
 Technologie-Peripheriegeräte
KI
Die Schulungskosten betragen weniger als 1.000 Yuan, eine Reduzierung um 90 %! NUS und Tsinghua University veröffentlichen VPGTrans: Einfache Anpassung GPT-4-ähnlicher multimodaler großer Modelle
Technologie-Peripheriegeräte
KI
Die Schulungskosten betragen weniger als 1.000 Yuan, eine Reduzierung um 90 %! NUS und Tsinghua University veröffentlichen VPGTrans: Einfache Anpassung GPT-4-ähnlicher multimodaler großer Modelle
Die Schulungskosten betragen weniger als 1.000 Yuan, eine Reduzierung um 90 %! NUS und Tsinghua University veröffentlichen VPGTrans: Einfache Anpassung GPT-4-ähnlicher multimodaler großer Modelle

Dieses Jahr ist das Jahr der explosiven Entwicklung der KI-Technologie, wobei große Sprachmodelle (LLM), repräsentiert durch ChatGPT, immer beliebter werden.
Sprachmodelle zeigen nicht nur großes Potenzial im Bereich der natürlichen Sprache, sondern strahlen auch allmählich auf andere Modalitäten aus. Beispielsweise erfordert das vinzentinische Graphenmodell Stable Diffusion auch ein Sprachmodell.
Das Training eines visuellen Sprachmodells (VL-LLM) von Grund auf erfordert oft viele Ressourcen, daher bestehen die vorhandenen Lösungen darin, das Sprachmodell und das visuelle Eingabeaufforderungsgenerierungsmodell (Visual Prompt Generator, VPG) zu verbinden Daher erfordert die weitere Optimierung von VPG immer noch Tausende von GPU-Stunden und Millionen von Trainingsdaten.
Kürzlich haben Forscher der National University of Singapore und der Tsinghua University eine Lösung, VPGTrans, vorgeschlagen, um vorhandenes VPG auf das bestehende VL-LLM-Modell zu migrieren, um das Ziel-VL-LLM-Modell zu erhalten.

Papierlink: https://arxiv.org/abs/2305.01278
Codelink: https://github.com/VPGTrans/VPGTrans
Demo zum multimodalen Dialogmodell: https://vpgtrans.github.io/
Autoren: Zhang Ao, Fei Hao, Yao Yuan, Ji Wei, Li Li, Liu Zhiyuan, Chua Tat-Seng
Einheit: National University of Singapore, Tsinghua University
Zu den wichtigsten Innovationspunkten des Artikels gehören:
1. Extrem niedrige Schulungskosten:
Durch unsere vorgeschlagene VPGTrans-Methode kann schnell sein (weniger als 10 % Trainingszeit) Das visuelle Modul des vorhandenen multimodalen Dialogmodells auf das neue Sprachmodell migrieren und ähnliche oder bessere Ergebnisse erzielen.
Im Vergleich zum Training des Vision-Moduls von Grund auf können wir beispielsweise die Schulungskosten für BLIP-2 FlanT5-XXL von über 19.000 RMB auf weniger als 1.000 RMB reduzieren:
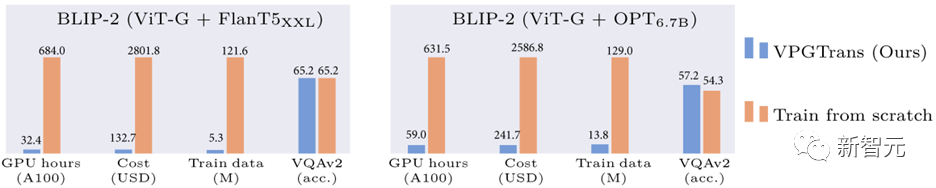
Bild 1: Vergleich der Reduzierung des BLIP-2-Trainingsaufwands basierend auf unserer VPGTrans-Methode
2. Multimodale Anpassung großer Modelle:
Durch unser VPGTrans-Framework können verschiedene neue Modelle entsprechend angepasst werden Je nach Bedarf können große Sprachmodelle flexibel visuelle Module hinzufügen. Beispielsweise haben wir VL-LLaMA und VL-Vicuna auf Basis von LLaMA-7B und Vicuna-7B hergestellt.
3. Open-Source-Multimodal-Dialogmodell:
Wir Open-Source-VL-Vicuna, ein GPT-4-ähnliches multimodales Dialogmodell, das eine hohe Qualitäts-Multimodalitätsdialog:
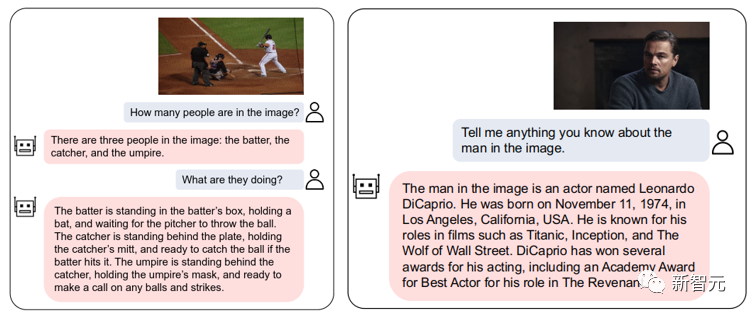
Abbildung 2: VL-Vicuna-Interaktionsbeispiel 1. Einführung in die Motivation
1.1 HintergrundLLM hat aus einem Trend in der Bereich des multimodalen Verständnisses. Transformation vom traditionellen vorab trainierten visuellen Sprachmodell (VLM) zum visuellen Sprachmodell basierend auf einem großen Sprachmodell (VL-LLM).
Durch die Verbindung des visuellen Moduls mit LLM kann VL-LLM das Wissen, die Fähigkeit zur Generalisierung ohne Stichproben, die Argumentationsfähigkeit und die Planungsfähigkeit des vorhandenen LLM erben. Zu den verwandten Modellen gehören BLIP-2[1], Flamingo[2], PALM-E usw. Abbildung 3: häufig verwendete VL-LLM-Architektur Modul (Visual Prompt Generator, VPG) und eine lineare Ebene (Projektor), die die Dimensionstransformation durchführt. In Bezug auf die Parameterskala macht  LLM im Allgemeinen den Hauptteil aus (z. B. 11B)
LLM im Allgemeinen den Hauptteil aus (z. B. 11B)
Während des Trainingsprozesses werden LLM-Parameter im Allgemeinen nicht aktualisiert oder nur eine sehr kleine Anzahl von Parametern aktualisiert. Trainierbare Parameter stammen hauptsächlich von VPG und Projektor. 1.2 Motivation Laden des Basis-LLM.
Daher kann das Training eines VL-LLM immer noch keinen enormen Rechenaufwand vermeiden. Um beispielsweise BLIP-2 zu erhalten (das Basis-LLM ist FlanT5-XXL), sind mehr als 600 Stunden A100-Trainingszeit erforderlich. Wenn Sie das A100-40G-Gerät von Amazon mieten, kostet es fast 20.000 Yuan.
Da die Schulung eines VPG von Grund auf so teuer ist, begannen wir darüber nachzudenken , ob wir ein vorhandenes VPG auf ein neues LLM migrieren können , um Kosten zu sparen.
Abbildung 4: VPG-Migration: Cross-LLM-Größenmigration und Cross-LLM-Typmigration
Wie in Abbildung 4 gezeigt, haben wir hauptsächlich die Migration von zwei Arten von VPG untersucht:
(1) Cross-LLM-Größenmigration (TaS): z. B. von OPT-2.7B zu OPT-6.7B.
(2) Cross-LLM-Typmigration (TaT): z. B. von OPT zu FlanT5.
Die Bedeutung von TaS ist: In der LLM-bezogenen wissenschaftlichen Forschung müssen wir normalerweise Parameter an einem kleinen LLM anpassen und dann zu einem großen LLM erweitern. Mit TaS können wir das auf dem kleinen LLM trainierte VPG nach Anpassung der Parameter direkt auf das große LLM migrieren. 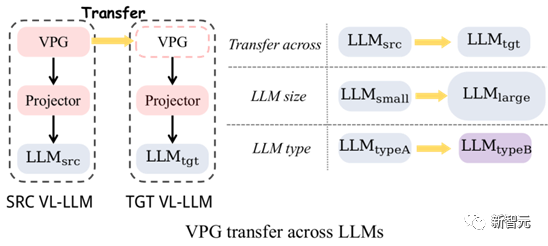
Die Bedeutung von TaT besteht darin, dass LLMs mit unterschiedlichen Funktionstypen immer wieder auftauchen, wie zum Beispiel LLaMA heute, Alpaca und Vicuna morgen. TaT ermöglicht es uns, vorhandenes VPG zu nutzen, um schnell visuelle Wahrnehmungsfähigkeiten zu neuen Sprachmodellen hinzuzufügen. 1.3 Beitrag
(1) Schlagen Sie eine effiziente Methode vor:
Wir haben zunächst die Schlüsselfaktoren untersucht, die die Effizienz der VPG-Migration beeinflussen, durch eine Reihe explorativer Experimente. Basierend auf den explorativen experimentellen Ergebnissen schlagen wir ein zweistufiges effizientes Migrationsframework vor: VPGTrans. Dieses Framework kann den Rechenaufwand und die erforderlichen Trainingsdaten, die zum Trainieren von VL-LLM erforderlich sind, erheblich reduzieren.
Zum Beispiel können wir im Vergleich zum Training von Grund auf durch die VPG-Migration von BLIP-2 OPT-2.7B auf 6.7B
nur etwa 10 % der Daten- und Rechenzeit nutzen, um ähnliche oder bessere Ergebnisse zu erzielen Jeder Datensatz Gute Wirkung (Bild 1) .
Die Schulungskosten liegen zwischen 17901 Yuan und 1673 Yuan.
(2) Erhalten Sie interessante Erkenntnisse:
Wir liefern einige interessante Erkenntnisse sowohl für TaS- als auch für TaT-Szenarien und versuchen, Erklärungen zu geben: a) Im TaS-Szenario hat die Verwendung von VPGTrans zur Migration von klein nach groß keinen Einfluss auf den endgültigen Modelleffekt. b) Im TaS-Szenario: Je kleiner die auf dem Sprachmodell trainierte VPG ist, desto höher ist die Effizienz bei der Migration zum großen Modell und desto besser ist der Endeffekt. c) Im TaT-Szenario ist die Migrationslücke umso größer, je kleiner das Modell ist. In unseren Verifizierungsexperimenten ist die gegenseitige Migration zwischen OPT350M und FlanT5-Basis mithilfe von VPGTrans fast so langsam wie ein Training von Grund auf. (3) Open Source: Wir haben VPGTrans verwendet, um zwei neue VL-LLMs zu erhalten: VL-LLaMA und VL-Vicuna, und haben sie als Open Source in der Community bereitgestellt. Unter anderem implementiert VL-Vicuna einen hochwertigen multimodalen Dialog ähnlich wie GPT4. Zuerst führen wir eine Reihe von Explorations- und Verifizierungsexperimenten durch, um zu analysieren, wie die Migrationseffizienz von VPG maximiert werden kann. Basierend auf diesen wichtigen Beobachtungen schlagen wir dann eine Lösung vor. Wir haben die BLIP-2-Architektur als unser Grundmodell ausgewählt, und der Korpus vor dem Training verwendete COCO und SBU mit insgesamt 1,4 Millionen Bild- und Textpaaren. Nachgelagerte Aufgaben werden mit den Zero-Shot-Einstellungen von COCO Caption, NoCaps, VQAv2, GQA und OK-VQA bewertet (die Caption-Aufgabe ist nicht unbedingt Zero-Shot). Im Folgenden sind unsere wichtigsten Ergebnisse aufgeführt: (1) Die direkte Übernahme einer trainierten VPG kann die Konvergenz beschleunigen, der Effekt ist jedoch begrenzt: Wir haben festgestellt, dass die direkte Migration einer auf einem LLM trainierten VPG nach Large LLM kann die Modellkonvergenz beschleunigen, aber der Beschleunigungseffekt ist begrenzt, und der Modelleffekt nach der Konvergenz wird im Vergleich zum völlig neuen VPG-Training geringer (die höchsten Punkte der blauen VQAv2- und GQA-Linien in Abbildung 5 liegen beide niedriger als die orangefarbene Linie) . Wir spekulieren, dass dieser Rückgang auf die Tatsache zurückzuführen ist, dass der zufällig initialisierte Projektor die vorhandene visuelle Wahrnehmungsfähigkeit in VPG zu Beginn des Trainings beeinträchtigt. 2. Hocheffiziente VPG-Migrationslösung: VPGTrans
2.1 Explorationsexperiment

Die folgende Abbildung zeigt die Ergebnisse, die durch direktes Erben des implementierten VPG erzielt werden (blaue Kurve). VPG neu trainieren (orangefarbene Linie): VPG von Grund auf neu trainieren. Die einzige Schulung findet auf dem Linearprojektor statt, eine Schulung zu VPG findet nicht statt.
(2) Ein Aufwärmtraining des Projektors kann Punktabfälle verhindern und die Konvergenz weiter beschleunigen:
Also reparieren wir VPG und LLM, wärmen den Projektor zuerst für 3 Epochen auf und Geben Sie dann das VPG für den nächsten Trainingsschritt frei.
Wir haben festgestellt, dass dadurch nicht nur Punktverluste vermieden, sondern auch die VPG-Konvergenz weiter beschleunigt werden können (Abbildung 6).
Aber es ist hervorzuheben, dass, da die Hauptkosten für die Schulung LLM (riesige Parameter) sind, die Kosten für die Schulung des Projektors nicht viel geringer sein werden als die Kosten für die Schulung des VPG und des Projektors gleichzeitig.
Also begannen wir, die Schlüsseltechnologien zu erforschen, um das Aufwärmen des Projektors zu beschleunigen.
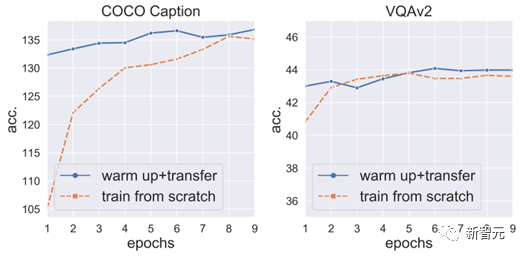
Abbildung 6: Ein Aufwärmtraining des Projektors kann Punktverlust verhindern und die Konvergenz beschleunigen
(3) Die Initialisierung des Wortvektorkonverters kann das Aufwärmen des Projektors beschleunigen:
Zuallererst erzeugt VPG Effekte, indem es Bilder in Soft-Prompts umwandelt, die LLM verstehen kann. Die Verwendung von Soft Prompt ist tatsächlich der von Wortvektor sehr ähnlich. Beide geben das Sprachmodell direkt ein, um das Modell zum Generieren entsprechender Inhalte aufzufordern. Also haben wir Wortvektoren als Proxy für Soft-Prompts verwendet und einen Wortvektorkonverter (eine lineare Ebene) von
nach 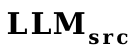
trainiert. 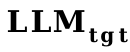
Dann verschmelzen wir den Wortvektorkonverter und den Projektor auf
als Initialisierung des Projektors. 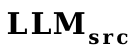
(4) Der Projektor kann bei einer sehr hohen Lernrate schnell konvergieren:
Wir haben weiter experimentiert und festgestellt, dass der Projektor aufgrund seiner geringen Anzahl an Parametern mit der fünffachen normalen Lernrate trainiert werden kann, ohne abzustürzen .
Durch Training mit 5-facher Lernrate kann das Aufwärmen des Projektors weiter auf 1 Epoche verkürzt werden
.(5) Eine zusätzliche Erkenntnis:
Obwohl das Aufwärmen des Projektors wichtig ist, reicht es nicht aus, den Projektor allein zu trainieren. Insbesondere bei der Untertitelaufgabe ist der Effekt des alleinigen Trainierens des Projektors schlechter als der des gleichzeitigen Trainierens des VPG (die grüne Linie in Abbildung 5 ist viel niedriger als die blaue Linie sowohl in COCO Caption als auch in NoCaps).
Das bedeutet auch, dass allein das Training des Projektors zu einer Unteranpassung führt
, das heißt,kann nicht vollständig an die Trainingsdaten angepasst werden. 2.2 Unsere vorgeschlagene Methode Wie in Abbildung 7 gezeigt, ist unsere Methode in zwei Phasen unterteilt: (1) Die erste Phase: Wir verwenden zunächst den Wortvektorkonverter, um ihn mit dem ursprünglichen Projektor als Initialisierung des neuen Projektors zu verschmelzen, und verwenden ihn dann Der neue Projektor wird mit der 5-fachen Lernrate für eine Epoche trainiert.
(2) Die zweite Stufe: VPG und Projektor direkt normal trainieren.
3. Experimentelle Ergebnisse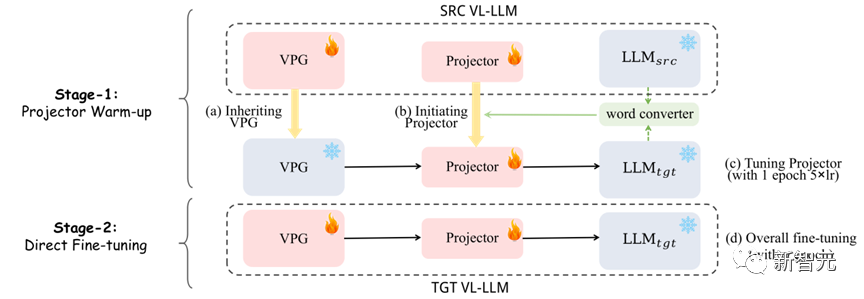 3.1 Beschleunigungsverhältnis
3.1 Beschleunigungsverhältnis
Tabelle 1: Das Beschleunigungsverhältnis unseres VPGTrans im Vergleich zum Training von Grund auf in jedem Datensatz
Wie in Tabelle 1 gezeigt, haben wir das Beschleunigungsverhältnis von VPGTrans an verschiedenen Datensätzen unter verschiedenen Migrationstypen getestet.
Das Beschleunigungsverhältnis von VPGTrans für einen bestimmten Datensatz A wird erhalten, indem die Anzahl der Trainingsrunden von Grund auf, um den besten Effekt a auf A zu erzielen, durch die minimale Anzahl von Trainingsrunden dividiert wird, bei denen der Effekt von VPGTrans auf A a übersteigt.
Zum Beispiel erfordert das Training von VPG auf OPT-2.7B von Grund auf 10 Epochen, um die besten Ergebnisse in der COCO-Beschriftung zu erzielen, aber die Migration von VPG von OPT-125M auf OPT-2.7B dauert nur 1 Epoche, um diese besten Ergebnisse zu erzielen . Das Beschleunigungsverhältnis beträgt 10/1=10 mal.
Wir können sehen, dass unser VPGTrans eine stabile Beschleunigung erreichen kann, egal in TaS- oder TaT-Szenarien.
3.2 Interessante Erkenntnisse
Wir haben einen der interessanteren Erkenntnisse zur Erläuterung ausgewählt. Weitere interessante Erkenntnisse finden Sie in unserem Artikel.
Im TaS-Szenario ist die Migrationseffizienz umso höher und der endgültige Modelleffekt umso besser, je kleiner die auf dem Sprachmodell trainierte VPG ist. Anhand von Tabelle 1 können wir feststellen, dass das Beschleunigungsverhältnis von OPT-1.3B zu OPT-2.7B viel kleiner ist als das Beschleunigungsverhältnis von OPT-125M und OPT-350M zu OPT-2.7b.
Wir haben versucht, eine Erklärung zu liefern: Im Allgemeinen ist es wahrscheinlicher, dass das VPG beschädigt wird, je größer das Sprachmodell ist, aufgrund der höheren Dimensionalität seines Textraums (VPG ist im Allgemeinen ein vorab trainiertes Modell). ähnlich wie CLIP) Eigene visuelle Wahrnehmungsfähigkeit . Wir haben es auf ähnliche Weise wie bei der linearen Sondierung verifiziert:
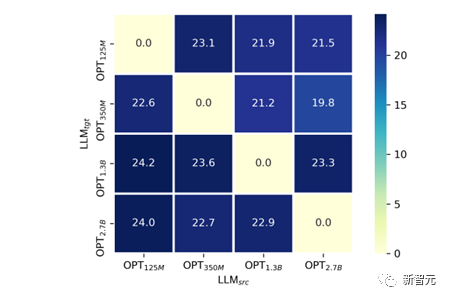
Wie in Abbildung 8 gezeigt haben wir eine Migration über LLM-Größen zwischen OPT-125M, 350M, 1.3B, 2.7B durchgeführt.
Im Experiment
Um die visuellen Wahrnehmungsfähigkeiten von VPG, die unter verschiedenen Modellgrößen trainiert wurden, fair zu vergleichen, haben wir die Parameter von VPG festgelegt und nur die lineare Projektorebene trainiert. Wir haben den SPICE-Indikator auf COCO Caption als Maß für die visuelle Wahrnehmungsfähigkeit ausgewählt. Es ist nicht schwer herauszufinden, dass es für jedes gegebene
fast im Einklang mit dem Phänomen steht, dass der endgültige SPICE umso höher ist, je kleiner das  ist.
ist.  3.3 Experimente im großen Maßstab
3.3 Experimente im großen Maßstab
Die vorherigen Experimente dienen hauptsächlich dazu, die Vermutung in Szenarien im kleinen Maßstab zu überprüfen. Um die Wirksamkeit unserer Methode zu beweisen, haben wir den Pre-Training-Prozess von BLIP-2 simuliert und groß angelegte Experimente durchgeführt:
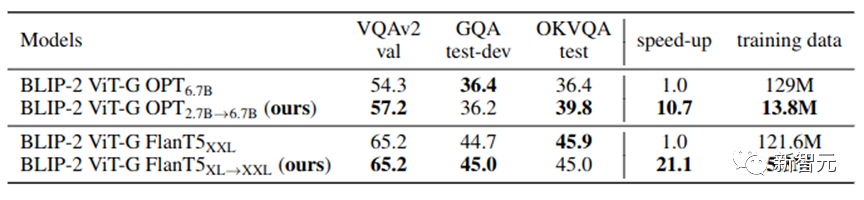
Wie in Tabelle 2 gezeigt, ist unser VPGTrans in groß angelegten Szenarien immer noch effektiv. Durch die Migration von OPT-2.7B auf OPT-6.7B haben wir nur 10,8 % der Daten und weniger als 10 % der Trainingszeit genutzt, um ähnliche oder bessere Ergebnisse zu erzielen.
Insbesondere erreicht unsere Methode eine
4,7 %ige Schulungskostenkontrollein BLIP-2 VL-LLM basierend auf FlanT5-XXL. 4. Passen Sie Ihre VL-LLMs individuell an
Unser VPGTrans kann schnell visuelle Wahrnehmungsmodule zu allen neuen LLMs hinzufügen und so ein brandneues, hochwertiges VL-LLM erhalten. In dieser Arbeit bilden wir zusätzlich einen VL-LLaMA und einen VL-Vicuna aus. Die Wirkung von VL-LLaMA ist wie folgt:
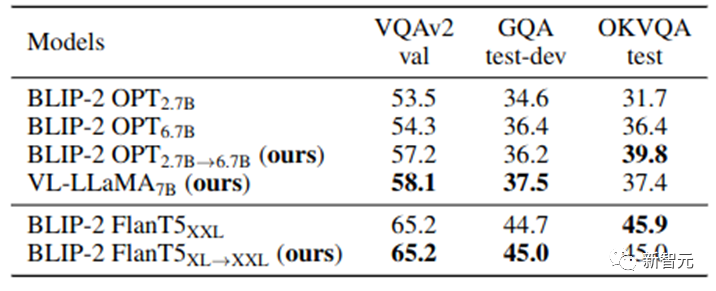
Tabelle 3: Wirkungsdarstellung von VL-LLaMA
Gleichzeitig kann unser VL-Vicuna ähnlich wie GPT-4 multimodale Gespräche führen. Wir haben einen einfachen Vergleich mit MiniGPT-4 durchgeführt:
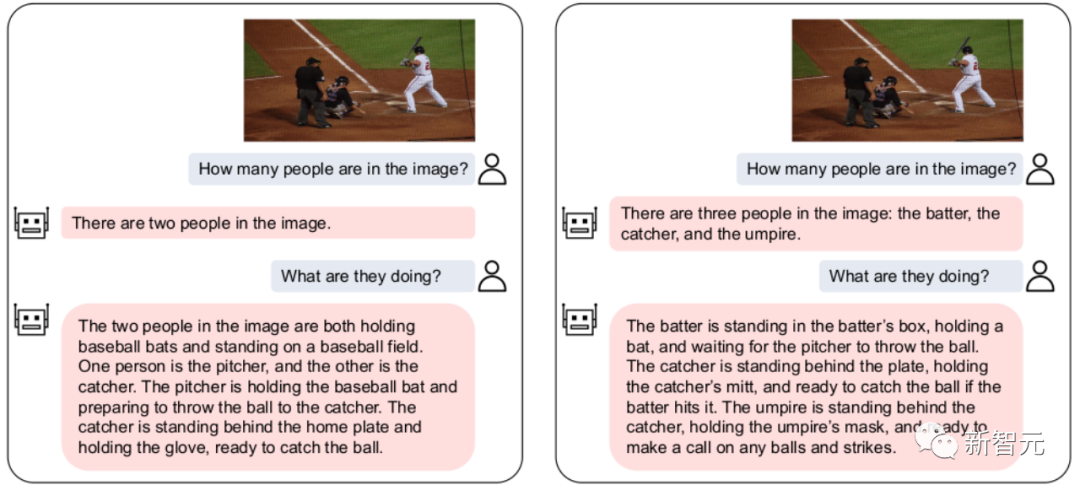
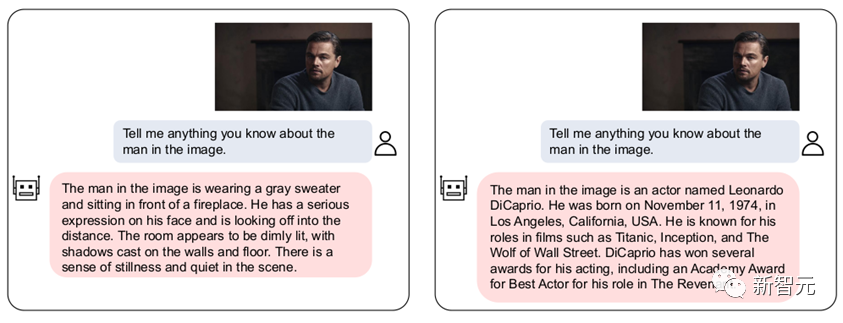
5. Zusammenfassung
In dieser Arbeit haben wir eine Untersuchung zum Migrationsproblem von VPG zwischen LLMs durchgeführt. Wir untersuchen zunächst die Schlüsselfaktoren, die die Migrationseffizienz maximieren.
Basierend auf wichtigen Beobachtungen schlagen wir ein neuartiges zweistufiges Migrationsframework vor, nämlich VPGTrans. Es kann eine gleichwertige oder bessere Leistung erzielen und gleichzeitig die Schulungskosten erheblich senken.
Durch VPGTrans haben wir die VPG-Migration von BLIP-2 OPT 2.7B auf BLIP-2 OPT 6.7B erreicht. Im Vergleich zur völlig neuen Verbindung von VPG mit OPT 6.7B benötigt VPGTrans nur 10,7 % Trainingsdaten und weniger als 10 % Trainingszeit.
Darüber hinaus präsentieren und diskutieren wir eine Reihe interessanter Erkenntnisse und die möglichen Gründe dafür. Abschließend demonstrieren wir den praktischen Wert unseres VPGTrans bei der Anpassung neuer VL-LLM, indem wir VL-LLaMA und LL-Vicuna trainieren.
Das obige ist der detaillierte Inhalt vonDie Schulungskosten betragen weniger als 1.000 Yuan, eine Reduzierung um 90 %! NUS und Tsinghua University veröffentlichen VPGTrans: Einfache Anpassung GPT-4-ähnlicher multimodaler großer Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
DALL-E 3 wurde im September 2023 offiziell als deutlich verbessertes Modell gegenüber seinem Vorgänger eingeführt. Er gilt als einer der bisher besten KI-Bildgeneratoren und ist in der Lage, Bilder mit komplexen Details zu erstellen. Zum Start war es jedoch exklusiv
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Projektlink vorne geschrieben: https://nianticlabs.github.io/mickey/ Anhand zweier Bilder kann die Kameraposition zwischen ihnen geschätzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere geschätzten Posen sind maßstabsunabhängig. Einige Anwendungen, wie z. B. Instant Augmented Reality jederzeit und überall, erfordern eine Posenschätzung von Skalenmetriken und sind daher auf externe Tiefenschätzer angewiesen, um die Skalierung wiederherzustellen. In diesem Artikel wird MicKey vorgeschlagen, ein Keypoint-Matching-Prozess, mit dem metrische Korrespondenzen im 3D-Kameraraum vorhergesagt werden können. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern können wir auf metrische Relativwerte schließen
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
