
 Technologie-Peripheriegeräte
KI
Stellt die Worteinbettung einen zu großen Anteil an Parametern dar? MorphTE-Methode 20-facher Komprimierungseffekt ohne Verlust
Technologie-Peripheriegeräte
KI
Stellt die Worteinbettung einen zu großen Anteil an Parametern dar? MorphTE-Methode 20-facher Komprimierungseffekt ohne Verlust
Stellt die Worteinbettung einen zu großen Anteil an Parametern dar? MorphTE-Methode 20-facher Komprimierungseffekt ohne Verlust

Einführung
Die Darstellung der Worteinbettung ist die Grundlage für verschiedene Verarbeitungsaufgaben natürlicher Sprache wie maschinelle Übersetzung, Beantwortung von Fragen, Textklassifizierung usw. Sie macht normalerweise 20 bis 90 % der gesamten Modellparameter aus. Das Speichern und Zugreifen auf diese Einbettungen erfordert viel Speicherplatz, was der Modellbereitstellung und -anwendung auf Geräten mit begrenzten Ressourcen nicht förderlich ist. Um dieses Problem anzugehen, wird in diesem Artikel die MorphTE-Worteinbettungskomprimierungsmethode vorgeschlagen. MorphTE kombiniert die leistungsstarken Komprimierungsfunktionen von Tensorproduktoperationen mit Vorkenntnissen der Sprachmorphologie, um eine hohe Komprimierung der Worteinbettungsparameter (mehr als 20 Mal) bei gleichzeitiger Beibehaltung der Modellleistung zu erreichen.

- Papierlink: https://arxiv.org/abs/2210.15379
- Offener Quellcode: https://github.com/bigganbing/Fairseq_MorphTE
Modell
Die in diesem Artikel vorgeschlagene MorphTE-Worteinbettungskomprimierungsmethode unterteilt Wörter zunächst in die kleinsten Einheiten mit semantischer Bedeutung – Morpheme – und trainiert eine niedrigdimensionale Vektordarstellung für jedes Morphem und verwendet dann Tensorprodukte, um das Quantum der niedrigdimensionalen zu realisieren. dimensionale Morphemvektoren Der verschränkte Zustand wird mathematisch dargestellt, um eine hochdimensionale Wortdarstellung zu erhalten.
01 Die Morphemzusammensetzung eines Wortes
In der Linguistik ist ein Morphem die kleinste Einheit mit bestimmten semantischen oder grammatikalischen Funktionen. Bei Sprachen wie Englisch kann ein Wort in kleinere Morphemeinheiten wie Wurzeln und Affixe aufgeteilt werden. Beispielsweise kann „unfreundlich“ in „un“ für Verneinung, „kind“ für etwas wie „freundlich“ und „ly“ für ein Adverb aufgeteilt werden. Für Chinesisch kann ein chinesisches Schriftzeichen auch in kleinere Einheiten wie Radikale aufgeteilt werden, beispielsweise kann „MU“ in „氵“ und „木“ aufgeteilt werden, die für Wasser stehen.

Während Morpheme Semantik enthalten, können sie auch zwischen Wörtern geteilt werden, um verschiedene Wörter zu verbinden. Darüber hinaus kann eine begrenzte Anzahl von Morphemen zu einer größeren Anzahl von Wörtern kombiniert werden.
02 Komprimierte Darstellung von Worteinbettungen in Form verschränkter Tensoren
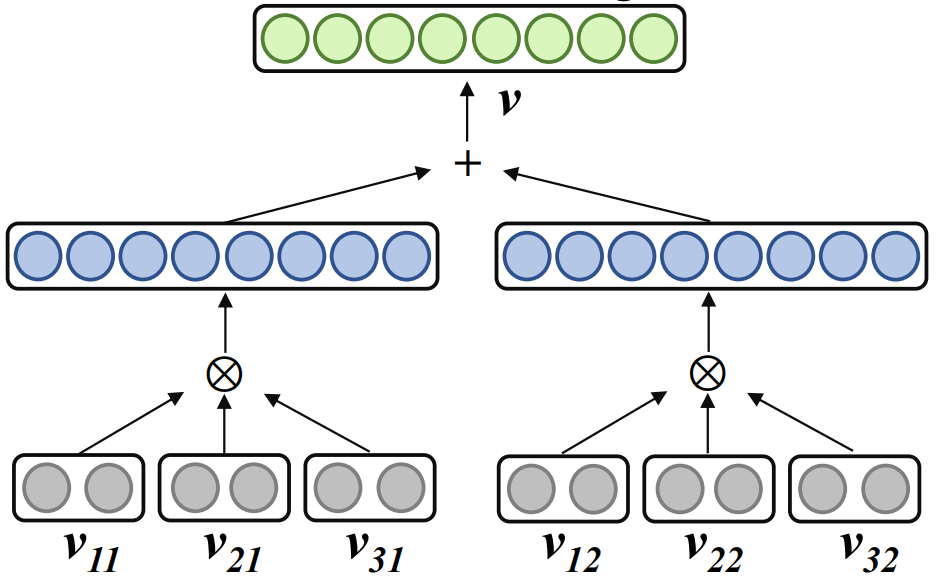
Verwandte Arbeit Word2ket verwendet ein Tensorprodukt, um eine einzelne Worteinbettung als verschränkte Tensorform mehrerer niedrigdimensionaler Vektoren darzustellen :
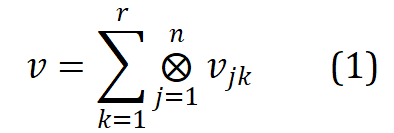
wobei , r der Rang, n die Ordnung und das Tensorprodukt darstellt. Word2ket muss diese niedrigdimensionalen Vektoren nur speichern und verwenden, um hochdimensionale Wortvektoren zu erstellen und so eine effektive Parameterreduzierung zu erreichen. Wenn beispielsweise r = 2 und n = 3 ist, kann ein Wortvektor mit einer Dimension von 512 durch zwei Gruppen von drei niedrigdimensionalen Vektortensorprodukten mit einer Dimension von 8 in jeder Gruppe erhalten werden Anzahl der Parameter wird von 512 auf 48 reduziert.
03 Morphologie-verbesserte Tensorwort-Einbettungskomprimierungsdarstellung
Durch das Tensorprodukt kann Word2ket eine offensichtliche Parameterkomprimierung erreichen. Bei komplexeren Aufgaben wie Hochleistungskomprimierung und Maschinen ist es jedoch normalerweise schwierig, eine Vorkomprimierungsleistung zu erzielen Übersetzung. Wirkung. Da niedrigdimensionale Vektoren die Grundeinheiten sind, aus denen Verschränkungstensoren bestehen, und Morpheme die Grundeinheiten sind, aus denen Wörter bestehen. Diese Studie befasst sich mit der Einführung sprachlicher Kenntnisse und schlägt MorphTE vor, das niedrigdimensionale Morphemvektoren trainiert und das Tensorprodukt der im Wort enthaltenen Morphemvektoren verwendet, um die entsprechende Worteinbettungsdarstellung zu erstellen.
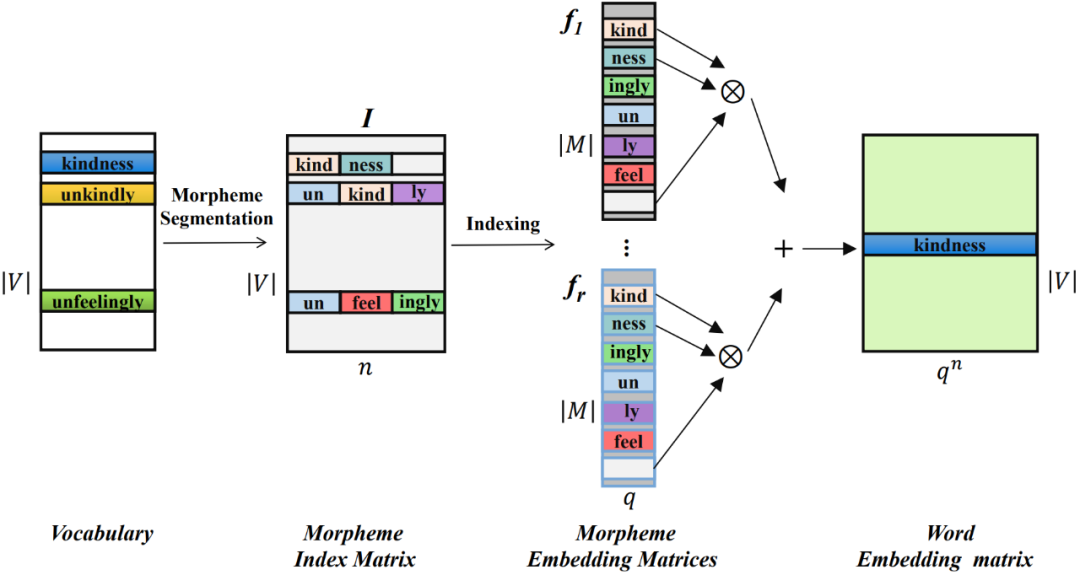
Insbesondere verwenden Sie zunächst das Morphem-Segmentierungstool, um die Wörter in der Vokabelliste V zu segmentieren. Die Morpheme aller Wörter bilden eine Morphemliste M, und die Anzahl der Morpheme ist deutlich geringer als die Anzahl von Wörtern ( ).
Konstruieren Sie für jedes Wort seinen Morphem-Indexvektor, der auf die Position des in jedem Wort enthaltenen Morphems in der Morphemtabelle zeigt. Die Morphem-Indexvektoren aller Wörter bilden eine Morphem-Indexmatrix von 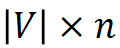 , wobei n die Ordnung von MorphTE ist.
, wobei n die Ordnung von MorphTE ist.
Für das j-te Wort 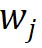 im Vokabular verwenden Sie seinen Morphem-Indexvektor #🎜🎜 ## 🎜🎜# Indexieren Sie den entsprechenden Morphemvektor aus r Gruppen parametrisierter Morphemeinbettungsmatrizen und führen Sie eine verschränkte Tensordarstellung durch Tensorprodukt durch, um die entsprechende Worteinbettung zu erhalten:
im Vokabular verwenden Sie seinen Morphem-Indexvektor #🎜🎜 ## 🎜🎜# Indexieren Sie den entsprechenden Morphemvektor aus r Gruppen parametrisierter Morphemeinbettungsmatrizen und führen Sie eine verschränkte Tensordarstellung durch Tensorprodukt durch, um die entsprechende Worteinbettung zu erhalten: 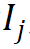 #🎜 🎜##🎜🎜 #
#🎜 🎜##🎜🎜 #
Auf die oben beschriebene Weise kann MophTE morphembasiertes sprachliches Vorwissen in die Worteinbettungsdarstellung injizieren, während die Morphemvektoren in verschiedenen Teilen zwischen Wörtern explizit verwendet werden können Bauen Sie Verbindungen zwischen Wörtern auf. Darüber hinaus sind die Anzahl und Vektordimensionen von Morphemen viel geringer als die Größe und Dimension des Vokabulars, und MophTE erreicht eine Komprimierung der Worteinbettungsparameter aus beiden Perspektiven. Daher ist MophTE in der Lage, eine qualitativ hochwertige Komprimierung von Worteinbettungsdarstellungen zu erreichen. 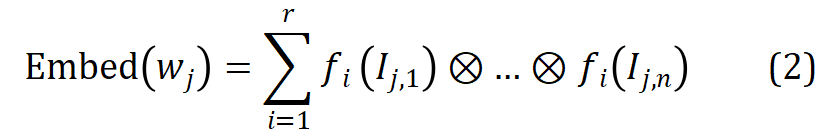
Experiment
In diesem Artikel werden hauptsächlich Experimente zu Übersetzungs-, Frage- und Antwortaufgaben in verschiedenen Sprachen und zugehörigen Worteinbettungen basierend auf Zerlegungs- und Komprimierungsmethoden durchgeführt werden verglichen.
Wie Sie der Tabelle entnehmen können, kann sich MorphTE an verschiedene Sprachen wie Englisch, Deutsch, Italienisch usw. Bei einem Komprimierungsverhältnis von mehr als dem 20-fachen ist MorphTE in der Lage, die Wirkung des Originalmodells beizubehalten, während bei fast allen anderen Komprimierungsmethoden eine Wirkungsabnahme zu verzeichnen ist. Darüber hinaus schneidet MorphTE mit einem Komprimierungsverhältnis von mehr als dem 40-fachen bei verschiedenen Datensätzen besser ab als andere Komprimierungsmethoden. #?? 38-faches Komprimierungsverhältnis unter Beibehaltung der Wirkung des Modells. 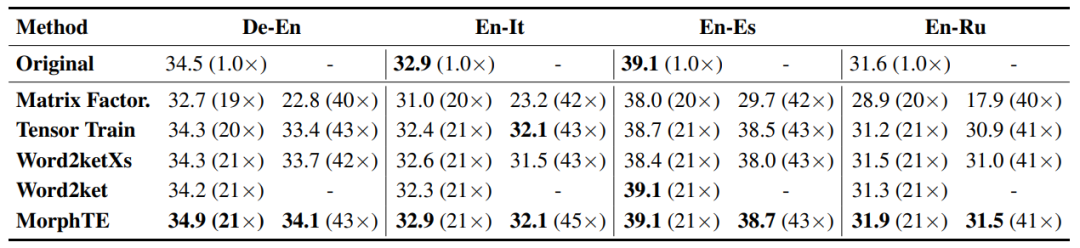
Fazit
MorphTE kombiniert a priori morphologische Sprachkenntnisse und die leistungsstarke Komprimierungsfähigkeit von Tensorprodukten, um eine qualitativ hochwertige Komprimierung von Worteinbettungen zu erreichen. Experimente mit verschiedenen Sprachen und Aufgaben zeigen, dass MorphTE eine 20- bis 80-fache Komprimierung der Worteinbettungsparameter erreichen kann, ohne die Wirkung des Modells zu beeinträchtigen. Dies bestätigt, dass die Einführung von morphembasiertem Sprachwissen das Erlernen komprimierter Darstellungen von Worteinbettungen verbessern kann. Obwohl MorphTE derzeit nur Morpheme modelliert, kann es tatsächlich zu einem allgemeinen Framework zur Verbesserung der Worteinbettungskomprimierung erweitert werden, das explizit mehr apriorisches linguistisches Wissen wie Prototypen, Wortarten, Groß- und Kleinschreibung usw. modelliert, um die Worteinbettungskomprimierung weiter zu verbessern.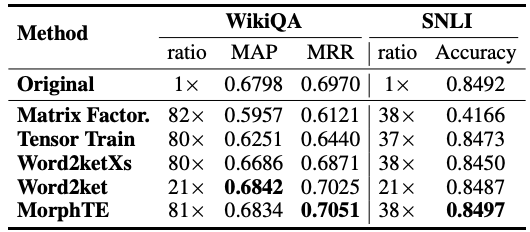
Das obige ist der detaillierte Inhalt vonStellt die Worteinbettung einen zu großen Anteil an Parametern dar? MorphTE-Methode 20-facher Komprimierungseffekt ohne Verlust. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 So schreiben Sie einen Roman in der Tomato Free Novel-App. Teilen Sie das Tutorial zum Schreiben eines Romans in der Tomato Novel-App
Mar 28, 2024 pm 12:50 PM
So schreiben Sie einen Roman in der Tomato Free Novel-App. Teilen Sie das Tutorial zum Schreiben eines Romans in der Tomato Novel-App
Mar 28, 2024 pm 12:50 PM
Tomato Novel ist eine sehr beliebte Roman-Lesesoftware. Jeder Roman und Comic ist sehr interessant und möchte auch Romane schreiben Also, wie schreiben wir den Roman darin? Meine Freunde wissen es nicht, also lasst uns gemeinsam auf diese Seite gehen und uns eine Einführung zum Schreiben eines Romans ansehen. Teilen Sie das Tomato-Roman-Tutorial zum Schreiben eines Romans. 1. Öffnen Sie zunächst die kostenlose Tomato-Roman-App auf Ihrem Mobiltelefon und klicken Sie auf „Personal Center – Writer Center“. 2. Gehen Sie zur Seite „Tomato Writer Assistant“ – klicken Sie auf „Neues Buch erstellen“. am Ende des Romans.
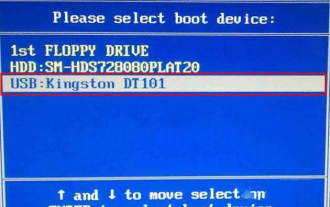 Wie rufe ich das BIOS auf dem Colorful-Motherboard auf? Bringen Sie Ihnen zwei Methoden bei
Mar 13, 2024 pm 06:01 PM
Wie rufe ich das BIOS auf dem Colorful-Motherboard auf? Bringen Sie Ihnen zwei Methoden bei
Mar 13, 2024 pm 06:01 PM
Colorful-Motherboards erfreuen sich auf dem chinesischen Inlandsmarkt großer Beliebtheit und Marktanteil, aber einige Benutzer von Colorful-Motherboards wissen immer noch nicht, wie sie im BIOS Einstellungen vornehmen sollen? Als Reaktion auf diese Situation hat Ihnen der Herausgeber speziell zwei Methoden zum Aufrufen des farbenfrohen Motherboard-BIOS vorgestellt. Kommen Sie und probieren Sie es aus! Methode 1: Verwenden Sie die U-Disk-Start-Tastenkombination, um das U-Disk-Installationssystem direkt aufzurufen. Die Tastenkombination für das Colorful-Motherboard zum Starten der U-Disk ist zunächst ESC oder F11, um ein Black zu erstellen Wenn Sie den Startbildschirm sehen, drücken Sie kontinuierlich die ESC- oder F11-Taste auf der Tastatur, um ein Fenster zur Auswahl der Startelementsequenz aufzurufen. Bewegen Sie den Cursor an die Stelle, an der „USB“ angezeigt wird " wird angezeigt, und dann
 So stellen Sie gelöschte Kontakte auf WeChat wieder her (ein einfaches Tutorial erklärt Ihnen, wie Sie gelöschte Kontakte wiederherstellen)
May 01, 2024 pm 12:01 PM
So stellen Sie gelöschte Kontakte auf WeChat wieder her (ein einfaches Tutorial erklärt Ihnen, wie Sie gelöschte Kontakte wiederherstellen)
May 01, 2024 pm 12:01 PM
Leider löschen Menschen aus bestimmten Gründen oft versehentlich bestimmte Kontakte. WeChat ist eine weit verbreitete soziale Software. Um Benutzern bei der Lösung dieses Problems zu helfen, wird in diesem Artikel erläutert, wie gelöschte Kontakte auf einfache Weise wiederhergestellt werden können. 1. Verstehen Sie den WeChat-Kontaktlöschmechanismus. Dies bietet uns die Möglichkeit, gelöschte Kontakte wiederherzustellen. Der Kontaktlöschmechanismus in WeChat entfernt sie aus dem Adressbuch, löscht sie jedoch nicht vollständig. 2. Nutzen Sie die integrierte „Kontaktbuch-Wiederherstellung“-Funktion von WeChat, um Zeit und Energie zu sparen. Mit dieser Funktion können Benutzer schnell gelöschte Kontakte wiederherstellen. 3. Rufen Sie die WeChat-Einstellungsseite auf und klicken Sie auf die untere rechte Ecke, öffnen Sie die WeChat-Anwendung „Me“ und klicken Sie auf das Einstellungssymbol in der oberen rechten Ecke, um die Einstellungsseite aufzurufen.
 So stellen Sie die Schriftgröße auf dem Mobiltelefon ein (Schriftgröße auf dem Mobiltelefon einfach anpassen)
May 07, 2024 pm 03:34 PM
So stellen Sie die Schriftgröße auf dem Mobiltelefon ein (Schriftgröße auf dem Mobiltelefon einfach anpassen)
May 07, 2024 pm 03:34 PM
Das Festlegen der Schriftgröße ist zu einer wichtigen Personalisierungsanforderung geworden, da Mobiltelefone zu einem wichtigen Werkzeug im täglichen Leben der Menschen geworden sind. Um den Bedürfnissen verschiedener Benutzer gerecht zu werden, wird in diesem Artikel erläutert, wie Sie das Nutzungserlebnis Ihres Mobiltelefons verbessern und die Schriftgröße des Mobiltelefons durch einfache Vorgänge anpassen können. Warum müssen Sie die Schriftgröße Ihres Mobiltelefons anpassen? Durch Anpassen der Schriftgröße kann der Text klarer und leichter lesbar werden. Geeignet für die Lesebedürfnisse von Benutzern unterschiedlichen Alters. Praktisch für Benutzer mit Sehbehinderung, die Schriftgröße zu verwenden Einstellungsfunktion des Mobiltelefonsystems – So rufen Sie die Systemeinstellungsoberfläche auf – Suchen und geben Sie die Option „Anzeige“ in der Einstellungsoberfläche ein – suchen Sie die Option „Schriftgröße“ und passen Sie sie mit einem Drittanbieter an Anwendung – Laden Sie eine Anwendung herunter und installieren Sie sie, die die Anpassung der Schriftgröße unterstützt – öffnen Sie die Anwendung und rufen Sie die entsprechende Einstellungsoberfläche auf – je nach Person
 Zusammenfassung der Methoden zum Erhalten von Administratorrechten in Win11
Mar 09, 2024 am 08:45 AM
Zusammenfassung der Methoden zum Erhalten von Administratorrechten in Win11
Mar 09, 2024 am 08:45 AM
Eine Zusammenfassung, wie Sie Win11-Administratorrechte erhalten. Im Betriebssystem Windows 11 sind Administratorrechte eine der sehr wichtigen Berechtigungen, die es Benutzern ermöglichen, verschiedene Vorgänge auf dem System auszuführen. Manchmal benötigen wir möglicherweise Administratorrechte, um einige Vorgänge abzuschließen, z. B. die Installation von Software, das Ändern von Systemeinstellungen usw. Im Folgenden werden einige Methoden zum Erhalten von Win11-Administratorrechten zusammengefasst. Ich hoffe, dass sie Ihnen helfen können. 1. Verwenden Sie Tastenkombinationen. Im Windows 11-System können Sie die Eingabeaufforderung schnell über Tastenkombinationen öffnen.
 Das Geheimnis des Ausbrütens mobiler Dracheneier wird gelüftet (Schritt für Schritt erfahren Sie, wie Sie mobile Dracheneier erfolgreich ausbrüten)
May 04, 2024 pm 06:01 PM
Das Geheimnis des Ausbrütens mobiler Dracheneier wird gelüftet (Schritt für Schritt erfahren Sie, wie Sie mobile Dracheneier erfolgreich ausbrüten)
May 04, 2024 pm 06:01 PM
Mobile Spiele sind mit der Entwicklung der Technologie zu einem festen Bestandteil des Lebens der Menschen geworden. Mit seinem niedlichen Drachenei-Bild und dem interessanten Schlüpfvorgang hat es die Aufmerksamkeit vieler Spieler auf sich gezogen, und eines der Spiele, das viel Aufmerksamkeit erregt hat, ist die mobile Version von Dragon Egg. Um den Spielern dabei zu helfen, ihre eigenen Drachen im Spiel besser zu kultivieren und zu züchten, erfahren Sie in diesem Artikel, wie Sie Dracheneier in der mobilen Version ausbrüten. 1. Wählen Sie den geeigneten Drachenei-Typ aus, der Ihnen gefällt und zu Ihnen passt, basierend auf den verschiedenen Arten von Drachenei-Attributen und -Fähigkeiten, die im Spiel zur Verfügung stehen. 2. Verbessern Sie die Stufe der Brutmaschine, indem Sie Aufgaben erledigen und Requisiten sammeln. Die Stufe der Brutmaschine bestimmt die Schlüpfgeschwindigkeit und die Erfolgsquote beim Schlüpfen. 3. Sammeln Sie die Ressourcen, die die Spieler zum Schlüpfen benötigen
 Detaillierte Erläuterung der Oracle-Versionsabfragemethode
Mar 07, 2024 pm 09:21 PM
Detaillierte Erläuterung der Oracle-Versionsabfragemethode
Mar 07, 2024 pm 09:21 PM
Ausführliche Erläuterung der Oracle-Versionsabfragemethode Oracle ist eines der beliebtesten relationalen Datenbankverwaltungssysteme weltweit. Es bietet umfangreiche Funktionen und leistungsstarke Leistung und wird häufig in Unternehmen eingesetzt. Im Prozess der Datenbankverwaltung und -entwicklung ist es sehr wichtig, die Version der Oracle-Datenbank zu verstehen. In diesem Artikel wird detailliert beschrieben, wie die Versionsinformationen der Oracle-Datenbank abgefragt werden, und es werden spezifische Codebeispiele angegeben. Fragen Sie die Datenbankversion der SQL-Anweisung in der Oracle-Datenbank ab, indem Sie eine einfache SQL-Anweisung ausführen
 Schneller Meister: So eröffnen Sie zwei WeChat-Konten auf Huawei-Handys!
Mar 23, 2024 am 10:42 AM
Schneller Meister: So eröffnen Sie zwei WeChat-Konten auf Huawei-Handys!
Mar 23, 2024 am 10:42 AM
In der heutigen Gesellschaft sind Mobiltelefone zu einem unverzichtbaren Bestandteil unseres Lebens geworden. Als wichtiges Werkzeug für unsere tägliche Kommunikation, Arbeit und unser Leben wird WeChat häufig genutzt. Allerdings kann es bei der Abwicklung unterschiedlicher Transaktionen erforderlich sein, zwei WeChat-Konten zu trennen, was erfordert, dass das Mobiltelefon die gleichzeitige Anmeldung bei zwei WeChat-Konten unterstützt. Als bekannte inländische Marke werden Huawei-Mobiltelefone von vielen Menschen genutzt. Wie können also zwei WeChat-Konten auf Huawei-Mobiltelefonen eröffnet werden? Lassen Sie uns das Geheimnis dieser Methode lüften. Zunächst müssen Sie zwei WeChat-Konten gleichzeitig auf Ihrem Huawei-Mobiltelefon verwenden. Der einfachste Weg ist
