

Auswahl der besten GPU für Deep Learning

Bei der Arbeit an maschinellen Lernprojekten, insbesondere wenn es um Deep Learning und neuronale Netze geht, ist es besser, mit einer GPU statt mit einer CPU zu arbeiten, da selbst eine sehr einfache GPU eine CPU übertrifft, wenn es um neuronale Netze geht.

Aber welche GPU sollten Sie kaufen? In diesem Artikel werden die relevanten Faktoren zusammengefasst, die Sie berücksichtigen sollten, damit Sie basierend auf Ihrem Budget und Ihren spezifischen Modellierungsanforderungen eine fundierte Entscheidung treffen können.
Warum eignet sich die GPU besser für maschinelles Lernen als die CPU?
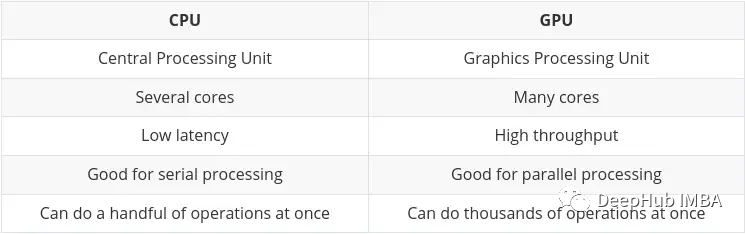
CPU (Central Processing Unit) ist die Hauptaufgabe des Computers. Sie ist sehr flexibel und muss nicht nur Anweisungen von verschiedenen Programmen und Hardware verarbeiten, sondern stellt auch bestimmte Anforderungen an die Verarbeitungsgeschwindigkeit. Um in dieser Multitasking-Umgebung eine gute Leistung zu erbringen, verfügt eine CPU über eine kleine Anzahl flexibler und schneller Verarbeitungseinheiten (auch Kerne genannt).
GPU (Graphics Processing Unit) GPU ist nicht so flexibel, wenn es um Multitasking geht. Aber es kann große Mengen komplexer mathematischer Berechnungen parallel durchführen. Dies wird durch eine größere Anzahl einfacher Kerne (Tausende bis Zehntausende) erreicht, die viele einfache Berechnungen gleichzeitig durchführen können.
Die Anforderung, mehrere Berechnungen parallel durchzuführen, ist ideal für:
- Grafik-Rendering – sich bewegende Grafikobjekte müssen ihre Flugbahnen ständig berechnen, was eine große Anzahl paralleler mathematischer Berechnungen erfordert, die ständig wiederholt werden.
- Maschinelles und tiefes Lernen – Eine große Anzahl von Matrix-/Tensorberechnungen kann die GPU parallel verarbeiten.
- Jede Art mathematischer Berechnung kann aufgeteilt werden, um parallel ausgeführt zu werden.
Die wichtigsten Unterschiede zwischen CPUs und GPUs wurden auf Nvidias eigenem Blog zusammengefasst:
Tensor Processing Unit (TPU)
Mit der Entwicklung von künstlicher Intelligenz und maschinellem/tiefem Lernen gibt es jetzt mehr spezialisierte Verarbeitungskerne , sogenannte Tensorkerne. Sie sind schneller und effizienter bei der Durchführung von Tensor-/Matrixberechnungen. Denn der Datentyp, mit dem wir uns beim maschinellen/tiefen Lernen befassen, sind Tensoren.
Obwohl es dedizierte TPUs gibt, enthalten einige der neuesten GPUs auch viele Tensorkerne, die wir später zusammenfassen.
Nvidia vs. AMD
Dies wird ein ziemlich kurzer Abschnitt sein, da die Antwort auf diese Frage definitiv Nvidia lautet.
Während es möglich ist, AMDs GPUs für maschinelles/tiefes Lernen zu verwenden, waren die GPUs von Nvidia zum Zeitpunkt des Verfassens dieses Artikels höher Kompatibilität und allgemein bessere Integration in Tools wie TensorFlow und PyTorch (z. B. ist die AMD-GPU-Unterstützung von PyTorch derzeit nur unter Linux verfügbar).
Für die Verwendung der AMD-GPU sind zusätzliche Tools (ROCm) erforderlich, die etwas mehr Arbeit erfordern und die Version möglicherweise nicht schnell aktualisiert wird. Diese Situation könnte sich in Zukunft verbessern, aber vorerst ist es besser, bei Nvidia zu bleiben.
Hauptmerkmale der GPU-Auswahl
Die Auswahl einer GPU, die für maschinelle Lernaufgaben geeignet ist und in Ihr Budget passt, hängt im Wesentlichen von vier Hauptfaktoren ab:
- Wie viel Speicher verfügt die GPU?
- Wie viele Verfügt die GPU über CUDA und/oder CUDA?
- Welche Chip-Architektur verwendet die Karte?
- Diese Aspekte werden im Folgenden einzeln besprochen, in der Hoffnung, Ihnen ein besseres Verständnis dafür zu vermitteln, was für Sie wichtig ist.
GPU-Speicher
Die Antwort lautet: Je mehr, desto besser!
Es hängt wirklich von Ihrer Aufgabe ab und davon, wie groß diese Modelle sind. Wenn Sie beispielsweise Bilder, Videos oder Audio verarbeiten, verarbeiten Sie per Definition eine ziemlich große Datenmenge, und der GPU-RAM ist ein sehr wichtiger Gesichtspunkt.
Es gibt immer Möglichkeiten, das Problem des unzureichenden Speichers zu lösen (z. B. durch Reduzierung der Stapelgröße). Dadurch wird jedoch Schulungszeit verschwendet, sodass die Anforderungen gut ausbalanciert werden müssen.
Aus Erfahrung empfehle ich Folgendes:
4 GB: Ich denke, das ist das absolute Minimum, und solange Sie es nicht mit übermäßig komplexen Modellen oder großen Bildern, Videos oder Audiodateien zu tun haben, reicht dies aus Funktioniert in den meisten Fällen, reicht aber für den täglichen Gebrauch nicht aus. Wenn Sie gerade erst anfangen und es ausprobieren möchten, ohne aufs Ganze zu gehen, dann fangen Sie damit an- 8 GB: Dies ist ein toller Start für das tägliche Lernen und kann die meisten Aufgaben erledigen, ohne das RAM-Limit zu überschreiten, aber es ist besser, es zu verwenden mehr Bei komplexen Bild-, Video- oder Audiomodellen können Probleme auftreten.
- 12GB: Ich denke, das ist die grundlegendste Voraussetzung für wissenschaftliche Forschung. Kann mit den meisten größeren Modellen umgehen, auch mit solchen, die mit Bildern, Video oder Audio arbeiten.
- 12 GB+: Je mehr desto besser, Sie können größere Datensätze und größere Stapelgrößen verarbeiten. Ab 12 GB beginnen die Preise wirklich zu steigen.
- Generell gilt: Bei gleichen Kosten ist es besser, eine „langsamere“ Karte mit mehr Speicher zu wählen. Bedenken Sie, dass der Vorteil von GPUs in einem hohen Durchsatz liegt, der stark vom verfügbaren RAM abhängt, um Daten über die GPU zu übertragen.
CUDA-Kerne und Tensor-Kerne
Das ist eigentlich ganz einfach, je mehr, desto besser.
Berücksichtigen Sie zuerst RAM, dann CUDA. Für maschinelles/tiefes Lernen sind Tensorkerne besser (schneller, effizienter) als CUDA-Kerne. Dies liegt daran, dass sie genau für die Berechnungen ausgelegt sind, die im Bereich des maschinellen/tiefen Lernens erforderlich sind.
Aber das spielt keine Rolle, denn CUDA-Kernel sind bereits schnell genug. Wenn Sie eine Karte bekommen können, die Tensor-Kerne enthält, ist das ein schönes Plus, aber lassen Sie sich nicht zu sehr darauf ein.
Sie werden später noch oft sehen, dass „CUDA“ erwähnt wird. Fassen wir es zunächst zusammen:
CUDA-Kerne – das sind die physischen Prozessoren auf der Grafikkarte, normalerweise sind es Tausende davon, 4090 sind bereits 16.000.
CUDA 11 – Zahlen können sich ändern, dies bezieht sich jedoch auf die installierte Software/Treiber, damit die Grafikkarte ordnungsgemäß funktioniert. NV veröffentlicht regelmäßig neue Versionen und kann wie jede andere Software installiert und aktualisiert werden.
CUDA Algebra (oder Rechenleistung) – Dies beschreibt den Codenamen der Grafikkarte in ihrer neueren Version. Dies ist fest in der Hardware verankert und kann daher nur durch ein Upgrade auf eine neue Karte geändert werden. Es wird durch Nummern und einen Codenamen unterschieden. Beispiel: 3. x[Kepler],5. x[Maxwell], 6. x [Pascal], 7. x[Turing] und 8. x(Ampere).
Chip-Architektur
Das ist tatsächlich wichtiger als Sie denken. Wir reden hier nicht über AMD, ich habe nur „Altgelb“ in meinen Augen.
Wir haben oben bereits erwähnt, dass die Karten der 30er-Serie Ampere-Architektur sind und die neuesten Karten der 40er-Serie Ada Lovelace sind. Normalerweise benennt Huang die Architektur nach einem berühmten Wissenschaftler und Mathematiker. Diesmal wählte er Ada Lovelace, die Tochter des berühmten britischen Dichters Byron, der Mathematikerin und Begründerin von Computerprogrammen, die die Konzepte von Schleifen und Unterprogrammen begründete.
Um die Rechenleistung der Karte zu verstehen, müssen wir zwei Aspekte verstehen:
- Signifikante Funktionsverbesserungen
- Eine wichtige Funktion hierbei ist das Training mit gemischter Präzision:
Verwenden Sie Zahlen mit einer Genauigkeit, die niedriger als 32-Bit-Gleitkomma ist Zahlen Das Format hat viele Vorteile. Erstens benötigen sie weniger Speicher, was das Training und den Einsatz größerer neuronaler Netze ermöglicht. Zweitens benötigen sie weniger Speicherbandbreite und beschleunigen so die Datenübertragungsvorgänge. Dritte mathematische Operationen laufen schneller und mit geringerer Präzision, insbesondere auf GPUs mit Tensor-Kernen. Beim gemischten Präzisionstraining werden alle diese Vorteile erreicht, ohne dass dabei die aufgabenspezifische Genauigkeit im Vergleich zum vollständigen Präzisionstraining verloren geht. Dies geschieht durch die Identifizierung von Schritten, die volle Präzision erfordern, und die Verwendung von 32-Bit-Gleitkomma nur für diese Schritte und 16-Bit-Gleitkomma überall sonst.
Hier ist das offizielle Nvidia-Dokument. Wenn Sie interessiert sind, können Sie einen Blick darauf werfen:
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html
Wenn Ihre GPU Hat 7.x (Turing) oder eine höhere Architektur, ist hybrides Präzisionstraining möglich. Das bedeutet RTX 20-Serie oder höher auf dem Desktop oder „T“- oder „A“-Serie auf dem Server.
Der Hauptgrund für die Vorteile des gemischten Präzisionstrainings besteht darin, dass die GPU des Tensor Core das gemischte Präzisionstraining beschleunigt. Wenn nicht, spart die Verwendung von FP16 auch größere Stapelgrößen, was indirekt die Trainingsgeschwindigkeit verbessert .
Wird es veraltet sein?
Wenn Sie besonders hohe Anforderungen an den Arbeitsspeicher haben, aber nicht genug Geld haben, um eine High-End-Karte zu kaufen, dann können Sie sich auf dem Gebrauchtmarkt für eine ältere GPU entscheiden. Das hat einen ziemlich großen Nachteil: Die Lebensdauer der Karte ist abgelaufen.
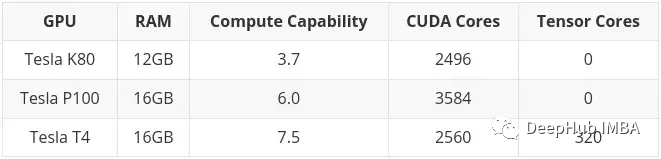
Ein typisches Beispiel ist Tesla K80, der über 4992 CUDA-Kerne und 24 GB RAM verfügt. Im Jahr 2014 kostete es etwa 7.000 US-Dollar. Der aktuelle Preis liegt zwischen 150 und 170 US-Dollar (der Preis für gesalzenen Fisch liegt bei etwa 600-700). Sie müssen sehr aufgeregt sein, einen so großen Speicher zu einem so kleinen Preis zu haben.
Aber es gibt ein sehr großes Problem. Die Computerarchitektur von K80 ist 3.7 (Kepler), die ab CUDA 11 nicht mehr unterstützt wird (die aktuelle CUDA-Version ist 11.7). Das bedeutet, dass die Karte abgelaufen ist, weshalb sie so günstig verkauft wird.
Überprüfen Sie daher bei der Auswahl einer gebrauchten Karte unbedingt, ob diese die neueste Treiber- und CUDA-Version unterstützt. Das ist das Wichtigste.
High-End-Gaming-Karten vs. Workstation-/Server-Karten
Lao Huang hat die Karte grundsätzlich in zwei Teile geteilt. Consumer-Grafikkarten und Workstation-/Server-Grafikkarten (d. h. professionelle Grafikkarten).
Es gibt einen deutlichen Unterschied zwischen den beiden Teilen, denn bei gleichen Spezifikationen (RAM, CUDA-Kerne, Architektur) sind Consumer-Grafikkarten in der Regel günstiger. Aber professionelle Karten haben in der Regel eine bessere Qualität und einen geringeren Energieverbrauch (tatsächlich ist das Geräusch der Turbine ziemlich laut, was in einem Computerraum in Ordnung ist, aber zu Hause oder im Labor etwas laut ist).
Bei hochwertigen (sehr teuren) professionellen Karten stellen Sie möglicherweise fest, dass sie über viel RAM verfügen (z. B. RTX A6000 hat 48 GB, A100 hat 80 GB!). Dies liegt daran, dass sie in der Regel auf die professionellen Märkte 3D-Modellierung, Rendering und maschinelles/tiefes Lernen abzielen, die viel RAM benötigen. Auch hier gilt: Wenn Sie Geld haben, kaufen Sie einfach A100 (H100 ist eine neue Version von A100 und kann derzeit nicht bewertet werden)
Aber ich persönlich denke, dass wir uns für High-End-Spielekarten für Endverbraucher entscheiden sollten, denn wenn es Ihnen nicht an Geld mangelt Geld, du wirst diesen Artikel auch nicht lesen, oder?
Vorschläge auswählen
Am Ende mache ich also einige Vorschläge basierend auf Budget und Bedürfnissen. Ich habe es in drei Teile unterteilt:
- Niedriges Budget
- Mittleres Budget
- Hohes Budget
Hohes Budget berücksichtigt nichts anderes als High-End-Consumer-Grafikkarten. Nochmals: Wenn Sie Geld haben: Kaufen Sie A100 oder H100.
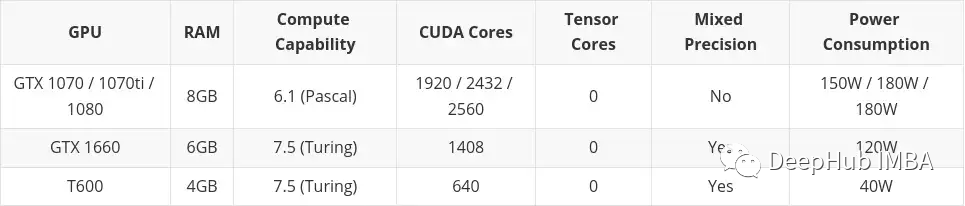
Dieser Artikel enthält Karten, die auf dem Gebrauchtmarkt gekauft wurden. Das liegt vor allem daran, dass ich glaube, dass Second Hand etwas ist, das man in Betracht ziehen sollte, wenn man über ein geringes Budget verfügt. Auch die Karten der Professional Desktop-Serie (T600, A2000 und A4000) sind hier enthalten, da ihre Konfigurationen teilweise etwas schlechter sind als vergleichbare Consumer-Grafikkarten, der Stromverbrauch jedoch deutlich besser ist.
low budget
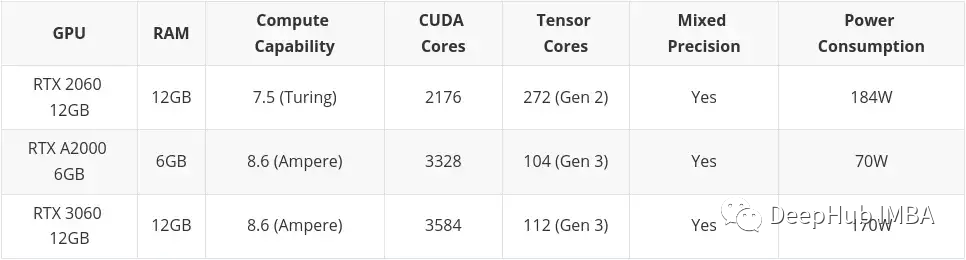
mittleres Budget
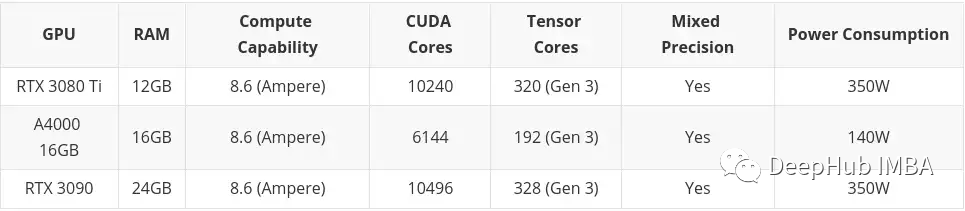
Wenn nicht Kaufen Sie es, ich werde es nicht kaufen, aber es wird morgen noch verfügbar sein Lassen Sie zweihundert fallen
Das obige ist der detaillierte Inhalt vonAuswahl der besten GPU für Deep Learning. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Das Grafikkarten-Erweiterungsdock Beelink EX verspricht keinen GPU-Leistungsverlust
Aug 11, 2024 pm 09:55 PM
Das Grafikkarten-Erweiterungsdock Beelink EX verspricht keinen GPU-Leistungsverlust
Aug 11, 2024 pm 09:55 PM
Eines der herausragenden Merkmale des kürzlich eingeführten Beelink GTi 14 ist, dass der Mini-PC über einen versteckten PCIe x8-Steckplatz an der Unterseite verfügt. Bei der Markteinführung gab das Unternehmen an, dass dies den Anschluss einer externen Grafikkarte an das System erleichtern würde. Beelink hat n
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 AMD FSR 3.1 eingeführt: Frame-Generierungsfunktion funktioniert auch auf Nvidia GeForce RTX- und Intel Arc-GPUs
Jun 29, 2024 am 06:57 AM
AMD FSR 3.1 eingeführt: Frame-Generierungsfunktion funktioniert auch auf Nvidia GeForce RTX- und Intel Arc-GPUs
Jun 29, 2024 am 06:57 AM
AMD löst sein ursprüngliches Versprechen vom 24. März ein und bringt FSR 3.1 im zweiten Quartal dieses Jahres auf den Markt. Was die Version 3.1 wirklich auszeichnet, ist die Entkopplung der Frame-Generierung von der Upscaling-Seite. Dadurch können Nvidia- und Intel-GPU-Besitzer den FSR 3 anwenden.
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
MetaFAIR hat sich mit Harvard zusammengetan, um einen neuen Forschungsrahmen zur Optimierung der Datenverzerrung bereitzustellen, die bei der Durchführung groß angelegten maschinellen Lernens entsteht. Es ist bekannt, dass das Training großer Sprachmodelle oft Monate dauert und Hunderte oder sogar Tausende von GPUs verwendet. Am Beispiel des Modells LLaMA270B erfordert das Training insgesamt 1.720.320 GPU-Stunden. Das Training großer Modelle stellt aufgrund des Umfangs und der Komplexität dieser Arbeitsbelastungen einzigartige systemische Herausforderungen dar. In letzter Zeit haben viele Institutionen über Instabilität im Trainingsprozess beim Training generativer SOTA-KI-Modelle berichtet. Diese treten normalerweise in Form von Verlustspitzen auf. Beim PaLM-Modell von Google kam es beispielsweise während des Trainingsprozesses zu Instabilitäten. Numerische Voreingenommenheit ist die Hauptursache für diese Trainingsungenauigkeit.
