
 Technologie-Peripheriegeräte
KI
Das 32k-Eingabefeld von GPT-4 reicht immer noch nicht aus? Unlimiformer erweitert die Kontextlänge auf unendliche Länge
Technologie-Peripheriegeräte
KI
Das 32k-Eingabefeld von GPT-4 reicht immer noch nicht aus? Unlimiformer erweitert die Kontextlänge auf unendliche Länge
Das 32k-Eingabefeld von GPT-4 reicht immer noch nicht aus? Unlimiformer erweitert die Kontextlänge auf unendliche Länge

Transformer ist heute die leistungsstärkste seq2seq-Architektur. Vortrainierte Transformatoren verfügen typischerweise über Kontextfenster von 512 (z. B. BERT) oder 1024 (z. B. BART) Token, was für viele aktuelle Textzusammenfassungsdatensätze (XSum, CNN/DM) lang genug ist.
Aber 16384 ist keine Obergrenze für die Länge des Kontexts, der zur Generierung erforderlich ist: Aufgaben mit langen Erzählungen, wie Buchzusammenfassungen (Krys-´cinski et al., 2021) oder narrative Fragen und Antworten (Kociský et al. , 2018), erfordern häufig Eingaben von mehr als 100.000 Token. Das aus Wikipedia-Artikeln generierte Challenge-Set (Liu* et al., 2018) enthält Eingaben von mehr als 500.000 Token. Open-Domain-Aufgaben bei der generativen Fragebeantwortung können Informationen aus größeren Eingaben synthetisieren, beispielsweise die Beantwortung von Fragen zu den aggregierten Eigenschaften von Artikeln aller lebenden Autoren auf Wikipedia. In Abbildung 1 sind die Größen mehrerer beliebter Zusammenfassungs- und Frage-und-Antwort-Datensätze im Vergleich zu den üblichen Kontextfensterlängen dargestellt. Die längste Eingabe ist mehr als 34-mal länger als das Kontextfenster von Longformer.
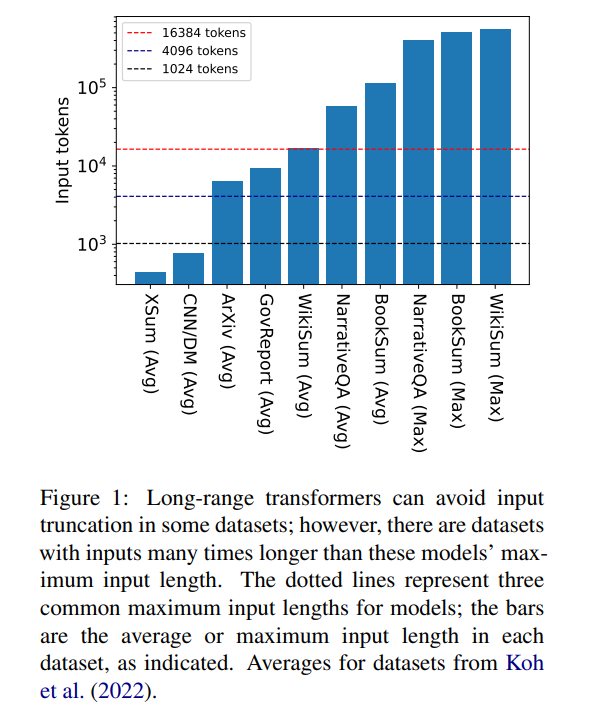
Bei diesen sehr langen Eingaben kann der Vanilla-Transformer nicht skalieren, da der native Aufmerksamkeitsmechanismus quadratische Komplexität aufweist. Lange Eingangstransformatoren sind zwar effizienter als Standardtransformatoren, erfordern jedoch dennoch erhebliche Rechenressourcen, die mit zunehmender Kontextfenstergröße zunehmen. Darüber hinaus erfordert die Vergrößerung des Kontextfensters eine Neuschulung des Modells mit der neuen Kontextfenstergröße, was rechen- und umweltintensiv ist.
In dem Artikel „Unlimiformer: Long-Range Transformers with Unlimited Length Input“ stellten Forscher der Carnegie Mellon University Unlimiformer vor. Hierbei handelt es sich um einen auf Abruf basierenden Ansatz, der ein vorab trainiertes Sprachmodell erweitert, um zum Testzeitpunkt Eingaben mit unendlicher Länge zu akzeptieren.

Link zum Papier: https://arxiv.org/pdf/2305.01625v1.pdf
Unlimiformer kann in jeden vorhandenen Encoder-Decoder-Transformator injiziert werden, der Eingaben mit unbegrenzter Länge verarbeiten kann . Bei einer langen Eingabesequenz kann Unlimiformer einen Datenspeicher auf den verborgenen Zuständen aller Eingabetoken aufbauen. Der Standard-Cross-Attention-Mechanismus des Decoders ist dann in der Lage, den Datenspeicher abzufragen und sich auf die obersten k Eingabetokens zu konzentrieren. Der Datenspeicher kann im GPU- oder CPU-Speicher gespeichert und sublinear abgefragt werden.
Unlimiformer kann direkt auf ein trainiertes Modell angewendet werden und kann bestehende Kontrollpunkte ohne weitere Schulung verbessern. Die Leistung von Unlimiformer wird nach der Feinabstimmung weiter verbessert. Dieses Papier zeigt, dass Unlimiformer auf mehrere Basismodelle wie BART (Lewis et al., 2020a) oder PRIMERA (Xiao et al., 2022) angewendet werden kann, ohne Gewichte hinzuzufügen und erneut zu trainieren. In verschiedenen seq2seq-Datensätzen mit großer Reichweite ist Unlimiformer nicht nur stärker als Transformer mit großer Reichweite wie Longformer (Beltagy et al., 2020b), SLED (Ivgi et al., 2022) und Memorizing Transformers (Wu et al., 2021). ) auf diesen Datensätzen Die Leistung ist besser, und in diesem Artikel wurde auch festgestellt, dass Unlimiform zusätzlich zum Longformer-Encodermodell angewendet werden kann, um weitere Verbesserungen zu erzielen.
Unlimiformer technisches Prinzip
Da die Größe des Encoder-Kontextfensters fest ist, ist die maximale Eingabelänge des Transformers begrenzt. Bei der Dekodierung können jedoch unterschiedliche Informationen relevant sein; außerdem können sich unterschiedliche Aufmerksamkeitsköpfe auf unterschiedliche Arten von Informationen konzentrieren (Clark et al., 2019). Daher verschwendet ein festes Kontextfenster möglicherweise Aufwand für Token, auf die die Aufmerksamkeit weniger gerichtet ist.
Bei jedem Dekodierungsschritt wählt jeder Aufmerksamkeitskopf in Unlimiformer aus allen Eingaben ein separates Kontextfenster aus. Dies wird erreicht, indem die Unlimiformer-Suche in den Decoder eingefügt wird: Bevor das Modell in das Cross-Attention-Modul eintritt, führt es eine k-Nearest-Neighbor-Suche (kNN) im externen Datenspeicher durch und wählt einen Satz jedes Aufmerksamkeitskopfes in jeder Decoderschicht aus. Token zur Teilnahme.
Kodierung
Um die Eingabesequenz länger als die Kontextfensterlänge des Modells zu kodieren, kodiert dieser Artikel die überlappenden Eingabeblöcke gemäß der Methode von Ivgi et al. (2022) (Ivgi et al., 2022), wobei jeder einzelne beibehalten wird Teilen Sie die mittlere Hälfte der Ausgabe auf, um vor und nach dem Kodierungsprozess ausreichend Kontext sicherzustellen. Schließlich verwendet dieser Artikel Bibliotheken wie Faiss (Johnson et al., 2019), um codierte Eingaben in Datenspeichern zu indizieren (Johnson et al., 2019).
Erweiterten Queraufmerksamkeitsmechanismus abrufen
Beim Standard-Queraufmerksamkeitsmechanismus konzentriert sich der Decoder des Transformators auf den endgültigen verborgenen Zustand des Encoders, und der Encoder schneidet normalerweise die Eingabe ab und nur den ersten k Token sind kodiert.
Dieser Artikel konzentriert sich nicht nur auf die ersten k Token der Eingabe, sondern ruft auch die ersten k verborgenen Zustände der längeren Eingabereihe ab und konzentriert sich nur auf die ersten k. Dadurch kann das Schlüsselwort aus der gesamten Eingabesequenz abgerufen werden, anstatt das Schlüsselwort abzuschneiden. Unser Ansatz ist außerdem hinsichtlich der Rechenleistung und des GPU-Speichers kostengünstiger als die Verarbeitung aller Eingabetokens und behält in der Regel über 99 % der Aufmerksamkeitsleistung bei.
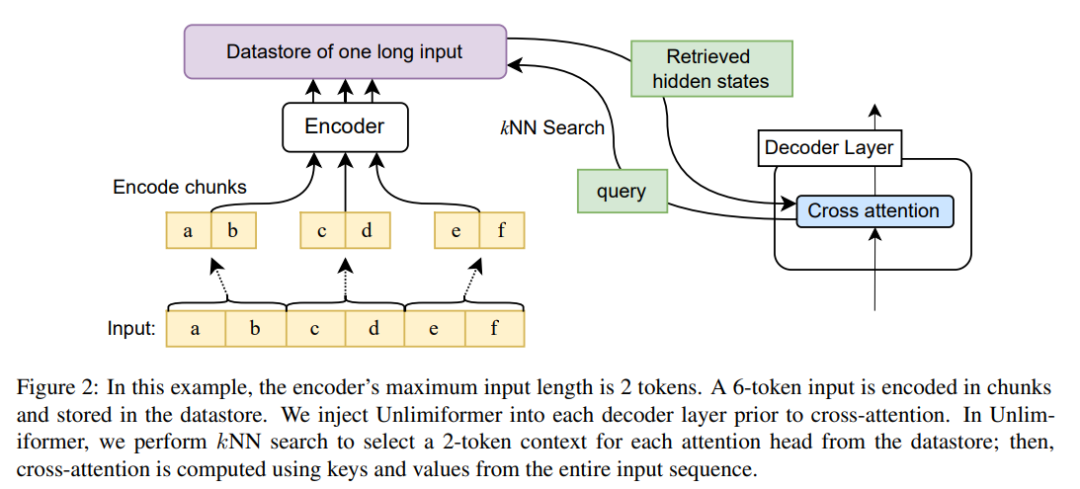
Abbildung 2 zeigt die Änderungen dieses Artikels an der seq2seq-Transformator-Architektur. Die vollständige Eingabe wird mithilfe des Encoders blockcodiert und in einem Datenspeicher gespeichert; der codierte Latentzustandsdatenspeicher wird dann beim Decodieren abgefragt. Die kNN-Suche ist nicht parametrisch und kann in jeden vorab trainierten seq2seq-Transformator eingefügt werden, wie unten beschrieben. Experimentelle Ergebnisse
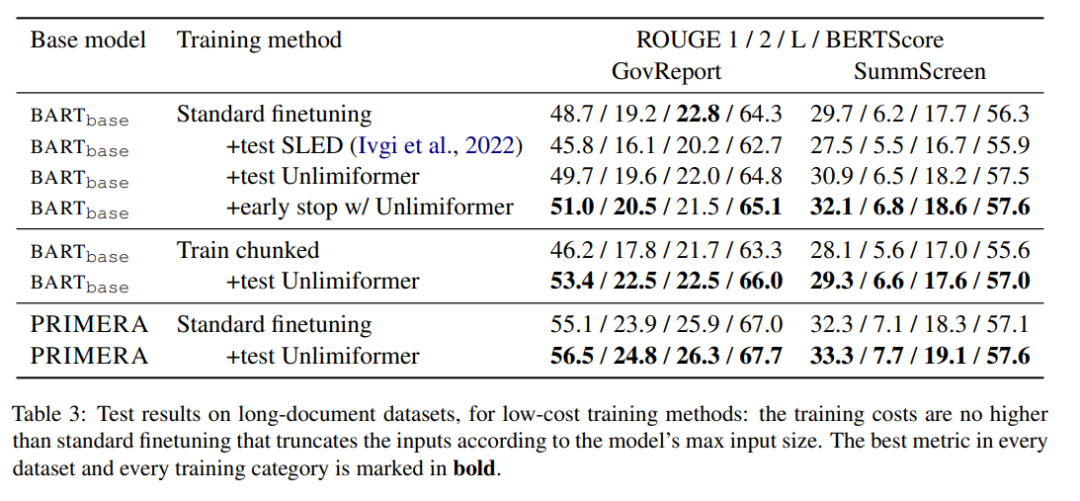
Buchzusammenfassung
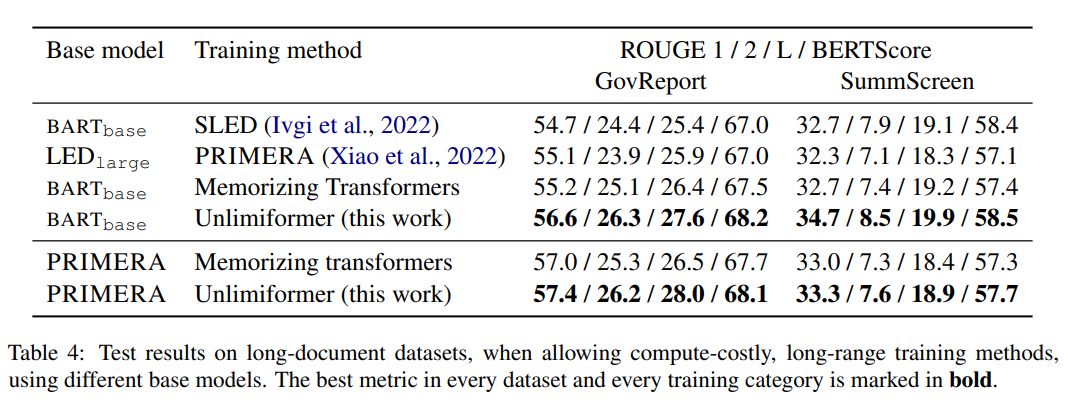
Das obige ist der detaillierte Inhalt vonDas 32k-Eingabefeld von GPT-4 reicht immer noch nicht aus? Unlimiformer erweitert die Kontextlänge auf unendliche Länge. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
Fügen Sie einer vorhandenen Tabelle in SQL neue Spalten hinzu, indem Sie die Anweisung für die Änderung Tabelle verwenden. Zu den spezifischen Schritten gehören: Ermittlung des Tabellennamens und Spalteninformationen, Schreiben von Alter Tabellenanweisungen und Ausführungsanweisungen. Fügen Sie beispielsweise eine E -Mail -Spalte in die Tabelle der Kunden hinzu (VARCHAR (50)): Änderung der Tabelle Kunden addieren Sie E -Mail -Varchar (50).
 Was ist die Syntax zum Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:51 PM
Was ist die Syntax zum Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:51 PM
Die Syntax zum Hinzufügen von Spalten in SQL ist Alter table table_name add column_name data_type [nicht null] [Standard default_value]; Wenn table_name der Tabellenname ist, ist Column_Name der neue Spaltenname, Data_Type ist der Datentyp, nicht null Gibt an, ob Nullwerte zulässig sind, und Standard Standard_Value gibt den Standardwert an.
 SQL Clear Tabelle: Tipps zur Leistungsoptimierung
Apr 09, 2025 pm 02:54 PM
SQL Clear Tabelle: Tipps zur Leistungsoptimierung
Apr 09, 2025 pm 02:54 PM
Tipps zur Verbesserung der SQL -Tabellenlösungsleistung: Verwenden Sie die Truncate -Tabelle anstelle des Löschens, löschen Sie den Speicherplatz und setzen Sie die Identitätsspalte zurück. Deaktivieren Sie fremde Schlüsselbeschränkungen, um die Kaskadierung der Löschung zu verhindern. Verwenden Sie Transaktionskapselungsvorgänge, um die Datenkonsistenz sicherzustellen. Batch löschen Big Data und begrenzen Sie die Anzahl der Zeilen durch die Grenze. Bauen Sie den Index nach dem Löschen neu auf, um die Effizienz der Abfrage zu verbessern.
 So setzen Sie Standardwerte beim Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:45 PM
So setzen Sie Standardwerte beim Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:45 PM
Legen Sie den Standardwert für neu hinzugefügte Spalten fest, verwenden Sie die Anweisung für die Änderung der Tabelle: Hinzufügen von Spalten angeben und den Standardwert: Alter Table table_name hinzufügen column_name data_type Standard default_value; Verwenden Sie die Einschränkungsklausel, um den Standardwert anzugeben: Alter Table Table_Name add Column_Name Data_type Einschränkung default_constraint default default_value;
 Verwenden Sie die Löschanweisung, um SQL -Tabellen zu löschen
Apr 09, 2025 pm 03:00 PM
Verwenden Sie die Löschanweisung, um SQL -Tabellen zu löschen
Apr 09, 2025 pm 03:00 PM
Ja, mit der Anweisung Löschen kann eine SQL -Tabelle gelöscht werden. TABLE_NAME ERSETZEN AUS DER NAME DER TABELLE, DIE DELDET.
 Wie geht es mit Redis -Speicherfragmentierung um?
Apr 10, 2025 pm 02:24 PM
Wie geht es mit Redis -Speicherfragmentierung um?
Apr 10, 2025 pm 02:24 PM
Redis -Gedächtnisfragmentierung bezieht sich auf die Existenz kleiner freier Bereiche in dem zugewiesenen Gedächtnis, die nicht neu zugewiesen werden können. Zu den Bewältigungsstrategien gehören: Neustart von Redis: Der Gedächtnis vollständig löschen, aber den Service unterbrechen. Datenstrukturen optimieren: Verwenden Sie eine Struktur, die für Redis besser geeignet ist, um die Anzahl der Speicherzuweisungen und -freisetzungen zu verringern. Konfigurationsparameter anpassen: Verwenden Sie die Richtlinie, um die kürzlich verwendeten Schlüsselwertpaare zu beseitigen. Verwenden Sie den Persistenzmechanismus: Daten regelmäßig sichern und Redis neu starten, um Fragmente zu beseitigen. Überwachen Sie die Speicherverwendung: Entdecken Sie die Probleme rechtzeitig und ergreifen Sie Maßnahmen.
 PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
Um eine Datentabelle mithilfe von PHPMYADMIN zu erstellen, sind die folgenden Schritte unerlässlich: Stellen Sie eine Verbindung zur Datenbank her und klicken Sie auf die neue Registerkarte. Nennen Sie die Tabelle und wählen Sie die Speichermotor (innoDB empfohlen). Fügen Sie Spaltendetails hinzu, indem Sie auf die Taste der Spalte hinzufügen, einschließlich Spaltenname, Datentyp, ob Nullwerte und andere Eigenschaften zuzulassen. Wählen Sie eine oder mehrere Spalten als Primärschlüssel aus. Klicken Sie auf die Schaltfläche Speichern, um Tabellen und Spalten zu erstellen.
 Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Das Erstellen einer Oracle -Datenbank ist nicht einfach, Sie müssen den zugrunde liegenden Mechanismus verstehen. 1. Sie müssen die Konzepte von Datenbank und Oracle DBMS verstehen. 2. Beherrschen Sie die Kernkonzepte wie SID, CDB (Containerdatenbank), PDB (Pluggable -Datenbank); 3.. Verwenden Sie SQL*Plus, um CDB zu erstellen und dann PDB zu erstellen. Sie müssen Parameter wie Größe, Anzahl der Datendateien und Pfade angeben. 4. Erweiterte Anwendungen müssen den Zeichensatz, den Speicher und andere Parameter anpassen und die Leistungsstimmung durchführen. 5. Achten Sie auf Speicherplatz, Berechtigungen und Parametereinstellungen und überwachen und optimieren Sie die Datenbankleistung kontinuierlich. Nur indem Sie es geschickt beherrschen, müssen Sie die Erstellung und Verwaltung von Oracle -Datenbanken wirklich verstehen.
