
 Java
javaLernprogramm
So geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an
Java
javaLernprogramm
So geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an
So geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an

Beschreibung
Dieses Projekt ist ein Springboot + Kafak-Integrationsprojekt und verwendet daher die Kafak-Verbrauchsanmerkung @KafkaListener in Springboot.
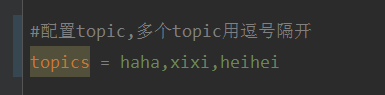
Konfigurieren Sie zunächst mehrere durch Kommas getrennte Themen in application.properties.
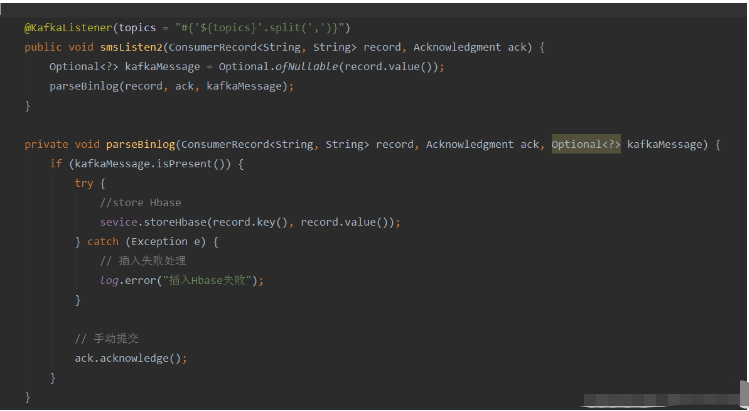
Methode: Verwenden Sie den SpEl-Ausdruck von Spring, um Themen wie folgt zu konfigurieren: @KafkaListener(topics = „#{’${topics}’.split(’,’)}“)
Run Das Programm und der Konsolendruckeffekt sind wie folgt:

Da nur ein Verbraucherthread geöffnet ist, werden alle Themen und Partitionen diesem Thread zugewiesen.
Wenn Sie mehrere Verbraucherthreads öffnen möchten, um diese Themen zu konsumieren, fügen Sie den Parameter concurrency der @KafkaListener-Annotation zur Anzahl der gewünschten Verbraucher hinzu (beachten Sie, dass die Anzahl der Verbraucher kleiner oder gleich der Anzahl sein muss). Verbraucher, die Sie möchten) Die Summe der Anzahl der Partitionen aller Themen Ändern Sie das Thema und konsumieren Sie es, während das Programm ausgeführt wird?

Nach dem Versuch kann diese Anforderung nicht mit der Annotation @KafkaListener erfüllt werden Consumer basierend auf den @KafkaListener-Annotationsinformationen, um das angegebene Thema zu konsumieren. Wenn das Thema während der Ausführung des Programms geändert wird, ist es dem Verbraucher nicht gestattet, die Verbraucherkonfiguration zu ändern und das Thema anschließend erneut zu abonnieren.
Aber wir können einen Kompromiss finden, der darin besteht, den topicPattern-Parameter von @KafkaListener für den Themenabgleich zu verwenden. 
Verwenden Sie die native Client-Abhängigkeit von Kafka, initialisieren Sie Verbraucher manuell und starten Sie Verbraucher-Threads, anstatt @KafkaListener zu verwenden.
Im Verbraucherthread ruft jeder Zyklus die neuesten Themeninformationen aus der Konfiguration, Datenbank oder anderen Konfigurationsquellen ab, vergleicht sie mit dem vorherigen Thema und abonniert das Thema erneut oder initialisiert den Verbraucher, wenn Änderungen auftreten.Implementierung
Kafka-Client-Abhängigkeit hinzufügen (diese Testserver-Kafka-Version: 2.12-2.4.0)<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.3.0</version> </dependency>
@Service
@Slf4j
public class KafkaConsumers implements InitializingBean {
/**
* 消费者
*/
private static KafkaConsumer<String, String> consumer;
/**
* topic
*/
private List<String> topicList;
public static String getNewTopic() {
try {
return org.apache.commons.io.FileUtils.readLines(new File("D:/topic.txt"), "utf-8").get(0);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 初始化消费者(配置写死是为了快速测试,请大家使用配置文件)
*
* @param topicList
* @return
*/
public KafkaConsumer<String, String> getInitConsumer(List<String> topicList) {
//配置信息
Properties props = new Properties();
//kafka服务器地址
props.put("bootstrap.servers", "192.168.9.185:9092");
//必须指定消费者组
props.put("group.id", "haha");
//设置数据key和value的序列化处理类
props.put("key.deserializer", StringDeserializer.class);
props.put("value.deserializer", StringDeserializer.class);
//创建消息者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅topic的消息
consumer.subscribe(topicList);
return consumer;
}
/**
* 开启消费者线程
* 异常请自己根据需求自己处理
*/
@Override
public void afterPropertiesSet() {
// 初始化topic
topicList = Splitter.on(",").splitToList(Objects.requireNonNull(getNewTopic()));
if (org.apache.commons.collections.CollectionUtils.isNotEmpty(topicList)) {
consumer = getInitConsumer(topicList);
// 开启一个消费者线程
new Thread(() -> {
while (true) {
// 模拟从配置源中获取最新的topic(字符串,逗号隔开)
final List<String> newTopic = Splitter.on(",").splitToList(Objects.requireNonNull(getNewTopic()));
// 如果topic发生变化
if (!topicList.equals(newTopic)) {
log.info("topic 发生变化:newTopic:{},oldTopic:{}-------------------------", newTopic, topicList);
// method one:重新订阅topic:
topicList = newTopic;
consumer.subscribe(newTopic);
// method two:关闭原来的消费者,重新初始化一个消费者
//consumer.close();
//topicList = newTopic;
//consumer = getInitConsumer(newTopic);
continue;
}
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("key:" + record.key() + "" + ",value:" + record.value());
}
}
}).start();
}
}
}Nach dem Login kopieren
Lassen Sie uns über die 72. Codezeile sprechen:@Service
@Slf4j
public class KafkaConsumers implements InitializingBean {
/**
* 消费者
*/
private static KafkaConsumer<String, String> consumer;
/**
* topic
*/
private List<String> topicList;
public static String getNewTopic() {
try {
return org.apache.commons.io.FileUtils.readLines(new File("D:/topic.txt"), "utf-8").get(0);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 初始化消费者(配置写死是为了快速测试,请大家使用配置文件)
*
* @param topicList
* @return
*/
public KafkaConsumer<String, String> getInitConsumer(List<String> topicList) {
//配置信息
Properties props = new Properties();
//kafka服务器地址
props.put("bootstrap.servers", "192.168.9.185:9092");
//必须指定消费者组
props.put("group.id", "haha");
//设置数据key和value的序列化处理类
props.put("key.deserializer", StringDeserializer.class);
props.put("value.deserializer", StringDeserializer.class);
//创建消息者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅topic的消息
consumer.subscribe(topicList);
return consumer;
}
/**
* 开启消费者线程
* 异常请自己根据需求自己处理
*/
@Override
public void afterPropertiesSet() {
// 初始化topic
topicList = Splitter.on(",").splitToList(Objects.requireNonNull(getNewTopic()));
if (org.apache.commons.collections.CollectionUtils.isNotEmpty(topicList)) {
consumer = getInitConsumer(topicList);
// 开启一个消费者线程
new Thread(() -> {
while (true) {
// 模拟从配置源中获取最新的topic(字符串,逗号隔开)
final List<String> newTopic = Splitter.on(",").splitToList(Objects.requireNonNull(getNewTopic()));
// 如果topic发生变化
if (!topicList.equals(newTopic)) {
log.info("topic 发生变化:newTopic:{},oldTopic:{}-------------------------", newTopic, topicList);
// method one:重新订阅topic:
topicList = newTopic;
consumer.subscribe(newTopic);
// method two:关闭原来的消费者,重新初始化一个消费者
//consumer.close();
//topicList = newTopic;
//consumer = getInitConsumer(newTopic);
continue;
}
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("key:" + record.key() + "" + ",value:" + record.value());
}
}
}).start();
}
}
}ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
Nach dem Login kopierenDie obige Codezeile bedeutet: in 100 ms Warten Sie, bis der Kafka-Broker Daten zurückgibt. Der Supermarktparameter gibt an, wie lange es nach der Abfrage dauern kann, unabhängig davon, ob Daten verfügbar sind oder nicht.
Nachdem Sie das Thema geändert haben, müssen Sie warten, bis die von dieser Umfrage abgerufenen Nachrichten verarbeitet wurden, und Änderungen im Thema während der while-Schleife (true) erkennen, bevor Sie das Thema erneut abonnieren können Die Methode poll () lautet zu einem Zeitpunkt: 500, wie unten gezeigt, wird im Quellcode des Kafka-Clients festgelegt.
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
Wenn Sie diese Konfiguration anpassen möchten, können Sie die
Laufergebnisse beim Initialisieren des Verbrauchers hinzufügen (im getesteten Thema sind keine Daten vorhanden)Hinweis: KafkaConsumer ist threadunsicher Verwenden Sie nicht eine KafkaConsumer-Instanz, um mehrere Verbraucher zu öffnen. Um mehrere Verbraucher zu öffnen, müssen Sie mehrere neue KafkaConsumer-Instanzen erstellen.
Das obige ist der detaillierte Inhalt vonSo geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So implementieren Sie eine Echtzeit-Aktienanalyse mit PHP und Kafka
Jun 28, 2023 am 10:04 AM
So implementieren Sie eine Echtzeit-Aktienanalyse mit PHP und Kafka
Jun 28, 2023 am 10:04 AM
Mit der Entwicklung des Internets und der Technologie sind digitale Investitionen zu einem Thema mit zunehmender Besorgnis geworden. Viele Anleger erforschen und studieren weiterhin Anlagestrategien in der Hoffnung, eine höhere Kapitalrendite zu erzielen. Im Aktienhandel ist die Aktienanalyse in Echtzeit für die Entscheidungsfindung sehr wichtig, und der Einsatz der Kafka-Echtzeit-Nachrichtenwarteschlange und der PHP-Technologie ist ein effizientes und praktisches Mittel. 1. Einführung in Kafka Kafka ist ein von LinkedIn entwickeltes verteiltes Publish- und Subscribe-Messagingsystem mit hohem Durchsatz. Die Hauptmerkmale von Kafka sind
 Vergleich und Differenzanalyse zwischen SpringBoot und SpringMVC
Dec 29, 2023 am 11:02 AM
Vergleich und Differenzanalyse zwischen SpringBoot und SpringMVC
Dec 29, 2023 am 11:02 AM
SpringBoot und SpringMVC sind beide häufig verwendete Frameworks in der Java-Entwicklung, es gibt jedoch einige offensichtliche Unterschiede zwischen ihnen. In diesem Artikel werden die Funktionen und Verwendungsmöglichkeiten dieser beiden Frameworks untersucht und ihre Unterschiede verglichen. Lassen Sie uns zunächst etwas über SpringBoot lernen. SpringBoot wurde vom Pivotal-Team entwickelt, um die Erstellung und Bereitstellung von Anwendungen auf Basis des Spring-Frameworks zu vereinfachen. Es bietet eine schnelle und einfache Möglichkeit, eigenständige, ausführbare Dateien zu erstellen
 So erstellen Sie Echtzeit-Datenverarbeitungsanwendungen mit React und Apache Kafka
Sep 27, 2023 pm 02:25 PM
So erstellen Sie Echtzeit-Datenverarbeitungsanwendungen mit React und Apache Kafka
Sep 27, 2023 pm 02:25 PM
So verwenden Sie React und Apache Kafka zum Erstellen von Echtzeit-Datenverarbeitungsanwendungen. Einführung: Mit dem Aufkommen von Big Data und Echtzeit-Datenverarbeitung ist die Erstellung von Echtzeit-Datenverarbeitungsanwendungen für viele Entwickler zum Ziel geworden. Die Kombination von React, einem beliebten Front-End-Framework, und Apache Kafka, einem leistungsstarken verteilten Messaging-System, kann uns beim Aufbau von Echtzeit-Datenverarbeitungsanwendungen helfen. In diesem Artikel wird erläutert, wie Sie mit React und Apache Kafka Echtzeit-Datenverarbeitungsanwendungen erstellen
 Praktisches Tutorial zur SpringBoot+Dubbo+Nacos-Entwicklung
Aug 15, 2023 pm 04:49 PM
Praktisches Tutorial zur SpringBoot+Dubbo+Nacos-Entwicklung
Aug 15, 2023 pm 04:49 PM
In diesem Artikel wird ein detailliertes Beispiel geschrieben, um über die tatsächliche Entwicklung von Dubbo + Nacos + Spring Boot zu sprechen. In diesem Artikel wird nicht zu viel theoretisches Wissen behandelt, sondern das einfachste Beispiel wird geschrieben, um zu veranschaulichen, wie Dubbo in Nacos integriert werden kann, um schnell eine Entwicklungsumgebung aufzubauen.
 Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Optionen für Kafka-Visualisierungstools ApacheKafka ist eine verteilte Stream-Verarbeitungsplattform, die große Mengen an Echtzeitdaten verarbeiten kann. Es wird häufig zum Aufbau von Echtzeit-Datenpipelines, Nachrichtenwarteschlangen und ereignisgesteuerten Anwendungen verwendet. Die Visualisierungstools von Kafka können Benutzern dabei helfen, Kafka-Cluster zu überwachen und zu verwalten und Kafka-Datenflüsse besser zu verstehen. Im Folgenden finden Sie eine Einführung in fünf beliebte Kafka-Visualisierungstools: ConfluentControlCenterConfluent
 Vergleichende Analyse der Kafka-Visualisierungstools: Wie wählt man das am besten geeignete Tool aus?
Jan 05, 2024 pm 12:15 PM
Vergleichende Analyse der Kafka-Visualisierungstools: Wie wählt man das am besten geeignete Tool aus?
Jan 05, 2024 pm 12:15 PM
Wie wählt man das richtige Kafka-Visualisierungstool aus? Vergleichende Analyse von fünf Tools Einführung: Kafka ist ein leistungsstarkes verteiltes Nachrichtenwarteschlangensystem mit hohem Durchsatz, das im Bereich Big Data weit verbreitet ist. Mit der Popularität von Kafka benötigen immer mehr Unternehmen und Entwickler ein visuelles Tool zur einfachen Überwachung und Verwaltung von Kafka-Clustern. In diesem Artikel werden fünf häufig verwendete Kafka-Visualisierungstools vorgestellt und ihre Merkmale und Funktionen verglichen, um den Lesern bei der Auswahl des Tools zu helfen, das ihren Anforderungen entspricht. 1. KafkaManager
 Wie installiere ich Apache Kafka unter Rocky Linux?
Mar 01, 2024 pm 10:37 PM
Wie installiere ich Apache Kafka unter Rocky Linux?
Mar 01, 2024 pm 10:37 PM
Um ApacheKafka auf RockyLinux zu installieren, können Sie die folgenden Schritte ausführen: Aktualisieren Sie das System: Stellen Sie zunächst sicher, dass Ihr RockyLinux-System auf dem neuesten Stand ist. Führen Sie den folgenden Befehl aus, um die Systempakete zu aktualisieren: sudoyumupdate Java installieren: ApacheKafka hängt von Java ab, also von Ihnen Sie müssen zuerst JavaDevelopmentKit (JDK) installieren. OpenJDK kann mit dem folgenden Befehl installiert werden: sudoyuminstalljava-1.8.0-openjdk-devel Herunterladen und dekomprimieren: Besuchen Sie die offizielle Website von ApacheKafka (), um das neueste Binärpaket herunterzuladen. Wählen Sie eine stabile Version
 Die Praxis von Go-Zero und Kafka+Avro: Aufbau eines leistungsstarken interaktiven Datenverarbeitungssystems
Jun 23, 2023 am 09:04 AM
Die Praxis von Go-Zero und Kafka+Avro: Aufbau eines leistungsstarken interaktiven Datenverarbeitungssystems
Jun 23, 2023 am 09:04 AM
In den letzten Jahren haben mit dem Aufkommen von Big Data und aktiven Open-Source-Communities immer mehr Unternehmen begonnen, nach leistungsstarken interaktiven Datenverarbeitungssystemen zu suchen, um den wachsenden Datenanforderungen gerecht zu werden. In dieser Welle von Technologie-Upgrades werden Go-Zero und Kafka+Avro von immer mehr Unternehmen beachtet und übernommen. go-zero ist ein auf der Golang-Sprache entwickeltes Microservice-Framework. Es zeichnet sich durch hohe Leistung, Benutzerfreundlichkeit, einfache Erweiterung und einfache Wartung aus und soll Unternehmen dabei helfen, schnell effiziente Microservice-Anwendungssysteme aufzubauen. sein schnelles Wachstum
