
 Backend-Entwicklung
Python-Tutorial
Was ist das Implementierungsprinzip des Wörterbuchs in der virtuellen Python-Maschine?
Backend-Entwicklung
Python-Tutorial
Was ist das Implementierungsprinzip des Wörterbuchs in der virtuellen Python-Maschine?
Was ist das Implementierungsprinzip des Wörterbuchs in der virtuellen Python-Maschine?

Dictionary-Datenstrukturanalyse
/* The ma_values pointer is NULL for a combined table
* or points to an array of PyObject* for a split table
*/
typedef struct {
PyObject_HEAD
Py_ssize_t ma_used;
PyDictKeysObject *ma_keys;
PyObject **ma_values;
} PyDictObject;
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
Py_ssize_t dk_size;
dict_lookup_func dk_lookup;
Py_ssize_t dk_usable;
PyDictKeyEntry dk_entries[1];
};
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value; /* This field is only meaningful for combined tables */
} PyDictKeyEntry;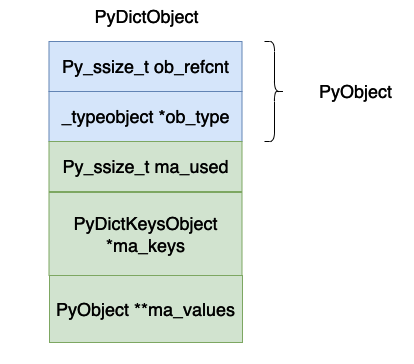
Die Bedeutung jedes Feldes oben ist:
ob_refcnt, der Referenzzähler des Objekts.
ob_type, der Datentyp des Objekts.
ma_used, die Anzahl der Daten in der aktuellen Hash-Tabelle.
ma_keys, zeigt auf das Array, das Schlüssel-Wert-Paare enthält.
ma_values, dies ist ein Array, das auf Werte zeigt, aber dieser Wert wird nicht unbedingt in der spezifischen Implementierung von cpython verwendet, da die Objekte im PyDictKeyEntry-Array in _dictkeysobject auch Werte speichern können, wenn der Alle Schlüssel sind Zeichenfolgen. In diesem Artikel wird der Wert in PyDictKeyEntry hauptsächlich zur Erläuterung der Implementierung des Wörterbuchs verwendet. Sie können diese Variable daher ignorieren.
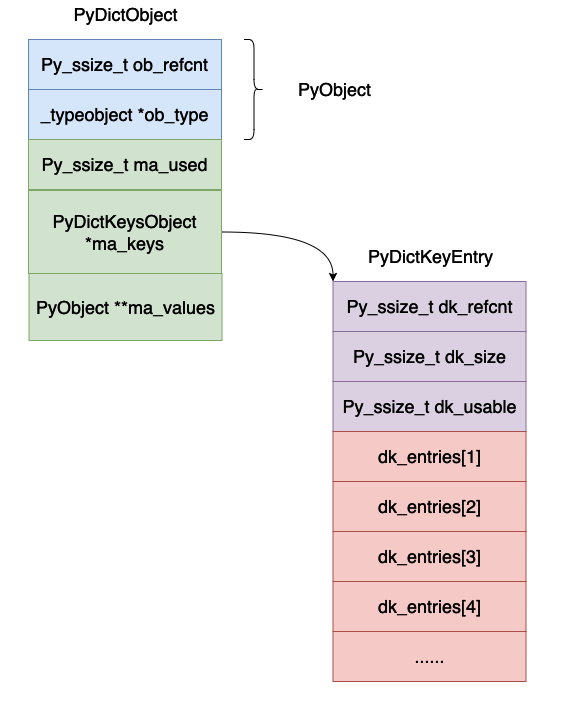
dk_refcnt, dies wird auch zur Darstellung der Referenzzählung verwendet. Dies hängt mit der Wörterbuchansicht zusammen. Das Prinzip ähnelt der Referenzzählung, daher werden wir es hier zunächst ignorieren.
dk_size, dies stellt die Größe der Hash-Tabelle dar, die 2n betragen muss. In diesem Fall kann die modulare Operation in eine bitweise UND-Operation umgewandelt werden.
dk_lookup, dies stellt die Suchfunktion der Hash-Tabelle dar, es ist ein Funktionszeiger.
dk_usable gibt an, wie viele Schlüssel-Wert-Paare im aktuellen Array verfügbar sind.
dk_entries, Hash-Tabelle, in der Schlüssel-Wert-Paare tatsächlich gespeichert werden.
Das Layout der gesamten Hash-Tabelle ist ungefähr wie in der folgenden Abbildung dargestellt:
Erstellen Sie ein neues Wörterbuchobjekt
Diese Funktion ist relativ einfach. Beantragen Sie zunächst Speicherplatz und führen Sie dann einige Initialisierungsvorgänge durch. und beantragen Sie die Hash-Tabelle zum Speichern von Schlüssel-Wert-Paaren.
static PyObject *
dict_new(PyTypeObject *type, PyObject *args, PyObject *kwds)
{
PyObject *self;
PyDictObject *d;
assert(type != NULL && type->tp_alloc != NULL);
// 申请内存空间
self = type->tp_alloc(type, 0);
if (self == NULL)
return NULL;
d = (PyDictObject *)self;
/* The object has been implicitly tracked by tp_alloc */
if (type == &PyDict_Type)
_PyObject_GC_UNTRACK(d);
// 因为还没有增加数据 因此哈希表当中 ma_used = 0
d->ma_used = 0;
// 申请保存键值对的数组 PyDict_MINSIZE_COMBINED 是一个宏定义 值为 8 表示哈希表数组的最小长度
d->ma_keys = new_keys_object(PyDict_MINSIZE_COMBINED);
// 如果申请失败返回 NULL
if (d->ma_keys == NULL) {
Py_DECREF(self);
return NULL;
}
return self;
}
// new_keys_object 函数如下所示
static PyDictKeysObject *new_keys_object(Py_ssize_t size)
{
PyDictKeysObject *dk;
Py_ssize_t i;
PyDictKeyEntry *ep0;
assert(size >= PyDict_MINSIZE_SPLIT);
assert(IS_POWER_OF_2(size));
// 这里是申请内存的位置真正申请内存空间的大小为 PyDictKeysObject 的大小加上 size-1 个PyDictKeyEntry的大小
// 这里你可能会有一位为啥不是 size 个 PyDictKeyEntry 的大小 因为在结构体 PyDictKeysObject 当中已经申请了一个 PyDictKeyEntry 对象了
dk = PyMem_MALLOC(sizeof(PyDictKeysObject) +
sizeof(PyDictKeyEntry) * (size-1));
if (dk == NULL) {
PyErr_NoMemory();
return NULL;
}
// 下面主要是一些初始化的操作 dk_refcnt 设置成 1 因为目前只有一个字典对象使用 这个 PyDictKeysObject 对象
DK_DEBUG_INCREF dk->dk_refcnt = 1;
dk->dk_size = size; // 哈希表的大小
// 下面这行代码主要是表示哈希表当中目前还能存储多少个键值对 在 cpython 的实现当中允许有 2/3 的数组空间去存储数据 超过这个数则需要进行扩容
dk->dk_usable = USABLE_FRACTION(size); // #define USABLE_FRACTION(n) ((((n) << 1)+1)/3)
ep0 = &dk->dk_entries[0];
/* Hash value of slot 0 is used by popitem, so it must be initialized */
ep0->me_hash = 0;
// 将所有的键值对初始化成 NULL
for (i = 0; i < size; i++) {
ep0[i].me_key = NULL;
ep0[i].me_value = NULL;
}
dk->dk_lookup = lookdict_unicode_nodummy;
return dk;
}Hash-Tabellen-Erweiterungsmechanismus
Lassen Sie uns zunächst den Erweiterungsmechanismus der Hash-Tabelle in der Wörterbuchimplementierung verstehen. Wenn wir dem Wörterbuch weiterhin neue Daten hinzufügen, werden die Daten im Wörterbuch bald die Array-Länge erreichen 23. Zu diesem Zeitpunkt ist eine Erweiterung erforderlich. Die Array-Größe nach der Erweiterung wird wie folgt berechnet:
#define GROWTH_RATE(d) (((d)->ma_used*2)+((d)->ma_keys->dk_size>>1))
Die Größe des neuen Arrays entspricht der Anzahl der ursprünglichen Schlüssel-Wert-Paare multipliziert mit 2 plus der Hälfte der ursprünglichen Array-Länge .
Im Allgemeinen gibt es drei Hauptschritte zur Erweiterung:
Berechnen Sie die Größe des neuen Arrays.
Neues Array erstellen.
Fügen Sie die Daten in der ursprünglichen Hash-Tabelle zum neuen Array hinzu (dh den Prozess des erneuten Hashings).
Der spezifische Implementierungscode lautet wie folgt:
static int
insertion_resize(PyDictObject *mp)
{
return dictresize(mp, GROWTH_RATE(mp));
}
static int
dictresize(PyDictObject *mp, Py_ssize_t minused)
{
Py_ssize_t newsize;
PyDictKeysObject *oldkeys;
PyObject **oldvalues;
Py_ssize_t i, oldsize;
// 下面的代码的主要作用就是计算得到能够大于等于 minused 最小的 2 的整数次幂
/* Find the smallest table size > minused. */
for (newsize = PyDict_MINSIZE_COMBINED;
newsize <= minused && newsize > 0;
newsize <<= 1)
;
if (newsize <= 0) {
PyErr_NoMemory();
return -1;
}
oldkeys = mp->ma_keys;
oldvalues = mp->ma_values;
/* Allocate a new table. */
// 创建新的数组
mp->ma_keys = new_keys_object(newsize);
if (mp->ma_keys == NULL) {
mp->ma_keys = oldkeys;
return -1;
}
if (oldkeys->dk_lookup == lookdict)
mp->ma_keys->dk_lookup = lookdict;
oldsize = DK_SIZE(oldkeys);
mp->ma_values = NULL;
/* If empty then nothing to copy so just return */
if (oldsize == 1) {
assert(oldkeys == Py_EMPTY_KEYS);
DK_DECREF(oldkeys);
return 0;
}
/* Main loop below assumes we can transfer refcount to new keys
* and that value is stored in me_value.
* Increment ref-counts and copy values here to compensate
* This (resizing a split table) should be relatively rare */
if (oldvalues != NULL) {
for (i = 0; i < oldsize; i++) {
if (oldvalues[i] != NULL) {
Py_INCREF(oldkeys->dk_entries[i].me_key);
oldkeys->dk_entries[i].me_value = oldvalues[i];
}
}
}
/* Main loop */
// 将原来数组当中的元素加入到新的数组当中
for (i = 0; i < oldsize; i++) {
PyDictKeyEntry *ep = &oldkeys->dk_entries[i];
if (ep->me_value != NULL) {
assert(ep->me_key != dummy);
insertdict_clean(mp, ep->me_key, ep->me_hash, ep->me_value);
}
}
// 更新一下当前哈希表当中能够插入多少数据
mp->ma_keys->dk_usable -= mp->ma_used;
if (oldvalues != NULL) {
/* NULL out me_value slot in oldkeys, in case it was shared */
for (i = 0; i < oldsize; i++)
oldkeys->dk_entries[i].me_value = NULL;
assert(oldvalues != empty_values);
free_values(oldvalues);
DK_DECREF(oldkeys);
}
else {
assert(oldkeys->dk_lookup != lookdict_split);
if (oldkeys->dk_lookup != lookdict_unicode_nodummy) {
PyDictKeyEntry *ep0 = &oldkeys->dk_entries[0];
for (i = 0; i < oldsize; i++) {
if (ep0[i].me_key == dummy)
Py_DECREF(dummy);
}
}
assert(oldkeys->dk_refcnt == 1);
DK_DEBUG_DECREF PyMem_FREE(oldkeys);
}
return 0;
}Daten in das Wörterbuch einfügen
Wenn wir weiterhin Daten in das Wörterbuch einfügen, ist es wahrscheinlich, dass wir auf Hash-Konflikte stoßen. Die Methode des Wörterbuchs zur Behandlung von Hash-Konflikten ist im Grunde eine Menge Die Methoden zur Behandlung von Hash-Konflikten sind alle ähnlich. Die Implementierung dieser offenen Adressmethode ist jedoch wie folgt:
rrreeDas obige ist der detaillierte Inhalt vonWas ist das Implementierungsprinzip des Wörterbuchs in der virtuellen Python-Maschine?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, hochrangige skalierbare Python-Datenbank Hadidb (HadIDB) ist eine leichte Datenbank in Python mit einem hohen Maß an Skalierbarkeit. Installieren Sie HadIDB mithilfe der PIP -Installation: PipinstallHadIDB -Benutzerverwaltung erstellen Benutzer: createUser (), um einen neuen Benutzer zu erstellen. Die Authentication () -Methode authentifiziert die Identität des Benutzers. fromHadidb.operationImportUseruser_obj = user ("admin", "admin") user_obj.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
MySQL kann ohne Netzwerkverbindungen für die grundlegende Datenspeicherung und -verwaltung ausgeführt werden. Für die Interaktion mit anderen Systemen, Remotezugriff oder Verwendung erweiterte Funktionen wie Replikation und Clustering ist jedoch eine Netzwerkverbindung erforderlich. Darüber hinaus sind Sicherheitsmaßnahmen (wie Firewalls), Leistungsoptimierung (Wählen Sie die richtige Netzwerkverbindung) und die Datensicherung für die Verbindung zum Internet von entscheidender Bedeutung.
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 Kann sich MySQL Workbench mit Mariadb verbinden?
Apr 08, 2025 pm 02:33 PM
Kann sich MySQL Workbench mit Mariadb verbinden?
Apr 08, 2025 pm 02:33 PM
MySQL Workbench kann eine Verbindung zu MariADB herstellen, vorausgesetzt, die Konfiguration ist korrekt. Wählen Sie zuerst "Mariadb" als Anschlusstyp. Stellen Sie in der Verbindungskonfiguration Host, Port, Benutzer, Kennwort und Datenbank korrekt ein. Überprüfen Sie beim Testen der Verbindung, ob der Mariadb -Dienst gestartet wird, ob der Benutzername und das Passwort korrekt sind, ob die Portnummer korrekt ist, ob die Firewall Verbindungen zulässt und ob die Datenbank vorhanden ist. Verwenden Sie in fortschrittlicher Verwendung die Verbindungspooling -Technologie, um die Leistung zu optimieren. Zu den häufigen Fehlern gehören unzureichende Berechtigungen, Probleme mit Netzwerkverbindung usw. Bei Debugging -Fehlern, sorgfältige Analyse von Fehlerinformationen und verwenden Sie Debugging -Tools. Optimierung der Netzwerkkonfiguration kann die Leistung verbessern
 So lösen Sie MySQL können keine Verbindung zum lokalen Host herstellen
Apr 08, 2025 pm 02:24 PM
So lösen Sie MySQL können keine Verbindung zum lokalen Host herstellen
Apr 08, 2025 pm 02:24 PM
Die MySQL -Verbindung kann auf die folgenden Gründe liegen: MySQL -Dienst wird nicht gestartet, die Firewall fängt die Verbindung ab, die Portnummer ist falsch, der Benutzername oder das Kennwort ist falsch, die Höradresse in my.cnf ist nicht ordnungsgemäß konfiguriert usw. Die Schritte zur Fehlerbehebung umfassen: 1. Überprüfen Sie, ob der MySQL -Dienst ausgeführt wird. 2. Passen Sie die Firewall -Einstellungen an, damit MySQL Port 3306 anhören kann. 3. Bestätigen Sie, dass die Portnummer mit der tatsächlichen Portnummer übereinstimmt. 4. Überprüfen Sie, ob der Benutzername und das Passwort korrekt sind. 5. Stellen Sie sicher, dass die Einstellungen für die Bindungsadresse in my.cnf korrekt sind.
 Benötigt MySQL einen Server?
Apr 08, 2025 pm 02:12 PM
Benötigt MySQL einen Server?
Apr 08, 2025 pm 02:12 PM
Für Produktionsumgebungen ist in der Regel ein Server erforderlich, um MySQL auszuführen, aus Gründen, einschließlich Leistung, Zuverlässigkeit, Sicherheit und Skalierbarkeit. Server haben normalerweise leistungsstärkere Hardware, redundante Konfigurationen und strengere Sicherheitsmaßnahmen. Bei kleinen Anwendungen mit niedriger Last kann MySQL auf lokalen Maschinen ausgeführt werden, aber Ressourcenverbrauch, Sicherheitsrisiken und Wartungskosten müssen sorgfältig berücksichtigt werden. Für eine größere Zuverlässigkeit und Sicherheit sollte MySQL auf Cloud oder anderen Servern bereitgestellt werden. Die Auswahl der entsprechenden Serverkonfiguration erfordert eine Bewertung basierend auf Anwendungslast und Datenvolumen.
