

Vergleichende Analyse von Deep-Learning-Architekturen

Das Konzept des Deep Learning stammt aus der Erforschung künstlicher neuronaler Netze. Ein mehrschichtiges Perzeptron, das mehrere verborgene Schichten enthält, ist eine Deep-Learning-Struktur. Deep Learning kombiniert Funktionen auf niedriger Ebene, um abstraktere Darstellungen auf hoher Ebene zu bilden, um Kategorien oder Merkmale von Daten darzustellen. Es ist in der Lage, verteilte Merkmalsdarstellungen von Daten zu erkennen. Deep Learning ist eine Form des maschinellen Lernens, und maschinelles Lernen ist der einzige Weg, künstliche Intelligenz zu erreichen.
Was sind also die Unterschiede zwischen verschiedenen Deep-Learning-Systemarchitekturen?
1. Vollständig verbundenes Netzwerk (FCN)
Ein vollständig verbundenes Netzwerk (FCN) besteht aus einer Reihe vollständig verbundener Schichten, wobei jedes Neuron in jeder Schicht mit jedem Neuron in einer anderen Schicht verbunden ist. Sein Hauptvorteil besteht darin, dass es „strukturunabhängig“ ist, d. h. es sind keine besonderen Annahmen über die Eingabe erforderlich. Obwohl diese Strukturunabhängigkeit vollständig verbundene Netzwerke sehr breit anwendbar macht, sind solche Netzwerke tendenziell schwächer als spezialisierte Netzwerke, die speziell auf die Struktur des Problemraums abgestimmt sind.
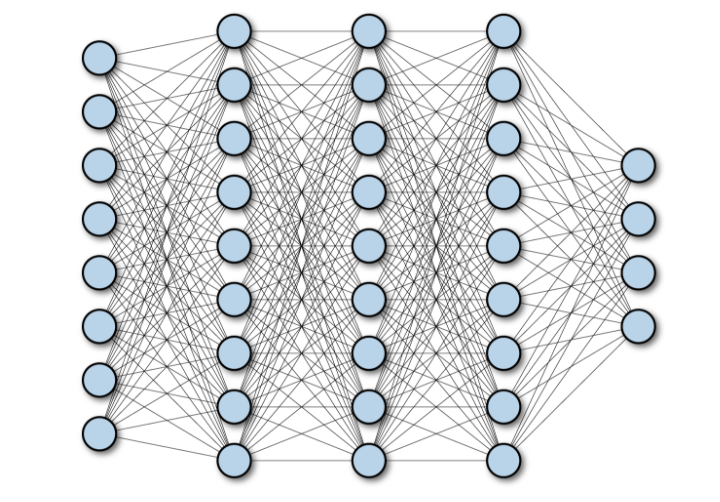
Die folgende Abbildung zeigt ein mehrschichtiges, vollständig verbundenes Netzwerk:
2. Convolutional Neural Network (CNN) ist eine mehrschichtige neuronale Netzwerkarchitektur, die hauptsächlich für Bilder dient Bearbeitung von Anträgen. Die CNN-Architektur geht ausdrücklich davon aus, dass die Eingabe eine räumliche Dimension (und optional eine Tiefendimension) hat, beispielsweise ein Bild, was die Codierung bestimmter Eigenschaften in die Modellarchitektur ermöglicht. Yann LeCun schuf das erste CNN, eine Architektur, die ursprünglich zur Erkennung handgeschriebener Zeichen verwendet wurde.
2.1 Architekturmerkmale von CNN
Aufschlüsseln der technischen Details von Computer-Vision-Modellen mit CNN:
Eingabe des Modells: Die Eingabe des CNN-Modells ist normalerweise ein Bild oder Text. CNNs können auch für Text verwendet werden, werden jedoch normalerweise seltener verwendet.Das Bild wird hier als Raster aus Pixeln dargestellt, bei dem es sich um ein Raster aus positiven ganzen Zahlen handelt, wobei jeder Zahl eine Farbe zugewiesen ist.
Ausgabe des Modells: Die Ausgabe des Modells hängt davon ab, was es vorherzusagen versucht. Die folgenden Beispiele stellen einige häufige Aufgaben dar:-
 Ein einfaches Faltungs-Neuronales Netzwerk besteht aus einer Reihe von Schichten, jede Schicht wandelt ein aktiviertes Volumen über eine differenzierbare Funktion in eine andere Darstellung um. Die Architektur eines Faltungs-Neuronalen Netzwerks verwendet hauptsächlich drei Arten von Schichten: Faltungsschichten, Pooling-Schichten und vollständig verbundene Schichten. Das Bild unten zeigt die verschiedenen Teile einer Faltungsschicht eines neuronalen Netzwerks:
Ein einfaches Faltungs-Neuronales Netzwerk besteht aus einer Reihe von Schichten, jede Schicht wandelt ein aktiviertes Volumen über eine differenzierbare Funktion in eine andere Darstellung um. Die Architektur eines Faltungs-Neuronalen Netzwerks verwendet hauptsächlich drei Arten von Schichten: Faltungsschichten, Pooling-Schichten und vollständig verbundene Schichten. Das Bild unten zeigt die verschiedenen Teile einer Faltungsschicht eines neuronalen Netzwerks:
- Nichtlinearität: Dies ist die auf den Faltungsfilter angewendete Gleichung, die es dem CNN ermöglicht, komplexe Beziehungen zwischen Eingabe- und Ausgabebildern zu lernen.
- Pooling: Auch als „Max-Pooling“ bekannt, wählt es nur die größte Zahl aus einer Reihe von Zahlen aus. Dies trägt dazu bei, die Größe des Ausdrucks zu reduzieren und die Anzahl der Berechnungen zu reduzieren, die das CNN durchführen muss, wodurch die Effizienz verbessert wird.
- Die Kombination dieser drei Operationen bildet ein vollständig Faltungsnetzwerk.
2.2 Anwendungsfälle von CNN
CNN (Convolutional Neural Network) ist eine Art neuronales Netzwerk, das häufig zur Lösung von Problemen im Zusammenhang mit räumlichen Daten verwendet wird, normalerweise in Bereichen wie Bildern (2D CNN) und Audio (1D CNN). Das breite Anwendungsspektrum von CNN umfasst Gesichtserkennung, medizinische Analyse und Klassifizierung usw. Durch CNN können detailliertere Merkmale in Bild- oder Audiodaten erfasst werden, wodurch eine genauere Erkennung und Analyse erreicht wird. Darüber hinaus kann CNN auch auf andere Bereiche angewendet werden, beispielsweise auf die Verarbeitung natürlicher Sprache und Zeitreihendaten. Kurz gesagt: CNN kann uns helfen, verschiedene Arten von Daten besser zu verstehen und zu analysieren. 2.3 Vorteile von CNN gegenüber FCN
Für ein vollständig verbundenes neuronales Netzwerk gibt es eine Eingabe mit der Form (Hin×Win×Cin) und eine Ausgabe mit der Form (Hout×Wout×Cout). Dies bedeutet, dass jede Pixelfarbe des Ausgabemerkmals mit jeder Pixelfarbe des Eingabemerkmals verbunden ist. Für jedes Pixel der Eingabe- und Ausgabebilder gibt es einen unabhängigen lernbaren Parameter. Daher beträgt die Anzahl der Parameter (Hin×Hout×Win×Wout×Cin×Cout).
In der Faltungsschicht ist die Eingabe ein Bild der Form (Hin, Win, Cin), und die Gewichte berücksichtigen die Nachbarschaftsgröße des gegebenen Pixels als K×K. Die Ausgabe ist die gewichtete Summe eines bestimmten Pixels und seiner Nachbarn. Für jedes Paar (Cin, Cout) von Eingangs- und Ausgangskanälen gibt es einen separaten Kernel, aber die Gewichte des Kernels sind ortsunabhängige Tensoren der Form (K, K, Cin, Cout). Tatsächlich kann diese Ebene Bilder jeder Auflösung akzeptieren, während vollständig verbundene Ebenen nur feste Auflösungen verwenden können. Schließlich sind die Schichtparameter (K, K, Cin, Cout). Für den Fall, dass die Kernelgröße K viel kleiner als die Eingabeauflösung ist, wird die Anzahl der Variablen erheblich reduziert.
Seitdem AlexNet den ImageNet-Wettbewerb gewonnen hat, beweist die Tatsache, dass jedes siegreiche neuronale Netzwerk eine CNN-Komponente verwendet hat, dass CNN für Bilddaten effektiver ist. Es ist sehr wahrscheinlich, dass Sie keinen aussagekräftigen Vergleich finden, da es nicht möglich ist, nur FC-Ebenen zur Verarbeitung von Bilddaten zu verwenden, während CNN diese Daten verarbeiten kann. Warum?
Die Anzahl der Gewichte mit 1000 Neuronen in der FC-Schicht beträgt etwa 150 Millionen für ein Bild. Dies ist lediglich die Anzahl der Gewichte für eine Ebene. Moderne CNN-Architekturen verfügen über 50–100 Schichten mit insgesamt Hunderttausenden Parametern (z. B. hat ResNet50 23 Millionen Parameter, Inception V3 hat 21 Millionen Parameter).
Aus mathematischer Sicht vergleicht man die Anzahl der Gewichtungen zwischen CNN und FCN (mit 100 versteckten Einheiten), wenn das Eingabebild 500×500×3 ist:
- Wx der FC-Schicht = 100×(500×500 × 3)=100×750000=75M
- CNN-Schicht =
<code>((shape of width of the filter * shape of height of the filter * number of filters in the previous layer+1)*number of filters)( +1 是为了偏置) = (Fw×Fh×D+1)×F=(5×5×3+1)∗2=152</code>
Übersetzungsinvarianz
Invarianz bedeutet, dass ein Objekt auch dann noch korrekt erkannt werden kann, wenn sich seine Position ändert. Dies ist normalerweise eine positive Eigenschaft, da dadurch die Identität (oder Kategorie) des Objekts erhalten bleibt. „Übersetzung“ hat hier eine spezifische Bedeutung in der Geometrie. Das Bild unten zeigt dasselbe Objekt an verschiedenen Orten. Aufgrund der Übersetzungsinvarianz kann CNN korrekt identifizieren, dass es sich bei beiden um Katzen handelt.
3. Recurrent Neural Network (RNN)
RNN ist eine der grundlegenden Netzwerkarchitekturen, auf denen andere Deep-Learning-Architekturen aufbauen. Ein wesentlicher Unterschied besteht darin, dass RNNs im Gegensatz zu normalen Feedforward-Netzwerken über Verbindungen verfügen können, die eine Rückkopplung zu ihrer vorherigen oder derselben Schicht ermöglichen. RNN verfügt gewissermaßen über ein „Gedächtnis“ früherer Berechnungen und nutzt diese Informationen für die aktuelle Verarbeitung.
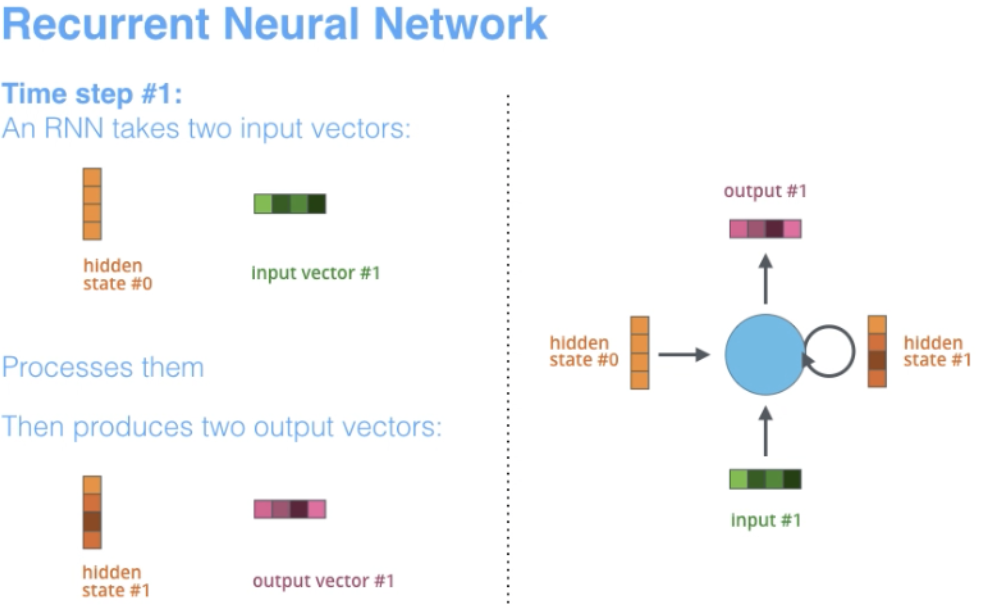
3.1 Architekturmerkmale von RNN
Der Begriff „Wiederkehrend“ wird verwendet, wenn das Netzwerk auf jeder Sequenzinstanz dieselbe Aufgabe ausführt, sodass die Ausgabe von vorherigen Berechnungen und Ergebnissen abhängt.
RNN eignet sich natürlich für viele NLP-Aufgaben, wie zum Beispiel die Sprachmodellierung. Sie sind in der Lage, den Bedeutungsunterschied zwischen „Hund“ und „Hot Dog“ zu erfassen, sodass RNNs speziell für die Modellierung dieser Art von Kontextabhängigkeit in Sprachen und ähnlichen Sequenzmodellierungsaufgaben geeignet sind, was den Einsatz von RNNs in diesen Bereichen sinnvoller macht als Der Hauptgrund für CNN. Ein weiterer Vorteil von RNN besteht darin, dass die Modellgröße nicht mit der Eingabegröße zunimmt, sodass Eingaben beliebiger Länge verarbeitet werden können.
Darüber hinaus verfügt RNN im Gegensatz zu CNN über flexible Rechenschritte, bietet bessere Modellierungsmöglichkeiten und schafft die Möglichkeit, unbegrenzten Kontext zu erfassen, da es historische Informationen berücksichtigt und seine Gewichtungen im Laufe der Zeit geteilt werden. Allerdings leiden rekurrente neuronale Netze unter dem Problem des verschwindenden Gradienten. Der Gradient wird sehr klein, wodurch die Aktualisierungsgewichte der Backpropagation sehr klein werden. Aufgrund der für jedes Etikett erforderlichen sequentiellen Verarbeitung und des Vorhandenseins verschwindender/explodierender Gradienten ist das RNN-Training langsam und manchmal schwierig zu konvergieren.
Das Bild unten von der Stanford University ist ein Beispiel für RNN-Architektur.
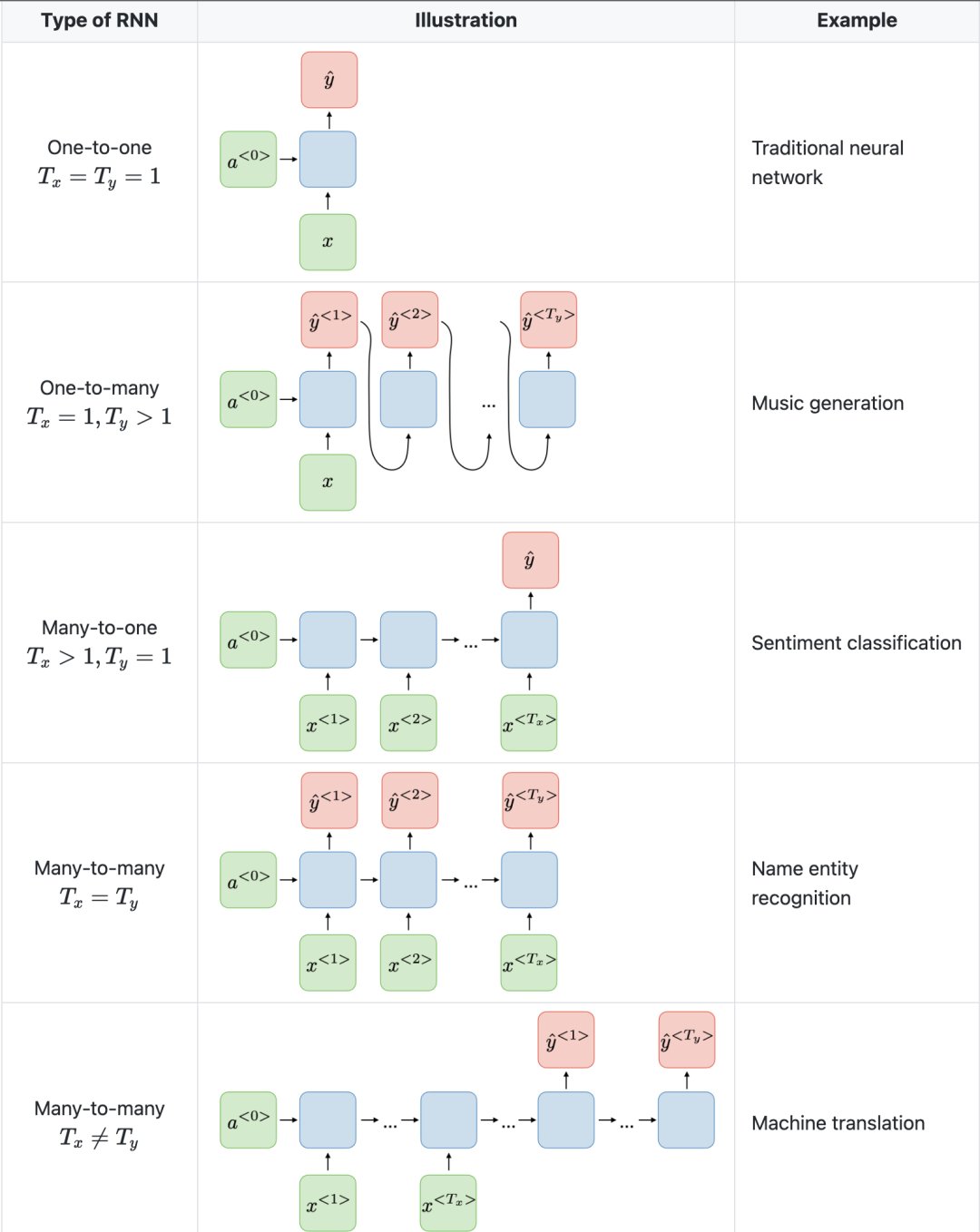
Zu beachten ist auch, dass CNN und RNN unterschiedliche Architekturen haben. CNN ist ein Feed-Forward-Neuronales Netzwerk, das Filter und Pooling-Schichten verwendet, während RNN die Ergebnisse durch Autoregression zurück in das Netzwerk einspeist.
3.2 Typische Anwendungsfälle von RNN
RNN ist ein neuronales Netzwerk, das speziell für die Analyse von Zeitreihendaten entwickelt wurde. Dabei beziehen sich Zeitreihendaten auf Daten, die in zeitlicher Reihenfolge angeordnet sind, z. B. Text oder Video. RNN hat breite Anwendungsmöglichkeiten in der Textübersetzung, der Verarbeitung natürlicher Sprache, der Stimmungsanalyse und der Sprachanalyse. Beispielsweise können damit Audioaufnahmen analysiert werden, um die Rede des Sprechers zu identifizieren und in Text umzuwandeln. Darüber hinaus können RNNs auch zur Textgenerierung verwendet werden, beispielsweise zum Erstellen von Texten für E-Mails oder Social-Media-Beiträge.
3.3 Komparative Vorteile von RNN und CNN
In CNN sind die Eingabe- und Ausgabegrößen festgelegt. Dies bedeutet, dass CNN ein Bild mit fester Größe nimmt und es zusammen mit der Zuverlässigkeit seiner Vorhersage auf der entsprechenden Ebene ausgibt. Bei RNN können die Eingabe- und Ausgabegrößen jedoch variieren. Diese Funktion ist nützlich für Anwendungen, die eine Ein- und Ausgabe variabler Größe erfordern, z. B. die Generierung von Text.
Sowohl Gated Recurrent Units (GRU) als auch Long Short-Term Memory Units (LSTM) bieten Lösungen für das Problem des verschwindenden Gradienten, das bei Recurrent Neural Networks (RNN) auftritt.
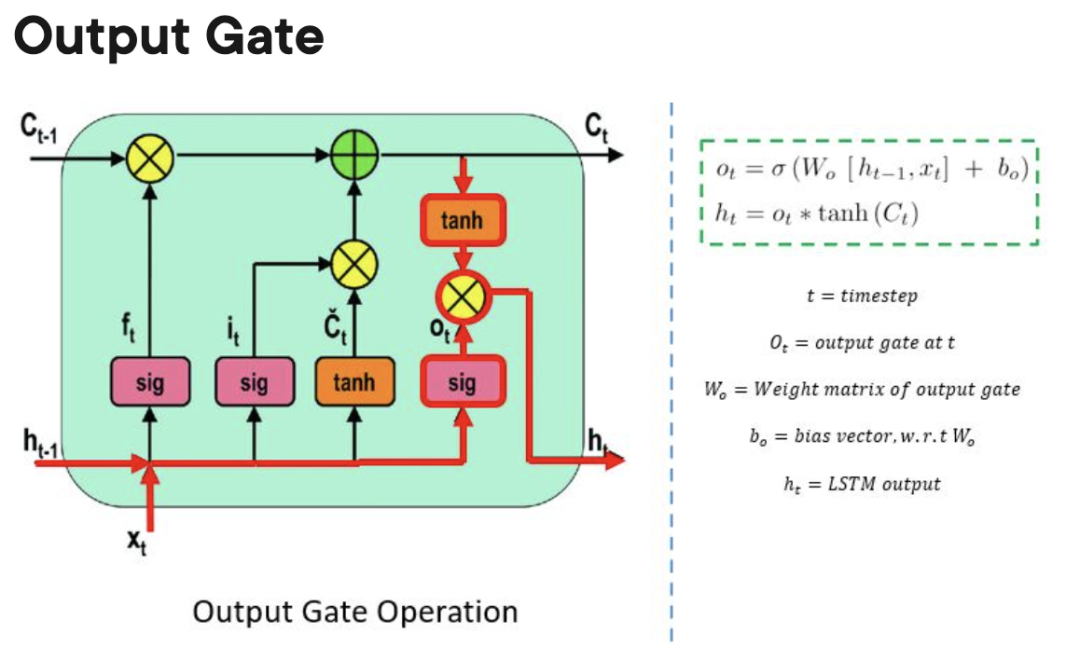
4. Long Short Memory Neural Network (LSTM)
Long Short Memory Neural Network (LSTM) ist eine spezielle Art von RNN. Es erleichtert RNNs die Speicherung von Informationen über viele Zeitstempel hinweg, indem es langfristige Abhängigkeiten lernt. Die folgende Abbildung ist eine visuelle Darstellung der LSTM-Architektur.
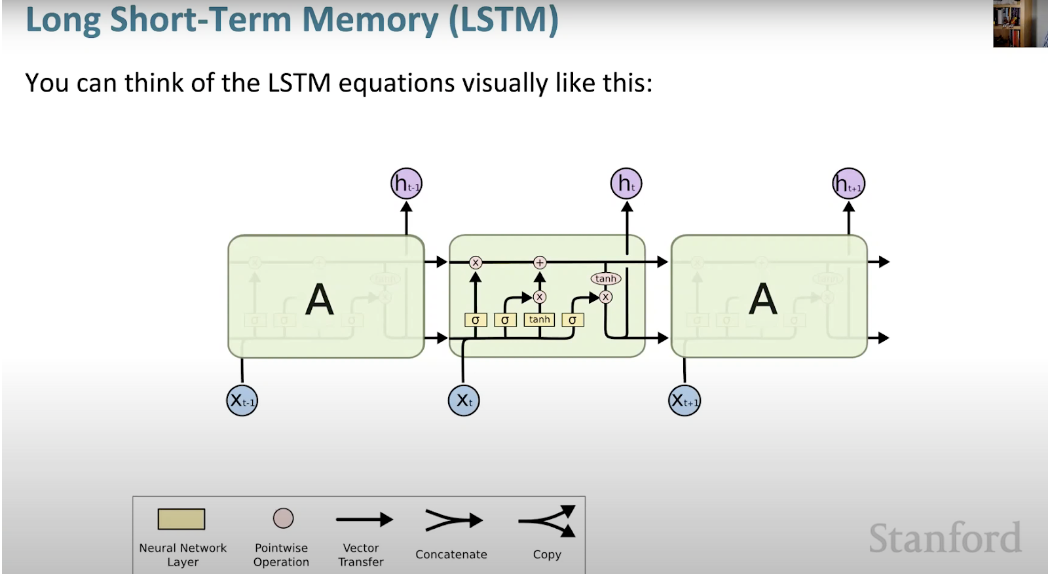
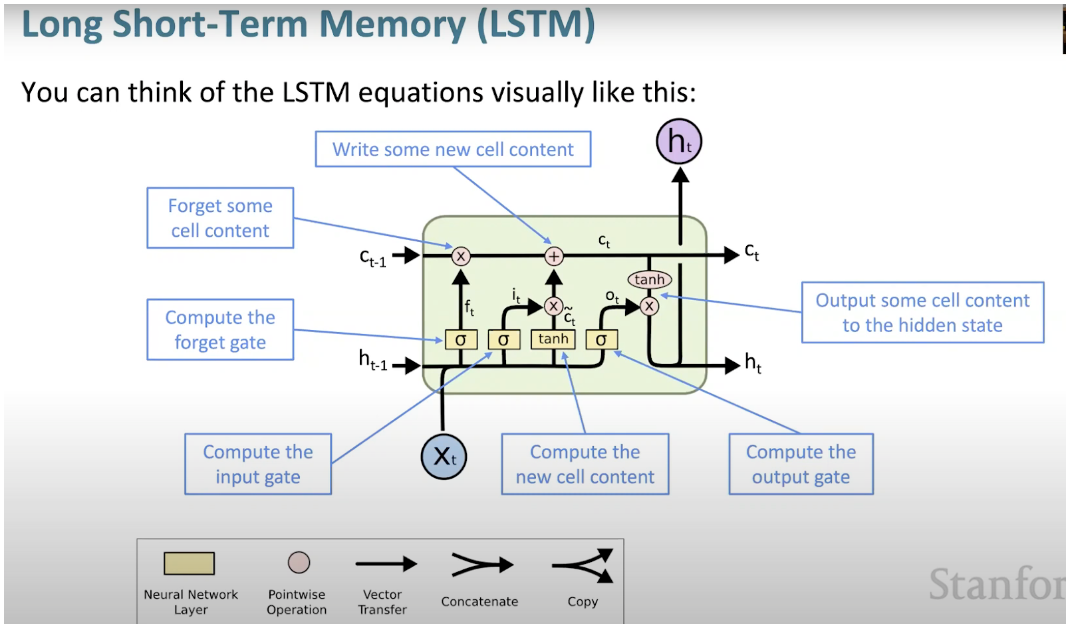
LSTM ist überall und in vielen Anwendungen oder Produkten, wie zum Beispiel Smartphones, zu finden. Seine Stärke liegt darin, dass es sich von der typischen neuronenbasierten Architektur entfernt und stattdessen das Konzept von Speichereinheiten übernimmt. Diese Speichereinheit behält ihren Wert entsprechend der Funktion ihrer Eingabe und kann ihren Wert für kurze oder lange Zeit halten. Dadurch kann sich das Gerät wichtige Dinge merken, nicht nur den zuletzt berechneten Wert.
Die LSTM-Speicherzelle enthält drei Tore, die den Zu- oder Abfluss von Informationen innerhalb ihrer Zelle steuern.
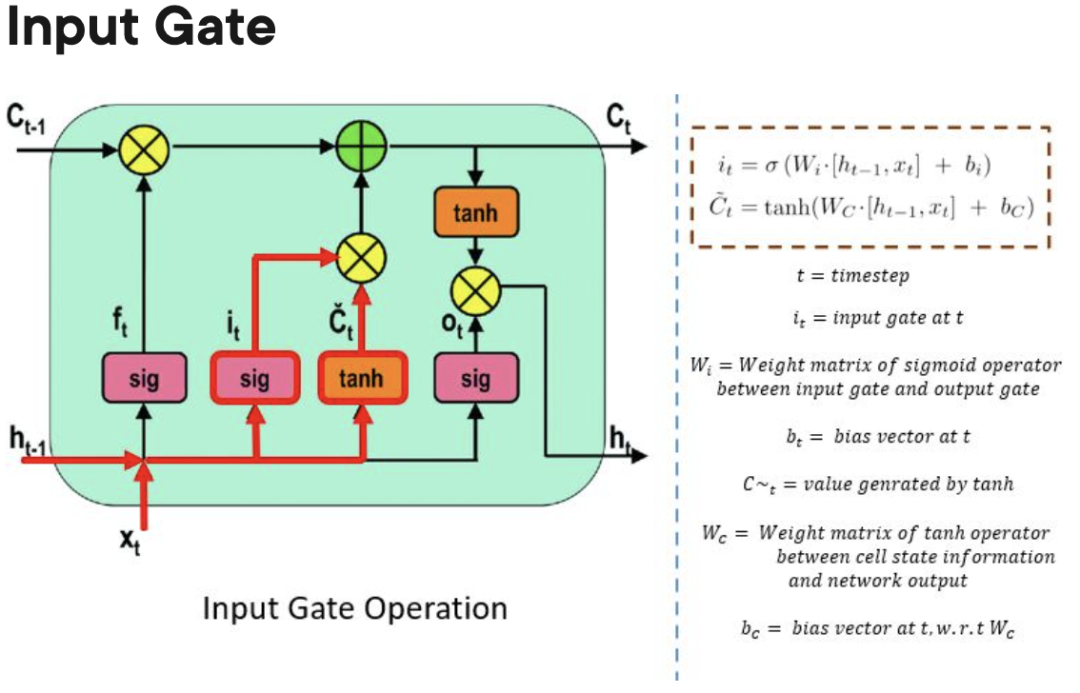
- Input Gate: Steuert, wann Informationen in den Speicher fließen können.
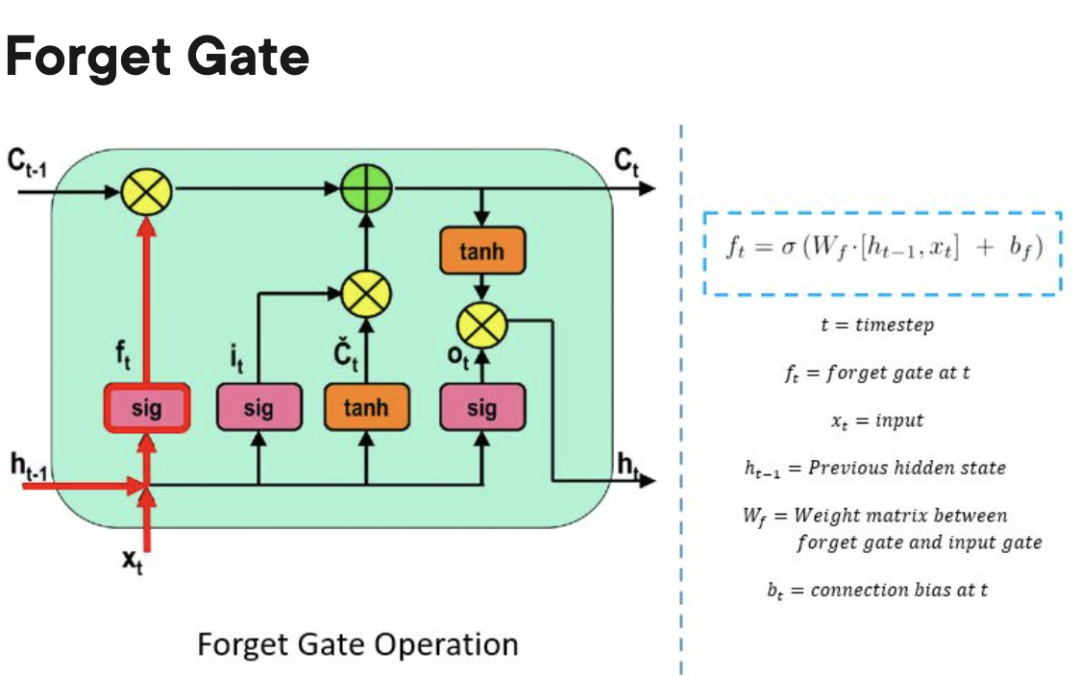
Forgetting Gate: Verantwortlich für die Verfolgung, welche Informationen „vergessen“ werden können, um Platz für die Verarbeitungseinheit zu schaffen, um sich neue Daten zu merken.
Output Gate: Bestimmt, wann die in der Verarbeitungseinheit gespeicherten Informationen als Ausgabe der Zelle verwendet werden können.
Vor- und Nachteile von LSTM im Vergleich zu GRU und RNN
Im Vergleich zu GRU und insbesondere RNN kann LSTM längerfristige Abhängigkeiten lernen. Da es drei Tore gibt (zwei in GRU und null in RNN), verfügt LSTM im Vergleich zu RNN und GRU über mehr Parameter. Diese zusätzlichen Parameter ermöglichen es dem LSTM-Modell, komplexe Sequenzdaten wie natürliche Sprache oder Zeitreihendaten besser zu verarbeiten. Darüber hinaus können LSTMs auch Eingabesequenzen variabler Länge verarbeiten, da ihre Gate-Struktur es ihnen ermöglicht, unnötige Eingaben zu ignorieren. Daher schneidet LSTM in vielen Anwendungen gut ab, darunter Spracherkennung, maschinelle Übersetzung und Börsenprognosen.
5. Gated Recurrent Unit (GRU)
GRU verfügt über zwei Tore: Update-Gate und Reset-Gate (im Wesentlichen zwei Vektoren), um zu entscheiden, welche Informationen an den Ausgang übergeben werden sollen.
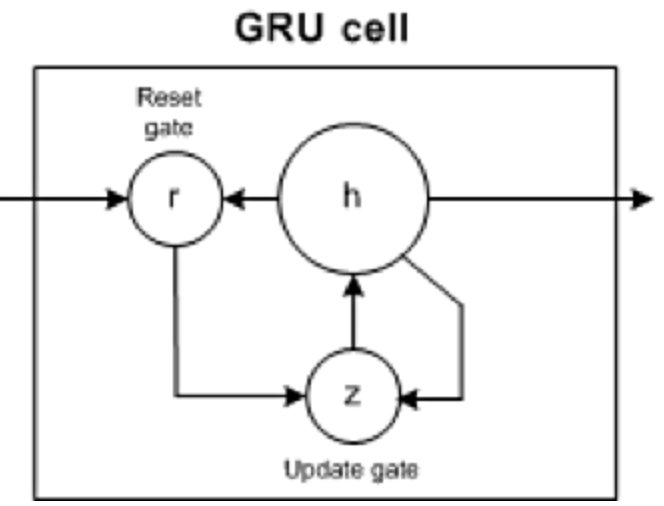
- Gate zurücksetzen: Hilft dem Modell bei der Entscheidung, wie viele vergangene Informationen es vergessen kann.
- Update-Gate: Hilft dem Modell zu bestimmen, wie viele vergangene Informationen (vorherige Zeitschritte) an die Zukunft weitergegeben werden müssen.
GRU vergleicht die Vor- und Nachteile von LSTM und RNN
Ähnlich wie RNN ist GRU auch ein wiederkehrendes neuronales Netzwerk, das Informationen effektiv über einen langen Zeitraum speichern und längere Abhängigkeiten erfassen kann als RNN. GRU ist jedoch einfacher und schneller zu trainieren als LSTM.
Obwohl GRU in der Implementierung komplexer ist als RNN, da es nur zwei Gating-Mechanismen enthält, verfügt es über eine geringere Anzahl von Parametern und kann im Allgemeinen keine Abhängigkeiten mit größerer Reichweite wie LSTM erfassen. Daher benötigt GRU in einigen Fällen möglicherweise mehr Trainingsdaten, um das gleiche Leistungsniveau wie LSTM zu erreichen.
Da GRU außerdem relativ einfach ist und der Rechenaufwand niedrig ist, kann es sinnvoller sein, GRU in Umgebungen mit begrenzten Ressourcen wie mobilen Geräten oder eingebetteten Systemen zu verwenden. Wenn andererseits die Genauigkeit des Modells für die Anwendung von entscheidender Bedeutung ist, ist LSTM möglicherweise die bessere Wahl.
6.Transformer
Der Artikel über Transformers „Attention is All You Need“ ist fast der Artikel Nummer eins aller Zeiten auf Arxiv. Transformer ist ein großes Encoder-Decoder-Modell, das mithilfe komplexer Aufmerksamkeitsmechanismen ganze Sequenzen verarbeiten kann.
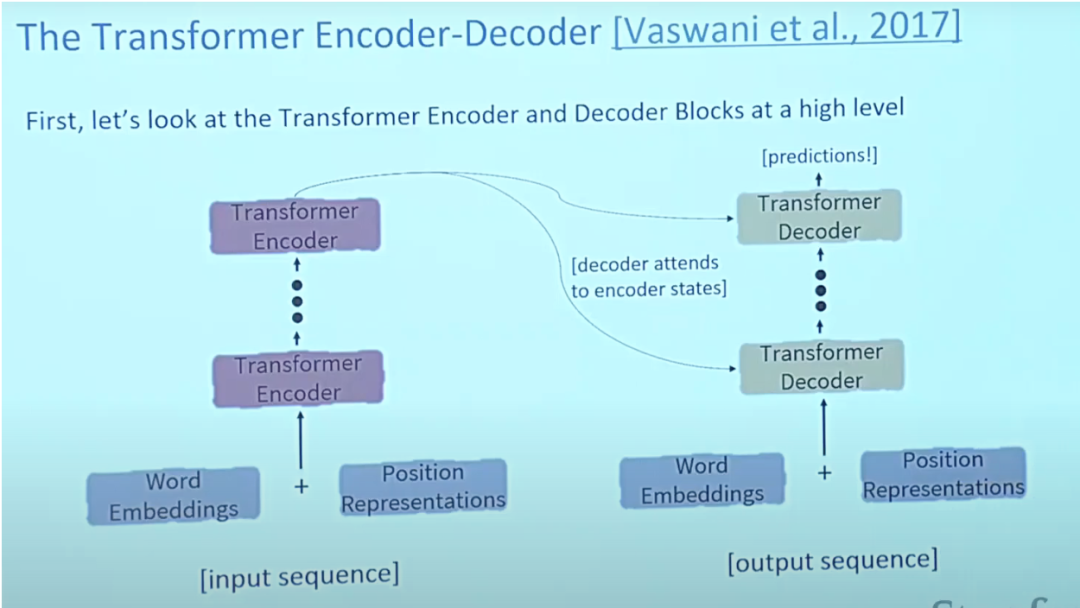
Typischerweise wird in Anwendungen zur Verarbeitung natürlicher Sprache jedes Eingabewort zunächst mithilfe eines Einbettungsalgorithmus in einen Vektor umgewandelt. Die Einbettung erfolgt nur im Encoder der untersten Ebene. Die Abstraktion, die allen Encodern gemeinsam ist, besteht darin, dass sie eine Liste von Vektoren der Größe 512 erhalten, bei denen es sich um die Worteinbettungen handelt, bei anderen Encodern jedoch direkt unter der Encoderausgabe.
Aufmerksamkeit bietet eine Lösung für das Engpassproblem. Bei dieser Art von Modellen stellen Kontextvektoren einen Flaschenhals dar, der es dem Modell erschwert, mit langen Sätzen umzugehen. Aufmerksamkeit ermöglicht es dem Modell, sich bei Bedarf auf relevante Teile der Eingabesequenz zu konzentrieren und die Darstellung jedes Wortes als Abfrage zu behandeln, um auf Informationen aus einer Reihe von Werten zuzugreifen und diese zu kombinieren.
6.1 Architekturmerkmale von Transformer
Im Allgemeinen ist der Encoder in der Transformer-Architektur in der Lage, alle verborgenen Zustände an den Decoder zu übergeben. Allerdings nutzt der Decoder die Aufmerksamkeit, um einen zusätzlichen Schritt auszuführen, bevor er die Ausgabe generiert. Der Decoder multipliziert jeden verborgenen Zustand mit seinem Softmax-Score, wodurch verborgene Zustände mit höherer Bewertung verstärkt und andere verborgene Zustände überflutet werden. Dadurch kann sich das Modell auf die Teile der Eingabe konzentrieren, die für die Ausgabe relevant sind.
Selbstaufmerksamkeit befindet sich im Encoder. Der erste Schritt besteht darin, aus jedem Encoder-Eingabevektor (Einbettung jedes Wortes) drei Vektoren zu erstellen: Schlüssel-, Abfrage- und Wertvektoren. Diese Vektoren werden durch Multiplikation der Einbettungen während des Trainings erstellt 3 Matrizen wurden dabei trainiert. Die K-, V- und Q-Dimensionen betragen 64, während die Einbettungs- und Encoder-Eingabe-/Ausgabevektoren eine Dimension von 512 haben. Das Bild unten stammt aus Jay Alammars Illustrated Transformer, der wahrscheinlich besten visuellen Interpretation im Internet.
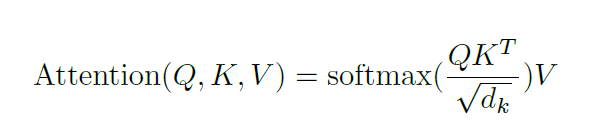
Die Größe dieser Liste ist ein einstellbarer Hyperparameter und entspricht im Wesentlichen der Länge des längsten Satzes im Trainingsdatensatz.
- Achtung:
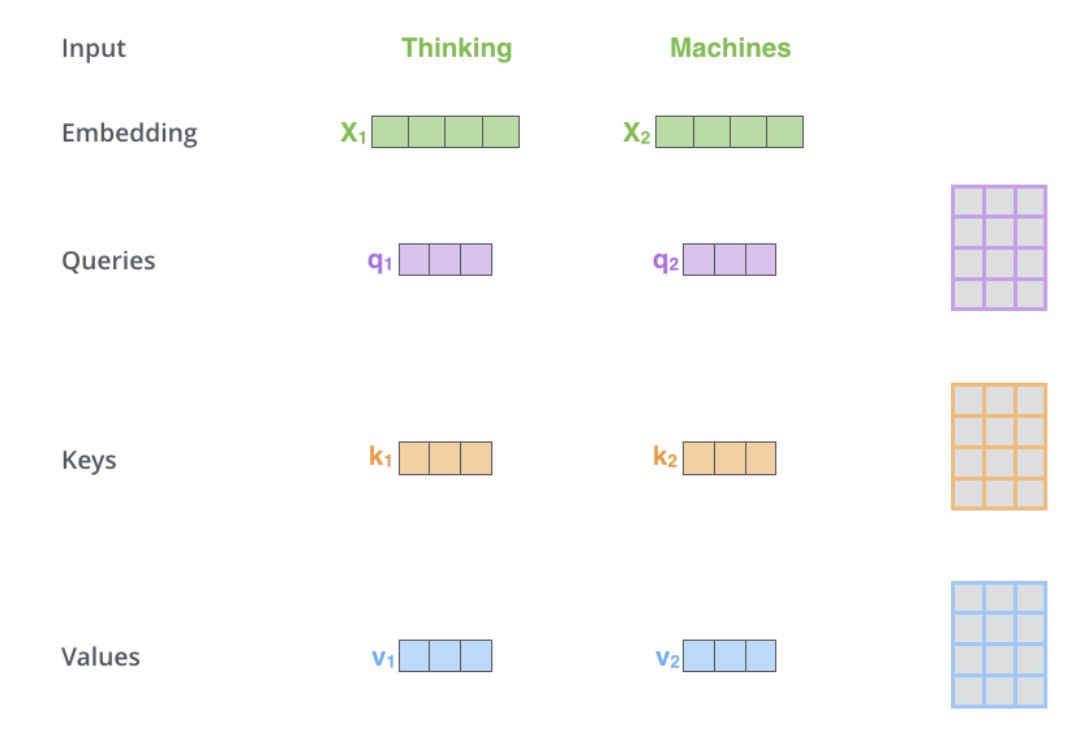
Was sind Abfrage-, Schlüssel- und Wertvektoren? Es handelt sich um abstrakte Konzepte, die beim Berechnen und Nachdenken über Aufmerksamkeit hilfreich sind. Die Berechnung der Queraufmerksamkeit im Decoder ist mit Ausnahme der Eingabe dieselbe wie die der Selbstaufmerksamkeit. Die gegenseitige Aufmerksamkeit kombiniert asymmetrisch zwei unabhängige Einbettungssequenzen derselben Dimension, während die Eingabe der Selbstaufmerksamkeit eine einzelne Einbettungssequenz ist.
Um Transformer zu diskutieren, ist es auch notwendig, zwei vorab trainierte Modelle zu diskutieren, nämlich BERT und GPT, da sie zum Erfolg von Transformer geführt haben.
Der vorab trainierte Decoder von GPT verfügt über 12 Schichten, darunter 768-dimensionale verborgene Zustände, eine 3072-dimensionale Feed-Forward-verborgene Schicht und ist mit 40.000 zusammengeführten Bytepaaren codiert. Es wird hauptsächlich beim Denken in natürlicher Sprache verwendet, um Satzpaare als Folgerung, Widerspruch oder Neutralität zu kennzeichnen.
BERT ist ein vorab trainierter Encoder, der maskierte Sprachmodellierung verwendet, um einen Teil der Wörter in der Eingabe durch spezielle [MASK]-Tokens zu ersetzen, und dann versucht, diese Wörter vorherzusagen. Daher muss der Verlust nur für die vorhergesagten maskierten Wörter berechnet werden. Beide BERT-Modellgrößen verfügen über eine große Anzahl von Encoderschichten (im Papier Transformer-Blöcke genannt) – 12 in der Basisversion und 24 in der großen Version. Diese verfügen außerdem über größere Feedforward-Netzwerke (768 bzw. 1024 versteckte Einheiten) und mehr Aufmerksamkeitsköpfe (12 bzw. 16) als die Standardkonfiguration in der Transformer-Referenzimplementierung im ersten Artikel (6 Encoderschichten, 512 versteckte Einheiten und 8 Aufmerksamkeitsköpfe). ). BERT-Modelle lassen sich leicht optimieren und können normalerweise auf einer einzelnen GPU durchgeführt werden. BERT kann für die Übersetzung in NLP verwendet werden, insbesondere für die Übersetzung ressourcenarmer Sprachen.
Ein Leistungsnachteil von Transformern besteht darin, dass ihre Rechenzeit in der Selbstaufmerksamkeit quadratisch ist, während RNNs nur linear wachsen. 6.2 Transformer-Anwendungsfälle . Dies nennt man „Selbstaufmerksamkeit“. Dies bedeutet, dass der Transformer den Inhalt des gesamten Datensatzes sehen kann, sobald er mit dem Training beginnt.
Vor dem Aufkommen von Transformer blieb der Fortschritt der KI-Sprachaufgaben weit hinter der Entwicklung anderer Bereiche zurück. Tatsächlich war die Verarbeitung natürlicher Sprache in der Deep-Learning-Revolution der letzten etwa zehn Jahre ein Nachzügler, und NLP blieb in gewissem Maße hinter Computer Vision zurück. Mit dem Aufkommen von Transformers hat der NLP-Bereich jedoch einen enormen Aufschwung erfahren und eine Reihe von Modellen wurde auf den Markt gebracht, die bei verschiedenen NLP-Aufgaben gute Ergebnisse erzielen.
Um den Unterschied zwischen traditionellen Sprachmodellen (basierend auf rekursiven Architekturen wie RNN, LSTM oder GRU) und Transformers zu verstehen, können wir ein Beispiel nennen: „Die Eule hat ein Eichhörnchen entdeckt aber er hat nur das Ende seines Schwanzes erreicht.“ Der Aufbau des zweiten Satzes ist verwirrend: Was bedeutet dieses „es“? Traditionelle Sprachmodelle, die sich nur auf die Wörter rund um „es“ konzentrieren, hätten Schwierigkeiten, aber ein Transformer, der jedes Wort mit jedem anderen Wort verbindet, kann erkennen, dass eine Eule ein Eichhörnchen gefangen hat und dass das Eichhörnchen einen Teil seines Schwanzes verloren hat.
6.2.2 Sichtfeld
Bei CNN beginnen wir im lokalen Bereich und erlangen nach und nach die globale Perspektive. CNN erkennt Bilder Pixel für Pixel, indem es Merkmale von lokal nach global aufbaut, um Merkmale wie Ecken oder Linien zu identifizieren. Allerdings werden im Transformer durch Selbstaufmerksamkeit bereits auf der ersten Ebene der Informationsverarbeitung (genau wie bei der Sprache) Verbindungen zwischen entfernten Bildorten hergestellt. Wenn der CNN-Ansatz einer Skalierung ausgehend von einem einzelnen Pixel gleicht, dann wird der Transformator nach und nach das gesamte unscharfe Bild in den Fokus bringen.

CNN generiert lokale Feature-Darstellungen, indem es wiederholt Filter auf lokale Patches der Eingabedaten anwendet, deren empfängliches Sichtfeld schrittweise vergrößert und eine globale Feature-Darstellung aufbaut. Aufgrund der Faltung kann die Fotos-App Birnen von Wolken unterscheiden. Vor der Transformer-Architektur galt CNN als unverzichtbar für Vision-Aufgaben.
Die Architektur des Vision Transformer-Modells ist fast identisch mit dem ersten Transformer aus dem Jahr 2017, mit nur einigen geringfügigen Änderungen, die es ihm ermöglichen, Bilder statt Wörter zu analysieren. Da Sprache tendenziell diskret ist, muss das Eingabebild diskretisiert werden, damit der Transformator visuelle Eingaben verarbeiten kann. Die genaue Nachahmung des Sprachansatzes und die Durchführung der Selbstaufmerksamkeit für jedes Pixel würde in Bezug auf die Rechenzeit unerschwinglich teuer werden. Daher unterteilt ViT größere Bilder in quadratische Zellen oder Patches (ähnlich wie Token im NLP). Die Größe ist beliebig, da das Token je nach Auflösung des Originalbilds größer oder kleiner sein kann (Standard ist 16 x 16 Pixel). Aber durch die Verarbeitung von Pixeln in Gruppen und die Anwendung der Selbstaufmerksamkeit auf jedes Pixel kann ViT schnell riesige Trainingsdatensätze verarbeiten und immer genauere Klassifizierungen ausgeben.
6.2.3 Multimodale Aufgaben der menschlichen Intelligenz. Mit anderen Worten: Es bestand Bedarf an einer einzigen Mehrzweckarchitektur, die einen nahtlosen Übergang zwischen Sinnen wie Lesen/Sehen, Sprechen und Zuhören ermöglicht. Für multimodale Aufgaben müssen mehrere Datentypen gleichzeitig verarbeitet werden, z. B. Originalbilder, Videos und Sprachen, und Transformer bietet das Potenzial einer allgemeinen Architektur. Aufgrund des diskreten Ansatzes früherer Architekturen, bei denen jeder Datentyp sein eigenes spezifisches Modell hatte, war dies eine schwierige Aufgabe. Transformer bieten jedoch eine einfache Möglichkeit, mehrere Eingabequellen zu kombinieren. Multimodale Netzwerke könnten beispielsweise Systeme antreiben, die die Lippenbewegungen von Menschen lesen und auf ihre Stimmen hören, indem sie gleichzeitig reichhaltige Darstellungen von Sprach- und Bildinformationen nutzen. Durch die gegenseitige Aufmerksamkeit ist Transformer in der Lage, Abfrage-, Schlüssel- und Wertevektoren aus verschiedenen Quellen abzuleiten, was es zu einem leistungsstarken Werkzeug für multimodales Lernen macht.
Aufgrund des diskreten Ansatzes früherer Architekturen, bei denen jeder Datentyp sein eigenes spezifisches Modell hatte, war dies eine schwierige Aufgabe. Transformer bieten jedoch eine einfache Möglichkeit, mehrere Eingabequellen zu kombinieren. Multimodale Netzwerke könnten beispielsweise Systeme antreiben, die die Lippenbewegungen von Menschen lesen und auf ihre Stimmen hören, indem sie gleichzeitig reichhaltige Darstellungen von Sprach- und Bildinformationen nutzen. Durch die gegenseitige Aufmerksamkeit ist Transformer in der Lage, Abfrage-, Schlüssel- und Wertevektoren aus verschiedenen Quellen abzuleiten, was es zu einem leistungsstarken Werkzeug für multimodales Lernen macht.
Der größte Vorteil liegt jedoch darin, dass Transformer sich für die Parallelisierung eignen. Im Gegensatz zu einem RNN, das bei jedem Zeitschritt ein Wort verarbeitet, besteht eine Schlüsseleigenschaft des Transformers darin, dass das Wort an jeder Position über seinen eigenen Pfad durch den Encoder fließt. In der Selbstaufmerksamkeitsschicht gibt es Abhängigkeiten zwischen diesen Pfaden, da die Selbstaufmerksamkeitsschicht die Bedeutung anderer Wörter in jeder Eingabesequenz für dieses Wort berechnet. Sobald jedoch die Selbstaufmerksamkeitsausgabe generiert ist, weist die Feedforward-Schicht diese Abhängigkeiten nicht mehr auf, sodass einzelne Pfade beim Durchlaufen der Feedforward-Schicht parallel ausgeführt werden können. Dies ist eine besonders nützliche Funktion im Fall des Transformer-Encoders, der jedes Eingabewort nach einer Selbstaufmerksamkeitsschicht parallel mit anderen Wörtern verarbeitet. Diese Funktion ist jedoch für den Decoder nicht sehr wichtig, da er jeweils nur ein Wort generiert und keine parallelen Wortpfade verwendet.
Die Laufzeit der Transformer-Architektur skaliert quadratisch mit der Länge der Eingabesequenz, was bedeutet, dass die Verarbeitung langsam sein kann, wenn lange Dokumente oder Zeichen als Eingabe verarbeitet werden. Mit anderen Worten, während der Selbstaufmerksamkeitsbildung müssen alle Interaktionspaare berechnet werden, was bedeutet, dass die Berechnung quadratisch mit der Sequenzlänge wächst, also O(T^2d), wobei T die Sequenzlänge und D ist die Dimension. Entspricht beispielsweise einem einfachen Satz d=1000, T≤30⇒T^2≤900⇒T^2d≈900K. Und für die zirkulierenden Nerven wächst es nur linear.
Wäre es nicht schön, wenn der Transformer nicht paarweise Interaktionen zwischen jedem Wortpaar im Satz berechnen müsste? Es gibt Studien, die zeigen, dass recht hohe Leistungsniveaus erreicht werden können, ohne die Interaktionen zwischen allen Wortpaaren zu berechnen (z. B. durch Approximation der paarweisen Aufmerksamkeit).
Im Vergleich zu CNN sind die Datenanforderungen von Transformer extrem hoch. CNNs sind immer noch stichprobeneffizient, was sie zu einer hervorragenden Wahl für Aufgaben mit geringem Ressourcenaufwand macht. Dies gilt insbesondere für Bild-/Videogenerierungsaufgaben, die selbst für CNN-Architekturen große Datenmengen erfordern (was die extrem hohen Datenanforderungen der Transformer-Architektur mit sich bringt). Beispielsweise wird die kürzlich von Radford et al. vorgeschlagene CLIP-Architektur mit CNN-basierten ResNets als visuellem Rückgrat trainiert (anstelle der ViT-ähnlichen Transformer-Architektur). Während Transformatoren Genauigkeitsgewinne bieten, sobald ihre Datenanforderungen erfüllt sind, bieten CNNs eine Möglichkeit, eine gute Genauigkeitsleistung bei Aufgaben bereitzustellen, bei denen die Menge der verfügbaren Daten nicht ungewöhnlich hoch ist. Daher haben beide Architekturen ihren Nutzen.
Da die Laufzeit der Transformer-Architektur einen quadratischen Zusammenhang mit der Länge der Eingabesequenz hat. Das heißt, die Berechnung der Aufmerksamkeit für alle Wortpaare erfordert, dass die Anzahl der Kanten im Diagramm quadratisch mit der Anzahl der Knoten wächst, d. h. in einem Satz mit n Wörtern muss der Transformer n^2 Wortpaare berechnen. Dies bedeutet, dass die Anzahl der Parameter riesig ist (d. h. die Speichernutzung hoch ist), was zu einer hohen Rechenkomplexität führt. Hohe Rechenanforderungen wirken sich insbesondere bei mobilen Geräten negativ auf die Leistung und die Akkulaufzeit aus. Um eine bessere Leistung (z. B. Genauigkeit) zu erzielen, benötigt Transformer insgesamt eine höhere Rechenleistung, mehr Daten, mehr Strom-/Akkulaufzeit und einen größeren Speicherbedarf.
7. Inferenzverzerrung
Jeder in der Praxis verwendete Algorithmus für maschinelles Lernen, vom nächsten Nachbarn bis zur Gradientenverstärkung, weist seine eigene induktive Verzerrung hinsichtlich der Kategorien auf, die leichter zu erlernen sind. Fast alle Lernalgorithmen haben die Tendenz zu lernen, dass Elemente, die ähnlich sind („nahe“ beieinander in einem bestimmten Merkmalsraum), mit größerer Wahrscheinlichkeit zur gleichen Klasse gehören. Lineare Modelle wie die logistische Regression gehen außerdem davon aus, dass Kategorien durch lineare Grenzen getrennt werden können, was eine „harte“ Tendenz darstellt, da das Modell nichts anderes lernen kann. Selbst bei der regulierten Regression, die beim maschinellen Lernen fast immer verwendet wird, besteht eine Tendenz zum Lernen von Grenzen mit einer kleinen Anzahl von Merkmalen und geringen Merkmalsgewichten. Dies ist eine „weiche“ Tendenz, da das Modell viele Klassen lernen kann Grenzen mit Features mit hohem Gewicht, aber das ist schwieriger/erfordert mehr Daten.
Sogar Deep-Learning-Modelle haben Inferenzverzerrungen. Beispielsweise ist das neuronale LSTM-Netzwerk sehr effektiv für Aufgaben zur Verarbeitung natürlicher Sprache, da es Kontextinformationen zu langen Sequenzen bevorzugt.

Das Verständnis von Domänenkenntnissen und Problemschwierigkeiten kann uns bei der Auswahl geeigneter Algorithmusanwendungen helfen. Zum Beispiel das Problem, relevante Begriffe aus klinischen Aufzeichnungen zu extrahieren, um festzustellen, ob bei einem Patienten Krebs diagnostiziert wurde. In diesem Fall funktioniert die logistische Regression gut, da es viele unabhängig informative Begriffe gibt. Bei anderen Problemen, etwa dem Extrahieren der Ergebnisse eines Gentests aus einem komplexen PDF-Bericht, kann die Verwendung von LSTM den langfristigen Kontext jedes Wortes besser verarbeiten, was zu einer besseren Leistung führt. Sobald ein Basisalgorithmus ausgewählt wurde, kann uns das Verständnis seiner Vorurteile auch beim Feature Engineering helfen, dem Prozess der Auswahl von Informationen, die in einen Lernalgorithmus eingespeist werden sollen.
Jede Modellstruktur weist eine inhärente Inferenzverzerrung auf, die dabei hilft, Muster in Daten zu verstehen und dadurch Lernen zu ermöglichen. Beispielsweise weist CNN eine gemeinsame Nutzung räumlicher Parameter und Übersetzung/räumliche Invarianz auf, während RNN eine gemeinsame Nutzung zeitlicher Parameter aufweist.
8. Zusammenfassung
Der alte Programmierer hat versucht, Transformer, CNN, RNN/GRU/LSTM in der Deep-Learning-Architektur zu vergleichen und zu analysieren, und hat verstanden, dass Transformer längere Abhängigkeiten lernen kann Beziehungen, erfordert jedoch höhere Datenanforderungen und Rechenleistung; Transformer eignet sich für multimodale Aufgaben und kann nahtlos zwischen Sinnen wie Lesen/Sehen, Sprechen und Zuhören wechseln Daten, um Lernen zu ermöglichen.
【Referenz】
- CNN vs. vollständig verbundenes Netzwerk für Bilderkennung?, https://stats.stackexchange.com/questions/341863/cnn- vs -vollständig verbundenes Netzwerk zur Bilderkennung
- https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1184/lectures/lecture12.pdf#🎜 🎜 # Einführung in LSTM-Einheiten in RNN, https://www.pluralsight.com/guides/introduction-to-lstm-units-in-rnn
- Lernen übertragbarer visueller Modelle aus natürlicher Sprache Supervision, https://arxiv.org/abs/2103.00020
- Linformer: Selbstaufmerksamkeit mit linearer Komplexität, https://arxiv.org/abs/2006.04768
- Umdenken Achtung bei Darstellern, https://arxiv.org/abs/2009.14794
- Big Bird: Transformers for Longer Sequences, https://arxiv.org/abs/2007.14062
- #🎜🎜 # Synthesizer: Neudenken der Selbstaufmerksamkeit in Transformer-Modellen, https://arxiv.org/abs/2005.00743
- Do Vision Transformers See Like Convolutional Neural Networks?, https://arxiv.org/abs/ 2108.08810
- Illustrierter Transformator, https://jalammar.github.io/illustrated-transformer/
Das obige ist der detaillierte Inhalt vonVergleichende Analyse von Deep-Learning-Architekturen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
 Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Diese Woche gab FigureAI, ein Robotikunternehmen, an dem OpenAI, Microsoft, Bezos und Nvidia beteiligt sind, bekannt, dass es fast 700 Millionen US-Dollar an Finanzmitteln erhalten hat und plant, im nächsten Jahr einen humanoiden Roboter zu entwickeln, der selbstständig gehen kann. Und Teslas Optimus Prime hat immer wieder gute Nachrichten erhalten. Niemand zweifelt daran, dass dieses Jahr das Jahr sein wird, in dem humanoide Roboter explodieren. SanctuaryAI, ein in Kanada ansässiges Robotikunternehmen, hat kürzlich einen neuen humanoiden Roboter auf den Markt gebracht: Phoenix. Beamte behaupten, dass es viele Aufgaben autonom und mit der gleichen Geschwindigkeit wie Menschen erledigen kann. Pheonix, der weltweit erste Roboter, der Aufgaben autonom in menschlicher Geschwindigkeit erledigen kann, kann jedes Objekt sanft greifen, bewegen und elegant auf der linken und rechten Seite platzieren. Es kann Objekte autonom identifizieren
