

Analyse von Standortkonfigurationsbeispielen im Nginx-Server

的 Lassen Sie mich zunächst die Typen und Zuordnungsregeln von Standorten vorstellen. Am Beispiel von Nginx Wiki wird Folgendes erläutert:
location = / {
# matches the query / only.
[ configuration a ]
}
location / {
# matches any query, since all queries begin with /, but regular
# expressions and any longer conventional blocks will be
# matched first.
[ configuration b ]
}
location ^~ /images/ {
# matches any query beginning with /images/ and halts searching,
# so regular expressions will not be checked.
[ configuration c ]
}
location ~* \.(gif|jpg|jpeg)$ {
# matches any request ending in gif, jpg, or jpeg. however, all
# requests to the /images/ directory will be handled by
# configuration c.
[ configuration d ]
}
location @named {
# such locations are not used during normal processing of requests,
# they are intended only to process internally redirected requests (for example error_page, try_files).
[ configuration e ]
}3, regulärer Abgleich, die Abgleichsreihenfolge ist die Reihenfolge, in der Standorte in der Konfigurationsdatei erscheinen. Wenn ein regulärer Standort übereinstimmt, stoppen Sie und verwenden Sie die Konfiguration dieses Standorts. Andernfalls verwenden Sie die Standortkonfiguration mit der größten Zeichenfolgenübereinstimmung, die Sie in Schritt 2 erhalten haben. Wenn wir den zweiten Standort erreichen, führen wir einen regulären Abgleich durch, daher verwenden wir die Konfiguration des zweiten Standorts: Konfigurationb
3, /images /1.jpg -> Der String stimmt mit dem zweiten Speicherort überein, aber dann wird auch mit dem Präfix des dritten Speicherorts übereinstimmt, und zu diesem Zeitpunkt ist dies die maximale Zeichenfolgenübereinstimmung für diese URL in der Konfigurationsdatei, und der Speicherort hat das Präfix „^~“ und dann das reguläre Der Abgleich wird nicht mehr durchgeführt und die Konfiguration wird schließlich verwendet. c
4,/some/other/path/to/1.jpg -> Zuerst stimmt die gleiche Zeichenfolge im Präfixteil mit der zweiten Position überein, und dann erfolgt der reguläre Abgleich Wenn der reguläre Abgleich erfolgreich ist, wird die Konfiguration d
verwendet. Die URL-Abgleichsregeln sind in den meisten Fällen jedoch etwas ungeeignet Der Abgleich erfolgt zuerst. Wenn es keine Übereinstimmung gibt, wird dann der Zeichenfolgenabgleich durchgeführt. In vielen Fällen kann dies Zeit beim Zeichenfolgenabgleich sparen. Schauen wir uns auf jeden Fall die Implementierung im Nginx-Quellcode an. Bevor wir den Matching-Location-Prozess einführen, stellen wir zunächst die Organisation des Locations in Nginx vor. Tatsächlich stimmt Nginx während der Konfigurationsanalyse mit dem String-Matching-Location überein mit dem regulären übereinstimmenden Speicherort. Der Speicherort wird in den folgenden zwei Feldern der ngx_http_core_loc_conf_t-Struktur der loc-Konfiguration des http-Kernmoduls gespeichert:
ngx_http_location_tree_node_t *static_locations; (ngx_pcre) ngx_http_core_loc_conf_t **regex_locations; if
Aus den Typen dieser beiden Felder ist ersichtlich, dass die Speicherorte durch Zeichenfolgen übereinstimmen werden in einem Standortbaum organisiert und die Standorte werden durch reguläre Ausdrücke abgeglichen. Es ist nur ein Array,
location tree和regex_locations数组建立过程在ngx_http_block中:
/* create location trees */
for (s = 0; s < cmcf->servers.nelts; s++) {
clcf = cscfp[s]->ctx->loc_conf[ngx_http_core_module.ctx_index];
if (ngx_http_init_locations(cf, cscfp[s], clcf) != ngx_ok) {
return ngx_conf_error;
}
if (ngx_http_init_static_location_trees(cf, clcf) != ngx_ok) {
return ngx_conf_error;
}
}Nach dem Lesen der Konfiguration werden alle Server im Server-Array in der Hauptkonfiguration des http-Kernmoduls gespeichert, und die Standorte in jedem Server werden in der Reihenfolge, in der sie in der Konfiguration erscheinen, in http gespeichert. In der Standortwarteschlange der LOC-Konfiguration des CORE-Moduls wird der obige Code zunächst nach dem Standort jedes Servers sortiert und klassifiziert. Dieser Schritt erfolgt in der Funktion ngx_http_init_location ().
Rreeee
Die oben genannten Schritte entsprechen dem regulären Standort. Nach dem Speichern wird der Standortbaum in ngx_http_init_static_location_trees erstellt:
static ngx_int_t
ngx_http_init_locations(ngx_conf_t *cf, ngx_http_core_srv_conf_t *cscf,
ngx_http_core_loc_conf_t *pclcf)
{
...
locations = pclcf->locations;
...
/* 按照类型排序location,排序完后的队列: (exact_match 或 inclusive) (排序好的,如果某个exact_match名字和inclusive location相同,exact_match排在前面)
| regex(未排序)| named(排序好的) | noname(未排序)*/
ngx_queue_sort(locations, ngx_http_cmp_locations);
named = null;
n = 0;
#if (ngx_pcre)
regex = null;
r = 0;
#endif
for (q = ngx_queue_head(locations);
q != ngx_queue_sentinel(locations);
q = ngx_queue_next(q))
{
lq = (ngx_http_location_queue_t *) q;
clcf = lq->exact ? lq->exact : lq->inclusive;
/* 由于可能存在nested location,也就是location里面嵌套的location,这里需要递归的处理一下当前location下面的nested location */
if (ngx_http_init_locations(cf, null, clcf) != ngx_ok) {
return ngx_error;
}
#if (ngx_pcre)
if (clcf->regex) {
r++;
if (regex == null) {
regex = q;
}
continue;
}
#endif
if (clcf->named) {
n++;
if (named == null) {
named = q;
}
continue;
}
if (clcf->noname) {
break;
}
}
if (q != ngx_queue_sentinel(locations)) {
ngx_queue_split(locations, q, &tail);
}
/* 如果有named location,将它们保存在所属server的named_locations数组中 */
if (named) {
clcfp = ngx_palloc(cf->pool,
(n + 1) * sizeof(ngx_http_core_loc_conf_t **));
if (clcfp == null) {
return ngx_error;
}
cscf->named_locations = clcfp;
for (q = named;
q != ngx_queue_sentinel(locations);
q = ngx_queue_next(q))
{
lq = (ngx_http_location_queue_t *) q;
*(clcfp++) = lq->exact;
}
*clcfp = null;
ngx_queue_split(locations, named, &tail);
}
#if (ngx_pcre)
/* 如果有正则匹配location,将它们保存在所属server的http core模块的loc配置的regex_locations 数组中,
这里和named location保存位置不同的原因是由于named location只能存在server里面,而regex location可以作为nested location */
if (regex) {
clcfp = ngx_palloc(cf->pool,
(r + 1) * sizeof(ngx_http_core_loc_conf_t **));
if (clcfp == null) {
return ngx_error;
}
pclcf->regex_locations = clcfp;
for (q = regex;
q != ngx_queue_sentinel(locations);
q = ngx_queue_next(q))
{
lq = (ngx_http_location_queue_t *) q;
*(clcfp++) = lq->exact;
}
*clcfp = null;
ngx_queue_split(locations, regex, &tail);
}
#endif
return ngx_ok;
} Nach der Verarbeitung durch die Funktion ngx_http_init_location() ist die Standortwarteschlange bereits in Ordnung Der Prozess zum Erstellen des Ternärbaums ist in ngx_http_create_locations_list() und ngx_http_create_locations_tree abgeschlossen. Diese beiden Funktionen sind beide rekursive Funktionen. Die erste Funktion rekursiviert jeden Knoten in der Standortwarteschlange und ruft den Standort ab, dem der Name des aktuellen Knotens vorangestellt ist. und speichert es unter dem Listenfeld des aktuellen Knotens, zum Beispiel für die folgenden Orte:
static ngx_int_t
ngx_http_init_static_location_trees(ngx_conf_t *cf,
ngx_http_core_loc_conf_t *pclcf)
{
ngx_queue_t *q, *locations;
ngx_http_core_loc_conf_t *clcf;
ngx_http_location_queue_t *lq;
locations = pclcf->locations;
if (locations == null) {
return ngx_ok;
}
if (ngx_queue_empty(locations)) {
return ngx_ok;
}
/* 这里也是由于nested location,需要递归一下 */
for (q = ngx_queue_head(locations);
q != ngx_queue_sentinel(locations);
q = ngx_queue_next(q))
{
lq = (ngx_http_location_queue_t *) q;
clcf = lq->exact ? lq->exact : lq->inclusive;
if (ngx_http_init_static_location_trees(cf, clcf) != ngx_ok) {
return ngx_error;
}
}
/* join队列中名字相同的inclusive和exact类型location,也就是如果某个exact_match的location名字和普通字符串匹配的location名字相同的话,
就将它们合到一个节点中,分别保存在节点的exact和inclusive下,这一步的目的实际是去重,为后面的建立排序树做准备 */
if (ngx_http_join_exact_locations(cf, locations) != ngx_ok) {
return ngx_error;
}
/* 递归每个location节点,得到当前节点的名字为其前缀的location的列表,保存在当前节点的list字段下 */
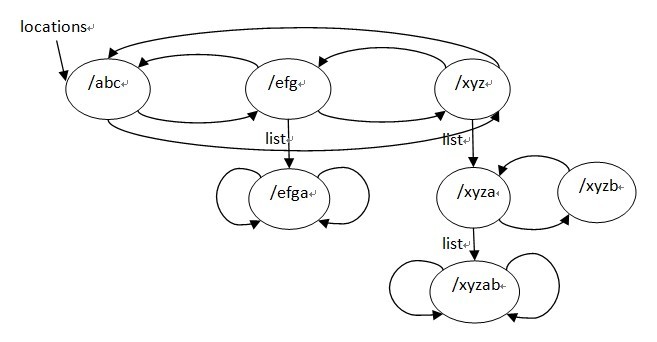
ngx_http_create_locations_list(locations, ngx_queue_head(locations));
/* 递归建立location三叉排序树 */
pclcf->static_locations = ngx_http_create_locations_tree(cf, locations, 0);
if (pclcf->static_locations == null) {
return ngx_error;
}
return ngx_ok;
}
static ngx_http_location_tree_node_t *
ngx_http_create_locations_tree(ngx_conf_t *cf, ngx_queue_t *locations,
size_t prefix)
{
...
/* 根节点为locations队列的中间节点 */
q = ngx_queue_middle(locations);
lq = (ngx_http_location_queue_t *) q;
len = lq->name->len - prefix;
node = ngx_palloc(cf->pool,
offsetof(ngx_http_location_tree_node_t, name) + len);
if (node == null) {
return null;
}
node->left = null;
node->right = null;
node->tree = null;
node->exact = lq->exact;
node->inclusive = lq->inclusive;
node->auto_redirect = (u_char) ((lq->exact && lq->exact->auto_redirect)
|| (lq->inclusive && lq->inclusive->auto_redirect));
node->len = (u_char) len;
ngx_memcpy(node->name, &lq->name->data[prefix], len);
/* 从中间节点开始断开 */
ngx_queue_split(locations, q, &tail);
if (ngx_queue_empty(locations)) {
/*
* ngx_queue_split() insures that if left part is empty,
* then right one is empty too
*/
goto inclusive;
}
/* 从locations左半部分得到左子树 */
node->left = ngx_http_create_locations_tree(cf, locations, prefix);
if (node->left == null) {
return null;
}
ngx_queue_remove(q);
if (ngx_queue_empty(&tail)) {
goto inclusive;
}
/* 从locations右半部分得到右子树 */
node->right = ngx_http_create_locations_tree(cf, &tail, prefix);
if (node->right == null) {
return null;
}
inclusive:
if (ngx_queue_empty(&lq->list)) {
return node;
}
/* 从list队列得到tree子树 */
node->tree = ngx_http_create_locations_tree(cf, &lq->list, prefix + len);
if (node->tree == null) {
return null;
}
return node;
}
location tree节点的ngx_http_location_tree_node_s结构:
struct ngx_http_location_tree_node_s {
ngx_http_location_tree_node_t *left;
ngx_http_location_tree_node_t *right;
ngx_http_location_tree_node_t *tree;
ngx_http_core_loc_conf_t *exact;
ngx_http_core_loc_conf_t *inclusive;
u_char auto_redirect;
u_char len;
u_char name[1];
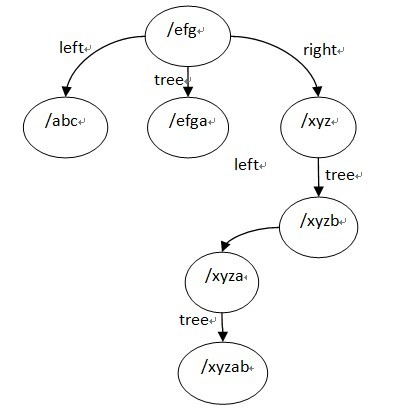
}; location tree结构用到的是left,right,tree 这3个字段, location tree实际上是一个三叉的字符串排序树,而且这里如果某个节点只考虑左,右子树,它是一颗平衡树,它的建立过程有点类似于一颗平衡排序二叉树的建立过程,先排序再用二分查找找到的节点顺序插入,ngx_http_location_tree_node_s的tree节点也是一颗平衡排序树,它是用该节点由ngx_http_create_locations_list()得到的list建立的,也就是该节点的名字是它的tree子树里面的所有节点名字的前缀,所以tree子树里面的所有节点的名字不用保存公共前缀,而且查找的时候,如果是转向tree节点的话,也是不需要再比较父节点的那段字符串了。
ngx_http_create_locations_tree()函数写的很清晰,它有一个参数是队列locations,它返回一颗三叉树,根节点为locations的中间节点,其左子树为locations队列的左半部分建立的location tree,右子树为location队列的右半部分建立的tree,tree节点为该根节点的list队列建立的tree。
最终建立的location tree如下(为了方便阅读,图中列出了tree节点的完整名字):
ps:关于 location modifier
1. =
这会完全匹配指定的 pattern ,且这里的 pattern 被限制成简单的字符串,也就是说这里不能使用正则表达式。
example:
server {
server_name jb51.net;
location = /abcd {
[…]
}
}匹配情况:
http://jb51.net/abcd # 正好完全匹配 http://jb51.net/abcd # 如果运行 nginx server 的系统本身对大小写不敏感,比如 windows ,那么也匹配 http://jb51.net/abcd?param1¶m2 # 忽略查询串参数(query string arguments),这里就是 /abcd 后面的 ?param1¶m2 http://jb51.net/abcd/ # 不匹配,因为末尾存在反斜杠(trailing slash),nginx 不认为这种情况是完全匹配 http://jb51.net/abcde # 不匹配,因为不是完全匹配
2. (none)
可以不写 location modifier ,nginx 仍然能去匹配 pattern 。这种情况下,匹配那些以指定的 patern 开头的 uri,注意这里的 uri 只能是普通字符串,不能使用正则表达式。
example:
server {
server_name jb51.net;
location /abcd {
[…]
}
}匹配情况:
http://jb51.net/abcd # 正好完全匹配 http://jb51.net/abcd # 如果运行 nginx server 的系统本身对大小写不敏感,比如 windows ,那么也匹配 http://jb51.net/abcd?param1¶m2 # 忽略查询串参数(query string arguments),这里就是 /abcd 后面的 ?param1¶m2 http://jb51.net/abcd/ # 末尾存在反斜杠(trailing slash)也属于匹配范围内 http://jb51.net/abcde # 仍然匹配,因为 uri 是以 pattern 开头的
3. ~
这个 location modifier 对大小写敏感,且 pattern 须是正则表达式
example:
server {
server_name jb51.net;
location ~ ^/abcd$ {
[…]
}
}匹配情况:
http://jb51.net/abcd # 完全匹配 http://jb51.net/abcd # 不匹配,~ 对大小写是敏感的 http://jb51.net/abcd?param1¶m2 # 忽略查询串参数(query string arguments),这里就是 /abcd 后面的 ?param1¶m2 http://jb51.net/abcd/ # 不匹配,因为末尾存在反斜杠(trailing slash),并不匹配正则表达式 ^/abcd$ http://jb51.net/abcde # 不匹配正则表达式 ^/abcd$
注意:对于一些对大小写不敏感的系统,比如 windows ,~ 和 ~* 都是不起作用的,这主要是操作系统的原因。
4. ~*
与 ~ 类似,但这个 location modifier 不区分大小写,pattern 须是正则表达式
example:
server {
server_name jb51.net;
location ~* ^/abcd$ {
[…]
}
}匹配情况:
http://jb51.net/abcd # 完全匹配 http://jb51.net/abcd # 匹配,这就是它不区分大小写的特性 http://jb51.net/abcd?param1¶m2 # 忽略查询串参数(query string arguments),这里就是 /abcd 后面的 ?param1¶m2 http://jb51.net/abcd/ # 不匹配,因为末尾存在反斜杠(trailing slash),并不匹配正则表达式 ^/abcd$ http://jb51.net/abcde # 不匹配正则表达式 ^/abcd$
5. ^~
匹配情况类似 2. (none) 的情况,以指定匹配模式开头的 uri 被匹配,不同的是,一旦匹配成功,那么 nginx 就停止去寻找其他的 location 块进行匹配了(与 location 匹配顺序有关)
6. @
用于定义一个 location 块,且该块不能被外部 client 所访问,只能被 nginx 内部配置指令所访问,比如 try_files or error_page
Das obige ist der detaillierte Inhalt vonAnalyse von Standortkonfigurationsbeispielen im Nginx-Server. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 So erlauben Sie den externen Netzwerkzugriff auf den Tomcat-Server
Apr 21, 2024 am 07:22 AM
So erlauben Sie den externen Netzwerkzugriff auf den Tomcat-Server
Apr 21, 2024 am 07:22 AM
Um dem Tomcat-Server den Zugriff auf das externe Netzwerk zu ermöglichen, müssen Sie Folgendes tun: Ändern Sie die Tomcat-Konfigurationsdatei, um externe Verbindungen zuzulassen. Fügen Sie eine Firewallregel hinzu, um den Zugriff auf den Tomcat-Server-Port zu ermöglichen. Erstellen Sie einen DNS-Eintrag, der den Domänennamen auf die öffentliche IP des Tomcat-Servers verweist. Optional: Verwenden Sie einen Reverse-Proxy, um Sicherheit und Leistung zu verbessern. Optional: Richten Sie HTTPS für mehr Sicherheit ein.
 So führen Sie thinkphp aus
Apr 09, 2024 pm 05:39 PM
So führen Sie thinkphp aus
Apr 09, 2024 pm 05:39 PM
Schritte zum lokalen Ausführen von ThinkPHP Framework: Laden Sie ThinkPHP Framework herunter und entpacken Sie es in ein lokales Verzeichnis. Erstellen Sie einen virtuellen Host (optional), der auf das ThinkPHP-Stammverzeichnis verweist. Konfigurieren Sie Datenbankverbindungsparameter. Starten Sie den Webserver. Initialisieren Sie die ThinkPHP-Anwendung. Greifen Sie auf die URL der ThinkPHP-Anwendung zu und führen Sie sie aus.
 Willkommen bei Nginx! Wie kann ich es lösen?
Apr 17, 2024 am 05:12 AM
Willkommen bei Nginx! Wie kann ich es lösen?
Apr 17, 2024 am 05:12 AM
Um den Fehler „Willkommen bei Nginx!“ zu beheben, müssen Sie die Konfiguration des virtuellen Hosts überprüfen, den virtuellen Host aktivieren, Nginx neu laden. Wenn die Konfigurationsdatei des virtuellen Hosts nicht gefunden werden kann, erstellen Sie eine Standardseite und laden Sie Nginx neu. Anschließend wird die Fehlermeldung angezeigt verschwindet und die Website wird normal angezeigt.
 So kommunizieren Sie zwischen Docker-Containern
Apr 07, 2024 pm 06:24 PM
So kommunizieren Sie zwischen Docker-Containern
Apr 07, 2024 pm 06:24 PM
In der Docker-Umgebung gibt es fünf Methoden für die Containerkommunikation: freigegebenes Netzwerk, Docker Compose, Netzwerk-Proxy, freigegebenes Volume und Nachrichtenwarteschlange. Wählen Sie abhängig von Ihren Isolations- und Sicherheitsanforderungen die am besten geeignete Kommunikationsmethode, z. B. die Nutzung von Docker Compose zur Vereinfachung von Verbindungen oder die Verwendung eines Netzwerk-Proxys zur Erhöhung der Isolation.
 So generieren Sie eine URL aus einer HTML-Datei
Apr 21, 2024 pm 12:57 PM
So generieren Sie eine URL aus einer HTML-Datei
Apr 21, 2024 pm 12:57 PM
Für die Konvertierung einer HTML-Datei in eine URL ist ein Webserver erforderlich. Dazu sind die folgenden Schritte erforderlich: Besorgen Sie sich einen Webserver. Richten Sie einen Webserver ein. Laden Sie eine HTML-Datei hoch. Erstellen Sie einen Domainnamen. Leiten Sie die Anfrage weiter.
 So stellen Sie das NodeJS-Projekt auf dem Server bereit
Apr 21, 2024 am 04:40 AM
So stellen Sie das NodeJS-Projekt auf dem Server bereit
Apr 21, 2024 am 04:40 AM
Serverbereitstellungsschritte für ein Node.js-Projekt: Bereiten Sie die Bereitstellungsumgebung vor: Erhalten Sie Serverzugriff, installieren Sie Node.js, richten Sie ein Git-Repository ein. Erstellen Sie die Anwendung: Verwenden Sie npm run build, um bereitstellbaren Code und Abhängigkeiten zu generieren. Code auf den Server hochladen: über Git oder File Transfer Protocol. Abhängigkeiten installieren: Stellen Sie eine SSH-Verbindung zum Server her und installieren Sie Anwendungsabhängigkeiten mit npm install. Starten Sie die Anwendung: Verwenden Sie einen Befehl wie node index.js, um die Anwendung zu starten, oder verwenden Sie einen Prozessmanager wie pm2. Konfigurieren Sie einen Reverse-Proxy (optional): Verwenden Sie einen Reverse-Proxy wie Nginx oder Apache, um den Datenverkehr an Ihre Anwendung weiterzuleiten
 Was sind die häufigsten Anweisungen in einer Docker-Datei?
Apr 07, 2024 pm 07:21 PM
Was sind die häufigsten Anweisungen in einer Docker-Datei?
Apr 07, 2024 pm 07:21 PM
Die am häufigsten verwendeten Anweisungen in Dockerfile sind: FROM: Neues Image erstellen oder neues Image ableiten RUN: Befehle ausführen (Software installieren, System konfigurieren) COPY: Lokale Dateien in das Image kopieren ADD: Ähnlich wie COPY kann es automatisch dekomprimiert werden tar-Archive oder URL-Dateien abrufen CMD: Geben Sie den Befehl an, wenn der Container gestartet wird. EXPOSE: Deklarieren Sie den Container-Überwachungsport (aber nicht öffentlich). ENV: Legen Sie die Umgebungsvariable fest. VOLUME: Mounten Sie das Hostverzeichnis oder das anonyme Volume. WORKDIR: Legen Sie das Arbeitsverzeichnis im fest Container ENTRYPOINT: Geben Sie an, was beim Start des Containers ausgeführt werden soll. Ausführbare Datei (ähnlich wie CMD, kann aber nicht überschrieben werden)
 Kann von außen auf Nodejs zugegriffen werden?
Apr 21, 2024 am 04:43 AM
Kann von außen auf Nodejs zugegriffen werden?
Apr 21, 2024 am 04:43 AM
Ja, auf Node.js kann von außen zugegriffen werden. Sie können die folgenden Methoden verwenden: Verwenden Sie Cloud Functions, um die Funktion bereitzustellen und öffentlich zugänglich zu machen. Verwenden Sie das Express-Framework, um Routen zu erstellen und Endpunkte zu definieren. Verwenden Sie Nginx, um Proxy-Anfragen an Node.js-Anwendungen umzukehren. Verwenden Sie Docker-Container, um Node.js-Anwendungen auszuführen und sie über Port-Mapping verfügbar zu machen.
