
 Technologie-Peripheriegeräte
KI
Beim Training großer Models wird auf „Energie' geachtet! Tao Dacheng leitet das Team: Alle Lösungen für „effizientes Training' werden in einem Artikel behandelt. Hören Sie auf zu sagen, dass Hardware der einzige Engpass ist
Technologie-Peripheriegeräte
KI
Beim Training großer Models wird auf „Energie' geachtet! Tao Dacheng leitet das Team: Alle Lösungen für „effizientes Training' werden in einem Artikel behandelt. Hören Sie auf zu sagen, dass Hardware der einzige Engpass ist
Beim Training großer Models wird auf „Energie' geachtet! Tao Dacheng leitet das Team: Alle Lösungen für „effizientes Training' werden in einem Artikel behandelt. Hören Sie auf zu sagen, dass Hardware der einzige Engpass ist

Der Bereich Deep Learning hat erhebliche Fortschritte gemacht, insbesondere in Aspekten wie Computer Vision, Verarbeitung natürlicher Sprache und Sprache. Groß angelegte Modelle, die mithilfe von Big Data trainiert werden, haben enorme Auswirkungen auf praktische Anwendungen, verbessern die industrielle Produktivität und fördern die Aussichten für die soziale Entwicklung .
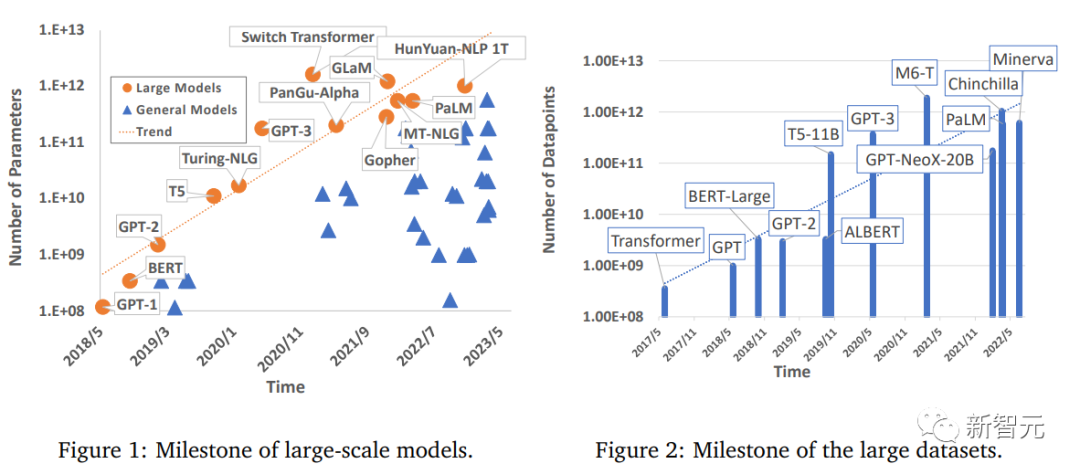
Allerdings erfordern große Modelle auch eine große Rechenleistung, um trainiert zu werden. Da die Anforderungen der Menschen an die Rechenleistung weiter steigen, gibt es zwar viele Studien, die sich mit effizienten Trainingsmethoden befassen, aber es gibt immer noch kein Deep Learning A umfassender Überblick über Modellbeschleunigungstechniken.
Kürzlich haben Forscher der University of Sydney, der University of Science and Technology of China und anderer Institutionen eine Übersicht veröffentlicht, in der effiziente Trainingstechniken für groß angelegte Deep-Learning-Modelle umfassend zusammengefasst und die gemeinsamen Mechanismen innerhalb jeder Komponente des Trainings aufgezeigt werden Verfahren .

Link zum Papier: https://arxiv.org/pdf/2304.03589.pdf
Die Forscher betrachteten die grundlegendste Formel zur Gewichtsaktualisierung und unterteilten ihre Grundkomponenten in fünf Hauptaspekte:
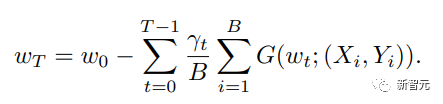
1. Datenzentriert (datenzentriert), einschließlich Datensatz-Regularisierung, Datenstichprobe und datenzentrierter Kurslerntechniken, die die rechnerische Komplexität von Stichproben erheblich reduzieren können; 2,
modellzentriert, einschließlich Beschleunigung von Grundmodulen, Komprimierungstraining, Modellinitialisierung und modellzentrierter Kurslerntechnologie, mit Schwerpunkt auf der Reduzierung von Parametern. Berechnung zur Beschleunigung des Trainings 3 die Auswahl der Lernrate, die Verwendung großer Batch-Größen, das Design effizienter Zielfunktionen, modellgewichteter Durchschnittstechnologie usw.; der Schwerpunkt liegt auf Trainingsstrategien, um die Vielseitigkeit von Großmodellen zu verbessern; Schulung
, einschließlich einiger Beschleunigungstechniken, die bei begrenzter Hardware verwendet werden;5, systemzentriert (systemzentriert)
, einschließlich einiger effizienter verteilter Frameworks und Open-Source-Bibliotheken, die ausreichende Hardwareunterstützung für die Implementierung beschleunigter Algorithmen bieten .Effizientes datenzentriertes Training
In letzter Zeit haben groß angelegte Modelle große Fortschritte gemacht, während ihre Anforderungen an Datensätze dramatisch gestiegen sind. Riesige Datenproben werden verwendet, um den Trainingsprozess voranzutreiben und eine hervorragende Leistung zu erzielen. Daher ist datenzentrierte Forschung für die tatsächliche Beschleunigung von entscheidender Bedeutung.Die Grundfunktion der Datenverarbeitung besteht darin, die Vielfalt der Datenproben effizient zu erhöhen, ohne die Kosten für die Kennzeichnung zu erhöhen. Da die Kosten für die Datenkennzeichnung oft zu hoch sind, können sich einige Entwicklungsinstitutionen diese auch nicht leisten Bedeutung der Forschung in datenzentrierten Bereichen; gleichzeitig konzentriert sich die Datenverarbeitung auch auf die Verbesserung der Effizienz des parallelen Ladens von Datenproben.
Forscher nennen all diese effiziente Datenverarbeitung einen „datenzentrierten“ Ansatz, der die Leistung beim Training groß angelegter Modelle erheblich verbessern kann.In diesem Artikel werden Technologien unter folgenden Aspekten besprochen und untersucht:
Datenregulierung
Datenregulierung ist eine Vorverarbeitungstechnologie, die durch eine Reihe von Datentransformationen verbessert wird kann die äquivalente Darstellung von Trainingsmustern im Merkmalsraum verbessern, ohne dass zusätzliche Beschriftungsinformationen erforderlich sind.
Effiziente Methoden zur Datenregulierung werden häufig im Trainingsprozess eingesetzt und können die Generalisierungsleistung großer Modelle erheblich verbessern. Daten-Sampling: Daten-Sampling ist auch eine effektive Methode, um den Gradienten in kleinen Chargen zu trainieren Die Auswirkungen unwichtiger oder schlechter Proben in der aktuellen Charge können reduziert werden.
Datenzentriertes Lehrplan-Lernen Lehrplan-Lernen untersucht progressive Trainingseinstellungen in verschiedenen Phasen des Trainingsprozesses, um den gesamten Rechenaufwand zu reduzieren. Modellzentriertes effizientes Training Der Entwurf einer effizienten Modellarchitektur ist immer eine der wichtigsten Studien im Bereich Deep Learning. Ein hervorragendes Modell sollte ein effizienter Feature-Extraktor sein, der auf Komponenten auf hoher Ebene projiziert werden kann sind leicht zu trennen. Fast alle Großmodelle bestehen aus kleinen Modulen oder Schichten, sodass die Untersuchung von Modellen als Leitfaden für ein effizientes Training von Großmodellen dienen kann:
Architektur Effizienz Der starke Anstieg der Parameteranzahl in tiefen Modellen bringt auch einen enormen Rechenaufwand mit sich, sodass eine effiziente Alternative implementiert werden muss, um die Leistung der Originalversion der Modellarchitektur anzunähern Die Richtung hat nach und nach auch die Aufmerksamkeit der akademischen Gemeinschaft auf sich gezogen; dieser Ersatz ist nicht nur eine Annäherung an numerische Berechnungen, sondern umfasst auch strukturelle Vereinfachung und Fusion in tiefen Modellen.
Kompressionstrainingseffizienz Kompression war schon immer eine der Forschungsrichtungen in der Rechenbeschleunigung und spielt eine Schlüsselrolle in der digitalen Signalverarbeitung (Multimedia-Computing/Bildverarbeitung).
Initialisierungseffizienz Die Initialisierung von Modellparametern ist ein sehr wichtiger Faktor in bestehenden theoretischen Analysen und tatsächlichen Szenarien.
Modellzentriertes Lehrplanlernen Aus modellzentrierter Sicht beginnt das Kurslernen normalerweise mit dem Training von einem kleinen Modell oder Teilparametern in einem großen Modell und stellt dann nach und nach die gesamte Architektur wieder her, was größere Vorteile bei der Beschleunigung des Trainingsprozesses zeigt Der Artikel untersucht die Implementierung und Effizienz dieser Methode im Trainingsprozess, da sie offensichtlich negative Auswirkungen hat. Das Beschleunigungsschema von Optimierungsmethoden war schon immer eine wichtige Forschungsrichtung im Bereich des maschinellen Lernens. Die Reduzierung der Komplexität bei gleichzeitiger Erzielung optimaler Bedingungen war schon immer das von der akademischen Gemeinschaft verfolgte Ziel. In den letzten Jahren haben effiziente und leistungsstarke Optimierungsmethoden wichtige Durchbrüche beim Training tiefer neuronaler Netze erzielt. Als grundlegender Optimierer, der im maschinellen Lernen weit verbreitet ist, haben tiefe Modelle jedoch erfolgreich dabei geholfen, verschiedene praktische Anwendungen zu erreichen Das Problem wird immer komplexer, der SGD fällt eher in lokale Minima und kann nicht stabil verallgemeinert werden. Um diese Schwierigkeiten zu lösen, wurde vorgeschlagen, dass Adam und seine Varianten Anpassungsfähigkeit in Aktualisierungen einführen. Dieser Ansatz hat bei groß angelegten Netzwerktrainings gute Ergebnisse erzielt, beispielsweise bei BERT-, Transformer- und ViT-Modellen. Neben der Eigenleistung des konzipierten Optimierers ist auch die Kombination beschleunigter Trainingstechniken wichtig. Basierend auf der Perspektive der Optimierung fassten Forscher die aktuellen Überlegungen zum beschleunigten Training in die folgenden Aspekte zusammen: Lernrate Lernrate Die Lernrate ist ein wichtiger Faktor bei nicht-konvexen Optimierung Hyperparameter sind auch im aktuellen Deep-Network-Training von entscheidender Bedeutung, und adaptive Methoden wie Adam und seine Varianten haben erfolgreich bemerkenswerte Fortschritte bei Deep-Modellen erzielt. Einige Strategien zur Anpassung der Lernrate basierend auf Gradienten höherer Ordnung erzielen auch effektiv ein beschleunigtes Training, und die Implementierung einer Lernratenabschwächung wirkt sich auch auf die Leistung während des Trainingsprozesses aus. Große Batchgröße Die Verwendung einer größeren Batchgröße verbessert effektiv die Trainingseffizienz und kann die Anzahl der zum Abschließen eines Epochentrainings erforderlichen Iterationen direkt reduzieren; in diesem Fall ist die Gesamtstichprobengröße festgelegt Die Verarbeitung einer größeren Chargengröße ist kostengünstiger als die Verarbeitung mehrerer Proben in kleineren Chargengrößen, da die Speichernutzung verbessert und Kommunikationsengpässe reduziert werden können. Effiziente Zielsetzung Das grundlegendste ERM spielt eine Schlüsselrolle bei der Minimierung von Problemen und macht viele Aufgaben praktisch. Mit der Vertiefung der Forschung zu großen Netzwerken widmen einige Arbeiten der Lücke zwischen Optimierung und Generalisierung mehr Aufmerksamkeit und schlagen wirksame Ziele vor, um Testfehler aus verschiedenen Perspektiven zu reduzieren und die gemeinsame Optimierung des Trainings zu verbessern Sie können die Genauigkeit des Tests erheblich beschleunigen. Gemittelte Gewichtungen Der gewichtete Durchschnitt ist eine praktische Technik, die die Allgemeingültigkeit des Modells verbessern kann, da ein gewichteter Durchschnitt historischer Zustände berücksichtigt wird, mit einem Satz eingefrorener oder erlernbarer Koeffizienten, die dies können Beschleunigen Sie den Trainingsprozess erheblich. Mehrere aktuelle Bemühungen haben sich darauf konzentriert, Deep-Learning-Modelle mit weniger Ressourcen zu trainieren und eine möglichst hohe Genauigkeit zu erreichen. Diese Art von Problem wird als budgetiertes Training definiert, d. h. als Training unter einem bestimmten Budget (einer Grenze messbarer Kosten), um die höchste Modellleistung zu erzielen. Um die Hardwareunterstützung systematisch zu berücksichtigen und näher an die reale Situation heranzukommen, definierten die Forscher Budgettraining als Training auf einem bestimmten Gerät und mit begrenzter Zeit, zum Beispiel das Training auf einem einzelnen Low-End-Deep-Learning Servertag, um das Modell mit der besten Leistung zu erhalten. Effizientes Lernen mit Fokus auf Optimierung
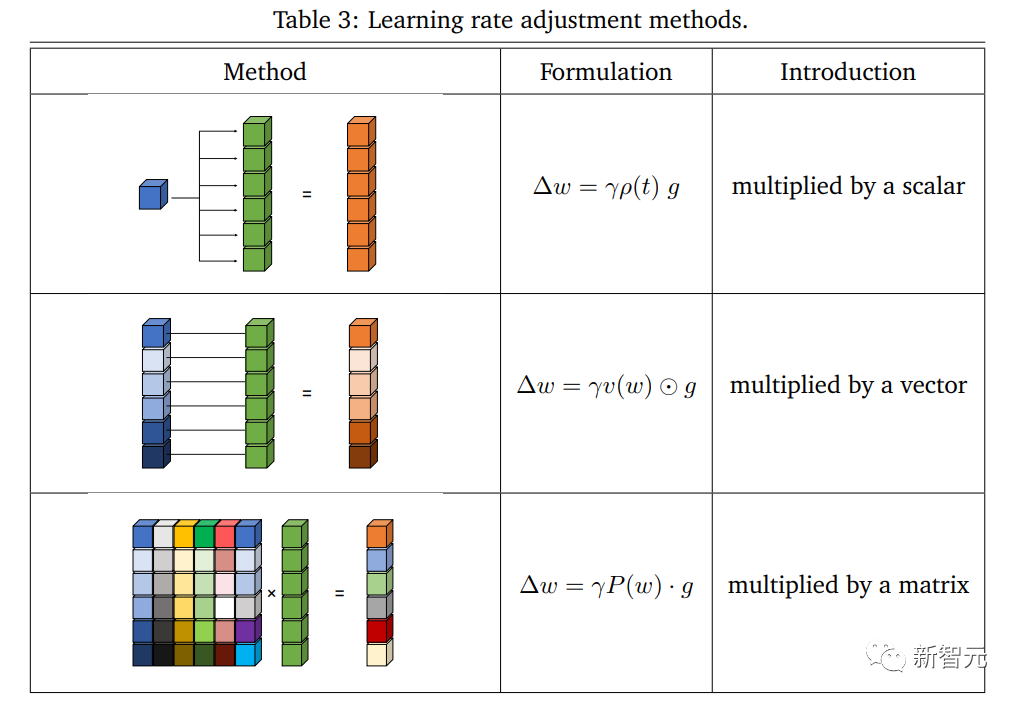
Budgetbasiertes und effizientes Training
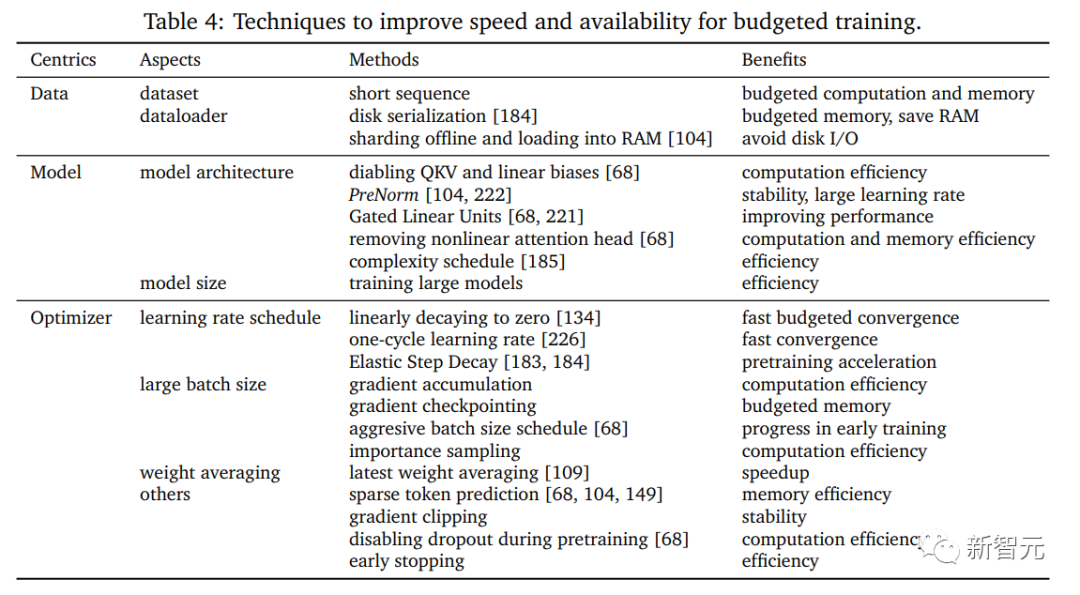
Eine Studie über Schulungen mit kleinem Budget kann Aufschluss darüber geben, wie man etwas schafft Ein Training mit kleinem Budget. Trainingsrezepte, einschließlich der Bestimmung der Konfiguration der Modellgröße, der Modellstruktur, des Lernratenplans und mehrerer anderer einstellbarer Faktoren, die sich auf die Leistung auswirken, sowie die Kombination effizienter Trainingstechniken, die für das verfügbare Budget geeignet sind. In diesem Artikel werden hauptsächlich einige fortgeschrittene Techniken besprochen Techniken für das Budgettraining.
Systemzentriertes effizientes TrainingSystemzentrierte Forschung besteht darin, spezifische Implementierungsmethoden für die entworfenen Algorithmen bereitzustellen, und Forschung ist erforderlich die effektive und praktische Ausführung von Hardware, die wirklich ein effizientes Training ermöglichen kann.
Forscher konzentrieren sich auf die Implementierung von Allzweck-Computergeräten, wie CPU- und GPU-Geräten in Clustern mit mehreren Knoten, und auf die Lösung potenzieller Konflikte bei Entwurfsalgorithmen einer Hardware Perspektive ist ein Anliegen Kern.
In diesem Artikel werden hauptsächlich die Hardware-Implementierungstechnologien in vorhandenen Frameworks und Bibliotheken von Drittanbietern untersucht. Diese Technologien unterstützen effektiv die Datenverarbeitung, Modelle und Optimierung und stellen einige vor Die bestehende Open-Source-Plattform bietet einen soliden Rahmen für die Modellerstellung, die effektive Nutzung von Daten für das Training, das gemischte Präzisionstraining und das verteilte Training.
Systemzentrierte Dateneffizienz
#🎜 🎜## 🎜🎜#Effiziente Datenverarbeitung und Datenparallelität sind zwei wichtige Anliegen bei der Systemimplementierung.
Mit dem rasanten Anstieg des Datenvolumens ist ineffiziente Datenverarbeitung nach und nach zu einem Engpass für die Trainingseffizienz geworden, insbesondere bei groß angelegtem Training auf mehreren Knoten, und immer mehr Designs sind es Durch Hardware-freundliche Rechenmethoden und Parallelisierung kann effektiv Zeitverschwendung beim Training vermieden werden.
Systemzentrierte Modelleffizienz
#🎜 🎜#Mit der schnellen Expansion von Aufgrund der Anzahl der Modellparameter ist die Systemeffizienz aus Sicht des Modells zu einem wichtigen Engpass geworden. Die Speicher- und Recheneffizienz großer Modelle hat die Hardware-Implementierung vor große Herausforderungen gestellt.In diesem Artikel wird hauptsächlich untersucht, wie eine effiziente E/A der Bereitstellung und eine optimierte Implementierung der Modellparallelität erreicht werden können, um das eigentliche Training zu beschleunigen.
Systemzentrierte Optimierungseffizienz#🎜 🎜#Der Optimierungsprozess repräsentiert die Backpropagation und Aktualisierung in jeder Iteration sind auch die zeitaufwändigsten Berechnungen im Training. Daher bestimmt die Implementierung der systemzentrierten Optimierung direkt die Effizienz des Trainings.
Um die Merkmale der Systemoptimierung klar zu interpretieren, konzentriert sich der Artikel auf die Effizienz verschiedener Berechnungsstufen und überprüft die Verbesserungen jedes Prozesses.
Open Source Frameworks# 🎜 🎜 #Effiziente Open-Source-Frameworks können das Training erleichtern. Als Brücke zwischen Grafting-Algorithmus-Design und Hardware-Unterstützung untersuchten die Forscher eine Reihe von Open-Source-Frameworks und analysierten die Vor- und Nachteile jedes Designs.
Schlussfolgerung
Der Artikel schlägt außerdem eine neuartige Taxonomie vor, die diese Technologien in fünf Hauptrichtungen zusammenfasst: datenzentriert, modellzentriert, optimierungszentriert, Budgettraining und systemzentriert.
Die ersten vier Teile führen hauptsächlich umfassende Forschung aus der Perspektive des Algorithmusdesigns und der Methodik durch, während im Teil „Systemzentriertes effizientes Training“ die eigentliche Umsetzung aus der Perspektive der Paradigmeninnovation und Hardwareunterstützung zusammengefasst wird.
Der Artikel bespricht und fasst häufig verwendete oder neu entwickelte Technologien für jeden Teil sowie die Vorteile und Kompromisse jeder Technologie zusammen und erörtert Einschränkungen und vielversprechende zukünftige Forschungsrichtungen, bevor er einen umfassenden technischen Überblick gibt und gleichzeitig Anleitungen gibt. In dieser Überprüfung werden auch die aktuellen Durchbrüche und Engpässe bei der effizienten Ausbildung dargelegt.
Die Forscher hoffen, den Forschern dabei zu helfen, eine allgemeine Trainingsbeschleunigung zu erreichen und zusätzlich zu einigen potenziellen Fortschritten, die am Ende jedes Abschnitts erwähnt werden, einige sinnvolle und vielversprechende Auswirkungen zu erzielen vielversprechende Gesichtspunkte sind wie folgt:
1. Effiziente Profilsuche
Effizientes Training kann aus den Perspektiven der Datenverbesserungskombination, Modellstruktur, Optimiererdesign usw. beginnen, um Modellen einige Fortschritte zu ermöglichen wurde bei der Entwicklung vorgefertigter und anpassbarer Profilsuchstrategien durchgeführt.
Neue Modellarchitekturen und Komprimierungsmodi, neue Aufgaben vor dem Training und die Nutzung von „Model-Edge“-Wissen sind ebenfalls eine Erkundung wert.
2. Mit einem auf die Optimierung des Kurses, der Lernrate und der Stapelgröße sowie der Modellkomplexität ausgerichteten Planer ist es möglich, eine bessere Leistung zu erzielen Der Scheduler kann sich dynamisch an das verbleibende Budget anpassen und so die Kosten für den manuellen Entwurf reduzieren. Mit dem adaptiven Scheduler können Parallelität und Kommunikationsmethoden untersucht und gleichzeitig allgemeinere und praktischere Situationen berücksichtigt werden, z. B. wenn mehrere Regionen und Daten in großem Maßstab dezentralisiert werden Ausbildung in einem zentralisierten heterogenen Netzwerk.
Das obige ist der detaillierte Inhalt vonBeim Training großer Models wird auf „Energie' geachtet! Tao Dacheng leitet das Team: Alle Lösungen für „effizientes Training' werden in einem Artikel behandelt. Hören Sie auf zu sagen, dass Hardware der einzige Engpass ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
