

Erfahren Sie in einem Artikel, was maschinelles Lernen ist

Die Welt ist voller Daten – Bilder, Videos, Tabellenkalkulationen, Audio und Texte, die von Menschen und Computern generiert werden, überschwemmen das Internet und ertränken uns in einem Meer von Informationen.
Traditionell analysieren Menschen Daten, um intelligentere Entscheidungen zu treffen und versuchen, Systeme anzupassen, um Änderungen in Datenmustern zu kontrollieren. Mit zunehmender Menge an eingehenden Informationen nimmt jedoch unsere Fähigkeit ab, diese zu verstehen, was uns vor die folgende Herausforderung stellt:
Wie nutzen wir all diese Daten, um Bedeutungen automatisiert statt manuell abzuleiten?
Hier kommt maschinelles Lernen ins Spiel. In diesem Artikel wird Folgendes vorgestellt:
- Was ist maschinelles Lernen?
- Schlüsselelemente von Algorithmen für maschinelles Lernen.
- Wie maschinelles Lernen funktioniert mit den Tools und Algorithmen zur Analyse und Verarbeitung von Daten, um genaue Vorhersagen zu treffen.
- Diese Vorhersagen werden durch maschinelles Lernen von Mustern aus einem Datensatz namens „Trainingsdaten“ getroffen und können die weitere technologische Entwicklung vorantreiben, um das Leben der Menschen zu verbessern.
- 一Was ist maschinelles Lernen?
– bezieht sich auf die Text-, Bild-, Video- oder Zeitreiheninformationen, aus denen das maschinelle Lernsystem lernen muss. Trainingsdaten werden häufig beschriftet, um dem ML-System die „richtige Antwort“ anzuzeigen, z. B. Begrenzungsrahmen um Gesichter in einem Gesichtsdetektor oder die zukünftige Aktienentwicklung in einem Aktienprädiktor.
steht für- – es bezieht sich auf die codierte Darstellung von Objekten in den Trainingsdaten, beispielsweise Gesichter, die durch Merkmale wie „Augen“ dargestellt werden. Das Codieren einiger Modelle ist einfacher als andere, und dies ist es, was die Modellauswahl bestimmt. Beispielsweise bilden neuronale Netze eine Darstellung, während Support-Vektor-Maschinen eine andere Darstellung bilden. Die meisten modernen Methoden nutzen neuronale Netze.
- Bewertung – Hier geht es darum, wie wir ein Modell beurteilen oder gegenüber einem anderen identifizieren. Wir nennen es normalerweise Nutzenfunktion, Verlustfunktion oder Bewertungsfunktion. Der mittlere quadratische Fehler (die Ausgabe des Modells im Vergleich zur Datenausgabe) oder die Wahrscheinlichkeit (die geschätzte Wahrscheinlichkeit des Modells angesichts der beobachteten Daten) sind Beispiele für verschiedene Bewertungsfunktionen.
- Optimierung – Dies bezieht sich darauf, wie der Raum durchsucht wird, der das Modell darstellt, oder wie die Beschriftungen in den Trainingsdaten verbessert werden, um eine bessere Auswertung zu erhalten. Optimierung bedeutet, die Modellparameter zu aktualisieren, um den Wert der Verlustfunktion zu minimieren. Dadurch kann das Modell seine Genauigkeit schneller verbessern.
- Das Obige ist eine detaillierte Klassifizierung der vier Komponenten von Algorithmen für maschinelles Lernen.
- Merkmale maschineller LernsystemeBeschreibend: Das System sammelt historische Daten, organisiert sie und präsentiert sie dann auf leicht verständliche Weise.
Entscheidungsprozess
Modelle für maschinelles Lernen sind darauf ausgelegt, Muster aus Daten zu lernen und dieses Wissen anzuwenden, um Vorhersagen zu treffen. Die Frage ist: Wie trifft das Modell Vorhersagen?
Der Prozess ist sehr einfach: Finden Sie Muster aus Eingabedaten (beschriftet oder unbeschriftet) und wenden Sie sie an, um ein Ergebnis abzuleiten.
Fehlerfunktion
Modelle für maschinelles Lernen sind darauf ausgelegt, die von ihnen gemachten Vorhersagen mit der Realität zu vergleichen. Das Ziel besteht darin, zu verstehen, ob das Lernen in die richtige Richtung erfolgt. Dies bestimmt die Genauigkeit des Modells und gibt Hinweise darauf, wie wir das Training des Modells verbessern können.
Modelloptimierungsprozess
Das ultimative Ziel des Modells besteht darin, Vorhersagen zu verbessern, was bedeutet, die Differenz zwischen bekannten Ergebnissen und entsprechenden Modellschätzungen zu verringern.
Das Modell muss sich durch ständige Aktualisierung der Gewichte besser an die Trainingsdatenproben anpassen. Der Algorithmus arbeitet in einer Schleife, bewertet und optimiert die Ergebnisse und aktualisiert die Gewichte, bis ein Maximalwert hinsichtlich der Genauigkeit des Modells erreicht wird.
Arten von Methoden des maschinellen Lernens
Maschinelles Lernen umfasst hauptsächlich vier Arten.
1. Überwachtes maschinelles Lernen
Beim überwachten Lernen lernt die Maschine, wie der Name schon sagt, unter Anleitung.
Dies geschieht, indem dem Computer ein Satz gekennzeichneter Daten zugeführt wird, damit die Maschine versteht, was die Eingabe ist und was die Ausgabe sein soll. Hier fungieren Menschen als Führer und versorgen das Modell mit gekennzeichneten Trainingsdaten (Input-Output-Paare), aus denen die Maschine Muster lernt.
Sobald die Beziehung zwischen Eingabe und Ausgabe aus früheren Datensätzen gelernt wurde, kann die Maschine den Ausgabewert neuer Daten leicht vorhersagen.
Wo können wir überwachtes Lernen einsetzen?
Die Antwort lautet: Wenn wir wissen, worauf wir in den Eingabedaten achten müssen und was wir als Ausgabe wünschen.
Zu den Haupttypen überwachter Lernprobleme gehören Regressions- und Klassifizierungsprobleme.
2. Unüberwachtes maschinelles Lernen
Unüberwachtes Lernen funktioniert genau das Gegenteil von überwachtem Lernen.
Es werden unbeschriftete Daten verwendet – die Maschine muss die Daten verstehen, versteckte Muster finden und entsprechende Vorhersagen treffen.
Hier liefern uns Maschinen neue Erkenntnisse, indem sie selbstständig verborgene Muster aus Daten ableiten, ohne dass der Mensch angeben muss, wonach er suchen soll.
Zu den Haupttypen unbeaufsichtigter Lernprobleme gehören Clustering und Assoziationsregelanalyse.
3. Reinforcement Learning
Reinforcement Learning beinhaltet einen Agenten, der lernt, sich in einer Umgebung zu verhalten, indem er Aktionen ausführt.
Basierend auf den Ergebnissen dieser Aktionen gibt es Feedback und passt seinen zukünftigen Kurs an – für jede gute Aktion erhält der Agent ein positives Feedback und für jede schlechte Aktion erhält der Agent ein negatives Feedback oder eine Strafe.
Reinforcement Learning lernt ohne gekennzeichnete Daten. Da es keine gekennzeichneten Daten gibt, kann der Agent nur auf der Grundlage seiner eigenen Erfahrung lernen.
4. Halbüberwachtes Lernen
Halbüberwacht ist der Zustand zwischen überwachtem und unüberwachtem Lernen.
Es nutzt die positiven Aspekte jedes Lernens, d. h. es verwendet kleinere beschriftete Datensätze als Leitfaden für die Klassifizierung und führt eine unbeaufsichtigte Merkmalsextraktion aus größeren unbeschrifteten Datensätzen durch.
Der Hauptvorteil des halbüberwachten Lernens besteht in seiner Fähigkeit, Probleme zu lösen, wenn nicht genügend beschriftete Daten zum Trainieren des Modells vorhanden sind oder wenn die Daten einfach nicht beschriftet werden können, weil Menschen nicht wissen, wonach sie darin suchen sollen.
Vier 6 reale Anwendungen für maschinelles Lernen
Maschinelles Lernen ist heutzutage das Herzstück fast aller Technologieunternehmen, einschließlich Unternehmen wie Google oder der YouTube-Suchmaschine.
Nachfolgend haben wir einige Beispiele für reale Anwendungen des maschinellen Lernens zusammengestellt, mit denen Sie vielleicht vertraut sind:
Selbstfahrende Autos
Fahrzeuge begegnen auf der Straße einer Vielzahl von Situationen.
Damit selbstfahrende Autos besser funktionieren als Menschen, müssen sie lernen und sich an veränderte Straßenverhältnisse und das Verhalten anderer Fahrzeuge anpassen.
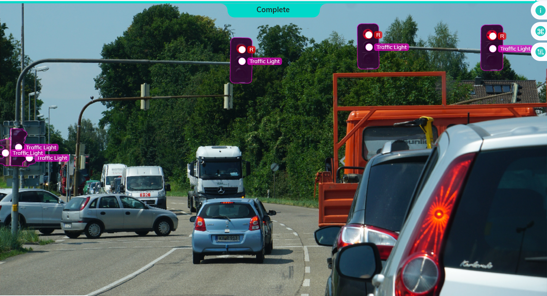
Selbstfahrende Autos sammeln von Sensoren und Kameras Daten über ihre Umgebung, interpretieren diese und reagieren entsprechend. Es nutzt überwachtes Lernen, um Objekte in der Umgebung zu identifizieren, unüberwachtes Lernen, um Muster in anderen Fahrzeugen zu erkennen, und ergreift schließlich mithilfe von Verstärkungsalgorithmen entsprechende Maßnahmen.
Bildanalyse und Objekterkennung
Bildanalyse wird verwendet, um verschiedene Informationen aus Bildern zu extrahieren.
Es gibt Anwendungen in Bereichen wie der Prüfung auf Herstellungsfehler, der Analyse des Autoverkehrs in Smart Cities oder visuellen Suchmaschinen wie Google Lens.
Die Hauptidee besteht darin, mithilfe von Deep-Learning-Techniken Merkmale aus Bildern zu extrahieren und diese Merkmale dann auf die Objekterkennung anzuwenden.
Kundenservice-Chatbots
Heutzutage ist es für Unternehmen weit verbreitet, KI-Chatbots zu verwenden, um Kundensupport und Vertrieb anzubieten. KI-Chatbots helfen Unternehmen bei der Bewältigung großer Mengen an Kundenanfragen, indem sie rund um die Uhr Support bieten, wodurch die Supportkosten gesenkt und zusätzliche Einnahmen und zufriedene Kunden generiert werden.
KI-Robotik nutzt die Verarbeitung natürlicher Sprache (NLP), um Text zu verarbeiten, Abfrageschlüsselwörter zu extrahieren und entsprechend zu reagieren.
Medizinische Bildgebung und Diagnostik
Die Wahrheit ist: Medizinische Bildgebungsdaten sind sowohl die umfangreichste als auch eine der komplexesten Informationsquellen.
Die manuelle Analyse Tausender medizinischer Bilder ist eine mühsame Aufgabe und verschwendet wertvolle Zeit für Pathologen, die effizienter genutzt werden könnte.
Aber es geht nicht nur um Zeitersparnis – kleine Merkmale wie Artefakte oder Knötchen sind möglicherweise mit bloßem Auge nicht sichtbar, was zu Verzögerungen bei der Krankheitsdiagnose und falschen Vorhersagen führt. Aus diesem Grund bietet der Einsatz von Deep-Learning-Techniken mit neuronalen Netzen, mit denen sich Merkmale aus Bildern extrahieren lassen, großes Potenzial.
Betrugserkennung
Mit der Expansion des E-Commerce-Sektors können wir einen Anstieg der Zahl der Online-Transaktionen und eine Diversifizierung der verfügbaren Zahlungsmethoden beobachten. Leider nutzen manche Menschen diese Situation aus. Betrüger in der heutigen Welt sind hochqualifiziert und können neue Technologien sehr schnell übernehmen.
Deshalb brauchen wir ein System, das Datenmuster analysieren, genaue Vorhersagen treffen und auf Online-Cybersicherheitsbedrohungen wie gefälschte Anmeldeversuche oder Phishing-Angriffe reagieren kann.
Beispielsweise können Betrugspräventionssysteme anhand der Tatsache, wo Sie in der Vergangenheit Einkäufe getätigt haben oder wie lange Sie online waren, erkennen, ob ein Kauf legitim ist. Ebenso können sie erkennen, ob jemand online oder am Telefon versucht, sich als Sie auszugeben.
Empfehlungsalgorithmus
Diese Relevanz von Empfehlungsalgorithmen basiert auf der Untersuchung historischer Daten und hängt von mehreren Faktoren ab, einschließlich Benutzerpräferenzen und -interessen.
Unternehmen wie JD.com oder Douyin nutzen Empfehlungssysteme, um relevante Inhalte oder Produkte zu kuratieren und Benutzern/Käufern anzuzeigen.
Fünf Herausforderungen und Einschränkungen des maschinellen Lernens
Unter- und Überanpassung
In den meisten Fällen liegt der Grund für die schlechte Leistung eines Algorithmus für maschinelles Lernen in Unter- und Überanpassung.
Lassen Sie uns diese Begriffe im Kontext des Trainings von Modellen für maschinelles Lernen aufschlüsseln.
- Unteranpassung ist ein Szenario, in dem ein maschinelles Lernmodell weder die Beziehungen zwischen Variablen in den Daten lernen noch neue Datenpunkte korrekt vorhersagen kann. Mit anderen Worten: Das maschinelle Lernsystem erkennt keine Trends über Datenpunkte hinweg.
- Überanpassung tritt auf, wenn ein Modell für maschinelles Lernen zu viel aus den Trainingsdaten lernt und dabei auf Datenpunkte achtet, die von Natur aus verrauscht oder für den Bereich des Datensatzes irrelevant sind. Es versucht, jeden Punkt auf der Kurve anzupassen und sich daher das Datenmuster zu merken.
Da das Modell nur über sehr geringe Flexibilität verfügt, kann es keine neuen Datenpunkte vorhersagen. Mit anderen Worten: Es konzentriert sich zu sehr auf die gegebenen Beispiele und sieht nicht das Gesamtbild.
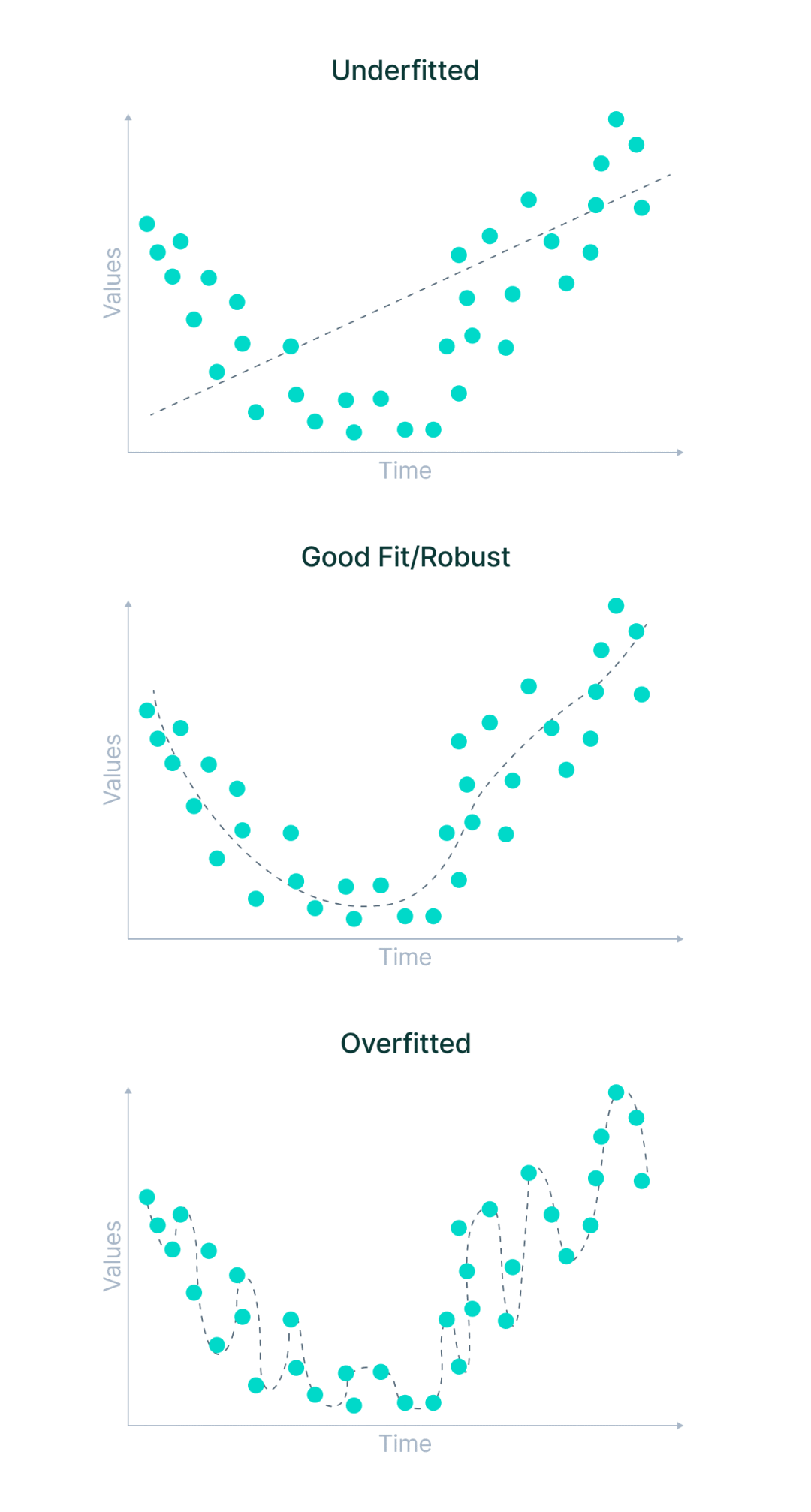
Was sind die Ursachen für Unter- und Überanpassung?
Allgemeinere Fälle umfassen Situationen, in denen die für das Training verwendeten Daten nicht sauber sind und viele Rausch- oder Müllwerte enthalten oder die Datengröße zu klein ist. Es gibt jedoch einige spezifischere Gründe.
Werfen wir einen Blick darauf.
Eine Unteranpassung kann aus folgenden Gründen auftreten:
- Das Modell wurde mit den falschen Parametern trainiert und die Trainingsdaten wurden nicht vollständig eingehalten
- Das Modell ist zu einfach und kann sich nicht genügend Funktionen merken
- Die Trainingsdaten sind zu vielfältig oder komplex
Dies kann in den folgenden Situationen passieren Überanpassung:
- Das Modell wurde mit den falschen Parametern trainiert und hat die Trainingsdaten überbeobachtet.
- Das Modell war zu komplex und nicht auf vielfältigere Daten vorab trainiert.
- Die Bezeichnungen der Trainingsdaten sind zu streng oder die Originaldaten sind zu einheitlich und stellen nicht die wahre Verteilung dar.

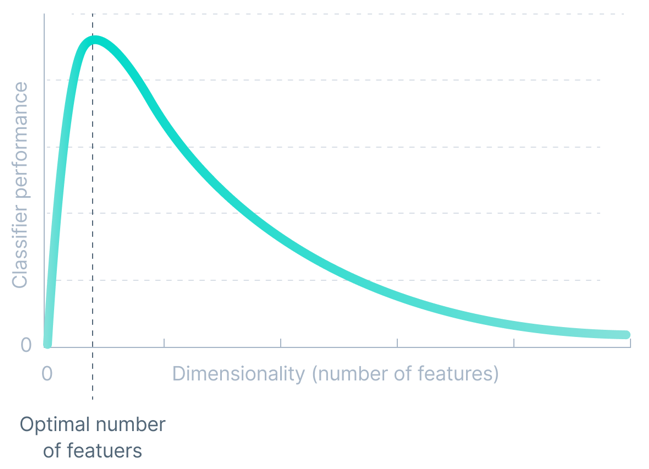
Dimensionalität
Die Genauigkeit jedes maschinellen Lernmodells ist direkt proportional zur Dimensionalität des Datensatzes. Aber es funktioniert nur bis zu einer bestimmten Schwelle.
Die Dimensionalität eines Datensatzes bezieht sich auf die Anzahl der im Datensatz vorhandenen Attribute/Merkmale. Eine exponentielle Erhöhung der Anzahl der Dimensionen führt zur Hinzufügung nicht wesentlicher Attribute, die das Modell verwirren und dadurch die Genauigkeit des maschinellen Lernmodells verringern.
Wir nennen diese Schwierigkeiten, die mit dem Training von Modellen für maschinelles Lernen verbunden sind, den „Fluch der Dimensionalität“.
Datenqualität
Maschinelle Lernalgorithmen reagieren empfindlich auf Trainingsdaten von geringer Qualität.
Die Datenqualität kann durch Rauschen in den Daten aufgrund falscher Daten oder fehlender Werte beeinträchtigt werden. Selbst relativ kleine Fehler in den Trainingsdaten können zu großen Fehlern in der Systemausgabe führen.
Wenn ein Algorithmus eine schlechte Leistung erbringt, liegt dies normalerweise an Problemen mit der Datenqualität, z. B. an unzureichender Menge/Schiefe/verrauschten Daten oder unzureichenden Funktionen zur Beschreibung der Daten.
Vor dem Training eines Modells für maschinelles Lernen ist daher häufig eine Datenbereinigung erforderlich, um qualitativ hochwertige Daten zu erhalten.
Das obige ist der detaillierte Inhalt vonErfahren Sie in einem Artikel, was maschinelles Lernen ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
01Ausblicksübersicht Derzeit ist es schwierig, ein angemessenes Gleichgewicht zwischen Detektionseffizienz und Detektionsergebnissen zu erreichen. Wir haben einen verbesserten YOLOv5-Algorithmus zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern entwickelt, der mehrschichtige Merkmalspyramiden, Multierkennungskopfstrategien und hybride Aufmerksamkeitsmodule verwendet, um die Wirkung des Zielerkennungsnetzwerks in optischen Fernerkundungsbildern zu verbessern. Laut SIMD-Datensatz ist der mAP des neuen Algorithmus 2,2 % besser als YOLOv5 und 8,48 % besser als YOLOX, wodurch ein besseres Gleichgewicht zwischen Erkennungsergebnissen und Geschwindigkeit erreicht wird. 02 Hintergrund und Motivation Mit der rasanten Entwicklung der Fernerkundungstechnologie wurden hochauflösende optische Fernerkundungsbilder verwendet, um viele Objekte auf der Erdoberfläche zu beschreiben, darunter Flugzeuge, Autos, Gebäude usw. Objekterkennung bei der Interpretation von Fernerkundungsbildern
 Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
MetaFAIR hat sich mit Harvard zusammengetan, um einen neuen Forschungsrahmen zur Optimierung der Datenverzerrung bereitzustellen, die bei der Durchführung groß angelegten maschinellen Lernens entsteht. Es ist bekannt, dass das Training großer Sprachmodelle oft Monate dauert und Hunderte oder sogar Tausende von GPUs verwendet. Am Beispiel des Modells LLaMA270B erfordert das Training insgesamt 1.720.320 GPU-Stunden. Das Training großer Modelle stellt aufgrund des Umfangs und der Komplexität dieser Arbeitsbelastungen einzigartige systemische Herausforderungen dar. In letzter Zeit haben viele Institutionen über Instabilität im Trainingsprozess beim Training generativer SOTA-KI-Modelle berichtet. Diese treten normalerweise in Form von Verlustspitzen auf. Beim PaLM-Modell von Google kam es beispielsweise während des Trainingsprozesses zu Instabilitäten. Numerische Voreingenommenheit ist die Hauptursache für diese Trainingsungenauigkeit.
 Maschinelles Lernen in C++: Ein Leitfaden zur Implementierung gängiger Algorithmen für maschinelles Lernen in C++
Jun 03, 2024 pm 07:33 PM
Maschinelles Lernen in C++: Ein Leitfaden zur Implementierung gängiger Algorithmen für maschinelles Lernen in C++
Jun 03, 2024 pm 07:33 PM
In C++ umfasst die Implementierung von Algorithmen für maschinelles Lernen: Lineare Regression: Wird zur Vorhersage kontinuierlicher Variablen verwendet. Zu den Schritten gehören das Laden von Daten, das Berechnen von Gewichtungen und Verzerrungen, das Aktualisieren von Parametern und die Vorhersage. Logistische Regression: Wird zur Vorhersage diskreter Variablen verwendet. Der Prozess ähnelt der linearen Regression, verwendet jedoch die Sigmoidfunktion zur Vorhersage. Support Vector Machine: Ein leistungsstarker Klassifizierungs- und Regressionsalgorithmus, der die Berechnung von Support-Vektoren und die Vorhersage von Beschriftungen umfasst.
 Ausblick auf zukünftige Trends der Golang-Technologie im maschinellen Lernen
May 08, 2024 am 10:15 AM
Ausblick auf zukünftige Trends der Golang-Technologie im maschinellen Lernen
May 08, 2024 am 10:15 AM
Das Anwendungspotenzial der Go-Sprache im Bereich des maschinellen Lernens ist enorm. Ihre Vorteile sind: Parallelität: Sie unterstützt die parallele Programmierung und eignet sich für rechenintensive Operationen bei maschinellen Lernaufgaben. Effizienz: Der Garbage Collector und die Sprachfunktionen sorgen dafür, dass der Code auch bei der Verarbeitung großer Datenmengen effizient ist. Benutzerfreundlichkeit: Die Syntax ist prägnant und erleichtert das Erlernen und Schreiben von Anwendungen für maschinelles Lernen.
