
wget --no-check-certificate https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
hadoop version
d Drücken Sie die Esc-Taste, um den Bearbeitungsmodus zu verlassen, geben Sie zum Speichern und Beenden Folgendes ein: wq. Viertens: Konfigurieren Sie die passwortfreie SSH-Anmeldung" >b Geben Sie i ein, um in den Bearbeitungsmodus zu gelangen. c. Fügen Sie den folgenden Inhalt in den Knoten ein. start-yarn.sh
d Drücken Sie die Esc-Taste, um den Bearbeitungsmodus zu verlassen, geben Sie zum Speichern und Beenden Folgendes ein: wq. Viertens: Konfigurieren Sie die passwortfreie SSH-Anmeldung
 Betrieb und Instandhaltung
Betrieb und Wartung von Linux
So installieren Sie Hadoop unter Linux
Betrieb und Instandhaltung
Betrieb und Wartung von Linux
So installieren Sie Hadoop unter Linux
So installieren Sie Hadoop unter Linux

1: JDK installieren
1 Führen Sie den folgenden Befehl aus, um das JDK1.8-Installationspaket herunterzuladen.
wget --no-check-certificate https://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz
2 Führen Sie den folgenden Befehl aus, um das heruntergeladene JDK1.8-Installationspaket zu dekomprimieren.
tar -zxvf jdk-8u151-linux-x64.tar.gz
3 Verschieben Sie das JDK-Paket und benennen Sie es um.
mv jdk1.8.0_151/ /usr/java8
4. Konfigurieren Sie Java-Umgebungsvariablen.
echo 'export JAVA_HOME=/usr/java8' >> /etc/profile echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile source /etc/profile
5 Überprüfen Sie, ob Java erfolgreich installiert wurde.
java -version
2: Hadoop installieren
Hinweis: Sie können Huawei-Quelle (mittlere Geschwindigkeit, akzeptabel, der Fokus liegt auf der Vollversion) und Tsinghua-Quelle zum Herunterladen auswählen Hadoop-Installationspaket (Die Download-Geschwindigkeit von Version 3.0.0 und höher ist zu langsam und es gibt nur wenige Versionen), Quelle der Beijing Foreign Studies University (die Download-Geschwindigkeit ist sehr hoch, aber es gibt nur wenige Versionen) – Ich habe es persönlich getestet #🎜 🎜#
1 Führen Sie den folgenden Befehl aus, um das Hadoop-Installationspaket herunterzuladen. wget --no-check-certificate https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
Nach dem Login kopieren
wget --no-check-certificate https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
2 Führen Sie den folgenden Befehl aus, um das Hadoop-Installationspaket nach /opt/hadoop zu entpacken. tar -zxvf hadoop-3.1.3.tar.gz -C /opt/
mv /opt/hadoop-3.1.3 /opt/hadoop
Nach dem Login kopieren
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/ mv /opt/hadoop-3.1.3 /opt/hadoop
3 Führen Sie den folgenden Befehl aus, um Hadoop-Umgebungsvariablen zu konfigurieren. echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
Nach dem Login kopieren
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile source /etc/profile
4 Führen Sie die folgenden Befehle aus, um die Konfigurationsdateien Yarn-env.sh und Hadoop-env.sh zu ändern. echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
Nach dem Login kopieren
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
5 Führen Sie den folgenden Befehl aus, um zu testen, ob Hadoop erfolgreich installiert wurde. hadoop version
Nach dem Login kopieren
Wenn die Versionsinformationen zurückgegeben werden, bedeutet dies, dass die Installation erfolgreich war. 3: Hadoop konfigurierenhadoop version
1 Ändern Sie die Hadoop-Konfigurationsdatei core-site.xml.
a Führen Sie den folgenden Befehl aus, um mit dem Aufrufen der Bearbeitungsseite zu beginnen. vim /opt/hadoop/etc/hadoop/core-site.xml
a. 执行以下命令开始进入编辑页面。 <property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>b. 输入i进入编辑模式。c. 在<configuration></configuration>节点内插入如下内容。
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
d. 按Esc键退出编辑模式,输入:wq保存退出。
2. 修改Hadoop配置文件 hdfs-site.xml。
a. 执行以下命令开始进入编辑页面。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>b. 输入i进入编辑模式。c. 在<configuration></configuration>节点内插入如下内容。
ssh-keygen -t rsa
d. 按Esc键退出编辑模式,输入:wq保存退出。
四:配置SSH免密登录
1. 执行以下命令,创建公钥和私钥。
cd ~ cd .ssh cat id_rsa.pub >> authorized_keys
2. 执行以下命令,将公钥添加到authorized_keys文件中。
vi /etc/profile
若报错,执行下面操作后重新执行上面两句命令;若没有报错直接进入第五步:
输入如下命令,在环境变量中添加下面的配置
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
然后向里面加入如下的内容
source /etc/profile
输入如下命令使改动生效b Geben Sie i ein, um in den Bearbeitungsmodus zu gelangen. c. Fügen Sie den folgenden Inhalt in den Knoten <configuration></configuration> ein.
hadoop namenode -format
d Drücken Sie die Esc-Taste, um den Bearbeitungsmodus zu verlassen, geben Sie zum Speichern und Beenden Folgendes ein: wq.
2 Ändern Sie die Hadoop-Konfigurationsdatei hdfs-site.xml. a Führen Sie den folgenden Befehl aus, um mit dem Aufrufen der Bearbeitungsseite zu beginnen.
start-dfs.sh
b Geben Sie i ein, um in den Bearbeitungsmodus zu gelangen. c. Fügen Sie den folgenden Inhalt in den Knoten <configuration> ein. start-yarn.sh
Nach dem Login kopierend Drücken Sie die Esc-Taste, um den Bearbeitungsmodus zu verlassen, geben Sie zum Speichern und Beenden Folgendes ein: wq. Viertens: Konfigurieren Sie die passwortfreie SSH-Anmeldung
1. Führen Sie die folgenden Befehle aus, um den öffentlichen Schlüssel und den privaten Schlüssel zu erstellen. start-yarn.sh
jps
Nach dem Login kopieren2 Führen Sie den folgenden Befehl aus, um den öffentlichen Schlüssel zur Datei „authorized_keys“ hinzuzufügen. rrreeeWenn ein Fehler gemeldet wird, führen Sie die folgenden Vorgänge aus und führen Sie dann die beiden oben genannten Befehle erneut aus. Wenn kein Fehler gemeldet wird, fahren Sie direkt mit Schritt fünf fort:  # 🎜🎜#
# 🎜🎜#Geben Sie den folgenden Befehl ein, fügen Sie die folgende Konfiguration zur Umgebungsvariablen hinzu
rrreeeFügen Sie dann den folgenden Inhalt hinzu
rrreee
Geben Sie den folgenden Befehl ein, damit die Änderungen wirksam werdenrrreee5: Starten Sie Hadoop1.#🎜 🎜#
Führen Sie den folgenden Befehl aus, um den Namensknoten zu initialisieren. rrreee
2.
Führen Sie die folgenden Befehle aus, um Hadoop zu starten. #🎜🎜##🎜🎜#rrreee#🎜🎜#Wenn Sie J/N wählen, wählen Sie J; andernfalls drücken Sie einfach die Eingabetaste#🎜🎜#rrreee#🎜🎜##🎜🎜#3.#🎜🎜##🎜🎜 # Führen Sie nach erfolgreichem Start den folgenden Befehl aus, um den erfolgreich gestarteten Prozess anzuzeigen. #🎜🎜##🎜🎜#rrreee#🎜🎜##🎜🎜##🎜🎜##🎜🎜# Normalerweise gibt es 6 Prozesse; #🎜🎜##🎜🎜##🎜🎜##🎜🎜#4. #🎜🎜##🎜🎜#Öffnen Sie den Browser und besuchen Sie http://:8088 und http://:50070 Hadoop-Pseudoverteilung Die Umgebung ist eingerichtet. #🎜🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜# Das obige ist der detaillierte Inhalt vonSo installieren Sie Hadoop unter Linux. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
jps
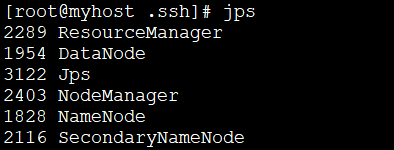 # 🎜🎜#
# 🎜🎜#Geben Sie den folgenden Befehl ein, fügen Sie die folgende Konfiguration zur Umgebungsvariablen hinzuFügen Sie dann den folgenden Inhalt hinzurrreee
 rrreee
rrreee

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Wie löste ich Berechtigungsprobleme bei der Verwendung von Python -Verssionsbefehl im Linux Terminal?
Apr 02, 2025 am 06:36 AM
Wie löste ich Berechtigungsprobleme bei der Verwendung von Python -Verssionsbefehl im Linux Terminal?
Apr 02, 2025 am 06:36 AM
Verwenden Sie Python im Linux -Terminal ...
 Wie konfigurieren Sie die Timing -Timing -Aufgabe von ApScheduler als Dienst auf macOS?
Apr 01, 2025 pm 06:09 PM
Wie konfigurieren Sie die Timing -Timing -Aufgabe von ApScheduler als Dienst auf macOS?
Apr 01, 2025 pm 06:09 PM
Konfigurieren Sie die Timing -Timing -Timing -Timing -Timing auf der MacOS -Plattform, wenn Sie die Timing -Timing -Timing -Timing von APScheduler als Service konfigurieren möchten, ähnlich wie bei NGIN ...
 Vier Möglichkeiten zur Implementierung von Multithreading in C -Sprache
Apr 03, 2025 pm 03:00 PM
Vier Möglichkeiten zur Implementierung von Multithreading in C -Sprache
Apr 03, 2025 pm 03:00 PM
Multithreading in der Sprache kann die Programmeffizienz erheblich verbessern. Es gibt vier Hauptmethoden, um Multithreading in C -Sprache zu implementieren: Erstellen Sie unabhängige Prozesse: Erstellen Sie mehrere unabhängig laufende Prozesse. Jeder Prozess hat seinen eigenen Speicherplatz. Pseudo-MultitHhreading: Erstellen Sie mehrere Ausführungsströme in einem Prozess, der denselben Speicherplatz freigibt und abwechselnd ausführt. Multi-Thread-Bibliothek: Verwenden Sie Multi-Thread-Bibliotheken wie PThreads, um Threads zu erstellen und zu verwalten, wodurch reichhaltige Funktionen der Thread-Betriebsfunktionen bereitgestellt werden. Coroutine: Eine leichte Multi-Thread-Implementierung, die Aufgaben in kleine Unteraufgaben unterteilt und sie wiederum ausführt.
 So öffnen Sie Web.xml
Apr 03, 2025 am 06:51 AM
So öffnen Sie Web.xml
Apr 03, 2025 am 06:51 AM
Um eine Web.xml -Datei zu öffnen, können Sie die folgenden Methoden verwenden: Verwenden Sie einen Texteditor (z.
 Kann der Python -Dolmetscher im Linux -System gelöscht werden?
Apr 02, 2025 am 07:00 AM
Kann der Python -Dolmetscher im Linux -System gelöscht werden?
Apr 02, 2025 am 07:00 AM
In Bezug auf das Problem der Entfernung des Python -Dolmetschers, das mit Linux -Systemen ausgestattet ist, werden viele Linux -Verteilungen den Python -Dolmetscher bei der Installation vorinstallieren, und verwendet den Paketmanager nicht ...
 Wofür wird der Linux am besten verwendet?
Apr 03, 2025 am 12:11 AM
Wofür wird der Linux am besten verwendet?
Apr 03, 2025 am 12:11 AM
Linux wird am besten als Serververwaltung, eingebettete Systeme und Desktop -Umgebungen verwendet. 1) In der Serververwaltung wird Linux verwendet, um Websites, Datenbanken und Anwendungen zu hosten und Stabilität und Zuverlässigkeit bereitzustellen. 2) In eingebetteten Systemen wird Linux aufgrund seiner Flexibilität und Stabilität in Smart Home und Automotive Electronic Systems häufig verwendet. 3) In der Desktop -Umgebung bietet Linux reichhaltige Anwendungen und eine effiziente Leistung.
 Wie ist Debian Hadoop -Kompatibilität?
Apr 02, 2025 am 08:42 AM
Wie ist Debian Hadoop -Kompatibilität?
Apr 02, 2025 am 08:42 AM
Debianlinux ist bekannt für seine Stabilität und Sicherheit und wird in Server-, Entwicklungs- und Desktop -Umgebungen häufig verwendet. Während es derzeit einen Mangel an offiziellen Anweisungen zur direkten Kompatibilität mit Debian und Hadoop gibt, wird dieser Artikel Sie dazu veranlassen, Hadoop in Ihrem Debian -System bereitzustellen. Debian -Systemanforderungen: Bevor Sie mit der Hadoop -Konfiguration beginnen, stellen Sie bitte sicher, dass Ihr Debian -System die Mindestanforderungen von Hadoop erfüllt, einschließlich der Installation der erforderlichen Java -Laufzeitumgebung (JRE) und Hadoop -Pakete. Schritte zur Bereitstellung von Hadoop -Bereitstellungen: Download und Unzip Hadoop: Laden Sie die Hadoop -Version von der offiziellen Apachehadoop -Website herunter und lösen Sie sie
 Ist Debian Strings kompatibel mit mehreren Browsern
Apr 02, 2025 am 08:30 AM
Ist Debian Strings kompatibel mit mehreren Browsern
Apr 02, 2025 am 08:30 AM
"DebianStrings" ist kein Standardbegriff und seine spezifische Bedeutung ist noch unklar. Dieser Artikel kann seine Browserkompatibilität nicht direkt kommentieren. Wenn sich jedoch "DebianStrings" auf eine Webanwendung bezieht, die auf einem Debian -System ausgeführt wird, hängt seine Browserkompatibilität von der technischen Architektur der Anwendung selbst ab. Die meisten modernen Webanwendungen sind für die Kompatibilität des Cross-Browsers verpflichtet. Dies beruht auf den folgenden Webstandards und der Verwendung gut kompatibler Front-End-Technologien (wie HTML, CSS, JavaScript) und Back-End-Technologien (wie PHP, Python, Node.js usw.). Um sicherzustellen, dass die Anwendung mit mehreren Browsern kompatibel ist, müssen Entwickler häufig Kreuzbrowser-Tests durchführen und die Reaktionsfähigkeit verwenden
