
 Betrieb und Instandhaltung
Betrieb und Wartung von Linux
Was ist der Befehl zum Überprüfen der Linux-Leistung?
Betrieb und Instandhaltung
Betrieb und Wartung von Linux
Was ist der Befehl zum Überprüfen der Linux-Leistung?
Was ist der Befehl zum Überprüfen der Linux-Leistung?

1.uptime

Mit diesem Befehl kann der Auslastungsstatus der Maschine schnell überprüft werden. In Linux-Systemen stellen diese Daten die Anzahl der Prozesse dar, die auf CPU-Ressourcen warten und in unterbrechungsfreien E/A-Prozessen blockiert sind (Prozessstatus ist D). Diese Daten können uns ein umfassendes Verständnis der Systemressourcennutzung vermitteln.
Die Ausgabe des Befehls gibt die durchschnittlichen Lastbedingungen für 1 Minute, 5 Minuten bzw. 15 Minuten an. Anhand dieser drei Daten können Sie erkennen, ob die Serverlast in der Region knapper wird oder nachlässt. Wenn die durchschnittliche 1-Minuten-Auslastung sehr hoch und die 15-minütige durchschnittliche Auslastung sehr niedrig ist, bedeutet dies, dass der Server eine hohe Auslastung aufweist und Sie weiter untersuchen müssen, wo die CPU-Ressourcen verbraucht werden. Wenn andererseits der 15-Minuten-Auslastungsdurchschnitt hoch und der 1-Minuten-Auslastungsdurchschnitt niedrig ist, ist es möglich, dass die Zeit, in der die CPU-Ressourcen knapp sind, vorbei ist. Wenn die durchschnittliche Last in der letzten Minute viel höher ist als die Last in 15 Minuten, müssen wir zur Fehlerbehebung die Befehle vmstat und mpstat verwenden.
2.dmesg|tail
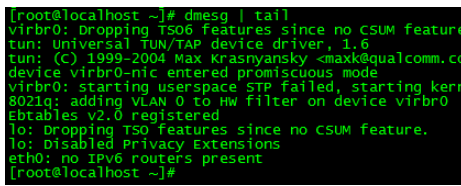
dmesgDieser Befehl wird verwendet, um Startinformationen anzuzeigen
dmesg |tail Dieser Befehl gibt die letzten 10 Zeilen des Systemprotokolls aus Systeminformationen Kernindikatoren. Diese Indikatoren ermöglichen es uns, den Systemstatus detaillierter zu verstehen. Der folgende Parameter 2 gibt an, dass alle zwei Sekunden statistische Informationen ausgegeben werden. Die Kopfzeile gibt die Bedeutung jeder Spalte an. Diese Spalten stellen einige Spalten im Zusammenhang mit der Leistungsoptimierung dar:
r: Warten auf die Anzahl der Prozesse auf CPU-Ressourcen . Diese Daten spiegeln die CPU-Auslastung besser wider als die durchschnittliche Auslastung. Die Daten umfassen keine Prozesse, die auf E/A warten. Wenn dieser Wert größer ist als die Anzahl der CPU-Kerne der Maschine, sind die CPU-Ressourcen der Maschine ausgelastet.
frei: Die Menge des verfügbaren Systemspeichers (in Kilobyte). Wenn der verbleibende Speicher nicht ausreicht, führt dies ebenfalls zu Systemleistungsproblemen. Der unten vorgestellte kostenlose Befehl kann ein detaillierteres Verständnis der Systemspeichernutzung liefern. 
Dieser Befehl kann die Auslastung jeder CPU anzeigen, wenn eine CPU-Auslastung vorliegt Wenn es besonders hoch ist, kann es an einer Single-Threaded-Anwendung liegen.
5.pidstat1
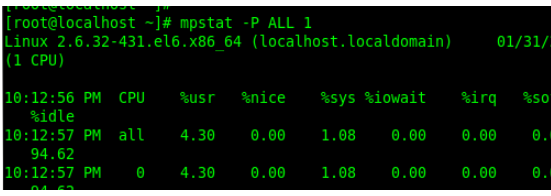
Der Befehl pidstat gibt die CPU-Auslastung des Prozesses aus Vorherige Daten können nicht überschrieben werden.
6.iostat-xz1
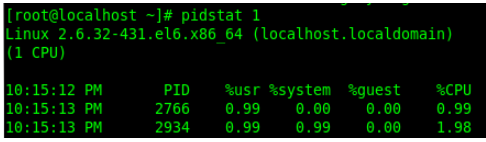
Der Befehl iostat wird hauptsächlich zum Überprüfen der IO-Situation der Maschinenfestplatte verwendet. Die Hauptbedeutung der von diesem Befehl ausgegebenen Spalten ist:
r/s,w/s,rkB/s,wkB/s: repräsentieren jeweils die Anzahl der Lese- und Schreibvorgänge pro Sekunde und die Anzahl der gelesene und geschriebene Daten pro Sekunde (Tausende) Byte). Ein zu hohes Lese- und Schreibvolumen kann zu Leistungsproblemen führen.
await: Die durchschnittliche Wartezeit für E/A-Vorgänge in Millisekunden. Dies ist die Zeit, die die Anwendung für die Interaktion mit der Festplatte aufwenden muss, einschließlich E/A-Wartezeit und tatsächlicher Betriebszeit. Wenn dieser Wert zu groß ist, liegt möglicherweise ein Engpass oder eine Fehlfunktion des Hardwaregeräts vor. 
Der Befehl free kann verwendet werden, um die Systemspeichernutzung zu überprüfen. Die letzten beiden Spalten stellen die für den E/A-Cache verwendete Speichermenge bzw. die für den Dateisystem-Seiten-Cache verwendete Speichermenge dar. Es ist zu beachten, dass in der zweiten Zeile -/+buffers/cache der Cache anscheinend viel Speicherplatz beansprucht. Dies ist die Speichernutzungsstrategie des Linux-Systems. Nutzen Sie den Speicher so weit wie möglich. Wenn die Anwendung Speicher benötigt, wird dieser Teil des Speichers sofort zurückgefordert und der Anwendung zugewiesen. Daher wird dieser Teil des Speichers im Allgemeinen als verfügbarer Speicher betrachtet.
Wenn nur sehr wenig Speicher verfügbar ist, verwendet das System möglicherweise den Swap-Bereich (sofern konfiguriert), was den E/A-Overhead erhöht (kann im Befehl iostat zurückgezogen werden) und die Systemleistung verringert.
8.sar-nDEV1
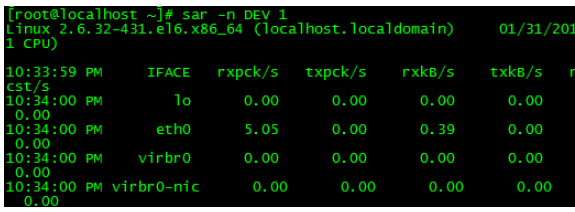
sar-Befehl kann hier die Durchsatzrate des Netzwerkgeräts überprüfen. Bei der Behebung von Leistungsproblemen können Sie anhand des Durchsatzes des Netzwerkgeräts beurteilen, ob das Netzwerkgerät ausgelastet ist. Wie in der Beispielausgabe hat das Netzwerkkartengerät eth0 eine Durchsatzrate von nur etwa 0,39 MByte/s :
aktiv /s: Die Anzahl der lokal initiierten TCP-Verbindungen pro Sekunde, also der TCP-Verbindungen, die durch den Verbindungsaufruf erstellt wurden.
passiv/s: Die Anzahl der remote initiierten TCP-Verbindungen pro Sekunde, also der TCP Durch den Accept-Aufruf erstellte Verbindungen; 
Die erste Zeile enthält die Informationen zur Aufgabenwarteschlange, die mit dem Ausführungsergebnis des Uptime-Befehls identisch sind: Die erste Spalte gibt die aktuelle Uhrzeit an, die zweite Spalte gibt an, wie lange das System bereits läuft läuft, und die dritte Spalte gibt die aktuelle Anzahl der angemeldeten Personen an. Der letzte Lastdurchschnitt stellt die Systemlast dar (die drei Werte sind: der Lastdurchschnitt von vor 1 Minute, 5 Minuten und 15 Minuten bis jetzt). Die Spalte stellt die Prozessinformationen dar, was sehr intuitiv ist.
Das obige ist der detaillierte Inhalt vonWas ist der Befehl zum Überprüfen der Linux-Leistung?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 Welche Computerkonfiguration ist für VSCODE erforderlich?
Apr 15, 2025 pm 09:48 PM
Welche Computerkonfiguration ist für VSCODE erforderlich?
Apr 15, 2025 pm 09:48 PM
VS Code system requirements: Operating system: Windows 10 and above, macOS 10.12 and above, Linux distribution processor: minimum 1.6 GHz, recommended 2.0 GHz and above memory: minimum 512 MB, recommended 4 GB and above storage space: minimum 250 MB, recommended 1 GB and above other requirements: stable network connection, Xorg/Wayland (Linux)
 VSCODE kann die Erweiterung nicht installieren
Apr 15, 2025 pm 07:18 PM
VSCODE kann die Erweiterung nicht installieren
Apr 15, 2025 pm 07:18 PM
Die Gründe für die Installation von VS -Code -Erweiterungen können sein: Netzwerkinstabilität, unzureichende Berechtigungen, Systemkompatibilitätsprobleme, VS -Code -Version ist zu alt, Antiviren -Software oder Firewall -Interferenz. Durch Überprüfen von Netzwerkverbindungen, Berechtigungen, Protokolldateien, Aktualisierungen von VS -Code, Deaktivieren von Sicherheitssoftware und Neustart von Code oder Computern können Sie Probleme schrittweise beheben und beheben.
 So führen Sie Java -Code in Notepad aus
Apr 16, 2025 pm 07:39 PM
So führen Sie Java -Code in Notepad aus
Apr 16, 2025 pm 07:39 PM
Obwohl Notepad den Java -Code nicht direkt ausführen kann, kann er durch Verwendung anderer Tools erreicht werden: Verwenden des Befehlszeilencompilers (JAVAC), um eine Bytecode -Datei (Dateiname.class) zu generieren. Verwenden Sie den Java Interpreter (Java), um Bytecode zu interpretieren, den Code auszuführen und das Ergebnis auszugeben.
 Kann VSCODE für MAC verwendet werden
Apr 15, 2025 pm 07:36 PM
Kann VSCODE für MAC verwendet werden
Apr 15, 2025 pm 07:36 PM
VS -Code ist auf Mac verfügbar. Es verfügt über leistungsstarke Erweiterungen, GIT -Integration, Terminal und Debugger und bietet auch eine Fülle von Setup -Optionen. Für besonders große Projekte oder hoch berufliche Entwicklung kann VS -Code jedoch Leistung oder funktionale Einschränkungen aufweisen.
 Wofür ist VSCODE Wofür ist VSCODE?
Apr 15, 2025 pm 06:45 PM
Wofür ist VSCODE Wofür ist VSCODE?
Apr 15, 2025 pm 06:45 PM
VS Code ist der vollständige Name Visual Studio Code, der eine kostenlose und open-Source-plattformübergreifende Code-Editor und Entwicklungsumgebung von Microsoft ist. Es unterstützt eine breite Palette von Programmiersprachen und bietet Syntax -Hervorhebung, automatische Codebettel, Code -Snippets und intelligente Eingabeaufforderungen zur Verbesserung der Entwicklungseffizienz. Durch ein reiches Erweiterungs -Ökosystem können Benutzer bestimmte Bedürfnisse und Sprachen wie Debugger, Code -Formatierungs -Tools und Git -Integrationen erweitern. VS -Code enthält auch einen intuitiven Debugger, mit dem Fehler in Ihrem Code schnell gefunden und behoben werden können.
 So verwenden Sie VSCODE
Apr 15, 2025 pm 11:21 PM
So verwenden Sie VSCODE
Apr 15, 2025 pm 11:21 PM
Visual Studio Code (VSCODE) ist ein plattformübergreifender, Open-Source-Editor und kostenloser Code-Editor, der von Microsoft entwickelt wurde. Es ist bekannt für seine leichte, Skalierbarkeit und Unterstützung für eine Vielzahl von Programmiersprachen. Um VSCODE zu installieren, besuchen Sie bitte die offizielle Website, um das Installateur herunterzuladen und auszuführen. Bei der Verwendung von VSCODE können Sie neue Projekte erstellen, Code bearbeiten, Code bearbeiten, Projekte navigieren, VSCODE erweitern und Einstellungen verwalten. VSCODE ist für Windows, MacOS und Linux verfügbar, unterstützt mehrere Programmiersprachen und bietet verschiedene Erweiterungen über den Marktplatz. Zu den Vorteilen zählen leicht, Skalierbarkeit, umfangreiche Sprachunterstützung, umfangreiche Funktionen und Versionen
 Was ist der Hauptzweck von Linux?
Apr 16, 2025 am 12:19 AM
Was ist der Hauptzweck von Linux?
Apr 16, 2025 am 12:19 AM
Zu den Hauptanwendungen von Linux gehören: 1. Server -Betriebssystem, 2. Eingebettes System, 3. Desktop -Betriebssystem, 4. Entwicklungs- und Testumgebung. Linux zeichnet sich in diesen Bereichen aus und bietet Stabilität, Sicherheits- und effiziente Entwicklungstools.
 So überprüfen Sie die Lageradresse von Git
Apr 17, 2025 pm 01:54 PM
So überprüfen Sie die Lageradresse von Git
Apr 17, 2025 pm 01:54 PM
Um die Git -Repository -Adresse anzuzeigen, führen Sie die folgenden Schritte aus: 1. Öffnen Sie die Befehlszeile und navigieren Sie zum Repository -Verzeichnis; 2. Führen Sie den Befehl "git remote -v" aus; 3.. Zeigen Sie den Repository -Namen in der Ausgabe und der entsprechenden Adresse an.
