

Klassifizierungsmodelle können in zwei Kategorien unterteilt werden: generative Modelle und diskriminative Modelle. In diesem Artikel werden die Unterschiede zwischen diesen beiden Modelltypen erläutert und die Vor- und Nachteile jedes Ansatzes erörtert.
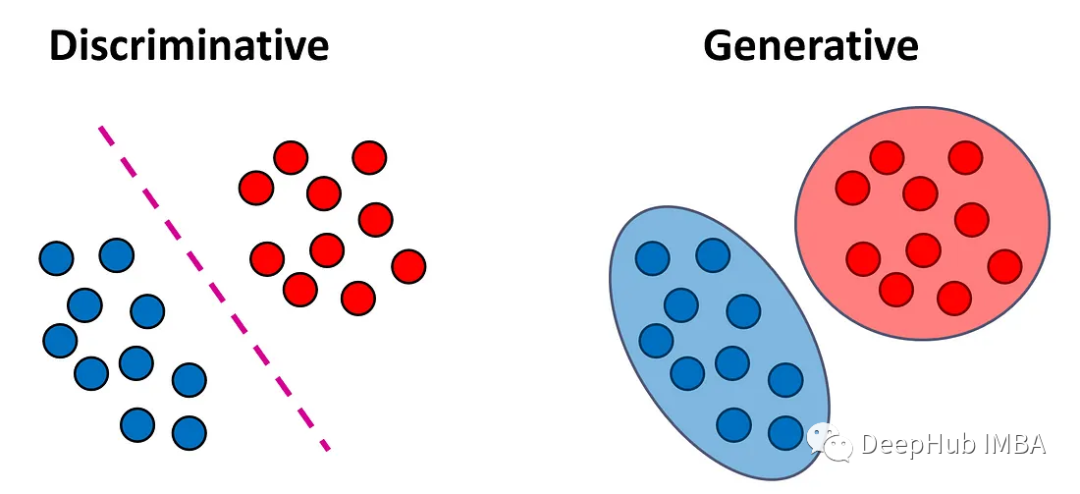
Das diskriminierende Modell ist ein Modell, das die Beziehung zwischen Eingabedaten und Ausgabeetiketten lernen kann Ausgabebeschriftungen durch Lernen von Merkmalen der Eingabedaten. Bei einem Klassifizierungsproblem besteht unser Ziel darin, jedem Eingabevektor x eine Bezeichnung y zuzuordnen. Diskriminative Modelle versuchen, direkt eine Funktion f(x) zu lernen, die Eingabevektoren Beschriftungen zuordnet. Diese Modelle können weiter in zwei Untertypen unterteilt werden:
Klassifikatoren versuchen, f(x) zu finden, ohne eine Wahrscheinlichkeitsverteilung zu verwenden. Diese Klassifikatoren geben für jede Stichprobe direkt eine Bezeichnung aus, ohne eine Wahrscheinlichkeitsschätzung der Klasse bereitzustellen. Diese Klassifikatoren werden oft als deterministische Klassifikatoren oder verteilungsfreie Klassifikatoren bezeichnet. Beispiele für solche Klassifikatoren sind k-nächste Nachbarn, Entscheidungsbäume und SVM.
Der Klassifikator lernt zunächst die Wahrscheinlichkeiten der hinteren Klasse P(y = k|x) aus den Trainingsdaten und ordnet basierend auf diesen Wahrscheinlichkeiten eine neue Stichprobe x einer der Klassen zu (normalerweise die mit dem höchste hintere Wahrscheinlichkeitsklasse).
Diese Klassifikatoren werden oft als probabilistische Klassifikatoren bezeichnet. Beispiele für solche Klassifikatoren sind die logistische Regression und neuronale Netze, die Sigmoid- oder Softmax-Funktionen in der Ausgabeschicht verwenden.
Wenn alle Dinge gleich sind, verwende ich im Allgemeinen einen probabilistischen Klassifikator anstelle eines deterministischen Klassifikators, da dieser Klassifikator zusätzliche Informationen über die Konfidenz bei der Zuordnung einer Stichprobe zu einer bestimmten Klasse liefert.
Allgemeine Diskriminanzmodelle umfassen:
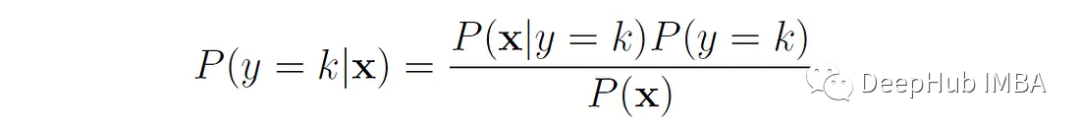
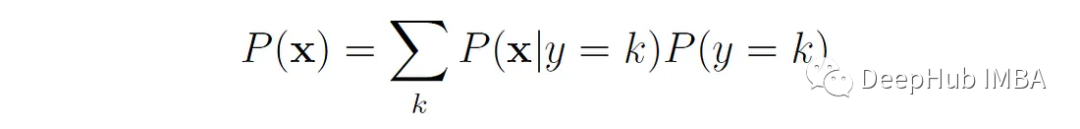
Die Trainingskomplexität ist hoch, da das generative Modell eine große Menge an Rechen- und Speicherressourcen erfordert, um eine gemeinsame Verteilung zwischen Eingabedaten und Ausgabedaten herzustellen. Die Annahme der Datenverteilung ist relativ stark, da das generative Modell eine gemeinsame Verteilung zwischen den Eingabedaten und den Ausgabedaten herstellen und die Verteilung der Daten annehmen und modellieren muss. Daher ist das generative Modell für eine komplexe Datenverteilung erforderlich eignet sich für kleine Rechenressourcen. Nicht anwendbar.
Generative Modelle können multimodale Daten verarbeiten, da generative Modelle multivariate gemeinsame Verteilungen zwischen Eingabedaten und Ausgabedaten erstellen können und dadurch multimodale Daten verarbeiten können.
Diskriminatives Modell:
Für ein generatives Modell ist es rechnerisch schwierig, die Eingabeverteilung P(x|y) zu lernen, ohne einige Annahmen über die Daten zu treffen, um beispielsweise P vorherzusagen (x |y)-Modellierung müssen wir 2 ᵐ Parameter aus den Daten jeder Klasse schätzen (diese Parameter stellen die bedingte Wahrscheinlichkeit jeder der 2 ᵐ Kombinationen von m Merkmalen dar). Modelle wie Naive Bayes gehen von einer bedingten Unabhängigkeit der Merkmale aus, um die Anzahl der zu erlernenden Parameter zu reduzieren, sodass die Trainingskomplexität gering ist. Solche Annahmen führen jedoch häufig dazu, dass generative Modelle schlechtere Ergebnisse erzielen als diskriminierende Modelle.
Gute Leistung bei komplexer Datenverteilung und hochdimensionalen Daten, da das diskriminative Modell die Zuordnungsbeziehung zwischen Eingabedaten und Ausgabedaten flexibel modellieren kann.
Das diskriminierende Modell reagiert empfindlich auf verrauschte Daten und fehlende Daten, da das Modell nur die Zuordnungsbeziehung zwischen Eingabedaten und Ausgabedaten berücksichtigt und die Informationen in den Eingabedaten nicht zum Ausfüllen fehlender Werte und zum Entfernen von Rauschen verwendet.
Generative Modelle und diskriminative Modelle sind beide wichtige Modelltypen beim maschinellen Lernen. Sie haben jeweils ihre eigenen Vorteile und anwendbaren Szenarien. In praktischen Anwendungen ist es notwendig, ein geeignetes Modell entsprechend den Anforderungen spezifischer Aufgaben auszuwählen und Hybridmodelle und andere technische Mittel zu kombinieren, um die Leistung und Wirkung des Modells zu verbessern.
Das obige ist der detaillierte Inhalt vonGenerative und diskriminierende Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So verwenden Sie Subplot in Matlab
So verwenden Sie Subplot in Matlab
 Was soll ich tun, wenn die Reiseroutenkarte nicht geöffnet werden kann?
Was soll ich tun, wenn die Reiseroutenkarte nicht geöffnet werden kann?
 Schritte zur SpringBoot-Projekterstellung
Schritte zur SpringBoot-Projekterstellung
 Was sind die Konfigurationsparameter des Videoservers?
Was sind die Konfigurationsparameter des Videoservers?
 Einführung in die Verwendung der Achsenfunktion in Matlab
Einführung in die Verwendung der Achsenfunktion in Matlab
 Handy-Bildschirm tft
Handy-Bildschirm tft
 So importieren Sie MDF-Dateien in die Datenbank
So importieren Sie MDF-Dateien in die Datenbank
 Löschen Sie redundante Tabellen in der Tabelle
Löschen Sie redundante Tabellen in der Tabelle
 So implementieren Sie die Online-Chat-Funktion von Vue
So implementieren Sie die Online-Chat-Funktion von Vue








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



