
 Technologie-Peripheriegeräte
KI
UCSD, MIT und andere chinesische Teams bringen Roboterhunden bei, die 3D-Welt wahrzunehmen! Mit dem M1-Chip können Sie Treppen steigen und Hindernisse überwinden.
Technologie-Peripheriegeräte
KI
UCSD, MIT und andere chinesische Teams bringen Roboterhunden bei, die 3D-Welt wahrzunehmen! Mit dem M1-Chip können Sie Treppen steigen und Hindernisse überwinden.
UCSD, MIT und andere chinesische Teams bringen Roboterhunden bei, die 3D-Welt wahrzunehmen! Mit dem M1-Chip können Sie Treppen steigen und Hindernisse überwinden.

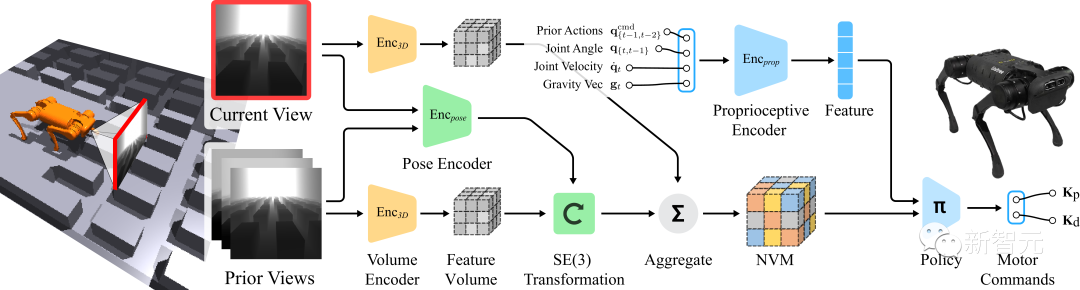
Kürzlich verwendeten Forscher von UCSD-, IAIFI- und MIT-Institutionen eine neue neuronale volumetrische Speicherarchitektur (NVM), um einem Roboterhund beizubringen, die dreidimensionale Welt wahrzunehmen.
Mit dieser Technologie kann der Roboterhund über ein einziges neuronales Netzwerk Treppen steigen, Lücken überqueren, Hindernisse überwinden usw. – völlig autonom, ohne dass eine Fernbedienung erforderlich ist.

Ich frage mich, ob Ihnen das weiße Kästchen auf dem Rücken des Hundes aufgefallen ist?
Er ist mit Apples M1-Chip ausgestattet, der für die visuellen Verarbeitungsaufgaben des Roboterhundes verantwortlich ist. Darüber hinaus entfernte das Team es von einem Mac.
Es ist nicht schwer zu erkennen, dass dieser Roboterhund vom MIT (im Grunde genommen) mühelos einen Astabschnitt vor sich erklimmen kann.
Ein MacBook mit 4 Beinen?
Wie wir alle wissen, ist es für Roboterhunde und Roboter mit anderen Beinen sehr schwierig, unebene Straßen zu überqueren.
Je komplexer die Straßenverhältnisse sind, desto mehr Hindernisse gibt es, die nicht sichtbar sind.
Um das Problem der „teilweise beobachtbaren Umgebung“ zu lösen, verbindet die aktuelle Visual-Motion-Technologie von SOTA Bildkanäle durch Frame-Stacking.
Diese einfache Verarbeitungsmethode bleibt jedoch weit hinter der aktuellen Computer-Vision-Technologie zurück, die den optischen Fluss und bestimmte 3D-Geometrien explizit modellieren kann.
Davon inspiriert schlug das Team eine neuronale Volumenspeicherarchitektur (NVM) vor, die die SE(3)-Äquivalenz der dreidimensionalen Welt vollständig berücksichtigen kann.

Projektadresse: https://rcchayang.github.io/NVM/
Anders als frühere Methoden ist NVM ein volumetrisches Format. Es aggregiert Merkmalsvolumina aus mehreren Kameraansichten im egozentrischen Rahmen des Roboters und ermöglicht so dem Roboter, seine Umgebung besser zu verstehen.
Die Testergebnisse zeigen, dass nach dem Einsatz des neuronalen volumetrischen Gedächtnisses (NVM) zum Trainieren der Beinbewegungen die Leistung des Roboters auf komplexem Gelände deutlich besser ist als bei der bisherigen Technologie.
Darüber hinaus zeigen die Ergebnisse der Ablationsexperimente, dass der im neuronalen volumetrischen Gedächtnis gespeicherte Inhalt genügend geometrische Informationen erfasst, um die 3D-Szene zu rekonstruieren.
Experimente in der realen Welt
Um dies in verschiedenen realen Szenarien außerhalb von Simulationen zu überprüfen, führte das Team Experimente sowohl in Innen- als auch in Außenszenarien durch.

Wenn der Roboterhund feststellt, dass plötzlich ein Hindernis vor ihm auftaucht, weicht er diesem sofort aus.

Das Gehen auf dem felsigen Untergrund scheint kein Problem zu sein, obwohl es immer noch anstrengender ist als auf flachem Untergrund.

Hindernisse, die im Vergleich zu einem selbst relativ groß sind, können dennoch mit harter Arbeit überwunden werden.

Unter Verwendung der bisherigen Erkennungskontrolltechnologie machten die Hinterbeine des Welpen offensichtlich Fehler bei der Einschätzung der Entfernung. Er trat in einen Graben und überschlug sich, was jedoch fehlschlug.

Nachdem der Welpe das vom MIT vorgeschlagene NVM übernommen hatte, überquerte er den Graben, stabiles Glück und Erfolg!

Mit der bisherigen Erkennungskontrolltechnologie verfehlte der Welpe mit seinem ersten Tritt das Ziel, der Kopf des Hundes packte den Boden und scheiterte.

Nachdem der Welpe das vom MIT vorgeschlagene NVM übernommen hatte, lief der Welpe reibungslos durch die Matrix.

Volumengedächtnis von Beinbewegungen
Die Verwendung einer egozentrischen Kameraperspektive ist im Wesentlichen ein Problem im Umgang mit einer „teilweise beobachtbaren Umgebung“ (teilweise beobachtet).
Um das Steuerungsproblem konkret zu machen, muss der Roboter Informationen aus vorherigen Frames sammeln und verdecktes Gelände korrekt ableiten.
Während der Bewegung erfährt die direkt am Roboterchassis montierte Kamera drastische und plötzliche Positionsänderungen.
Auf diese Weise wird es bei der Charakterisierung einer Bildserie sehr wichtig, dass ein einzelner Rahmen an der richtigen Position platziert werden kann.
Zu diesem Zweck kann das vom Team vorgeschlagene Konzept des Neural Volume Memory (NVM) eine Reihe eingegebener visueller Informationen in Szenenmerkmale für die 3D-Darstellung umwandeln und dann ausgeben.
Lernen von NVM durch selbstüberwachtes Lernen
Während das „Ziel des Verhaltensklonens“ ausreicht, um eine gute Strategie zu entwickeln, sorgt die Äquivarianz von Übersetzung und Rotation automatisch für ein unabhängiges, selbstüberwachtes Lernen Ziele.
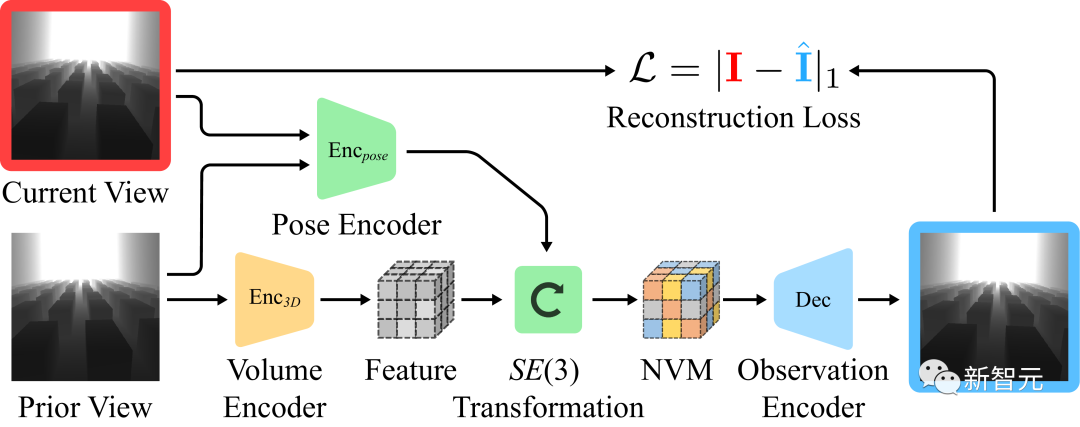
Selbstüberwachtes Lernen: Das Forschungsteam trainierte einen unabhängigen Decoder. Lassen Sie visuelle Beobachtungen in verschiedenen Frames vorhersagen, indem Sie eine visuelle Beobachtung durchführen und den Übergang zwischen zwei Frames schätzen.
Wie im Bild oben gezeigt, kann davon ausgegangen werden, dass die umgebende 3D-Szene zwischen den Bildern unverändert bleibt. Da die Kamera nach vorne blickt, können wir die Feature-Lautstärke aus vorherigen Bildern normalisieren und zur Vorhersage nachfolgender Bilder verwenden.
Visuelle Rekonstruktion des Decoders
Das erste Bild zeigt die Bewegung des Roboters in der Umgebung, das zweite Bild ist das eingegebene visuelle Beobachtungsergebnis und das dritte Bild ist die Vision, die unter Verwendung des 3D-Feature-Volumens und des geschätzten Bildes Observe synthetisiert wurde die Wirkung.
Für die visuelle Beobachtung der Eingabe wendete das Forschungsteam zahlreiche Datenverbesserungen an den Bildern an, um die Robustheit des Modells zu verbessern.
#? # Ruihan Yan
Ruihan Yan

# 🎜 🎜#
Ge Yang schloss sein Studium an der Yale University mit einem Bachelor-Abschluss in Physik und Mathematik ab und erhielt einen Doktortitel in Physik von der University of Chicago. Derzeit ist er Postdoktorand am Institute for Artificial Intelligence and Fundamental Interactions (IAIFI) der National Science Foundation.Ge Yangs Forschung umfasst zwei Gruppen verwandter Fragen. Die erste Gruppe besteht darin, das Lernen zu verbessern, indem wir die Art und Weise überdenken, wie wir Wissen in neuronalen Netzen darstellen und wie Wissen über Verteilungen hinweg übertragen wird. Die zweite Gruppe befasst sich mit Verstärkungslernen durch die Linse theoretischer Werkzeuge wie neuronaler Tangentenkerne, nichteuklidischer Geometrie und Hamilton-Dynamik.
 Xiaolong Wang
Xiaolong Wang
#🎜🎜 # #🎜🎜 #
Xiaolong Wang ist Assistenzprofessorin in der ECE-Abteilung der University of California, San Diego. Er ist Mitglied des Robotikteams am TILOS National Science Foundation Institute for Artificial Intelligence.
Er promovierte in Robotik an der Carnegie Mellon University und forschte als Postdoktorand an der University of California, Berkeley.
Das obige ist der detaillierte Inhalt vonUCSD, MIT und andere chinesische Teams bringen Roboterhunden bei, die 3D-Welt wahrzunehmen! Mit dem M1-Chip können Sie Treppen steigen und Hindernisse überwinden.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
