

So wenden Sie Python-Multiprozesse an

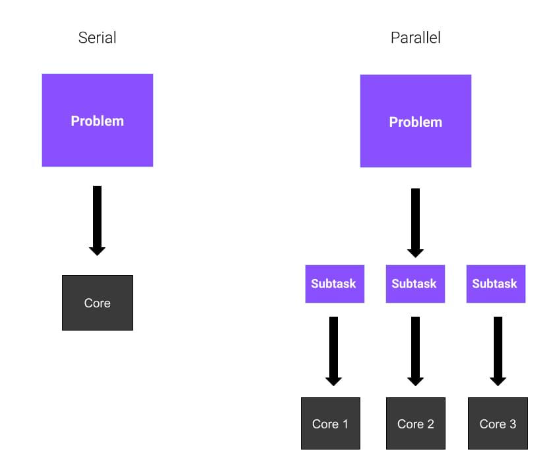
Paralleles und serielles Rechnen
Stellen Sie sich vor, Sie haben ein riesiges Problem zu lösen und sind allein. Sie müssen die Quadratwurzeln von acht verschiedenen Zahlen berechnen. Was machst du? Du hast keine große Auswahl. Beginnen Sie mit der ersten Zahl und berechnen Sie das Ergebnis. Dann wendet man sich anderen Menschen zu.
Was wäre, wenn Sie drei Freunde hätten, die gut in Mathe sind und bereit sind, Ihnen zu helfen? Jeder von ihnen berechnet die Quadratwurzel aus zwei Zahlen und Ihre Arbeit wird einfacher, da die Arbeitsbelastung gleichmäßig auf Ihre Freunde verteilt wird. Das bedeutet, dass Ihr Problem schneller gelöst wird.
Okay, ist alles klar? In diesen Beispielen repräsentiert jeder Freund einen Kern der CPU. Im ersten Beispiel wird die gesamte Aufgabe von Ihnen nacheinander gelöst. Dies wird als Serielle Berechnung bezeichnet. Da Sie im zweiten Beispiel insgesamt vier Kerne verwenden, verwenden Sie Parallel-Computing. Paralleles Rechnen umfasst die Verwendung paralleler Prozesse oder Prozesse, die auf mehrere Kerne eines Prozessors verteilt sind.
Paralleles Programmiermodell
Wir haben festgestellt, was parallele Programmierung ist, aber wie verwenden wir sie? Wir haben bereits gesagt, dass paralleles Rechnen die Ausführung mehrerer Aufgaben auf mehreren Kernen eines Prozessors umfasst, was bedeutet, dass diese Aufgaben gleichzeitig ausgeführt werden. Bevor Sie mit der Parallelisierung fortfahren, sollten Sie mehrere Aspekte berücksichtigen. Gibt es beispielsweise andere Optimierungen, die unsere Berechnungen beschleunigen können?
Gehen wir nun davon aus, dass Parallelisierung die am besten geeignete Lösung ist. Es gibt drei Hauptmodi des parallelen Rechnens:
Vollständige Parallelität. Aufgaben können unabhängig voneinander ausgeführt werden und müssen nicht miteinander kommunizieren.
Gemeinsame Speicherparallelität. Prozesse (oder Threads) müssen kommunizieren, daher teilen sie sich einen globalen Adressraum.
Messaging. Prozesse müssen bei Bedarf Nachrichten austauschen.
In diesem Artikel erklären wir das erste Modell, das auch das einfachste ist.
Python Multiprocessing: Prozessbasierte Parallelität in Python
Eine Möglichkeit, Parallelität in Python zu erreichen, ist die Verwendung des Moduls Multiprocessing. Mit dem multiprocessing-Modul können Sie mehrere Prozesse erstellen, jeder mit seinem eigenen Python-Interpreter. Daher implementiert Python-Multiprocessing prozessbasierte Parallelität. multiprocessing模块允许你创建多个进程,每个进程都有自己的 Python 解释器。因此,Python 多进程实现了基于进程的并行。
你可能听说过其他库,比如threading,它也是Python内置的,但它们之间有着重要的区别。multiprocessing模块创建新进程,而threading
Sie haben vielleicht schon von anderen Bibliotheken wie threading gehört, die ebenfalls in Python integriert sind, aber es gibt wichtige Unterschiede zwischen ihnen. Das Modul multiprocessing erstellt neue Prozesse, während threading neue Threads erstellt.
Vorteile der Verwendung von Multi-Processing
Sie fragen sich vielleicht: „Warum Multi-Processing wählen?“ Multi-Processing kann die Effizienz eines Programms erheblich verbessern, indem mehrere Aufgaben parallel statt nacheinander ausgeführt werden. Ein ähnlicher Begriff ist Multithreading, aber sie sind unterschiedlich.
Ein Prozess ist ein Programm, das zur Ausführung in den Speicher geladen wird und seinen Speicher nicht mit anderen Prozessen teilt. Ein Thread ist eine Ausführungseinheit in einem Prozess. Mehrere Threads laufen in einem Prozess und teilen sich den Speicherplatz des Prozesses miteinander.
Pythons Global Interpreter Lock (GIL) ermöglicht die Ausführung jeweils nur eines Threads unter dem Interpreter, was bedeutet, dass Sie die Leistungsvorteile von Multithreading nicht nutzen können, wenn Sie den Python-Interpreter benötigen. Aus diesem Grund ist Multi-Processing in Python vorteilhafter als Threading. Mehrere Prozesse können parallel ablaufen, da jeder Prozess über einen eigenen Interpreter verfügt, der die ihm zugewiesenen Anweisungen ausführt. Darüber hinaus betrachtet das Betriebssystem Ihr Programm in mehreren Prozessen und plant diese separat, d. h. Ihr Programm hat einen größeren Anteil an den gesamten Computerressourcen. Daher ist die Mehrfachverarbeitung schneller, wenn das Programm CPU-gebunden ist. In Situationen, in denen es viele E/A-Vorgänge in einem Programm gibt, sind Threads möglicherweise effizienter, da das Programm die meiste Zeit darauf wartet, dass die E/A-Vorgänge abgeschlossen sind. Allerdings sind mehrere Prozesse in der Regel effizienter, da sie gleichzeitig ablaufen.
Hier sind einige Vorteile der Mehrfachverarbeitung:
Bessere CPU-Nutzung bei CPU-intensiven Aufgaben
Mehr Kontrolle über Sub-Threads im Vergleich zu Threads
-
Einfach zu programmieren
Der erste Vorteil hängt mit der Leistung zusammen. Da durch Multiprocessing neue Prozesse entstehen, können Sie die Rechenleistung der CPU besser nutzen, indem Sie Aufgaben auf andere Kerne verteilen. Heutzutage sind die meisten Prozessoren Mehrkernprozessoren, und wenn Sie Ihren Code optimieren, können Sie durch paralleles Rechnen Zeit sparen.
Der zweite Vorteil ist eine Alternative zum Multithreading. Threads sind keine Prozesse, und das hat Konsequenzen. Wenn Sie einen Thread erstellen, ist es gefährlich, ihn wie einen normalen Prozess zu beenden oder ihn sogar zu unterbrechen. Da der Vergleich zwischen Multi-Processing und Multi-Threading den Rahmen dieses Artikels sprengen würde, werde ich später einen separaten Artikel schreiben, um über den Unterschied zwischen Multi-Processing und Multi-Threading zu sprechen.
Der dritte Vorteil der Mehrfachverarbeitung besteht darin, dass sie einfach zu implementieren ist, da die Aufgabe, die Sie bearbeiten möchten, für die parallele Programmierung geeignet ist.
Erste Schritte mit der Python-Multiverarbeitung
Wir sind endlich bereit, Python-Code zu schreiben!
Wir beginnen mit einem sehr einfachen Beispiel, anhand dessen wir die Kernaspekte der Python-Mehrverarbeitung veranschaulichen. In diesem Beispiel haben wir zwei Prozesse:
parentoft. Es gibt nur einen übergeordneten Prozess und dieser kann mehrere untergeordnete Prozesse haben.parent经常。只有一个父进程,它可以有多个子进程。child进程。这是由父进程产生的。每个子进程也可以有新的子进程。
我们将使用该child过程来执行某个函数。这样,parent可以继续执行。
一个简单的 Python多进程示例
这是我们将用于此示例的代码:
from multiprocessing import Process
def bubble_sort(array):
check = True
while check == True:
check = False
for i in range(0, len(array)-1):
if array[i] > array[i+1]:
check = True
temp = array[i]
array[i] = array[i+1]
array[i+1] = temp
print("Array sorted: ", array)
if __name__ == '__main__':
p = Process(target=bubble_sort, args=([1,9,4,5,2,6,8,4],))
p.start()
p.join()在这个片段中,我们定义了一个名为bubble_sort(array)。这个函数是冒泡排序算法的一个非常简单的实现。如果你不知道它是什么,请不要担心,因为它并不重要。要知道的关键是它是一个可以实现某个功能的函数。
进程类
从multiprocessing,我们导入类Process。此类表示将在单独进程中运行的活动。事实上,你可以看到我们已经传递了一些参数:
target=bubble_sort,意味着我们的新进程将运行该bubble_sort函数args=([1,9,4,52,6,8,4],),这是作为参数传递给目标函数的数组
一旦我们创建了 Process 类的实例,我们只需要启动该进程。这是通过编写p.start()完成的。此时,该进程开始。
在我们退出之前,我们需要等待子进程完成它的计算。该join()方法等待进程终止。
在这个例子中,我们只创建了一个子进程。正如你可能猜到的,我们可以通过在Process类中创建更多实例来创建更多子进程。
进程池类
如果我们需要创建多个进程来处理更多 CPU 密集型任务怎么办?我们是否总是需要明确地开始并等待终止?这里的解决方案是使用Pool类。
Pool类允许你创建一个工作进程池,在下面的示例中,我们将研究如何使用它。这是我们的新示例:
from multiprocessing import Pool
import time
import math
N = 5000000
def cube(x):
return math.sqrt(x)
if __name__ == "__main__":
with Pool() as pool:
result = pool.map(cube, range(10,N))
print("Program finished!")在这个代码片段中,我们有一个cube(x)函数,它只接受一个整数并返回它的平方根。很简单,对吧?
然后,我们创建一个Pool类的实例,而不指定任何属性。默认情况下,Pool类为每个 CPU 核心创建一个进程。接下来,我们使用几个参数运行map方法。
map方法将cube函数应用于我们提供的可迭代对象的每个元素——在本例中,它是从10到N的每个数字的列表。
这样做的最大优点是列表上的计算是并行进行的!
joblib
包joblib是一组使并行计算更容易的工具。它是一个用于多进程的通用第三方库。它还提供缓存和序列化功能。要安装joblib包,请在终端中使用以下命令:
pip install joblib
我们可以将之前的示例转换为以下示例以供使用joblib:
from joblib import Parallel, delayed
def cube(x):
return x**3
start_time = time.perf_counter()
result = Parallel(n_jobs=3)(delayed(cube)(i) for i in range(1,1000))
finish_time = time.perf_counter()
print(f"Program finished in {finish_time-start_time} seconds")
print(result)事实上,直观地看到它的作用。delayed()
child-Prozess. Dies wird vom übergeordneten Prozess generiert. Jeder untergeordnete Prozess kann auch neue untergeordnete Prozesse haben. 🎜Wir werden die Prozedur child verwenden, um eine Funktion auszuführen. Auf diese Weise kann parent die Ausführung fortsetzen. 🎜
Ein einfaches Python-Multiprozessbeispiel
Das werden wir für dieses Beispiel verwenden Code: 🎜
result = Parallel(n_jobs=3)((cube, (i,), {}) for i in range(1,1000))In diesem Snippet definieren wir eine Klasse namens bubble_sort(array). Diese Funktion ist eine sehr einfache Implementierung des Blasensortierungsalgorithmus. Wenn Sie nicht wissen, was es ist, machen Sie sich keine Sorgen, denn es ist nicht wichtig. Das Wichtigste, was man wissen muss, ist, dass es sich um eine Funktion handelt, die etwas tut. 🎜
Prozessklasse
Aus Multiprocessing importieren wir KlasseProzess. Diese Klasse stellt Aktivitäten dar, die in einem separaten Prozess ausgeführt werden. Tatsächlich können Sie sehen, dass wir einige Parameter übergeben haben: 🎜
- 🎜🎜
target=bubble_sort, was Our bedeutet Der neue Prozess führt die Funktion bubble_sort🎜🎜🎜args=([1,9,4,52,6,8,4],) aus ist das Array, das als Parameter an die Zielfunktion übergeben wird 🎜Sobald wir eine Instanz der Process-Klasse erstellt haben, müssen wir nur noch den Prozess starten . Dies geschieht durch das Schreiben von p.start(). An diesem Punkt beginnt der Prozess. 🎜
Wir müssen warten, bis der untergeordnete Prozess seine Berechnungen abgeschlossen hat, bevor wir ihn beenden. Die Methode join() wartet auf die Beendigung des Prozesses. 🎜
In diesem Beispiel erstellen wir nur einen untergeordneten Prozess. Wie Sie vielleicht erraten haben, können wir mehr untergeordnete Prozesse erstellen, indem wir mehr Instanzen in der Klasse Process erstellen. 🎜
Prozesspoolklasse
Wenn wir mehrere Prozesse erstellen müssen, um CPU-intensivere Prozesse zu bewältigen. Was mit Typaufgaben zu tun? Müssen wir immer explizit starten und auf die Beendigung warten? Die Lösung hier ist die Verwendung der Klasse Pool. 🎜
Mit der Klasse Pool können Sie einen Pool von Arbeitsprozessen erstellen. Im folgenden Beispiel sehen wir uns an, wie man ihn verwendet. Hier ist unser neues Beispiel: 🎜
result = Parallel(n_jobs=3, prefer="threads")(delayed(cube)(i) for i in range(1,1000))
In diesem Codeausschnitt haben wir eine cube(x)-Funktion, die einfach eine Ganzzahl akzeptiert und deren Quadratwurzel zurückgibt. Ziemlich einfach, oder? 🎜
Dann erstellen wir eine Instanz der Klasse Pool, ohne irgendwelche Eigenschaften anzugeben. Standardmäßig erstellt die Klasse Pool einen Prozess pro CPU-Kern. Als nächstes führen wir die Methode map mit einigen Parametern aus. 🎜
Die Methode map wendet die Funktion cube auf jedes Element des von uns bereitgestellten Iterables an – in diesem Fall a Liste aller Zahlen von 10 bis N. 🎜
Der größte Vorteil dabei ist, dass die Berechnungen auf der Liste parallel durchgeführt werden! 🎜
joblib🎜
Paket joblib ist eine Reihe von Tools, die paralleles Rechnen ermöglichen einfacheres Werkzeug. Es handelt sich um eine Allzweckbibliothek eines Drittanbieters für mehrere Prozesse. Es bietet außerdem Caching- und Serialisierungsfunktionen. Um das joblib-Paket zu installieren, verwenden Sie den folgenden Befehl im Terminal: 🎜
from multiprocessing import Pool
import time
import math
N = 5000000
def cube(x):
return math.sqrt(x)
if __name__ == "__main__":
# first way, using multiprocessing
start_time = time.perf_counter()
with Pool() as pool:
result = pool.map(cube, range(10,N))
finish_time = time.perf_counter()
print("Program finished in {} seconds - using multiprocessing".format(finish_time-start_time))
print("---")
# second way, serial computation
start_time = time.perf_counter()
result = []
for x in range(10,N):
result.append(cube(x))
finish_time = time.perf_counter()
print("Program finished in {} seconds".format(finish_time-start_time))Wir können das vorherige Beispiel in das folgende Beispiel zur Verwendung umwandeln joblib: 🎜
> python code.py Program finished in 1.6385094 seconds - using multiprocessing --- Program finished in 2.7373942999999996 seconds
Tatsächlich sehen Sie intuitiv, was es tut. Die Funktion delayed() ist ein Wrapper um eine andere Funktion, die eine „verzögerte“ Version eines Funktionsaufrufs generiert. Dies bedeutet, dass die Funktion beim Aufruf nicht sofort ausgeführt wird. 🎜
然后,我们多次调用delayed函数,并传递不同的参数集。例如,当我们将整数1赋予cube函数的延迟版本时,我们不计算结果,而是分别为函数对象、位置参数和关键字参数生成元组(cube, (1,), {})。
我们使用Parallel()创建了引擎实例。当它像一个以元组列表作为参数的函数一样被调用时,它将实际并行执行每个元组指定的作业,并在所有作业完成后收集结果作为列表。在这里,我们创建了n_jobs=3的Parallel()实例,因此将有三个进程并行运行。
我们也可以直接编写元组。因此,上面的代码可以重写为:
result = Parallel(n_jobs=3)((cube, (i,), {}) for i in range(1,1000))使用joblib的好处是,我们可以通过简单地添加一个附加参数在多线程中运行代码:
result = Parallel(n_jobs=3, prefer="threads")(delayed(cube)(i) for i in range(1,1000))
这隐藏了并行运行函数的所有细节。我们只是使用与普通列表理解没有太大区别的语法。
充分利用 Python多进程
创建多个进程并进行并行计算不一定比串行计算更有效。对于 CPU 密集度较低的任务,串行计算比并行计算快。因此,了解何时应该使用多进程非常重要——这取决于你正在执行的任务。
为了让你相信这一点,让我们看一个简单的例子:
from multiprocessing import Pool
import time
import math
N = 5000000
def cube(x):
return math.sqrt(x)
if __name__ == "__main__":
# first way, using multiprocessing
start_time = time.perf_counter()
with Pool() as pool:
result = pool.map(cube, range(10,N))
finish_time = time.perf_counter()
print("Program finished in {} seconds - using multiprocessing".format(finish_time-start_time))
print("---")
# second way, serial computation
start_time = time.perf_counter()
result = []
for x in range(10,N):
result.append(cube(x))
finish_time = time.perf_counter()
print("Program finished in {} seconds".format(finish_time-start_time))此代码段基于前面的示例。我们正在解决同样的问题,即计算N个数的平方根,但有两种方法。第一个涉及 Python 进程的使用,而第二个不涉及。我们使用time库中的perf_counter()方法来测量时间性能。
在我的电脑上,我得到了这个结果:
> python code.py Program finished in 1.6385094 seconds - using multiprocessing --- Program finished in 2.7373942999999996 seconds
如你所见,相差不止一秒。所以在这种情况下,多进程更好。
让我们更改代码中的某些内容,例如N的值。 让我们把它降低到N=10000,看看会发生什么。
这就是我现在得到的:
> python code.py Program finished in 0.3756742 seconds - using multiprocessing --- Program finished in 0.005098400000000003 seconds
发生了什么?现在看来,多进程是一个糟糕的选择。为什么?
与解决的任务相比,在进程之间拆分计算所带来的开销太大了。你可以看到在时间性能方面有多大差异。
Das obige ist der detaillierte Inhalt vonSo wenden Sie Python-Multiprozesse an. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Was ist der Grund, warum PS immer wieder Laden zeigt?
Apr 06, 2025 pm 06:39 PM
Was ist der Grund, warum PS immer wieder Laden zeigt?
Apr 06, 2025 pm 06:39 PM
PS "Laden" Probleme werden durch Probleme mit Ressourcenzugriff oder Verarbeitungsproblemen verursacht: Die Lesegeschwindigkeit von Festplatten ist langsam oder schlecht: Verwenden Sie Crystaldiskinfo, um die Gesundheit der Festplatte zu überprüfen und die problematische Festplatte zu ersetzen. Unzureichender Speicher: Upgrade-Speicher, um die Anforderungen von PS nach hochauflösenden Bildern und komplexen Schichtverarbeitung zu erfüllen. Grafikkartentreiber sind veraltet oder beschädigt: Aktualisieren Sie die Treiber, um die Kommunikation zwischen PS und der Grafikkarte zu optimieren. Dateipfade sind zu lang oder Dateinamen haben Sonderzeichen: Verwenden Sie kurze Pfade und vermeiden Sie Sonderzeichen. Das eigene Problem von PS: Installieren oder reparieren Sie das PS -Installateur neu.
 Wie löst ich das Problem des Ladens beim Starten von PS?
Apr 06, 2025 pm 06:36 PM
Wie löst ich das Problem des Ladens beim Starten von PS?
Apr 06, 2025 pm 06:36 PM
Ein PS, der beim Booten auf "Laden" steckt, kann durch verschiedene Gründe verursacht werden: Deaktivieren Sie korrupte oder widersprüchliche Plugins. Eine beschädigte Konfigurationsdatei löschen oder umbenennen. Schließen Sie unnötige Programme oder aktualisieren Sie den Speicher, um einen unzureichenden Speicher zu vermeiden. Upgrade auf ein Solid-State-Laufwerk, um die Festplatte zu beschleunigen. PS neu installieren, um beschädigte Systemdateien oder ein Installationspaketprobleme zu reparieren. Fehlerinformationen während des Startprozesses der Fehlerprotokollanalyse anzeigen.
 Wie löste ich das Problem des Ladens, wenn die PS die Datei öffnet?
Apr 06, 2025 pm 06:33 PM
Wie löste ich das Problem des Ladens, wenn die PS die Datei öffnet?
Apr 06, 2025 pm 06:33 PM
Das Laden von Stottern tritt beim Öffnen einer Datei auf PS auf. Zu den Gründen gehören: zu große oder beschädigte Datei, unzureichender Speicher, langsame Festplattengeschwindigkeit, Probleme mit dem Grafikkarten-Treiber, PS-Version oder Plug-in-Konflikte. Die Lösungen sind: Überprüfen Sie die Dateigröße und -integrität, erhöhen Sie den Speicher, aktualisieren Sie die Festplatte, aktualisieren Sie den Grafikkartentreiber, deinstallieren oder deaktivieren Sie verdächtige Plug-Ins und installieren Sie PS. Dieses Problem kann effektiv gelöst werden, indem die PS -Leistungseinstellungen allmählich überprüft und genutzt wird und gute Dateimanagementgewohnheiten entwickelt werden.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Wie kontrolliert PS -Federn die Weichheit des Übergangs?
Apr 06, 2025 pm 07:33 PM
Wie kontrolliert PS -Federn die Weichheit des Übergangs?
Apr 06, 2025 pm 07:33 PM
Der Schlüssel zur Federkontrolle liegt darin, seine allmähliche Natur zu verstehen. PS selbst bietet nicht die Möglichkeit, die Gradientenkurve direkt zu steuern, aber Sie können den Radius und die Gradientenweichheit flexius durch mehrere Federn, Matching -Masken und feine Selektionen anpassen, um einen natürlichen Übergangseffekt zu erzielen.
 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Was soll ich tun, wenn sich die PS -Karte in der Ladeschnittstelle befindet?
Apr 06, 2025 pm 06:54 PM
Was soll ich tun, wenn sich die PS -Karte in der Ladeschnittstelle befindet?
Apr 06, 2025 pm 06:54 PM
Die Ladeschnittstelle der PS-Karte kann durch die Software selbst (Dateibeschäftigung oder Plug-in-Konflikt), die Systemumgebung (ordnungsgemäße Treiber- oder Systemdateienbeschäftigung) oder Hardware (Hartscheibenbeschäftigung oder Speicherstickfehler) verursacht werden. Überprüfen Sie zunächst, ob die Computerressourcen ausreichend sind. Schließen Sie das Hintergrundprogramm und geben Sie den Speicher und die CPU -Ressourcen frei. Beheben Sie die PS-Installation oder prüfen Sie, ob Kompatibilitätsprobleme für Plug-Ins geführt werden. Aktualisieren oder Fallback die PS -Version. Überprüfen Sie den Grafikkartentreiber und aktualisieren Sie ihn und führen Sie die Systemdateiprüfung aus. Wenn Sie die oben genannten Probleme beheben, können Sie die Erkennung von Festplatten und Speichertests ausprobieren.
