
 Technologie-Peripheriegeräte
KI
Wie lässt sich LLM mit einer einzelnen GPU optimieren, um Einschränkungen der Rechenleistung zu umgehen? Dies ist ein Tutorial zum „Gradient Accumulation'-Algorithmus
Technologie-Peripheriegeräte
KI
Wie lässt sich LLM mit einer einzelnen GPU optimieren, um Einschränkungen der Rechenleistung zu umgehen? Dies ist ein Tutorial zum „Gradient Accumulation'-Algorithmus
Wie lässt sich LLM mit einer einzelnen GPU optimieren, um Einschränkungen der Rechenleistung zu umgehen? Dies ist ein Tutorial zum „Gradient Accumulation'-Algorithmus

Seit große Modelle zum Trend geworden sind, sind GPUs zu einem knappen Gut geworden. Die Reserven vieler Unternehmen reichen möglicherweise nicht aus, geschweige denn einzelner Entwickler. Gibt es eine Möglichkeit, Rechenleistung zu nutzen, um Modelle effizienter zu trainieren?
In einem aktuellen Blog stellte Sebastian Raschka die Methode „Gradientenakkumulation“ vor, mit der eine größere Batchgröße zum Trainieren des Modells verwendet werden kann, wenn der GPU-Speicher begrenzt ist, und so Hardwareeinschränkungen umgeht.

Zuvor hat Sebastian Raschka auch einen Artikel geteilt, in dem Multi-GPU-Trainingsstrategien verwendet werden, um die Feinabstimmung großer Sprachmodelle zu beschleunigen, einschließlich Mechanismen wie Modell- oder Tensor-Sharding, die Modellgewichte verteilen und Berechnungen zwischen verschiedenen Geräten, um GPU-Speicherbeschränkungen zu umgehen.
Feinabstimmung des BLOOM-Modells für die Klassifizierung
Angenommen, wir sind daran interessiert, ein kürzlich vorab trainiertes großes Sprachmodell zu übernehmen, um nachgelagerte Aufgaben wie die Textklassifizierung zu bewältigen. Dann könnten wir uns dafür entscheiden, das alternative Open-Source-BLOOM-Modell von GPT-3 zu verwenden, insbesondere die BLOOM-Version mit „nur“ 560 Millionen Parametern – sie sollte problemlos in den RAM einer herkömmlichen GPU passen (Google Colab ist eine kostenlose Version). hat eine GPU mit 15 GB RAM).
Sobald Sie anfangen, werden Sie wahrscheinlich auf Probleme stoßen: Während des Trainings oder der Feinabstimmung nimmt das Gedächtnis schnell zu. Die einzige Möglichkeit, dieses Modell zu trainieren, ist mit einer Stapelgröße von 1.

Der Code zur Feinabstimmung von BLOOM für die Zielklassifizierungsaufgabe unter Verwendung einer Stapelgröße von 1 (Stapelgröße = 1) lautet wie folgt. Sie können den vollständigen Code auch auf der GitHub-Projektseite herunterladen:
https://github.com/rasbt/gradient-accumulation-blog/blob/main/src/1_batchsize-1.py
Das können Sie Verwenden Sie dies. Der Code wird kopiert und direkt in Google Colab eingefügt, aber die zugehörige Datei local_dataset_utilities.py muss auch per Drag & Drop in denselben Ordner gezogen werden, aus dem einige Datensatz-Dienstprogramme importiert wurden.
<code># pip install torch lightning matplotlib pandas torchmetrics watermark transformers datasets -Uimport osimport os.path as opimport timefrom datasets import load_datasetfrom lightning import Fabricimport torchfrom torch.utils.data import DataLoaderimport torchmetricsfrom transformers import AutoTokenizerfrom transformers import AutoModelForSequenceClassificationfrom watermark import watermarkfrom local_dataset_utilities import download_dataset, load_dataset_into_to_dataframe, partition_datasetfrom local_dataset_utilities import IMDBDatasetdef tokenize_text (batch):return tokenizer (batch ["text"], truncatinotallow=True, padding=True, max_length=1024)def train (num_epochs, model, optimizer, train_loader, val_loader, fabric):for epoch in range (num_epochs):train_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch_idx, batch in enumerate (train_loader):model.train ()### FORWARD AND BACK PROPoutputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"]) fabric.backward (outputs ["loss"])### UPDATE MODEL PARAMETERSoptimizer.step ()optimizer.zero_grad ()### LOGGINGif not batch_idx % 300:print (f"Epoch: {epoch+1:04d}/{num_epochs:04d}"f"| Batch {batch_idx:04d}/{len (train_loader):04d}"f"| Loss: {outputs ['loss']:.4f}")model.eval ()with torch.no_grad ():predicted_labels = torch.argmax (outputs ["logits"], 1)train_acc.update (predicted_labels, batch ["label"])### MORE LOGGINGmodel.eval ()with torch.no_grad ():val_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch in val_loader:outputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"])predicted_labels = torch.argmax (outputs ["logits"], 1)val_acc.update (predicted_labels, batch ["label"])print (f"Epoch: {epoch+1:04d}/{num_epochs:04d}"f"| Train acc.: {train_acc.compute ()*100:.2f}%"f"| Val acc.: {val_acc.compute ()*100:.2f}%")train_acc.reset (), val_acc.reset ()if __name__ == "__main__":print (watermark (packages="torch,lightning,transformers", pythnotallow=True))print ("Torch CUDA available?", torch.cuda.is_available ())device = "cuda" if torch.cuda.is_available () else "cpu"torch.manual_seed (123)# torch.use_deterministic_algorithms (True)############################# 1 Loading the Dataset##########################download_dataset ()df = load_dataset_into_to_dataframe ()if not (op.exists ("train.csv") and op.exists ("val.csv") and op.exists ("test.csv")):partition_dataset (df)imdb_dataset = load_dataset ("csv",data_files={"train": "train.csv","validation": "val.csv","test": "test.csv",},)############################################ 2 Tokenization and Numericalization#########################################tokenizer = AutoTokenizer.from_pretrained ("bigscience/bloom-560m", max_length=1024)print ("Tokenizer input max length:", tokenizer.model_max_length, flush=True)print ("Tokenizer vocabulary size:", tokenizer.vocab_size, flush=True)print ("Tokenizing ...", flush=True)imdb_tokenized = imdb_dataset.map (tokenize_text, batched=True, batch_size=None)del imdb_datasetimdb_tokenized.set_format ("torch", columns=["input_ids", "attention_mask", "label"])os.environ ["TOKENIZERS_PARALLELISM"] = "false"############################################ 3 Set Up DataLoaders#########################################train_dataset = IMDBDataset (imdb_tokenized, partition_key="train")val_dataset = IMDBDataset (imdb_tokenized, partition_key="validation")test_dataset = IMDBDataset (imdb_tokenized, partition_key="test")train_loader = DataLoader (dataset=train_dataset,batch_size=1,shuffle=True,num_workers=4,drop_last=True,)val_loader = DataLoader (dataset=val_dataset,batch_size=1,num_workers=4,drop_last=True,)test_loader = DataLoader (dataset=test_dataset,batch_size=1,num_workers=2,drop_last=True,)############################################ 4 Initializing the Model#########################################fabric = Fabric (accelerator="cuda", devices=1, precisinotallow="16-mixed")fabric.launch ()model = AutoModelForSequenceClassification.from_pretrained ("bigscience/bloom-560m", num_labels=2)optimizer = torch.optim.Adam (model.parameters (), lr=5e-5)model, optimizer = fabric.setup (model, optimizer)train_loader, val_loader, test_loader = fabric.setup_dataloaders (train_loader, val_loader, test_loader)############################################ 5 Finetuning#########################################start = time.time ()train (num_epochs=1,model=model,optimizer=optimizer,train_loader=train_loader,val_loader=val_loader,fabric=fabric,)end = time.time ()elapsed = end-startprint (f"Time elapsed {elapsed/60:.2f} min")with torch.no_grad ():model.eval ()test_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch in test_loader:outputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"])predicted_labels = torch.argmax (outputs ["logits"], 1)test_acc.update (predicted_labels, batch ["label"])print (f"Test accuracy {test_acc.compute ()*100:.2f}%")</code>Der Autor hat Lightning Fabric verwendet, weil es Entwicklern ermöglicht, die Anzahl der GPUs und Multi-GPU-Trainingsstrategien flexibel zu ändern, wenn dieser Code auf unterschiedlicher Hardware ausgeführt wird. Es ermöglicht auch das Training mit gemischter Präzision durch einfaches Anpassen der Präzisionsflagge. In diesem Fall kann ein Training mit gemischter Präzision die Trainingsgeschwindigkeit um das Dreifache erhöhen und den Speicherbedarf um etwa 25 % senken.
Der oben gezeigte Hauptcode wird in der Hauptfunktion ausgeführt (wenn __name__ == „__main__“-Kontext. Auch wenn nur eine einzelne GPU verwendet wird, wird empfohlen, die PyTorch-Laufumgebung zu verwenden, um ein Multi-GPU-Training durchzuführen . Dann sind die folgenden drei Codeteile, die in if __name__ == "__main__" enthalten sind, für das Laden der Daten verantwortlich:
# 1 Laden Sie den Datensatz
# 2 Tokenisierung und Numerisierung
# 3 Richten Sie den ein data Loader
Abschnitt 4 ist die Initialisierung des Modells, und dann wird in Abschnitt 5 die Feinabstimmung der Zugfunktion aufgerufen. Hier wird es interessant. In der Funktion train (...) ist eine Standard-PyTorch-Schleife implementiert. Die kommentierte Version der Kerntrainingsschleife sieht folgendermaßen aus:
Das Problem mit Batch-Größe 1 (Batch-Größe=1) besteht darin, dass Gradientenaktualisierungen sehr verwirrend und schwierig werden, wie unten gezeigt, wenn das Modell basierend auf der Fluktuation trainiert wird Was kann man tun, um Modelle mit größeren Batch-Größen zu trainieren, da nicht viele GPUs für Tensor-Sharding verfügbar sind?
Eine Lösung ist die Gradientenakkumulation, mit der die zuvor erwähnte Trainingsschleife modifiziert werden kann.
什么是梯度积累?
梯度累积是一种在训练期间虚拟增加批大小(batch size)的方法,当可用的 GPU 内存不足以容纳所需的批大小时,这非常有用。在梯度累积中,梯度是针对较小的批次计算的,并在多次迭代中累积(通常是求和或平均),而不是在每一批次之后更新模型权重。一旦累积梯度达到目标「虚拟」批大小,模型权重就会使用累积梯度进行更新。
参考下面更新的 PyTorch 训练循环:
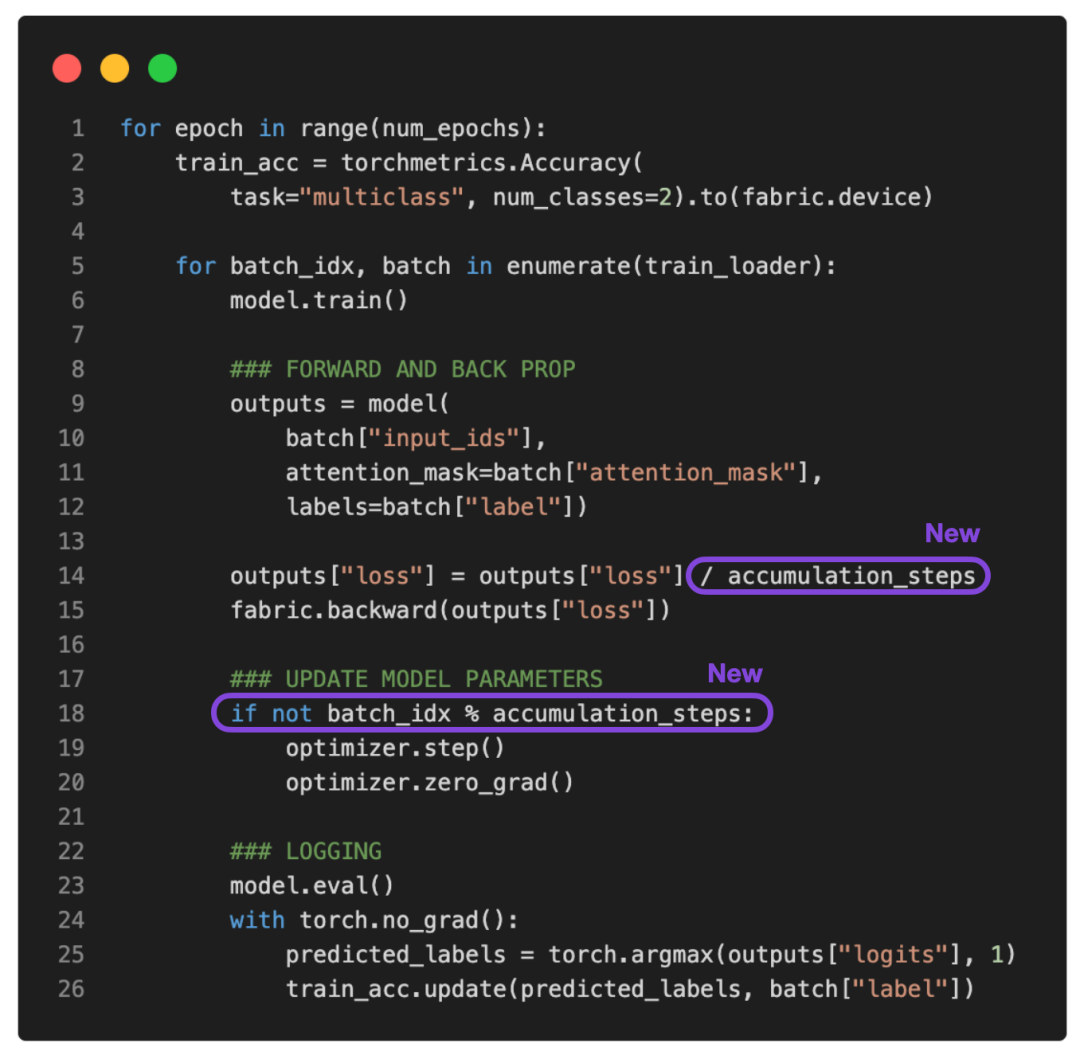
如果将 accumulation_steps 设置为 2,那么 zero_grad () 和 optimizer.step () 将只会每隔一秒调用一次。因此,使用 accumulation_steps=2 运行修改后的训练循环与将批大小(batch size)加倍具有相同的效果。
例如,如果想使用 256 的批大小,但只能将 64 的批大小放入 GPU 内存中,就可以对大小为 64 的四个批执行梯度累积。(处理完所有四个批次后,将获得相当于单个批大小为 256 的累积梯度。)这样能够有效地模拟更大的批大小,而无需更大的 GPU 内存或跨不同设备的张量分片。
虽然梯度累积可以帮助我们训练具有更大批量大小的模型,但它不会减少所需的总计算量。实际上,它有时会导致训练过程略慢一些,因为权重更新的执行频率较低。尽管如此,它却能帮我们解决限制问题,即批大小非常小时导致的更新频繁且混乱。
例如,现在让我们运行上面的代码,批大小为 1,需要 16 个累积步骤(accumulation steps)来模拟批大小等于 16。
输出如下:
<code>...torch : 2.0.0lightning : 2.0.0transformers: 4.27.2Torch CUDA available? True...Epoch: 0001/0001 | Batch 23700/35000 | Loss: 0.0168Epoch: 0001/0001 | Batch 24000/35000 | Loss: 0.0006Epoch: 0001/0001 | Batch 24300/35000 | Loss: 0.0152Epoch: 0001/0001 | Batch 24600/35000 | Loss: 0.0003Epoch: 0001/0001 | Batch 24900/35000 | Loss: 0.0623Epoch: 0001/0001 | Batch 25200/35000 | Loss: 0.0010Epoch: 0001/0001 | Batch 25500/35000 | Loss: 0.0001Epoch: 0001/0001 | Batch 25800/35000 | Loss: 0.0047Epoch: 0001/0001 | Batch 26100/35000 | Loss: 0.0004Epoch: 0001/0001 | Batch 26400/35000 | Loss: 0.1016Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.0021Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0008Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.0060Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0001Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.0426Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.0012Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0025Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0025Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0000Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.0495Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.0164Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.0067Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.0037Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0005Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0013Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.0112Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0053Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.0012Epoch: 0001/0001 | Batch 32400/35000 | Loss: 0.1365Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.0210Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.0374Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0007Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.0341Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.0259Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0005Epoch: 0001/0001 | Batch 34500/35000 | Loss: 0.4792Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0003Epoch: 0001/0001 | Train acc.: 78.67% | Val acc.: 87.28%Time elapsed 51.37 minTest accuracy 87.37%</code>
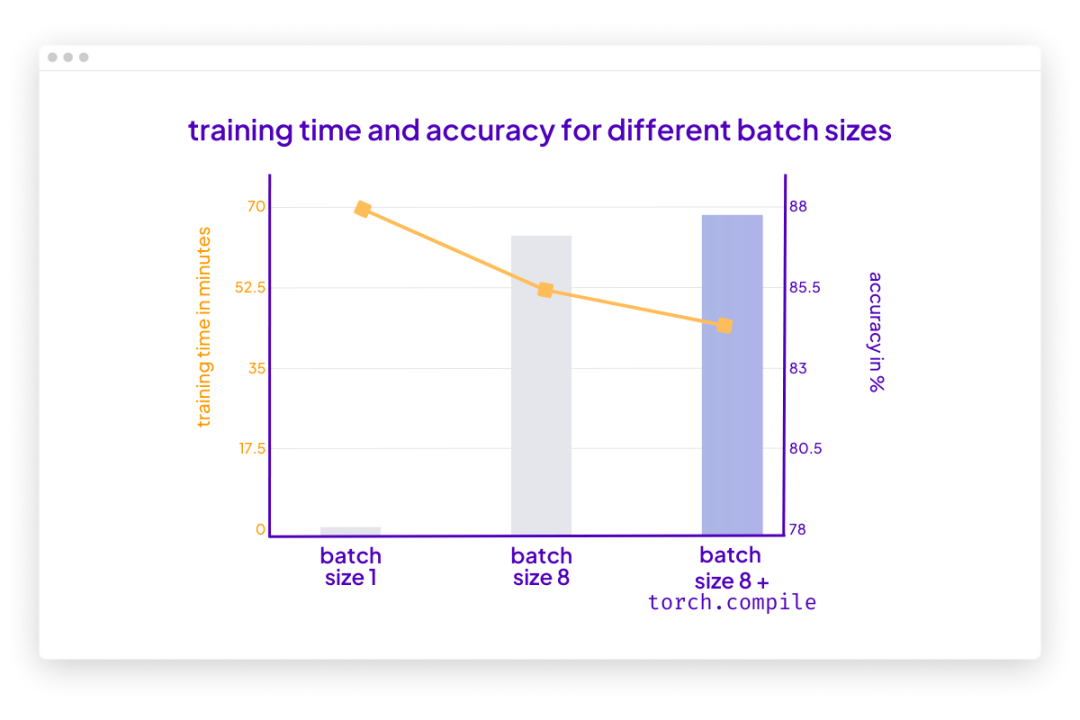
根据上面的结果,损失的波动比以前小了。此外,测试集性能提升了 10%。由于只迭代了训练集一次,因此每个训练样本只会遇到一次。训练用于 multiple epochs 的模型可以进一步提高预测性能。
你可能还会注意到,这段代码的执行速度也比之前使用的批大小为 1 的代码快。如果使用梯度累积将虚拟批大小增加到 8,仍然会有相同数量的前向传播(forward passes)。然而,由于每八个 epoch 只更新一次模型,因此反向传播(backward passes)会很少,这样可更快地在一个 epoch(训练轮数)内迭代样本。
结论
梯度累积是一种在执行权重更新之前通过累积多个小的批梯度来模拟更大的批大小的技术。该技术在可用内存有限且内存中可容纳批大小较小的情况下提供帮助。
但是,首先请思考一种你可以运行批大小的场景,这意味着可用内存大到足以容纳所需的批大小。在那种情况下,梯度累积可能不是必需的。事实上,运行更大的批大小可能更有效,因为它允许更多的并行性且能减少训练模型所需的权重更新次数。
总之,梯度累积是一种实用的技术,可以用于降低小批大小干扰信息对梯度更新准确性的影响。这是迄今一种简单而有效的技术,可以让我们绕过硬件的限制。
PS:可以让这个运行得更快吗?
没问题。可以使用 PyTorch 2.0 中引入的 torch.compile 使其运行得更快。只需要添加一些 model = torch.compile,如下图所示:
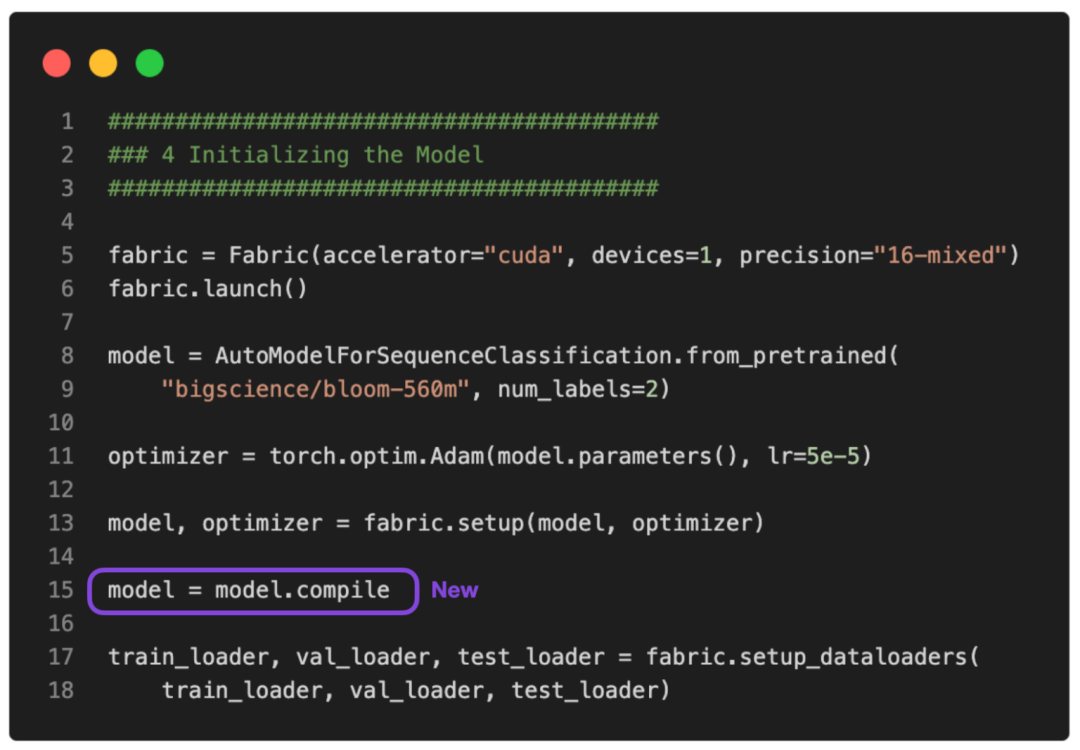
GitHub 上提供了完整的脚本。
在这种情况下,torch.compile 在不影响建模性能的情况下又减少了十分钟的训练时间:
<code>poch: 0001/0001 | Batch 26400/35000 | Loss: 0.0320Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.0010Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.0006Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.0157Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.0540Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.0035Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0016Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0008Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.0877Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.0232Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.0014Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.0032Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0004Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0062Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.0032Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0066Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.0017Epoch: 0001/0001 | Batch 32400/35000 | Loss: 0.1485Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.0324Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.0155Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0007Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.0049Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.1170Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0002Epoch: 0001/0001 | Batch 34500/35000 | Loss: 0.4201Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0018Epoch: 0001/0001 | Train acc.: 78.39% | Val acc.: 86.84%Time elapsed 43.33 minTest accuracy 87.91%</code>
请注意,与之前相比准确率略有提高很可能是由于随机性。
Das obige ist der detaillierte Inhalt vonWie lässt sich LLM mit einer einzelnen GPU optimieren, um Einschränkungen der Rechenleistung zu umgehen? Dies ist ein Tutorial zum „Gradient Accumulation'-Algorithmus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Vier empfohlene KI-gestützte Programmiertools
Apr 22, 2024 pm 05:34 PM
Vier empfohlene KI-gestützte Programmiertools
Apr 22, 2024 pm 05:34 PM
Dieses KI-gestützte Programmiertool hat in dieser Phase der schnellen KI-Entwicklung eine große Anzahl nützlicher KI-gestützter Programmiertools zu Tage gefördert. KI-gestützte Programmiertools können die Entwicklungseffizienz verbessern, die Codequalität verbessern und Fehlerraten reduzieren. Sie sind wichtige Helfer im modernen Softwareentwicklungsprozess. Heute wird Dayao Ihnen 4 KI-gestützte Programmiertools vorstellen (und alle unterstützen die C#-Sprache). https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot ist ein KI-Codierungsassistent, der Ihnen hilft, Code schneller und mit weniger Aufwand zu schreiben, sodass Sie sich mehr auf Problemlösung und Zusammenarbeit konzentrieren können. Git
 Welcher KI-Programmierer ist der beste? Entdecken Sie das Potenzial von Devin, Tongyi Lingma und SWE-Agent
Apr 07, 2024 am 09:10 AM
Welcher KI-Programmierer ist der beste? Entdecken Sie das Potenzial von Devin, Tongyi Lingma und SWE-Agent
Apr 07, 2024 am 09:10 AM
Am 3. März 2022, weniger als einen Monat nach der Geburt von Devin, dem weltweit ersten KI-Programmierer, entwickelte das NLP-Team der Princeton University einen Open-Source-KI-Programmierer-SWE-Agenten. Es nutzt das GPT-4-Modell, um Probleme in GitHub-Repositorys automatisch zu lösen. Die Leistung des SWE-Agenten auf dem SWE-Bench-Testsatz ist ähnlich wie die von Devin, er benötigt durchschnittlich 93 Sekunden und löst 12,29 % der Probleme. Durch die Interaktion mit einem dedizierten Terminal kann der SWE-Agent Dateiinhalte öffnen und durchsuchen, die automatische Syntaxprüfung verwenden, bestimmte Zeilen bearbeiten sowie Tests schreiben und ausführen. (Hinweis: Der obige Inhalt stellt eine geringfügige Anpassung des Originalinhalts dar, die Schlüsselinformationen im Originaltext bleiben jedoch erhalten und überschreiten nicht die angegebene Wortbeschränkung.) SWE-A
 Erfahren Sie, wie Sie mobile Anwendungen mit der Go-Sprache entwickeln
Mar 28, 2024 pm 10:00 PM
Erfahren Sie, wie Sie mobile Anwendungen mit der Go-Sprache entwickeln
Mar 28, 2024 pm 10:00 PM
Tutorial zur Entwicklung mobiler Anwendungen in der Go-Sprache Da der Markt für mobile Anwendungen weiterhin boomt, beginnen immer mehr Entwickler damit, sich mit der Verwendung der Go-Sprache für die Entwicklung mobiler Anwendungen zu befassen. Als einfache und effiziente Programmiersprache hat die Go-Sprache auch großes Potenzial für die Entwicklung mobiler Anwendungen gezeigt. In diesem Artikel wird detailliert beschrieben, wie die Go-Sprache zum Entwickeln mobiler Anwendungen verwendet wird, und es werden spezifische Codebeispiele angehängt, um den Lesern den schnellen Einstieg und die Entwicklung eigener mobiler Anwendungen zu erleichtern. 1. Vorbereitung Bevor wir beginnen, müssen wir die Entwicklungsumgebung und die Tools vorbereiten. Kopf
 Zusammenfassung der fünf beliebtesten Go-Sprachbibliotheken: wesentliche Tools für die Entwicklung
Feb 22, 2024 pm 02:33 PM
Zusammenfassung der fünf beliebtesten Go-Sprachbibliotheken: wesentliche Tools für die Entwicklung
Feb 22, 2024 pm 02:33 PM
Zusammenfassung der fünf beliebtesten Go-Sprachbibliotheken: wesentliche Werkzeuge für die Entwicklung, die spezifische Codebeispiele erfordern Seit ihrer Geburt hat die Go-Sprache große Aufmerksamkeit und Anwendung gefunden. Als aufstrebende effiziente und prägnante Programmiersprache ist die schnelle Entwicklung von Go untrennbar mit der Unterstützung umfangreicher Open-Source-Bibliotheken verbunden. In diesem Artikel werden fünf beliebte Go-Sprachbibliotheken vorgestellt. Diese Bibliotheken spielen eine wichtige Rolle bei der Go-Entwicklung und bieten Entwicklern leistungsstarke Funktionen und praktische Entwicklungserfahrung. Um die Verwendung und Funktion dieser Bibliotheken besser zu verstehen, werden wir sie gleichzeitig anhand konkreter Codebeispiele erläutern.
 Welche Linux-Distribution eignet sich am besten für die Android-Entwicklung?
Mar 14, 2024 pm 12:30 PM
Welche Linux-Distribution eignet sich am besten für die Android-Entwicklung?
Mar 14, 2024 pm 12:30 PM
Die Android-Entwicklung ist eine arbeitsreiche und spannende Aufgabe, und die Auswahl einer geeigneten Linux-Distribution für die Entwicklung ist besonders wichtig. Welche der vielen Linux-Distributionen eignet sich am besten für die Android-Entwicklung? In diesem Artikel wird dieses Problem unter verschiedenen Aspekten untersucht und spezifische Codebeispiele aufgeführt. Werfen wir zunächst einen Blick auf einige derzeit beliebte Linux-Distributionen: Ubuntu, Fedora, Debian, CentOS usw. Sie alle haben ihre eigenen Vorteile und Eigenschaften.
 Erkundung der Front-End-Technologie der Go-Sprache: eine neue Vision für die Front-End-Entwicklung
Mar 28, 2024 pm 01:06 PM
Erkundung der Front-End-Technologie der Go-Sprache: eine neue Vision für die Front-End-Entwicklung
Mar 28, 2024 pm 01:06 PM
Als schnelle und effiziente Programmiersprache erfreut sich Go im Bereich der Backend-Entwicklung großer Beliebtheit. Allerdings assoziieren nur wenige Menschen die Go-Sprache mit der Front-End-Entwicklung. Tatsächlich kann die Verwendung der Go-Sprache für die Front-End-Entwicklung nicht nur die Effizienz verbessern, sondern Entwicklern auch neue Horizonte eröffnen. In diesem Artikel wird die Möglichkeit der Verwendung der Go-Sprache für die Front-End-Entwicklung untersucht und spezifische Codebeispiele bereitgestellt, um den Lesern ein besseres Verständnis dieses Bereichs zu erleichtern. In der traditionellen Frontend-Entwicklung werden häufig JavaScript, HTML und CSS zum Erstellen von Benutzeroberflächen verwendet
 VSCode verstehen: Wofür wird dieses Tool verwendet?
Mar 25, 2024 pm 03:06 PM
VSCode verstehen: Wofür wird dieses Tool verwendet?
Mar 25, 2024 pm 03:06 PM
„VSCode verstehen: Wofür wird dieses Tool verwendet?“ „Als Programmierer, egal ob Sie Anfänger oder erfahrener Entwickler sind, können Sie auf den Einsatz von Codebearbeitungstools nicht verzichten.“ Unter vielen Bearbeitungstools ist Visual Studio Code (kurz VSCode) bei Entwicklern als Open-Source-, leichter und leistungsstarker Code-Editor sehr beliebt. Wofür genau wird VSCode verwendet? Dieser Artikel befasst sich mit den Funktionen und Verwendungsmöglichkeiten von VSCode und stellt spezifische Codebeispiele bereit, um den Lesern zu helfen
 Umfassende Anleitung: Detaillierter Java Virtual Machine-Installationsprozess
Jan 24, 2024 am 09:02 AM
Umfassende Anleitung: Detaillierter Java Virtual Machine-Installationsprozess
Jan 24, 2024 am 09:02 AM
Grundlagen für die Java-Entwicklung: Detaillierte Erläuterung der Installationsschritte für virtuelle Java-Maschinen, spezifische Codebeispiele erforderlich. Mit der Entwicklung der Informatik und Technologie ist die Java-Sprache zu einer der am weitesten verbreiteten Programmiersprachen geworden. Es bietet die Vorteile einer plattformübergreifenden und objektorientierten Sprache und hat sich nach und nach zur bevorzugten Sprache für Entwickler entwickelt. Bevor Sie Java für die Entwicklung verwenden, müssen Sie zunächst die Java Virtual Machine (JavaVirtualMachine, JVM) installieren. In diesem Artikel werden die Installationsschritte der Java Virtual Machine ausführlich erläutert und spezifische Codebeispiele bereitgestellt.
