
 Technologie-Peripheriegeräte
KI
Das Erstellen von Videos ist so einfach, geben Sie einfach einen Hinweis, und Sie können es auch online ausprobieren
Technologie-Peripheriegeräte
KI
Das Erstellen von Videos ist so einfach, geben Sie einfach einen Hinweis, und Sie können es auch online ausprobieren
Das Erstellen von Videos ist so einfach, geben Sie einfach einen Hinweis, und Sie können es auch online ausprobieren

Sie geben Text ein und lassen die KI ein Video erstellen. Diese Idee erschien bisher nur in der Fantasie der Menschen. Mit der Entwicklung der Technologie wurde diese Funktion nun realisiert.
In den letzten Jahren hat generative künstliche Intelligenz im Bereich Computer Vision große Aufmerksamkeit erregt. Mit dem Aufkommen von Diffusionsmodellen ist die Generierung hochwertiger Bilder aus Textaufforderungen, d. h. die Text-zu-Bild-Synthese, sehr beliebt und erfolgreich geworden.
Neueste Forschungsversuche versuchen, das Text-zu-Bild-Diffusionsmodell erfolgreich auf die Aufgabe der Text-zu-Video-Generierung und -Bearbeitung zu erweitern, indem es im Videobereich wiederverwendet wird. Obwohl solche Methoden vielversprechende Ergebnisse erzielt haben, erfordern die meisten von ihnen eine umfangreiche Schulung unter Verwendung großer Mengen gekennzeichneter Daten, was für viele Benutzer möglicherweise zu teuer ist.
Um die Videoerzeugung kostengünstiger zu machen, hat Tune-A-Video letztes Jahr einen Mechanismus zur Anwendung des Stable Diffusion (SD)-Modells auf den Videobereich eingeführt. Es muss nur ein Video angepasst werden, was den Schulungsaufwand erheblich reduziert. Obwohl dies wesentlich effizienter ist als frühere Methoden, bedarf es dennoch einer Optimierung. Darüber hinaus sind die Generierungsfunktionen von Tune-A-Video auf textgesteuerte Videobearbeitungsanwendungen beschränkt, und das Zusammenstellen von Videos von Grund auf übersteigt seine Möglichkeiten.
In diesem Artikel haben Forscher von Picsart AI Resarch (PAIR), der University of Texas in Austin und anderen Institutionen einen Schritt nach vorne bei dem neuen Problem der Text-zu-Video-Synthese im Null-Aufnahme-Modus und ohne Training gemacht. die Videos basierend auf Textaufforderungen ohne jegliche Optimierung oder Feinabstimmung generiert.

- Papieradresse: https://arxiv.org/pdf/2303.13439.pdf
- Projektadresse: https://github.com/Picsart-AI- Research/Text2Video-Zero
- Testadresse: https://huggingface.co/spaces/PAIR/Text2Video-Zero
Mal sehen, wie es funktioniert. Zum Beispiel surft ein Panda; ein Bär tanzt auf dem Times Square:

Die Forschung kann auch Aktionen basierend auf dem Ziel generieren:

Zusätzlich Kantenerkennung kann durchgeführt werden:

Ein Schlüsselkonzept des in diesem Artikel vorgeschlagenen Ansatzes besteht darin, ein vorab trainiertes Text-zu-Bild-Modell (z. B. Stable Diffusion) zu modifizieren, um es mit zeitkonsistenter Generierung anzureichern . Indem wir auf bereits trainierten Text-zu-Bild-Modellen aufbauen, nutzt unser Ansatz deren hervorragende Bilderzeugungsqualität und verbessert ihre Anwendbarkeit auf den Videobereich, ohne dass zusätzliches Training erforderlich ist.
Um die zeitliche Konsistenz zu verbessern, schlägt dieses Papier zwei innovative Modifikationen vor: (1) zunächst die latente Kodierung des generierten Frames mit Bewegungsinformationen anreichern, um die globale Szene und den Hintergrund zeitlich konsistent zu halten; (2) dann ein Kreuz verwenden; -Frame-Aufmerksamkeitsmechanismus, um den Kontext, das Erscheinungsbild und die Identität von Vordergrundobjekten während der gesamten Sequenz zu bewahren. Experimente zeigen, dass diese einfachen Modifikationen qualitativ hochwertige und zeitlich konsistente Videos erzeugen können (siehe Abbildung 1).

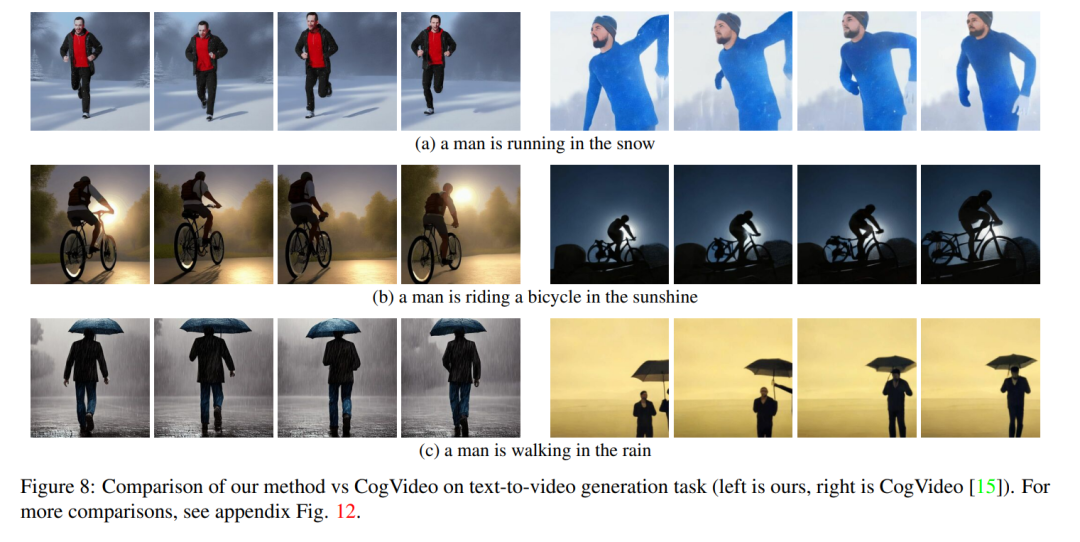
Obwohl die Arbeit anderer Leute auf großen Videodaten trainiert wird, erzielt unsere Methode eine ähnliche und manchmal bessere Leistung (dargestellt in den Abbildungen 8, 9).
# 🎜 🎜#
Die Methode in diesem Artikel ist nicht auf die Text-zu-Video-Synthese beschränkt, sondern ist auch auf bedingte Verfahren anwendbar (siehe Abbildungen 6 und 5). ) und die Erzeugung spezialisierter Videos (siehe Abbildung 7) sowie die anweisungsgeführte Videobearbeitung können als Video Instruct-Pix2Pix bezeichnet werden, das von Instruct-Pix2Pix gesteuert wird (siehe Abbildung 9).

# 🎜 🎜#
In diesem Artikel wird die Text-zu-Bild-Synthesefunktion von Stable Diffusion (SD) genutzt, um die Text-zu-Video-Aufgabe im Nulldurchgang zu bewältigen -Shot-Situationen. Für die Anforderungen der Videogenerierung und nicht der Bildgenerierung sollte sich SD auf den Betrieb der zugrunde liegenden Codesequenzen konzentrieren. Der naive Ansatz besteht darin, m potenzielle Codes unabhängig aus einer Standard-Gauß-Verteilung abzutasten, d ( 0, I) und wenden DDIM-Sampling an, um den entsprechenden Tensor #
zu erhalten, wobei k = 1,...,m, und werden dann dekodiert, um die generierte Videosequenz # zu erhalten 🎜🎜#
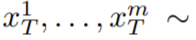
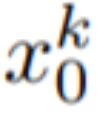
Um dieses Problem zu lösen, empfiehlt dieser Artikel die folgenden zwei Methoden : (i) Bewegungsdynamik zwischen latenten Kodierungen einführen, um die zeitliche Konsistenz der globalen Szene aufrechtzuerhalten; (ii) einen rahmenübergreifenden Aufmerksamkeitsmechanismus verwenden, um das Erscheinungsbild und die Identität von Vordergrundobjekten zu bewahren; Jede Komponente der in diesem Dokument verwendeten Methode wird im Folgenden ausführlich beschrieben. Eine Übersicht über die Methode finden Sie in Abbildung 2.
Experiment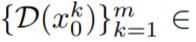 Beachten Sie, dass dieser Artikel zur Vereinfachung der Notation die gesamte mögliche Codesequenz wie folgt darstellt:
Beachten Sie, dass dieser Artikel zur Vereinfachung der Notation die gesamte mögliche Codesequenz wie folgt darstellt: 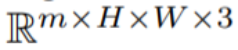
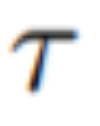

Bei Text-to-Video lässt sich beobachten, dass qualitativ hochwertige Videos generiert werden, die gut auf die Textansagen abgestimmt sind (siehe Abbildung 3). Beispielsweise wird ein Panda dazu gezeichnet, auf natürliche Weise auf der Straße zu laufen. Ebenso wurden unter Verwendung zusätzlicher Kanten- oder Posenführung (siehe Abbildungen 5, 6 und 7) hochwertige Videos mit passenden Eingabeaufforderungen und Anleitungen generiert, die eine gute zeitliche Konsistenz und Identitätswahrung zeigten. #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜# Im Fall von Abbildung 1) das generierte Video hat eine hohe Wiedergabetreue im Verhältnis zum Eingangsvideo und befolgt dabei strikt die Anweisungen. Vergleich mit Baseline Dieser Artikel vergleicht seine Methode mit zwei Öffentlich verfügbare Basislinien zum Vergleich: CogVideo und Tune-A-Video. Da es sich bei CogVideo um eine Text-zu-Video-Methode handelt, wird sie in diesem Artikel in einem rein textgesteuerten Videosyntheseszenario unter Verwendung von Video Instruct-Pix2Pix mit Tune-A-Video verglichen. Für den quantitativen Vergleich verwendet dieser Artikel den CLIP-Score zur Bewertung des Modells, der den Grad der Videotextausrichtung darstellt. Durch zufälliges Abrufen von 25 von CogVideo generierten Videos und Synthetisieren der entsprechenden Videos mit denselben Tipps gemäß der Methode in diesem Artikel. Die CLIP-Werte unserer Methode und von CogVideo liegen bei 31,19 bzw. 29,63. Daher ist unsere Methode etwas besser als CogVideo, obwohl letztere 9,4 Milliarden Parameter hat und umfangreiches Training für Videos erfordert. Abbildung 8 zeigt mehrere Ergebnisse der in diesem Dokument vorgeschlagenen Methode und bietet einen qualitativen Vergleich mit CogVideo. Beide Methoden weisen über die gesamte Sequenz hinweg eine gute zeitliche Konsistenz auf und bewahren sowohl die Identität des Objekts als auch seinen Kontext. Unsere Methode zeigt bessere Möglichkeiten zur Text-Video-Ausrichtung. Beispielsweise generiert unsere Methode in Abbildung 8 (b) korrekt ein Video einer Person, die in der Sonne Fahrrad fährt, während CogVideo den Hintergrund auf Mondlicht setzt. Auch in Abbildung 8 (a) zeigt unsere Methode korrekt eine im Schnee laufende Person, während der Schnee und die laufende Person in dem von CogVideo generierten Video nicht deutlich sichtbar sind. Video Die qualitativen Ergebnisse von Instruct-Pix2Pix und der visuelle Vergleich mit Instruct-Pix2Pix und Tune-AVideo pro Frame sind in Abbildung 9 dargestellt. Während Instruct-Pix2Pix eine gute Bearbeitungsleistung pro Frame zeigt, mangelt es ihm an zeitlicher Konsistenz. Dies macht sich besonders bei Videos mit Skifahrern bemerkbar, in denen Schnee und Himmel in unterschiedlichen Stilen und Farben gezeichnet sind. Diese Probleme wurden mit der Video Instruct-Pix2Pix-Methode gelöst, was zu einer zeitlich konsistenten Videobearbeitung während der gesamten Sequenz führte. Obwohl Tune-A-Video im Vergleich zur Methode in diesem Artikel eine zeitkonsistente Videogenerierung erstellt, entspricht sie weniger der Anleitung und ist schwierig zu erstellen. Lokal bearbeitet , und die Details der Eingabesequenz gehen verloren. Dies wird deutlich, wenn man sich den Schnitt des Videos des Tänzers ansieht, der in Abbildung 9 links dargestellt ist. Im Vergleich zu Tune-A-Video stellt unsere Methode das gesamte Outfit heller dar, während der Hintergrund besser erhalten bleibt, z. B. die Wand hinter dem Tänzer, die nahezu unverändert bleibt. Tune-A-Video hat eine stark deformierte Wand bemalt. Darüber hinaus entspricht unsere Methode den Eingabedetails besser. Im Vergleich zu Tune-A-Video zeichnet Video Instruction-Pix2Pix Tänzer anhand der bereitgestellten Posen (Abbildung 9 links) und zeigt alle im Eingabevideo erscheinenden Skifahrer an. Wie im letzten Bild auf der rechten Seite von Abbildung 9 gezeigt). Alle oben genannten Schwächen von Tune-A-Video sind auch in den Abbildungen 23, 24 zu beobachten.

Das obige ist der detaillierte Inhalt vonDas Erstellen von Videos ist so einfach, geben Sie einfach einen Hinweis, und Sie können es auch online ausprobieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Ist es ein Verstoß, die Videos anderer Leute auf Douyin zu posten? Wie werden Videos ohne Rechtsverletzung bearbeitet?
Mar 21, 2024 pm 05:57 PM
Ist es ein Verstoß, die Videos anderer Leute auf Douyin zu posten? Wie werden Videos ohne Rechtsverletzung bearbeitet?
Mar 21, 2024 pm 05:57 PM
Mit dem Aufkommen von Kurzvideoplattformen ist Douyin zu einem unverzichtbaren Bestandteil des täglichen Lebens eines jeden geworden. Auf TikTok können wir interessante Videos aus aller Welt sehen. Manche Leute posten gerne die Videos anderer Leute, was die Frage aufwirft: Verstößt Douyin gegen das Posten der Videos anderer Leute? In diesem Artikel wird dieses Problem erörtert und Ihnen erklärt, wie Sie Videos ohne Rechtsverletzung bearbeiten und Probleme mit Rechtsverletzungen vermeiden können. 1. Verstößt es gegen Douyins Veröffentlichung von Videos anderer Personen? Gemäß den Bestimmungen des Urheberrechtsgesetzes meines Landes stellt die unbefugte Nutzung der Werke des Urheberrechtsinhabers ohne die Erlaubnis des Urheberrechtsinhabers einen Verstoß dar. Daher stellt das Posten von Videos anderer Personen auf Douyin ohne die Erlaubnis des ursprünglichen Autors oder Urheberrechtsinhabers einen Verstoß dar. 2. Wie bearbeite ich ein Video ohne Urheberrechtsverletzung? 1. Verwendung von gemeinfreien oder lizenzierten Inhalten: Öffentlich
 Wie kann man mit dem Posten von Videos auf Douyin Geld verdienen? Wie kann ein Neuling mit Douyin Geld verdienen?
Mar 21, 2024 pm 08:17 PM
Wie kann man mit dem Posten von Videos auf Douyin Geld verdienen? Wie kann ein Neuling mit Douyin Geld verdienen?
Mar 21, 2024 pm 08:17 PM
Douyin, die nationale Kurzvideoplattform, ermöglicht uns nicht nur, in unserer Freizeit eine Vielzahl interessanter und neuartiger Kurzvideos zu genießen, sondern gibt uns auch eine Bühne, um uns zu zeigen und unsere Werte zu verwirklichen. Wie kann man also Geld verdienen, indem man Videos auf Douyin veröffentlicht? Dieser Artikel wird diese Frage ausführlich beantworten und Ihnen dabei helfen, mit TikTok mehr Geld zu verdienen. 1. Wie kann man mit dem Posten von Videos auf Douyin Geld verdienen? Nachdem Sie ein Video gepostet und eine bestimmte Anzahl an Aufrufen auf Douyin erreicht haben, haben Sie die Möglichkeit, am Werbe-Sharing-Plan teilzunehmen. Diese Einkommensmethode ist eine der bekanntesten unter Douyin-Benutzern und stellt auch für viele YouTuber die Haupteinnahmequelle dar. Douyin entscheidet anhand verschiedener Faktoren wie Kontogewicht, Videoinhalt und Publikumsfeedback, ob Möglichkeiten zum Teilen von Werbung bereitgestellt werden sollen. Die TikTok-Plattform ermöglicht es Zuschauern, ihre Lieblingsschöpfer durch das Versenden von Geschenken zu unterstützen.
 So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren_So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren
Mar 30, 2024 pm 12:26 PM
So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren_So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren
Mar 30, 2024 pm 12:26 PM
1. Öffnen Sie zunächst Weibo auf Ihrem Mobiltelefon und klicken Sie unten rechts auf [Ich] (wie im Bild gezeigt). 2. Klicken Sie dann oben rechts auf [Zahnrad], um die Einstellungen zu öffnen (wie im Bild gezeigt). 3. Suchen und öffnen Sie dann [Allgemeine Einstellungen] (wie im Bild gezeigt). 4. Geben Sie dann die Option [Video Follow] ein (wie im Bild gezeigt). 5. Öffnen Sie dann die Einstellung [Video-Upload-Auflösung] (wie im Bild gezeigt). 6. Wählen Sie abschließend [Originalbildqualität] aus, um eine Komprimierung zu vermeiden (wie im Bild gezeigt).
 Vier empfohlene KI-gestützte Programmiertools
Apr 22, 2024 pm 05:34 PM
Vier empfohlene KI-gestützte Programmiertools
Apr 22, 2024 pm 05:34 PM
Dieses KI-gestützte Programmiertool hat in dieser Phase der schnellen KI-Entwicklung eine große Anzahl nützlicher KI-gestützter Programmiertools zu Tage gefördert. KI-gestützte Programmiertools können die Entwicklungseffizienz verbessern, die Codequalität verbessern und Fehlerraten reduzieren. Sie sind wichtige Helfer im modernen Softwareentwicklungsprozess. Heute wird Dayao Ihnen 4 KI-gestützte Programmiertools vorstellen (und alle unterstützen die C#-Sprache). https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot ist ein KI-Codierungsassistent, der Ihnen hilft, Code schneller und mit weniger Aufwand zu schreiben, sodass Sie sich mehr auf Problemlösung und Zusammenarbeit konzentrieren können. Git
 Wie veröffentliche ich Xiaohongshu-Videowerke? Worauf sollte ich beim Posten von Videos achten?
Mar 23, 2024 pm 08:50 PM
Wie veröffentliche ich Xiaohongshu-Videowerke? Worauf sollte ich beim Posten von Videos achten?
Mar 23, 2024 pm 08:50 PM
Mit dem Aufkommen von Kurzvideoplattformen ist Xiaohongshu für viele Menschen zu einer Plattform geworden, auf der sie ihr Leben teilen, sich ausdrücken und Traffic gewinnen können. Auf dieser Plattform ist die Veröffentlichung von Videoarbeiten eine sehr beliebte Art der Interaktion. Wie veröffentlicht man also Xiaohongshu-Videoarbeiten? 1. Wie veröffentliche ich Xiaohongshu-Videowerke? Stellen Sie zunächst sicher, dass Sie einen Videoinhalt zum Teilen bereit haben. Sie können zum Fotografieren Ihr Mobiltelefon oder eine andere Kameraausrüstung verwenden, Sie müssen jedoch auf die Bildqualität und die Klarheit des Tons achten. 2. Bearbeiten Sie das Video: Um die Arbeit attraktiver zu gestalten, können Sie das Video bearbeiten. Sie können professionelle Videobearbeitungssoftware wie Douyin, Kuaishou usw. verwenden, um Filter, Musik, Untertitel und andere Elemente hinzuzufügen. 3. Wählen Sie ein Cover: Das Cover ist der Schlüssel, um Benutzer zum Klicken zu bewegen. Wählen Sie ein klares und interessantes Bild als Cover, um Benutzer zum Klicken zu bewegen.
 So betten Sie ein PPT-Video in ein Foliendokument ein und fügen es zu einer Datei zusammen
Mar 20, 2024 am 11:30 AM
So betten Sie ein PPT-Video in ein Foliendokument ein und fügen es zu einer Datei zusammen
Mar 20, 2024 am 11:30 AM
Microsoft PowerPoint-Präsentationen gehören zu unseren am häufigsten verwendeten Office-Programmen. Um die zu erläuternden Inhalte umfassend und detailliert darzustellen, ist Video eine der wichtigen Präsentationsmethoden. Wissen Sie, wenn wir Videos in PPT einfügen, sei es über Hyperlinks oder WindowsMediaPlayer-Steuerelemente, müssen wir Pfadprobleme berücksichtigen. Wenn wir also ein PPT-Video einbetten und in einer Datei kombinieren möchten, wie sollten wir das Problem lösen? Schauen wir uns als nächstes die Lösung an! Die Schritte sind wie folgt: 1. Zuerst doppelklicken wir, um die Microsoft PowerPoint-Präsentation [Video Embed.pptx] zu öffnen. Weil ShockwaveFlashO verwendet wird
 Erfahren Sie, wie Sie mobile Anwendungen mit der Go-Sprache entwickeln
Mar 28, 2024 pm 10:00 PM
Erfahren Sie, wie Sie mobile Anwendungen mit der Go-Sprache entwickeln
Mar 28, 2024 pm 10:00 PM
Tutorial zur Entwicklung mobiler Anwendungen in der Go-Sprache Da der Markt für mobile Anwendungen weiterhin boomt, beginnen immer mehr Entwickler damit, sich mit der Verwendung der Go-Sprache für die Entwicklung mobiler Anwendungen zu befassen. Als einfache und effiziente Programmiersprache hat die Go-Sprache auch großes Potenzial für die Entwicklung mobiler Anwendungen gezeigt. In diesem Artikel wird detailliert beschrieben, wie die Go-Sprache zum Entwickeln mobiler Anwendungen verwendet wird, und es werden spezifische Codebeispiele angehängt, um den Lesern den schnellen Einstieg und die Entwicklung eigener mobiler Anwendungen zu erleichtern. 1. Vorbereitung Bevor wir beginnen, müssen wir die Entwicklungsumgebung und die Tools vorbereiten. Kopf
 Welcher KI-Programmierer ist der beste? Entdecken Sie das Potenzial von Devin, Tongyi Lingma und SWE-Agent
Apr 07, 2024 am 09:10 AM
Welcher KI-Programmierer ist der beste? Entdecken Sie das Potenzial von Devin, Tongyi Lingma und SWE-Agent
Apr 07, 2024 am 09:10 AM
Am 3. März 2022, weniger als einen Monat nach der Geburt von Devin, dem weltweit ersten KI-Programmierer, entwickelte das NLP-Team der Princeton University einen Open-Source-KI-Programmierer-SWE-Agenten. Es nutzt das GPT-4-Modell, um Probleme in GitHub-Repositorys automatisch zu lösen. Die Leistung des SWE-Agenten auf dem SWE-Bench-Testsatz ist ähnlich wie die von Devin, er benötigt durchschnittlich 93 Sekunden und löst 12,29 % der Probleme. Durch die Interaktion mit einem dedizierten Terminal kann der SWE-Agent Dateiinhalte öffnen und durchsuchen, die automatische Syntaxprüfung verwenden, bestimmte Zeilen bearbeiten sowie Tests schreiben und ausführen. (Hinweis: Der obige Inhalt stellt eine geringfügige Anpassung des Originalinhalts dar, die Schlüsselinformationen im Originaltext bleiben jedoch erhalten und überschreiten nicht die angegebene Wortbeschränkung.) SWE-A
