
 Technologie-Peripheriegeräte
KI
Kombinieren Sie regelbasierte und maschinelle Lernansätze, um leistungsstarke Hybridsysteme aufzubauen
Technologie-Peripheriegeräte
KI
Kombinieren Sie regelbasierte und maschinelle Lernansätze, um leistungsstarke Hybridsysteme aufzubauen
Kombinieren Sie regelbasierte und maschinelle Lernansätze, um leistungsstarke Hybridsysteme aufzubauen

Nach all den Jahren sind wir alle davon überzeugt, dass ML fast überall, wenn nicht sogar besser, zumindest mit Vor-ML-Lösungen mithalten kann. Beispielsweise werden wir alle bei einigen Regelbeschränkungen darüber nachdenken, ob sie durch ein baumbasiertes ML-Modell ersetzt werden können. Aber die Welt ist nicht immer schwarz und weiß, und obwohl maschinelles Lernen sicherlich seinen Platz bei der Lösung von Problemen hat, ist es nicht immer die beste Lösung. Regelbasierte Systeme können maschinelles Lernen sogar übertreffen, insbesondere in Bereichen, in denen Erklärbarkeit, Robustheit und Transparenz von entscheidender Bedeutung sind.
In diesem Artikel werde ich einige praktische Fälle vorstellen und wie die Kombination manueller Regeln und ML unsere Lösung verbessert.
Regelbasiertes System
Ein regelbasiertes System unterstützt die Entscheidungsfindung durch vordefinierte Regeln. Das System wertet Daten basierend auf gespeicherten Regeln aus und führt spezifische Operationen basierend auf Zuordnungen aus.
Hier ein paar Beispiele:
Betrugserkennung: Bei der Betrugserkennung können regelbasierte Systeme eingesetzt werden, um verdächtige Transaktionen anhand vordefinierter Regeln schnell zu erkennen und zu untersuchen.
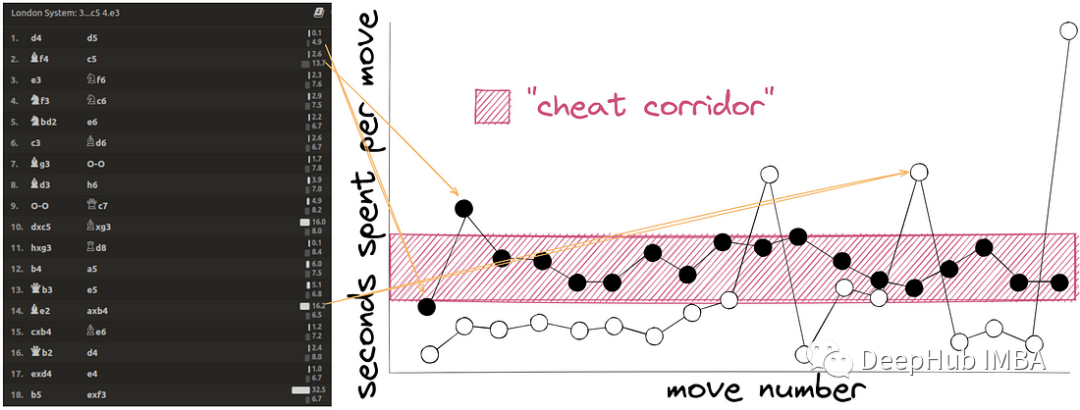
Bei Schach-Cheats besteht die grundlegende Methode darin, eine Computer-Schachanwendung in einem anderen Fenster zu installieren und das Programm zum Schachspielen zu verwenden. Egal wie komplex das Programm ist, es dauert 4-5 Sekunden. Daher wird ein „Schwellenwert“ hinzugefügt, um die Zeit jedes Schritts des Spielers zu berechnen. Wenn die Fluktuation nicht groß ist, kann er als Betrüger eingestuft werden, wie in der folgenden Abbildung dargestellt:
Gesundheitsbranche : Mit regelbasierten Systemen lassen sich Rezepte verwalten und Medikationsfehler verhindern. Sie können auch sehr nützlich sein, um Ärzten dabei zu helfen, Patienten auf der Grundlage früherer Ergebnisse zusätzliche Analysen zu verschreiben.
Supply Chain Management: Im Supply Chain Management können regelbasierte Systeme verwendet werden, um Warnungen bei niedrigen Lagerbeständen zu generieren und bei der Verwaltung von Ablaufdaten oder bei der Einführung neuer Produkte zu helfen.
Auf maschinellem Lernen basierende Systeme
Systeme auf maschinellem Lernen (ML) nutzen Algorithmen, um aus Daten zu lernen und Vorhersagen zu treffen oder Maßnahmen zu ergreifen, ohne dass sie explizit programmiert werden müssen. Maschinelle Lernsysteme nutzen das durch Training an großen Datenmengen gewonnene Wissen, um Vorhersagen und Entscheidungen über neue Daten zu treffen. ML-Algorithmen können ihre Leistung verbessern, da mehr Daten für das Training verwendet werden. Maschinelle Lernsysteme umfassen die Verarbeitung natürlicher Sprache, Bild- und Spracherkennung, prädiktive Analysen und mehr.
Betrugserkennung: Banken können maschinelle Lernsysteme nutzen, um aus vergangenen betrügerischen Transaktionen zu lernen und potenzielle betrügerische Aktivitäten in Echtzeit zu erkennen. Oder es könnte das System zurückentwickeln und nach Transaktionen suchen, die sehr „unnormal“ aussehen.
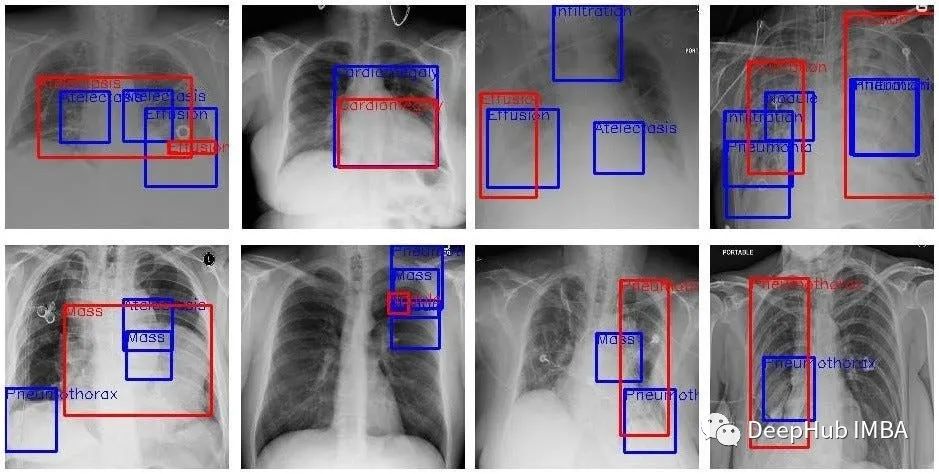
Gesundheitswesen: Krankenhäuser können ML-Systeme verwenden, um Patientendaten zu analysieren und anhand bestimmter Röntgenbilder die Wahrscheinlichkeit eines Patienten, eine bestimmte Krankheit zu entwickeln, vorherzusagen.
Vergleich
Sowohl regelbasierte Systeme als auch ML-Systeme haben ihre eigenen Vor- und Nachteile
Die Vorteile regelbasierter Systeme liegen auf der Hand:
- Einfach zu verstehen und zu erklären
- Schnell umzusetzen
- Einfach zu ändern
- Robust
Nachteile:
- Probleme mit vielen Variablen
- Probleme mit vielen Einschränkungen
- Begrenzt auf bestehende Regeln
Die Vorteile ML-basierter Systeme liegen ebenfalls auf der Hand
- Autonom lernendes System
- Die Fähigkeit, komplexere Probleme zu lösen
- Reduzierter menschlicher Eingriff und verbesserte Effizienz im Vergleich zu regelbasierten Systemen
- Flexible Anpassung an Änderungen in Daten und Umgebung durch kontinuierliches Lernen
Nachteile:
- Erforderliche Daten, Manchmal ist vieles
- auf die Daten-ML beschränkt, die wir zuvor gesehen haben
- Begrenzte kognitive Fähigkeit
Durch Vergleich haben wir festgestellt, dass die Vor- und Nachteile der beiden Systeme nicht im Widerspruch stehen und sich ergänzen. Gibt es also einen Weg? um sie zu kombinieren? Wie kann man ihre Vorteile kombinieren?
Hybride Systeme
Hybride Systeme, die regelbasierte Systeme und maschinelle Lernalgorithmen kombinieren, erfreuen sich in letzter Zeit immer größerer Beliebtheit. Sie können insbesondere bei der Bearbeitung komplexer Probleme robustere, genauere und effizientere Ergebnisse liefern.
Werfen wir einen Blick auf ein Hybridsystem, das mithilfe des Mietdatensatzes implementiert werden kann:
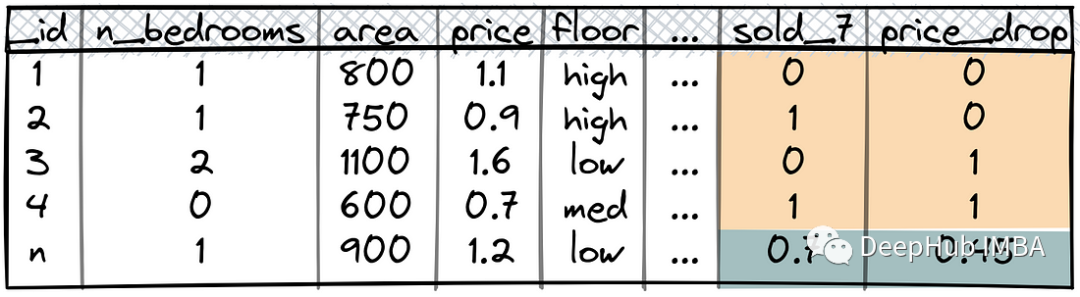
Feature Engineering: Wandeln Sie Böden in eine von drei Kategorien um: hoch, mittel oder niedrig, abhängig von der Etage des Gebäudes Nummer. Dies kann die Effizienz von ML-Modellen verbessern
Fest codierte Regeln können im Rahmen des Feature-Engineering-Prozesses verwendet werden, um wichtige Features in den Eingabedaten zu identifizieren und zu extrahieren. Wenn beispielsweise die Problemdomäne klar und eindeutig ist, können die Regeln einfach und genau definiert werden und hartcodierte Regeln können verwendet werden, um neue Features zu erstellen oder vorhandene Features zu ändern, um die Leistung des maschinellen Lernmodells zu verbessern. Obwohl Hardcoding-Regeln und Feature-Engineering zwei unterschiedliche Techniken sind, können sie zusammen verwendet werden, um die Leistung von Modellen für maschinelles Lernen zu verbessern. Mit hartcodierten Regeln können neue Features erstellt oder vorhandene Features geändert werden, während Feature Engineering zum Extrahieren von Features verwendet werden kann, die durch hartcodierte Regeln nicht einfach erfasst werden können.
Nachbearbeitung: Das Endergebnis runden oder normalisieren.
Fest codierte Regeln können als Teil der Nachbearbeitungsphase verwendet werden, um die Ausgabe des maschinellen Lernmodells zu ändern. Wenn beispielsweise ein Modell für maschinelles Lernen eine Reihe von Vorhersagen ausgibt, die nicht mit einigen bekannten Regeln oder Einschränkungen übereinstimmen, können hartcodierte Regeln verwendet werden, um die Vorhersagen so zu ändern, dass sie den Regeln oder Einschränkungen entsprechen. Nachbearbeitungstechniken wie Filtern oder Glätten können die Ausgabe eines maschinellen Lernmodells verfeinern, indem sie Rauschen oder Fehler entfernen oder die Gesamtgenauigkeit von Vorhersagen verbessern. Diese Techniken sind besonders effektiv, wenn Unsicherheit in den probabilistischen Ausgabevorhersagen des maschinellen Lernmodells oder in den Eingabedaten besteht. In einigen Fällen können auch Nachbearbeitungstechniken eingesetzt werden, um die Eingabedaten mit zusätzlichen Informationen anzureichern. Wenn beispielsweise ein Modell für maschinelles Lernen auf einem begrenzten Datensatz trainiert wird, können Nachbearbeitungstechniken verwendet werden, um zusätzliche Funktionen aus externen Quellen (z. B. sozialen Medien oder Newsfeeds) zu extrahieren und so die Genauigkeit von Vorhersagen zu verbessern.
Fall
Gesundheitswesen
Werfen wir einen Blick auf die Daten zu Herzerkrankungen:
Wenn wir Random Forest verwenden, um die Zielklasse vorherzusagen:
clf = RandomForestClassifier(n_estimators=100, random_state=random_seed X_train, X_test, y_train, y_test = train_test_split( df.iloc[:, :-1], df.iloc[:, -1], test_size=0.30, random_state=random_seed ) clf.fit(X_train, y_train))
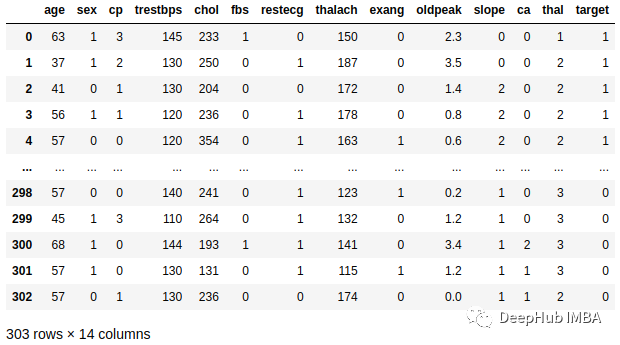
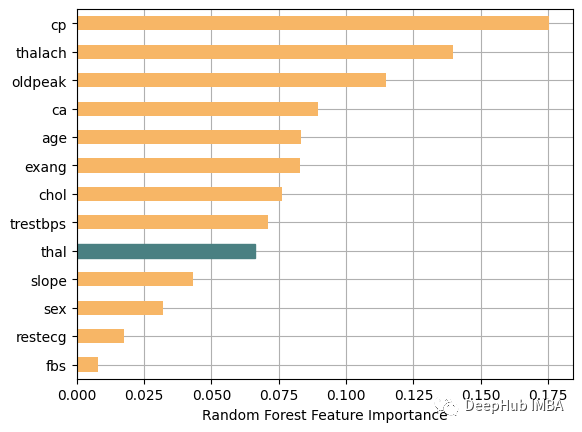
Einer der Gründe für die Wahl von Random Forest ist hier seine Build-Feature-Wichtigkeitsfunktionen. Die Bedeutung der für das Training verwendeten Funktionen können Sie unten sehen:
Sehen Sie sich die Ergebnisse an:
y_pred = pd.Series(clf.predict(X_test), index=y_test.index cm = confusion_matrix(y_test, y_pred, labels=clf.classes_) conf_matrix = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=clf.classes_) conf_matrix.plot())
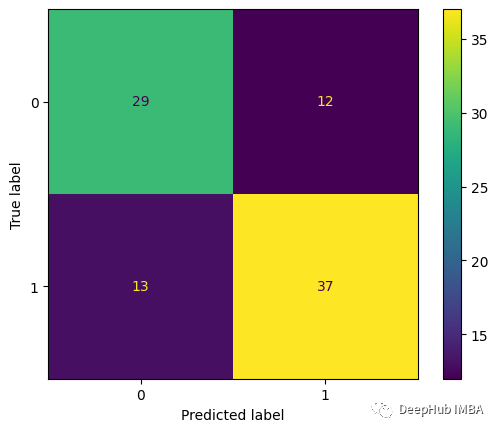
f1_score(y_test, y_pred): 0.74 recall_score(y_test, y_pred): 0.747
Dann sieht ein Kardiologe Ihr Modell. Aufgrund seiner Erfahrung und seines Fachwissens glaubt er, dass das Thalassämie-Merkmal (Thal) viel wichtiger ist als oben gezeigt. Deshalb haben wir beschlossen, ein Histogramm zu erstellen und die Ergebnisse anzusehen.
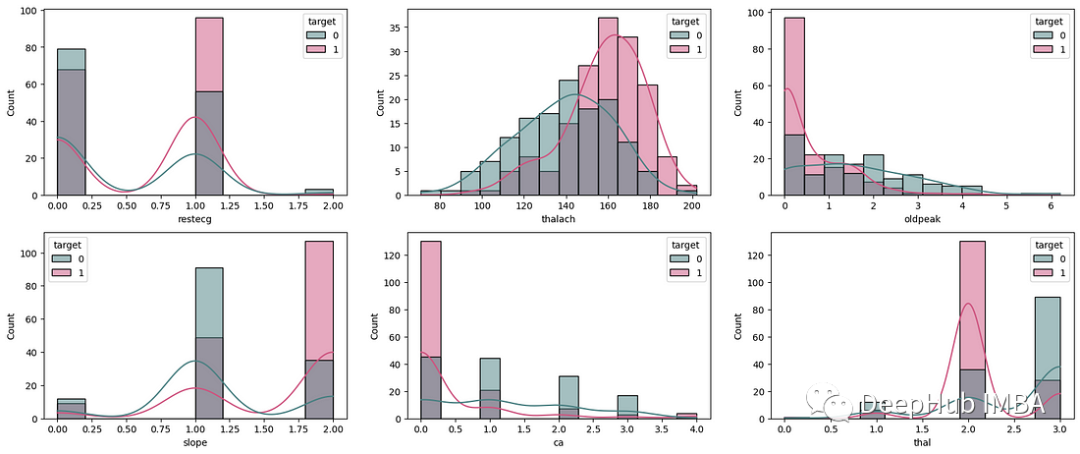
Geben Sie dann eine verbindliche Regel an
y_pred[X_test[X_test["thal"] == 2].index] = 1
Die resultierende Verwirrungsmatrix sieht folgendermaßen aus:
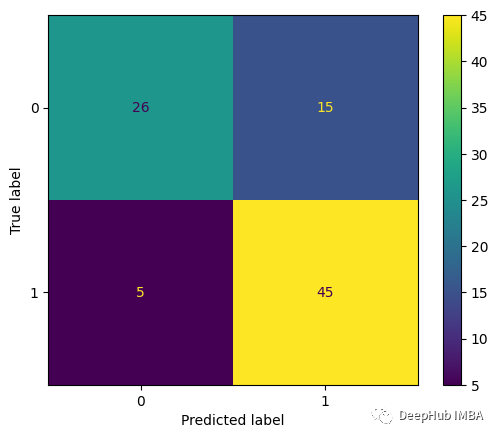
f1_score(y_test, y_pred): 0.818 recall_score(y_test, y_pred): 0.9
Das Ergebnis wurde erheblich verbessert. Hier spielt Domänenwissen eine wichtige Rolle bei der Beurteilung von Patientenscores.
Betrügerische Transaktionen
Der folgende Datensatz enthält Bankbetrugstransaktionen. Der Datensatz ist stark unausgeglichen: dient als unser Prädiktor für manuelle Regeln:
df["Class"].value_counts() 0 28431 1 4925
Wir können die Ergebnisse eines rein regelbasierten Systems und der kNN-Methode vergleichen. Der Grund für die Verwendung von kNN besteht darin, dass es unausgeglichene Daten verarbeiten kann:
Wie wir sehen können, haben wir mit nur drei geschriebenen Regeln eine bessere Leistung als das KNN-Modell Implementierung, gute Reaktion auf Ausreißer, Robustheit und erhöhte Transparenz. Sie sind von Vorteil, wenn Geschäftslogik mit maschinellem Lernen kombiniert wird. Beispielsweise können hybride Regel-ML-Systeme im Gesundheitswesen Krankheiten diagnostizieren, indem sie klinische Regeln mit Algorithmen für maschinelles Lernen kombinieren, die Patientendaten analysieren. Maschinelles Lernen kann bei vielen Aufgaben hervorragende Ergebnisse erzielen, erfordert aber auch ergänzende Domänenkenntnisse. Domänenwissen kann Modellen des maschinellen Lernens dabei helfen, Daten besser zu verstehen und genauere Vorhersagen und Klassifizierungen vorzunehmen.
Hybridmodelle können uns helfen, Domänenwissen und Modelle für maschinelles Lernen zu kombinieren. Hybridmodelle bestehen in der Regel aus mehreren Untermodellen, die jeweils für bestimmte Domänenkenntnisse optimiert sind. Diese Untermodelle können Modelle sein, die auf fest codierten Regeln basieren, Modelle, die auf statistischen Methoden basieren, oder sogar Modelle, die auf Deep Learning basieren.
Hybridmodelle können Domänenwissen nutzen, um den Lernprozess von Modellen für maschinelles Lernen zu steuern und so die Genauigkeit und Zuverlässigkeit des Modells zu verbessern. Im medizinischen Bereich können Hybridmodelle beispielsweise das Fachwissen eines Arztes mit der Leistungsfähigkeit eines Modells für maschinelles Lernen kombinieren, um die Krankheit eines Patienten zu diagnostizieren. Im Bereich der Verarbeitung natürlicher Sprache können Hybridmodelle sprachliches Wissen und die Fähigkeiten maschineller Lernmodelle kombinieren, um natürliche Sprache besser zu verstehen und zu generieren.
Kurz gesagt können Hybridmodelle uns dabei helfen, Domänenwissen und Modelle für maschinelles Lernen zu kombinieren, wodurch die Genauigkeit und Zuverlässigkeit des Modells verbessert wird und ein breites Anwendungsspektrum bei verschiedenen Aufgaben möglich ist.
Das obige ist der detaillierte Inhalt vonKombinieren Sie regelbasierte und maschinelle Lernansätze, um leistungsstarke Hybridsysteme aufzubauen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1369
1369
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Laienhaft ausgedrückt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Eingabedaten einer vorhergesagten Ausgabe zuordnet. Genauer gesagt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Modellparameter anpasst, indem sie aus Trainingsdaten lernt, um den Fehler zwischen der vorhergesagten Ausgabe und der wahren Bezeichnung zu minimieren. Beim maschinellen Lernen gibt es viele Modelle, z. B. logistische Regressionsmodelle, Entscheidungsbaummodelle, Support-Vektor-Maschinenmodelle usw. Jedes Modell verfügt über seine anwendbaren Datentypen und Problemtypen. Gleichzeitig gibt es viele Gemeinsamkeiten zwischen verschiedenen Modellen oder es gibt einen verborgenen Weg für die Modellentwicklung. Am Beispiel des konnektionistischen Perzeptrons können wir es durch Erhöhen der Anzahl verborgener Schichten des Perzeptrons in ein tiefes neuronales Netzwerk umwandeln. Wenn dem Perzeptron eine Kernelfunktion hinzugefügt wird, kann es in eine SVM umgewandelt werden. Dieses hier
 Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
In den 1950er Jahren wurde die künstliche Intelligenz (KI) geboren. Damals entdeckten Forscher, dass Maschinen menschenähnliche Aufgaben wie das Denken ausführen können. Später, in den 1960er Jahren, finanzierte das US-Verteidigungsministerium künstliche Intelligenz und richtete Labore für die weitere Entwicklung ein. Forscher finden Anwendungen für künstliche Intelligenz in vielen Bereichen, etwa bei der Erforschung des Weltraums und beim Überleben in extremen Umgebungen. Unter Weltraumforschung versteht man die Erforschung des Universums, das das gesamte Universum außerhalb der Erde umfasst. Der Weltraum wird als extreme Umgebung eingestuft, da sich seine Bedingungen von denen auf der Erde unterscheiden. Um im Weltraum zu überleben, müssen viele Faktoren berücksichtigt und Vorkehrungen getroffen werden. Wissenschaftler und Forscher glauben, dass die Erforschung des Weltraums und das Verständnis des aktuellen Zustands aller Dinge dazu beitragen können, die Funktionsweise des Universums zu verstehen und sich auf mögliche Umweltkrisen vorzubereiten
 Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
In diesem Artikel wird vorgestellt, wie Überanpassung und Unteranpassung in Modellen für maschinelles Lernen mithilfe von Lernkurven effektiv identifiziert werden können. Unteranpassung und Überanpassung 1. Überanpassung Wenn ein Modell mit den Daten übertrainiert ist, sodass es daraus Rauschen lernt, spricht man von einer Überanpassung des Modells. Ein überangepasstes Modell lernt jedes Beispiel so perfekt, dass es ein unsichtbares/neues Beispiel falsch klassifiziert. Für ein überangepasstes Modell erhalten wir einen perfekten/nahezu perfekten Trainingssatzwert und einen schrecklichen Validierungssatz-/Testwert. Leicht geändert: „Ursache der Überanpassung: Verwenden Sie ein komplexes Modell, um ein einfaches Problem zu lösen und Rauschen aus den Daten zu extrahieren. Weil ein kleiner Datensatz als Trainingssatz möglicherweise nicht die korrekte Darstellung aller Daten darstellt. 2. Unteranpassung Heru.“
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
MetaFAIR hat sich mit Harvard zusammengetan, um einen neuen Forschungsrahmen zur Optimierung der Datenverzerrung bereitzustellen, die bei der Durchführung groß angelegten maschinellen Lernens entsteht. Es ist bekannt, dass das Training großer Sprachmodelle oft Monate dauert und Hunderte oder sogar Tausende von GPUs verwendet. Am Beispiel des Modells LLaMA270B erfordert das Training insgesamt 1.720.320 GPU-Stunden. Das Training großer Modelle stellt aufgrund des Umfangs und der Komplexität dieser Arbeitsbelastungen einzigartige systemische Herausforderungen dar. In letzter Zeit haben viele Institutionen über Instabilität im Trainingsprozess beim Training generativer SOTA-KI-Modelle berichtet. Diese treten normalerweise in Form von Verlustspitzen auf. Beim PaLM-Modell von Google kam es beispielsweise während des Trainingsprozesses zu Instabilitäten. Numerische Voreingenommenheit ist die Hauptursache für diese Trainingsungenauigkeit.
