socket import *
import threading
import MyFramework
# 开发自己的Web服务器主类
class MyHttpWebServer(object):
def __init__(self, port):
# 创建 HTTP服务的 TCP套接字
server_socket = socket(AF_INET, SOCK_STREAM)
# 设置端口号互用,程序退出之后不需要等待,直接释放端口
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, True)
# 绑定 ip和 port
server_socket.bind(('', port))
# listen使套接字变为了被动连接
server_socket.listen(128)
self.server_socket = server_socket
# 处理请求函数
@staticmethod # 静态方法
def handle_browser_request(new_socket):
# 接受客户端发来的数据
recv_data = new_socket.recv(4096)
# 如果没有数据,那么请求无效,关闭套接字,直接退出
if len(recv_data) == 0:
new_socket.close()
return
# 对接收的字节数据进行转换为字符数据
request_data = recv_data.decode('utf-8')
print("浏览器请求的数据:", request_data)
request_array = request_data.split(' ', maxsplit=2)
# 得到请求路径
request_path = request_array[1]
print("请求的路径是:", request_path)
if request_path == "/":
# 如果请求路径为根目录,自动设置为:/index.html
request_path = "/index.html"
# 判断是否为:.html 结尾
if request_path.endswith(".html"):
"动态资源请求"
# 动态资源的处理交给Web框架来处理,需要把请求参数交给Web框架,可能会有多个参数,采用字典结构
params = {
'request_path': request_path
}
# Web框架处理动态资源请求后,返回一个响应
response = MyFramework.handle_request(params)
new_socket.send(response)
new_socket.close()
else:
"静态资源请求"
# 根据请求路径读取/static 目录中的文件数据,相应给客户端
response_body = None # 响应主体
response_header = None # 响应头的第一行
response_first_line = None # 响应头内容
response_type = 'test/html' # 默认响应类型
try:
# 读取 static目录中相对应的文件数据,rb模式是一种兼容模式,可以打开图片,也可以打开js
with open('static'+request_path, 'rb') as f:
response_body = f.read()
if request_path.endswith('.jpg'):
response_type = 'image/webp'
response_first_line = 'HTTP/1.1 200 OK'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: ' + response_type + '; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 浏览器读取的文件可能不存在
except Exception as e:
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容
# 响应头
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Content-Length:'+str(len(response_body))+'\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 最后都会执行的代码
finally:
# 组成响应数据发送给(客户端)浏览器
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response)
# 关闭套接字
new_socket.close()
# 启动服务器,并接受客户端请求
def start(self):
# 循环并多线程来接收客户端请求
while True:
# accept等待客户端连接
new_socket, ip_port = self.server_socket.accept()
print("客户端ip和端口", ip_port)
# 一个客户端的请求交给一个线程来处理
sub_thread = threading.Thread(target=MyHttpWebServer.handle_browser_request, args=(new_socket, ))
# 设置当前线程为守护线程
sub_thread.setDaemon(True)
sub_thread.start() # 启动子线程
# Web 服务器程序的入口
def main():
web_server = MyHttpWebServer(8080)
web_server.start()
if __name__ == '__main__':
main()Nach dem Login kopieren
2. Wenn der Anforderungspfad nicht übereinstimmt, müssen die Antwortdaten auch die 404-Seite zurückgeben 3 Verwenden Sie eine Vorlage, um den Antwortinhalt anzuzeigen#. 🎜🎜## -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
import sys
import time
from socket import *
import threading
import MyFramework
# 开发自己的Web服务器主类
class MyHttpWebServer(object):
def __init__(self, port):
# 创建 HTTP服务的 TCP套接字
server_socket = socket(AF_INET, SOCK_STREAM)
# 设置端口号互用,程序退出之后不需要等待,直接释放端口
server_socket.setsockopt(SOL_SOCKET, SO_REUSEADDR, True)
# 绑定 ip和 port
server_socket.bind(('', port))
# listen使套接字变为了被动连接
server_socket.listen(128)
self.server_socket = server_socket
# 处理请求函数
@staticmethod # 静态方法
def handle_browser_request(new_socket):
# 接受客户端发来的数据
recv_data = new_socket.recv(4096)
# 如果没有数据,那么请求无效,关闭套接字,直接退出
if len(recv_data) == 0:
new_socket.close()
return
# 对接收的字节数据进行转换为字符数据
request_data = recv_data.decode('utf-8')
print("浏览器请求的数据:", request_data)
request_array = request_data.split(' ', maxsplit=2)
# 得到请求路径
request_path = request_array[1]
print("请求的路径是:", request_path)
if request_path == "/":
# 如果请求路径为根目录,自动设置为:/index.html
request_path = "/index.html"
# 判断是否为:.html 结尾
if request_path.endswith(".html"):
"动态资源请求"
# 动态资源的处理交给Web框架来处理,需要把请求参数交给Web框架,可能会有多个参数,采用字典结构
params = {
'request_path': request_path
}
# Web框架处理动态资源请求后,返回一个响应
response = MyFramework.handle_request(params)
new_socket.send(response)
new_socket.close()
else:
"静态资源请求"
# 根据请求路径读取/static 目录中的文件数据,相应给客户端
response_body = None # 响应主体
response_header = None # 响应头的第一行
response_first_line = None # 响应头内容
response_type = 'test/html' # 默认响应类型
try:
# 读取 static目录中相对应的文件数据,rb模式是一种兼容模式,可以打开图片,也可以打开js
with open('static'+request_path, 'rb') as f:
response_body = f.read()
if request_path.endswith('.jpg'):
response_type = 'image/webp'
response_first_line = 'HTTP/1.1 200 OK'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: ' + response_type + '; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 浏览器读取的文件可能不存在
except Exception as e:
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容
# 响应头
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Content-Length:'+str(len(response_body))+'\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
# 最后都会执行的代码
finally:
# 组成响应数据发送给(客户端)浏览器
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
new_socket.send(response)
# 关闭套接字
new_socket.close()
# 启动服务器,并接受客户端请求
def start(self):
# 循环并多线程来接收客户端请求
while True:
# accept等待客户端连接
new_socket, ip_port = self.server_socket.accept()
print("客户端ip和端口", ip_port)
# 一个客户端的请求交给一个线程来处理
sub_thread = threading.Thread(target=MyHttpWebServer.handle_browser_request, args=(new_socket, ))
# 设置当前线程为守护线程
sub_thread.setDaemon(True)
sub_thread.start() # 启动子线程
# Web 服务器程序的入口
def main():
web_server = MyHttpWebServer(8080)
web_server.start()
if __name__ == '__main__':
main()1. Entwerfen Sie selbst eine Vorlage index.html, einige Orte verwenden dynamische Daten, um 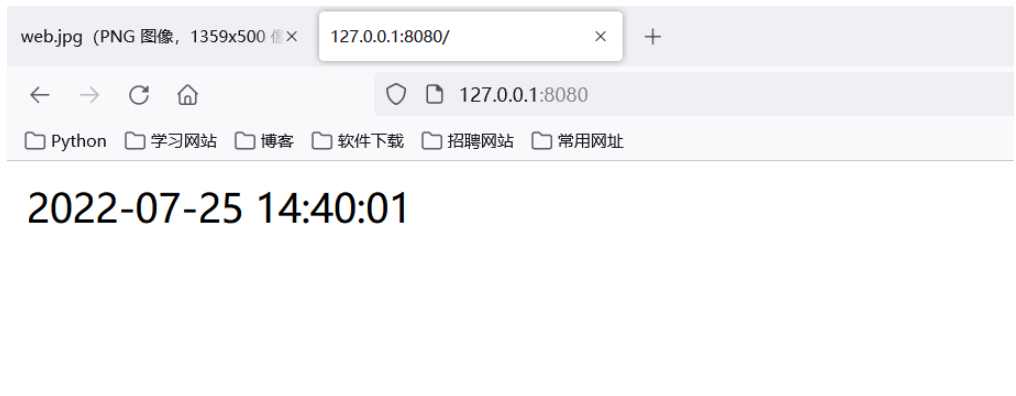
# -*- coding: utf-8 -*-
# @File : MyFramework.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/25 14:05
import time
# 自定义Web框架
# 处理动态资源请求的函数
def handle_request(parm):
request_path = parm['request_path']
if request_path == '/index.html': # 当前请求路径有与之对应的动态响应,当前框架只开发了 index.html的功能
response = index()
return response
else:
# 没有动态资源的数据,返回404页面
return page_not_found()
# 当前 index函数,专门处理index.html的请求
def index():
# 需求,在页面中动态显示当前系统时间
data = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
response_body = data
response_first_line = 'HTTP/1.1 200 OK\r\n'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
response = (response_first_line + response_header + '\r\n' + response_body).encode('utf-8')
return response
def page_not_found():
with open('static/404.html', 'rb') as f:
response_body = f.read() # 响应的主体页面内容
# 响应头
response_first_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Content-Length:' + str(len(response_body)) + '\r\n' + \
'Content-Type: text/html; charset=utf-8\r\n' + \
'Date:' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) + '\r\n' + \
'Server: Flyme awei Server\r\n'
response = (response_first_line + response_header + '\r\n').encode('utf-8') + response_body
return response# 🎜🎜#a. Fügen Sie einen bedingten Beurteilungszweig hinzu#🎜🎜 #
b Fügen Sie eine spezielle Verarbeitungsfunktion hinzu 2. Es handelt sich um die direkte Zuordnung zwischen dem angeforderten URL-Pfad und der Verarbeitung Funktion.
2. Es handelt sich um die direkte Zuordnung zwischen dem angeforderten URL-Pfad und der Verarbeitung Funktion.
3, Routing-Tabelle
AnforderungspfadVerarbeitungsfunktion#🎜 🎜#
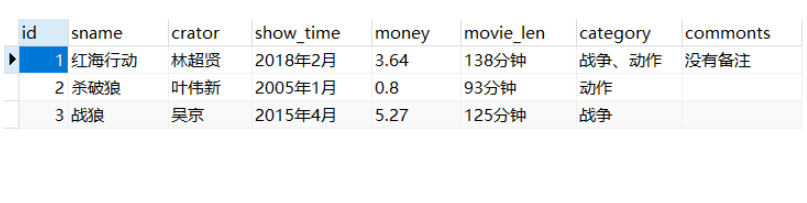
/index.html
| /user_info.html | #🎜 🎜#user_info function |
|---|---|
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>首页 - 电影列表</title>
<link href="/css/bootstrap.min.css" rel="stylesheet">
<script src="/js/jquery-1.12.4.min.js"></script>
<script src="/js/bootstrap.min.js"></script>
</head>
<body>
<div class="navbar navbar-inverse navbar-static-top ">
<div class="container">
<div class="navbar-header">
<button class="navbar-toggle" data-toggle="collapse" data-target="#mymenu">
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a href="#" class="navbar-brand">电影列表</a>
</div>
<div class="collapse navbar-collapse" id="mymenu">
<ul class="nav navbar-nav">
<li class="active"><a href="">电影信息</a></li>
<li><a href="">个人中心</a></li>
</ul>
</div>
</div>
</div>
<div class="container">
<div class="container-fluid">
<table class="table table-hover">
<tr>
<th>序号</th>
<th>名称</th>
<th>导演</th>
<th>上映时间</th>
<th>票房</th>
<th>电影时长</th>
<th>类型</th>
<th>备注</th>
<th>删除电影</th>
</tr>
{%datas%}
</table>
</div>
</div>
</body>
</html>Nach dem Login kopieren | Hinweis: Die dynamische Ressourcenanforderung des Benutzers wird durch Durchlaufen der Routing-Tabelle abgeschlossen, um die entsprechende Verarbeitungsfunktion zu finden. 5. Verwenden Sie einen Dekorator, um Routen hinzuzufügen |
response_body = response_body.replace('{%datas%}', data)Nach dem Login kopieren | 2 Funktion zum Hinzufügen von Routen # 定义路由表
route_list = {
('/index.html', index),
('/user_info.html', user_info)
}
for path, func in route_list:
if request_path == path:
return func()
else:
# 没有动态资源的数据,返回404页面
return page_not_found()Nach dem Login kopieren | Zusammenfassung: Mithilfe des Decorators mit Parametern können wir unsere Routen automatisch zur Routing-Tabelle hinzufügen.
# -*- coding: utf-8 -*-
# @File : My_Web_Server.py
# @author: Flyme awei
# @email : 1071505897@qq.com
# @Time : 2022/7/24 21:28
# 定义路由表
route_list = []
# route_list = {
# ('/index.html', index),
# ('/user_info.html', user_info)
# }
# 定义一个带参数的装饰器
def route(request_path): # 参数就是URL请求
def add_route(func):
# 添加路由表
route_list.append((request_path, func))
@wraps(func)
def invoke(*args, **kwargs):
# 调用指定的处理函数,并返回结果
return func()
return invoke
return add_route
# 处理动态资源请求的函数
def handle_request(parm):
request_path = parm['request_path']
# if request_path == '/index.html': # 当前请求路径有与之对应的动态响应,当前框架只开发了 index.html的功能
# response = index()
# return response
# elif request_path == '/user_info.html': # 个人中心的功能
# return user_info()
# else:
# # 没有动态资源的数据,返回404页面
# return page_not_found()
for path, func in route_list:
if request_path == path:
return func()
else:
# 没有动态资源的数据,返回404页面
return page_not_found()@route('/user_info.html')
Das obige ist der detaillierte Inhalt vonSo entwickeln Sie mit Python ein benutzerdefiniertes Web-Framework. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So verwenden Sie Debian Apache -Protokolle, um die Website der Website zu verbessern
Apr 12, 2025 pm 11:36 PM
So verwenden Sie Debian Apache -Protokolle, um die Website der Website zu verbessern
Apr 12, 2025 pm 11:36 PM
In diesem Artikel wird erläutert, wie die Leistung der Website verbessert wird, indem Apache -Protokolle im Debian -System analysiert werden. 1. Log -Analyse -Basics Apache Protokoll Datensätze Die detaillierten Informationen aller HTTP -Anforderungen, einschließlich IP -Adresse, Zeitstempel, URL, HTTP -Methode und Antwortcode. In Debian -Systemen befinden sich diese Protokolle normalerweise in /var/log/apache2/access.log und /var/log/apache2/error.log verzeichnis. Das Verständnis der Protokollstruktur ist der erste Schritt in der effektiven Analyse. 2. Tool mit Protokollanalyse Mit einer Vielzahl von Tools können Apache -Protokolle analysiert: Befehlszeilen -Tools: GREP, AWK, SED und andere Befehlszeilen -Tools.
 Python: Spiele, GUIs und mehr
Apr 13, 2025 am 12:14 AM
Python: Spiele, GUIs und mehr
Apr 13, 2025 am 12:14 AM
Python zeichnet sich in Gaming und GUI -Entwicklung aus. 1) Spielentwicklung verwendet Pygame, die Zeichnungen, Audio- und andere Funktionen bereitstellt, die für die Erstellung von 2D -Spielen geeignet sind. 2) Die GUI -Entwicklung kann Tkinter oder Pyqt auswählen. Tkinter ist einfach und einfach zu bedienen. PYQT hat reichhaltige Funktionen und ist für die berufliche Entwicklung geeignet.
 PHP und Python: Vergleich von zwei beliebten Programmiersprachen
Apr 14, 2025 am 12:13 AM
PHP und Python: Vergleich von zwei beliebten Programmiersprachen
Apr 14, 2025 am 12:13 AM
PHP und Python haben jeweils ihre eigenen Vorteile und wählen nach den Projektanforderungen. 1.PHP ist für die Webentwicklung geeignet, insbesondere für die schnelle Entwicklung und Wartung von Websites. 2. Python eignet sich für Datenwissenschaft, maschinelles Lernen und künstliche Intelligenz mit prägnanter Syntax und für Anfänger.
 Die Rolle von Debian Sniffer bei der DDOS -Angriffserkennung
Apr 12, 2025 pm 10:42 PM
Die Rolle von Debian Sniffer bei der DDOS -Angriffserkennung
Apr 12, 2025 pm 10:42 PM
In diesem Artikel wird die DDOS -Angriffserkennungsmethode erörtert. Obwohl kein direkter Antragsfall von "Debiansniffer" gefunden wurde, können die folgenden Methoden zur Erkennung von DDOS -Angriffsanfällen verwendet werden: Effektive DDOS -Angriffserkennungstechnologie: Erkennung auf der Grundlage der Verkehrsanalyse: Identifizierung von DDOS -Angriffen durch Überwachung abnormaler Muster des Netzwerkverkehrs, z. Beispielsweise können Python -Skripte in Kombination mit Pyshark- und Colorama -Bibliotheken den Netzwerkverkehr in Echtzeit überwachen und Warnungen ausstellen. Erkennung auf der Grundlage der statistischen Analyse: Durch Analyse statistischer Merkmale des Netzwerkverkehrs wie Daten
 Nginx SSL -Zertifikat -Aktualisierung Debian Tutorial
Apr 13, 2025 am 07:21 AM
Nginx SSL -Zertifikat -Aktualisierung Debian Tutorial
Apr 13, 2025 am 07:21 AM
In diesem Artikel werden Sie begleitet, wie Sie Ihr NginXSSL -Zertifikat auf Ihrem Debian -System aktualisieren. Schritt 1: Installieren Sie zuerst CertBot und stellen Sie sicher, dass Ihr System Certbot- und Python3-CertBot-Nginx-Pakete installiert hat. If not installed, please execute the following command: sudoapt-getupdatesudoapt-getinstallcertbotpython3-certbot-nginx Step 2: Obtain and configure the certificate Use the certbot command to obtain the Let'sEncrypt certificate and configure Nginx: sudocertbot--nginx Follow the prompts to select
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Um die Effizienz des Lernens von Python in einer begrenzten Zeit zu maximieren, können Sie Pythons DateTime-, Zeit- und Zeitplanmodule verwenden. 1. Das DateTime -Modul wird verwendet, um die Lernzeit aufzuzeichnen und zu planen. 2. Das Zeitmodul hilft, die Studie zu setzen und Zeit zu ruhen. 3. Das Zeitplanmodul arrangiert automatisch wöchentliche Lernaufgaben.
 So konfigurieren Sie den HTTPS -Server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
So konfigurieren Sie den HTTPS -Server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
Das Konfigurieren eines HTTPS -Servers auf einem Debian -System umfasst mehrere Schritte, einschließlich der Installation der erforderlichen Software, der Generierung eines SSL -Zertifikats und der Konfiguration eines Webservers (z. B. Apache oder NGINX) für die Verwendung eines SSL -Zertifikats. Hier ist eine grundlegende Anleitung unter der Annahme, dass Sie einen Apacheweb -Server verwenden. 1. Installieren Sie zuerst die erforderliche Software, stellen Sie sicher, dass Ihr System auf dem neuesten Stand ist, und installieren Sie Apache und OpenSSL: sudoaptupdatesudoaptupgradesudoaptinsta
