
 Technologie-Peripheriegeräte
KI
13948 Fragen zu 52 Themen wie Analysis und Linienerzeugung wurden an die Tsinghua-Universität geschickt, um einen Testsatz für das chinesische Großmodell zu erstellen
Technologie-Peripheriegeräte
KI
13948 Fragen zu 52 Themen wie Analysis und Linienerzeugung wurden an die Tsinghua-Universität geschickt, um einen Testsatz für das chinesische Großmodell zu erstellen
13948 Fragen zu 52 Themen wie Analysis und Linienerzeugung wurden an die Tsinghua-Universität geschickt, um einen Testsatz für das chinesische Großmodell zu erstellen

Das Aufkommen von ChatGPT hat der chinesischen Community die Kluft zur internationalen Führungsebene bewusst gemacht. In letzter Zeit lief die Entwicklung chinesischer Großmodelle auf Hochtouren, es gibt jedoch nur sehr wenige chinesische Bewertungsbenchmarks.
Im Entwicklungsprozess der OpenAI GPT-Reihe/Google PaLM-Reihe/DeepMind Chinchilla-Reihe/Anthropic Claude-Reihe spielten die drei Datensätze von MMLU/MATH/BBH eine entscheidende Rolle, da sie die Fähigkeiten in jeder Dimension umfassender abdecken das Modell. Am bemerkenswertesten ist der MMLU-Datensatz, der die umfassenden Wissenskapazitäten von 57 Disziplinen berücksichtigt, von den Geisteswissenschaften über die Sozialwissenschaften bis hin zu Natur- und Ingenieurwissenschaften. Die Gopher- und Chinchilla-Modelle von DeepMind berücksichtigen nur MMLU-Ergebnisse. Daher möchten wir eine chinesische, ausreichend differenzierte, multidisziplinäre Benchmark-Liste erstellen, um Entwickler bei der Entwicklung großer chinesischer Modelle zu unterstützen.
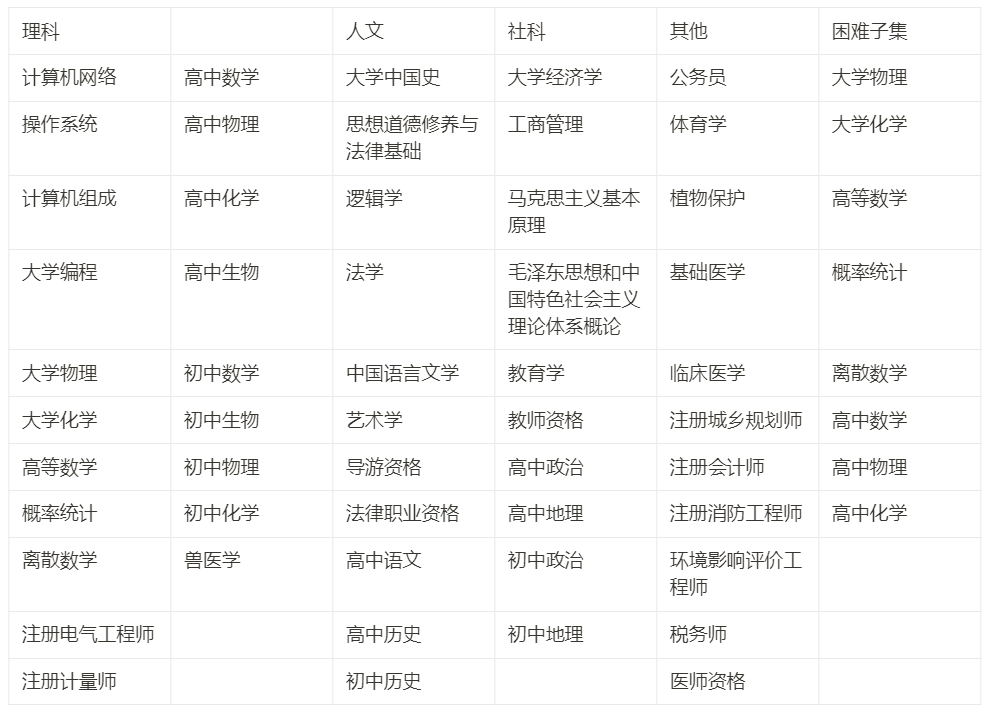
Wir haben etwa drei Monate damit verbracht, ein Programm zu erstellen, das vier Hauptrichtungen abdeckt: Geisteswissenschaften, Sozialwissenschaften, Natur- und Ingenieurwissenschaften und andere Hauptfächer sowie 52 Fächer (Infinitesimalrechnung, Liniengenerierung ...), von der Mittelschule bis zum Universitätsabsolventen Studenten- und Berufsprüfung, insgesamt 13948 Fragen zu Chinesischkenntnissen und Argumentationstests. Wir nennen es C-Eval, um der chinesischen Gemeinschaft bei der Entwicklung großer Modelle zu helfen.
Dieser Artikel dokumentiert unseren Prozess der Erstellung von C-Eval und teilt unsere Denkweise und F&E-Prioritäten aus unserer Sicht mit Entwicklern. Unser wichtigstes Ziel ist die Unterstützung der Modellentwicklung und nicht die Erstellung von Rankings . Das blinde Streben nach einem hohen Rang auf der Liste wird viele nachteilige Folgen haben, aber wenn C-Eval wissenschaftlich zur Unterstützung der Modelliteration eingesetzt werden kann, kann C-Eval maximiert werden. Daher empfehlen wir , den C-Eval-Datensatz und die C-Eval-Liste aus der Perspektive der Modellentwicklung zu behandeln.
- Website: https://cevalbenchmark.com/
- Github: https://github.com/SJTU-LIT/ce. val
- Papier: https://arxiv.org/abs/2305.08322
Inhaltsverzeichnis

1 – Kernindikatoren der Modellstärke
Passen Sie zunächst a an Modell Es ist nicht schwer, ein Konversationsroboter wie Alpaca, Vicuna und RWKV in der Open-Source-Welt zu sein. Es fühlt sich gut an, mit ihnen zu chatten, aber wenn Sie wirklich möchten, dass diese Modelle produktiv werden Einfach nur plaudern ist nicht genug. Daher besteht das erste Problem bei der Erstellung eines Bewertungsmaßstabs darin, den Grad der Differenzierung zu ermitteln und herauszufinden, welche Art von Fähigkeit der Kernindikator ist, der die Stärke eines Modells auszeichnet. Wir betrachten die beiden Kerne „Wissen“ und „Vernunft“. 1.1 - Wissen
Warum ist Wissensfähigkeit die Kernfähigkeit? Es gibt mehrere Argumente wie folgt:Wir hoffen, dass das Modell universell sein und zur Produktivität in verschiedenen Bereichen beitragen kann, was natürlich erfordert, dass das Modell die Kenntnisse in jedem Bereich kennt.
Wir hoffen auch, dass das Modell keinen Unsinn redet und nicht weiß, was es nicht weiß. Dies erfordert auch eine Erweiterung des Wissens des Modells, damit es seltener sagen kann, dass es nicht weiß.
- In Stanfords HELM English-Bewertungsliste ist eine wichtige Schlussfolgerung, dass die Größe des Modells signifikant positiv mit der Leistung wissensintensiver Aufgaben korreliert, da die Anzahl der Parameter des Modells zum Speichern von Wissen verwendet werden kann.
- Wie oben erwähnt, berücksichtigen bestehende wichtige Modelle wie DeepMinds Gopher/Chinchilla bei der Bewertung fast nur MMLU. Der Kern von MMLU ist die Wissensabdeckung des Testmodells.
- Im Release-Blog von GPT-4 wird zunächst die Leistung des Modells bei verschiedenen Fachprüfungen als Maß für die Fähigkeiten des Modells aufgeführt.
- Somit sind wissensbasierte Fähigkeiten ein guter Maßstab für das Potenzial des Basismodells.
-
1.2 - Argumentationsfähigkeit
Argumentationsfähigkeit ist die Fähigkeit, sich auf der Grundlage von Wissen weiter zu verbessern. Sie stellt dar, ob das Modell sehr schwierige und komplexe Dinge tun kann. Damit ein Modell stark ist, benötigt es zunächst umfassendes Wissen und kann dann auf der Grundlage dieses Wissens Schlussfolgerungen ziehen.
Das wichtige Argument für die Argumentation ist:
- Im Release-Blog von GPT-4 schrieb OpenAI klar: „Der Unterschied kommt zum Vorschein, wenn die Komplexität der Aufgabe einen ausreichenden Schwellenwert erreicht“ (GPT-3.5 und GPT Der Unterschied von -4 wird erst sichtbar, wenn die Aufgabe einen bestimmten Grad an Komplexität erreicht. Dies zeigt, dass starke Modelle über erhebliche Inferenzfähigkeiten verfügen, während schwächere Modelle nicht über große Fähigkeiten verfügen.
- Im Tech Report von PaLM-2 sind die beiden Inferenzdatensätze BBH und MATH speziell zur Diskussion und Fokussierung aufgeführt.
- Wenn Sie möchten, dass das Modell zu einer neuen Generation von Computerplattformen wird und darauf ein neues Anwendungsökosystem entsteht, müssen Sie das Modell stark genug machen, um komplexe Aufgaben zu erledigen.
Hier müssen wir auch den Zusammenhang zwischen Argumentation und Wissen klären:
- Wissensbasierte Fähigkeiten sind die Grundlage der Modellfähigkeiten, und Argumentationsfähigkeiten sind eine weitere Sublimation – Modellargumentation basiert ebenfalls auf dem Vorhandenen Wissensgraph.
- Auf der Liste der wissensbasierten Aufgaben ändern sich die Modellgröße und der Modellwert im Allgemeinen kontinuierlich. Es ist unwahrscheinlich, dass es zu einem klippenartigen Rückgang kommt, nur weil das Modell klein ist – aus dieser Perspektive wissensbasierte Aufgaben sind differenzierter.
- Auf der Liste der Argumentationsaufgaben kann es zu einem Phasenwechsel zwischen der Modellgröße und der Modellbewertung kommen. Nur wenn das Modell bis zu einem bestimmten Grad groß genug ist (wahrscheinlich 50B und höher, also das Niveau von LLaMA). 65B) wird die Fähigkeit zum Modelldenken zum Vorschein kommen.
- Bei wissensbasierten Aufgaben sind die Auswirkungen der Gedankenkettenaufforderung (CoT) und der Nur-Antwort-Aufforderung (AO) nahezu gleich; bei Argumentationsaufgaben ist CoT deutlich besser als AO.
- Sie müssen hier also bedenken, dass CoT nur Argumentationseffekte, aber keine Wissenseffekte hinzufügt. Wir haben dieses Phänomen auch im C-Eval-Datensatz beobachtet.
2 – Das Ziel von C-Eval
Mit der obigen Erklärung von Wissen und Argumentation haben wir beschlossen, von der wissensbasierten Aufgabe auszugehen und einen Datensatz zu erstellen, um die Wissensfähigkeit des Modells zu testen Äquivalent zum Benchmarking des MMLU-Datensatzes hoffen wir auch, einige argumentationsbezogene Inhalte bereitzustellen, um die Fähigkeiten höherer Ordnung des Modells weiter zu messen. Daher haben wir in C-Eval speziell die Themen extrahiert, die eine starke Argumentation erfordern ( Infinitesimalrechnung, lineare Algebra, Wahrscheinlichkeit ...) und nannten sie C-Eval. Die harte Teilmenge wird verwendet, um die Argumentationsfähigkeit des Modells zu messen, was einem Benchmarking des MATH-Datensatzes entspricht.
Bei C-Eval Hard muss das Modell zunächst über mathematische Kenntnisse verfügen, dann muss es eine schrittweise Idee zur Problemlösung haben und dann Wolfram Alpha/Mathematica/Matlab für numerische Zwecke aufrufen und Symbolik/Differenzierung und Integration während des Problemlösungsprozesses. Die Fähigkeit, den Berechnungsprozess und die Ergebnisse im Latex-Format auszudrücken, ist sehr schwierig.
C-Eval hofft, MMLU als Ganzes zu bewerten (dieser Datensatz wird für die Entwicklung von GPT-3.5, GPT-4, PaLM, PaLM-2, Gopher, Chinchilla verwendet) und hofft, den harten Teil MATH zu bewerten (Dieser Datensatz wird bei der Entwicklung von GPT-4, PaLM-2, Minerva, Galactica verwendet).
An dieser Stelle ist zu beachten, dass unser wichtigstes Ziel darin besteht, die Modellentwicklung zu unterstützen und nicht aufzulisten . Das blinde Streben nach einem hohen Rang auf der Liste hat viele nachteilige Konsequenzen, die wir gleich erläutern werden. Wenn Sie C-Eval jedoch wissenschaftlich nutzen können, um die Modelliteration zu unterstützen, werden Sie enorme Vorteile erzielen. Wir empfehlen, den C-Eval-Datensatz und die C-Eval-Liste aus der Perspektive der Modellentwicklung zu behandeln.
2.1 - Das Ziel besteht darin, die Modellentwicklung zu unterstützen
Im eigentlichen Forschungs- und Entwicklungsprozess müssen wir oft die Qualität einer bestimmten Lösung oder die Qualität eines bestimmten Modells kennen Dieses Mal benötigen wir einen Datensatz, der uns beim Testen hilft. Im Folgenden sind zwei klassische Szenen aufgeführt:
Szenario 1: Suche nach zusätzlichen Hyperparametern Optimales Schema für die Mischung von Trainingsdaten vor dem Training.- Szenario 2, Vergleich der Trainingsphase des Modells: Ich habe einen vorab trainierten Kontrollpunkt und einen durch Anweisungen abgestimmten Kontrollpunkt, und dann möchte ich die Wirkung meiner Anweisungsoptimierung messen, damit ich kann die beiden kombinieren. Die Prüfpunkte werden bei C-Eval miteinander verglichen, um die relative Qualität des Vortrainings und der Unterrichtsoptimierung zu messen.
- 2.2 - Ranking ist nicht das Ziel Wir müssen betonen, warum das Ranking auf der Liste nicht das Ziel sein sollte:
Wenn Sie das Ranking auf der Liste zu Ihrem Ziel machen, wird es das sein Bei hohen Punktzahlen kann man leicht vorbeikommen, aber an Vielseitigkeit verlieren – das ist eine wichtige Lektion, die die NLP-Akademikergemeinschaft aus der Feinabstimmung von Bert vor GPT-3.5 gelernt hat.
Die Liste selbst misst nur das Potenzial des Modells, nicht die tatsächliche Benutzererfahrung – wenn das Modell den Benutzern wirklich gefällt, bedarf es noch einer Menge manueller Bewertung
- Wenn das Ziel ein Ranking ist, ist es das auch Einfache Abkürzungen für hohe Punktzahlen. Die Qualität und der Geist solider wissenschaftlicher Forschung sind verloren gegangen.
- Wenn C-Eval als Hilfsmittel zur Entwicklungsunterstützung eingesetzt wird, kann seine positive Rolle jedoch maximiert werden. Wenn es jedoch als Listenranking verwendet wird, kommt es zu einem enormen Missbrauch von C-Eval-Risiken Es besteht eine hohe Wahrscheinlichkeit, dass am Ende keine guten Ergebnisse erzielt werden.
- Daher empfehlen wir noch einmal
Viele Testteams, selbst im selben Unternehmen, können keine relevanten Informationen über das getestete Modell kennen (Black-Box-Tests), oder das überhaupt wissen Ob das Modell eine Anweisungsoptimierung durchlaufen hat, also müssen wir sowohl In-Context-Lernen als auch Zero-Shot-Prompting unterstützen.Da es sich bei einigen Modellen um Black-Box-Tests handelt, gibt es keine Möglichkeit, Protokolle abzurufen. Es ist jedoch schwieriger zu bestimmen, ob kleine Modelle keine Logits-Antwort haben. Daher müssen wir eine Reihe kleiner Modelle ermitteln, um die Antwort zu ermitteln.
Es gibt viele Arten von Modelltestmodellen, z. B. In-Context-Lernen und Zero-Shot-Prompt; es gibt viele Eingabeaufforderungsformate, z. B. Nur-Antwort-Modelle und Gedankenketten; B. vorab trainierte Kontrollpunkte und durch Anweisungen fein abgestimmte Kontrollpunkte, daher müssen wir die jeweiligen Auswirkungen und Wechselwirkungen dieser Faktoren klären. Das Modell reagiert sehr empfindlich auf Eingabeaufforderungen, ob schnelles Engineering erforderlich ist und ob schnelles Engineering der Fairness abträglich ist.
GPT-3.5 / GPT-4 / Claude / PaLMs schnelles Engineering sollte durchgeführt werden und dann aus ihren Erfahrungen lernen.
Die oben genannten Probleme wurden durch Feedback von Entwicklern während unserer Interaktionen mit ihnen entdeckt. Diese Probleme wurden in der Dokumentation und im Github-Code der aktuellen öffentlichen Version von C-Eval gelöst.
- Die oben genannten Prozesse beweisen auch, dass die Behandlung des C-Eval-Datensatzes und der C-Eval-Liste aus der Perspektive der Modellentwicklung sehr gut jedem bei der Entwicklung chinesischer Großmodelle helfen kann.
-
Wir heißen alle Entwickler herzlich willkommen, Probleme und Pull-Anfragen an unseren GitHub zu senden, um uns mitzuteilen, wie wir Ihnen besser helfen können. Wir hoffen, Ihnen besser helfen zu können:)
3 – Wie Sie die Qualität sicherstellen können
In diesem Kapitel diskutieren wir die Methoden, mit denen wir die Qualität des Datensatzes während des Produktionsprozesses sichergestellt haben. Unsere wichtigsten Referenzen sind hier die beiden Datensätze MMLU und MATH. Da sich die vier wichtigsten großen Modellteams, OpenAI, Google, DeepMind und Anthropic, alle auf MMLU und MATH konzentrieren, hoffen wir, zu diesen beiden beitragen zu können Datensätze. Nach unserer vorläufigen Recherche und einer Reihe von Diskussionen trafen wir zwei wichtige Entscheidungen: Die eine bestand darin, den Datensatz von Grund auf neu zu erstellen, und die andere darin, sich darauf zu konzentrieren, zu verhindern, dass die Frage vom Crawler erfasst wird kriecht ins Trainingsset . 3.1 - Handgefertigt
Eine wichtige Inspiration im Entwicklungsprozess von GPT ist, dass es im Bereich der künstlichen Intelligenz genauso viel Intelligenz gibt wie künstliche Intelligenz. Das ist auch sehr gut Konkret aus der Quelle der Fragen:
Die meisten Fragen in C-Eval stammen aus Dateien im PDF- und Word-Format. Solche Fragen erfordern eine zusätzliche Verarbeitung und (manuelle) Bereinigung verwendet werden kann. Dies liegt daran, dass es im Internet zu viele verschiedene Fragen gibt, die wahrscheinlich im Vortraining des Modells verwendet wurden:
- Nach dem Sammeln der Fragen muss zunächst die PDF-Datei mit OCR elektronisch konvertiert und dann das Format in Markdown vereinheitlicht werden, und der mathematische Teil wird im Latex-Format vereinheitlicht. Die Verarbeitung von Formeln ist eine mühsame Sache: Erstens ist OCR möglicherweise nicht möglich in der Lage, es richtig zu erkennen, und dann kann OCR nicht direkt als Latex erkannt werden. Wenn es nicht automatisch konvertiert werden kann, geben die Schüler es manuell ein Das Endergebnis ist, dass der gesamte symbolbezogene Inhalt in mehr als 13.000 Fragen (einschließlich mathematischer Formeln und chemischer Formeln wie H2O) von den Studenten unseres Projektteams einzeln überprüft wurde Wir machen das zwei Wochen lang
Jetzt lässt sich unser Thema sehr schön in Form von Markdown darstellen. Dieses Beispiel können Sie direkt im Erkundungsbereich unserer Website sehen
- Die nächste Schwierigkeit besteht darin, die offizielle Gedankenkette zu konstruieren. Der entscheidende Punkt hierbei ist, dass wir sicherstellen müssen, dass unser CoT korrekt ist. Unser ursprünglicher Ansatz bestand darin, GPT-4 für jedes Kontextbeispiel eine Gedankenkette generieren zu lassen, aber später stellten wir fest, dass dies nicht machbar war. Erstens war die generierte Kette zu lang (mehr als 2048 Token). Die Länge einiger Modelle wird möglicherweise nicht unterstützt. Das andere ist, dass die Fehlerrate zu hoch ist. Es ist besser, jedes einzelne Modell selbst zu überprüfen.
- Also unsere Schüler basieren auf dem von GPT-4 generierten CoT, der Berechnung und der Zeilengenerierung , Wahrscheinlichkeit, Diskretisierung dieser prompten Fragen (5 Fragen für jedes Fach als kontextbezogene Beispiele), ich habe es wirklich selbst gemacht. Das Folgende ist ein Beispiel:
Der Student auf der linken Seite hat es getan es selbst und dann im Markdown-Latex-Format geschrieben; die rechte Seite ist der gerenderte Effekt

- Sie können auch spüren, warum die Frage schwierig ist, die Gedankenkette sehr lang ist und warum die Das Modell muss in der Lage sein, die Symbole und Summen der numerischen Berechnungen auszuführen Mechanismen, um zu verhindern, dass unsere Fragen in den Trainingssatz eingemischt werden
- Zunächst gibt unser Testset nur die Fragen, aber nicht die Antworten bekannt. Sie können Ihr eigenes Modell verwenden, um die Antworten lokal auszuführen und auf der Website einzureichen, und dann wird die Punktzahl im Hintergrund ausgegeben
- Dann sind alle C-Eval-Fragen Simulationsfragen. Wir haben keine echten Fragen von der Mittelschule über die Aufnahmeprüfungen für Postgraduierte bis hin zu Berufsprüfungen verwendet. Dies liegt daran, dass die echten Fragen der nationalen Prüfungen weit verbreitet und sehr einfach sind in den Modelltrainingssatz gecrawlt werden
Natürlich kann es trotz unserer Bemühungen unweigerlich vorkommen, dass Fragen in der Fragendatenbank auf einer bestimmten Webseite durchsucht werden können, aber wir glauben, dass diese Situation selten sein sollte. Und den Ergebnissen nach zu urteilen, sind die C-Eval-Fragen immer noch ausreichend differenziert, insbesondere der schwierige Teil.
4 – Methoden zur Verbesserung des Rankings
Als nächstes analysieren wir, mit welchen Methoden das Ranking des Modells verbessert werden kann. Wir listen zunächst die Abkürzungen für Sie auf, einschließlich der Verwendung von LLaMA, das nicht kommerziell erhältlich ist, und der Verwendung von durch GPT generierten Daten sowie die Nachteile dieser Methoden. Anschließend besprechen wir, was der schwierige, aber richtige Weg ist.
4.1 - Welche Abkürzungen kann ich nehmen?
Hier sind die Abkürzungen, die Sie verwenden können:- Verwenden Sie LLaMA als Basismodell: In unserem anderen verwandten englischen Modellbewertungsprojekt Chain-of-thought Hub haben wir auf The hingewiesen Das 65B LLaMA-Modell ist ein etwas schwächeres Basismodell als GPT-3.5. Es verfügt über großes Potenzial. Wenn es mit chinesischen Daten trainiert wird, können seine leistungsstarken Englischfähigkeiten automatisch auf Chinesisch übertragen werden. Aber die Nachteile davon sind:
- Erstens ist die Obergrenze der F&E-Fähigkeiten durch LLaMA 65B festgelegt, und es ist unmöglich, GPT-3.5 zu überschreiten, geschweige denn GPT-4 Andererseits ist LLaMA nicht im Handel erhältlich. Die Verwendung für die Kommerzialisierung verstößt direkt gegen die Vorschriften.
- Verwenden Sie die von GPT-4 generierten Daten. und geben Sie dann die GPT-4-Antwort ein, um einfach Ihr eigenes Modell zu erstellenAber die Nachteile davon sind erstens, dass es sich um reines Schummeln handelt und die erzielten Ergebnisse nicht verallgemeinert werden können und zweitens nicht die wahren Fähigkeiten des Modells darstellen können , wenn es kommerzialisiert wird, verstößt es direkt gegen die Verwendung von OpenAI-Vorschriften; drittens wird die Destillation von GPT-4 das Phänomen des Modellunsinns verstärken Dies liegt daran, dass die Feinabstimmung der Modellablehnungsfähigkeit das Modell fördert zu wissen, was es weiß und was nicht; aber direkt Wenn Sie GPT-4 kopieren, wissen andere Modelle möglicherweise nicht unbedingt, was GPT-4 weiß. Dies wird Modelle dazu ermutigen, Unsinn zu reden. Dieses Phänomen wurde kürzlich in einem Vortrag von John Schulman in Berkeley hervorgehoben.
- Oft ist auf etwas, das wie eine Abkürzung aussieht, tatsächlich heimlich ein Preis vermerkt. 4.2 - Schwieriger, aber richtiger Weg
Der beste Weg ist, selbstständig zu sein und sich von Grund auf zu entwickeln. Diese Sache ist schwierig, braucht Zeit und erfordert Geduld, aber es ist der richtige Weg.
Konkret müssen Sie sich auf Beiträge der folgenden Institutionen konzentrierenOpenAI – Es besteht kein Zweifel, dass alle Artikel vollständig auswendig gelernt werden müssen
Anthropic – Was OpenAI nicht kann Sag es dir, Anthropic wird es dir sagen
- Google DeepMind – Google ist eher eine Abzocke und erzählt dir alle Technologien ehrlich, im Gegensatz zu OpenAI, das versteckt und versteckt ist
- Wenn der Leser unerfahren ist, dann du kann zunächst aufhören, Artikel von anderen Orten zu lesen. Entwickeln Sie zunächst Ihr Urteilsvermögen und lesen Sie dann Artikel von anderen Orten, damit Sie zwischen Gut und Böse unterscheiden können. Im akademischen Bereich ist es wichtig, zwischen Gut und Böse zu unterscheiden, anstatt einfach nur ohne Urteil zu akzeptieren.
- Während des Forschungs- und Entwicklungsprozesses wird empfohlen, auf folgende Inhalte zu achten:
- Wie man Vortrainingsdaten organisiert, wie zum Beispiel die DoReMi-Methode
- Wie man die Stabilität von Vortrainingsdaten erhöht, wie zum Beispiel die BLOOM-Methode# 🎜🎜#
- So organisieren Sie Anleitungs-Tuning-Daten, wie z. B. The Flan Collection
- Wie man Anleitungen durchführt Tuning, wie zum Beispiel Selbstanweisung
- Wie man RL macht, wie zum Beispiel konstitutionelle KI
- Wie Erhöhen Sie Ihre Denkfähigkeiten, wie in unserem vorherigen Blog
- So verbessern Sie die Codierungsfähigkeiten, wie z. B. StarCoder #🎜🎜 #So erhöhen Sie die Fähigkeit, Werkzeuge zu verwenden (C-Eval Hard erfordert, dass das Modell Werkzeuge für wissenschaftliche Berechnungen aufrufen kann), wie z. B. Toolformer
- #🎜🎜 #
# 🎜🎜#Großes Modell ist eine zeitaufwändige Sache. Es ist ein umfassender Test der industriellen Fähigkeiten der künstlichen Intelligenz: # 🎜🎜#
# 🎜🎜#Die GPT-Serie von OpenAI ging von GPT-3 auf GPT-4, von 2019 bis 2023 dauerte es insgesamt vier Jahre.
- Anthropic Nachdem das ursprüngliche Team von OpenAI getrennt wurde, dauerte es trotz der Erfahrung mit GPT-3 ein Jahr, Claude zu überarbeiten.
- Das Team von LLaMA brauchte trotz der Lehren aus OPT und BLOOM sechs Monate.
- GLM-130B dauerte zwei Jahre von der Projektgründung bis zur Veröffentlichung.
- Der Ausrichtungsteil von MOSS, der Inhalt vor RL, hat ebenfalls fast ein halbes Jahr gedauert, und hier ist RL immer noch nicht enthalten.
- Deshalb besteht kein Grund zur Eile zur Rangliste, kein Grund, morgen die Ergebnisse zu sehen, kein Grund, übermorgen online zu gehen - Nehmen Sie sich Zeit, Schritt für Schritt. Oft ist der schwierige, aber richtige Weg tatsächlich der schnellste Weg. 5 – Fazit
In diesem Artikel haben wir die Entwicklungsziele, den Prozess und die wichtigsten Überlegungen von C-Eval vorgestellt. Unser Ziel ist es, Entwicklern dabei zu helfen, chinesische Großmodelle besser zu entwickeln und den wissenschaftlichen Einsatz von C-Eval in Wissenschaft und Industrie zu fördern, um die Modelliteration zu unterstützen. Wir haben es nicht eilig, die Ergebnisse zu sehen, denn große Modelle selbst sind eine sehr schwierige Sache. Wir kennen die Abkürzungen, die wir nehmen können, aber wir wissen auch, dass der schwierige, aber richtige Weg tatsächlich der schnellste Weg ist. Wir hoffen, dass diese Arbeit das F&E-Ökosystem chinesischer Großmodelle fördern und es den Menschen ermöglichen kann, den Komfort dieser Technologie früher zu erleben.
Anhang 1: Im C-Eval enthaltene Fächer
# 🎜🎜#
Anhang 2: Beiträge der Projektmitglieder
Hinweis: Die entsprechende URL der im Artikel genannten Artikel finden Sie auf der Originalseite.


Das obige ist der detaillierte Inhalt von13948 Fragen zu 52 Themen wie Analysis und Linienerzeugung wurden an die Tsinghua-Universität geschickt, um einen Testsatz für das chinesische Großmodell zu erstellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
 Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Projektlink vorne geschrieben: https://nianticlabs.github.io/mickey/ Anhand zweier Bilder kann die Kameraposition zwischen ihnen geschätzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere geschätzten Posen sind maßstabsunabhängig. Einige Anwendungen, wie z. B. Instant Augmented Reality jederzeit und überall, erfordern eine Posenschätzung von Skalenmetriken und sind daher auf externe Tiefenschätzer angewiesen, um die Skalierung wiederherzustellen. In diesem Artikel wird MicKey vorgeschlagen, ein Keypoint-Matching-Prozess, mit dem metrische Korrespondenzen im 3D-Kameraraum vorhergesagt werden können. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern können wir auf metrische Relativwerte schließen
 Nehmen Sie an einem neuen Xianxia-Abenteuer teil! Der Vorab-Download von „Zhu Xian 2' „Wuwei Test' ist jetzt verfügbar
Apr 22, 2024 pm 12:50 PM
Nehmen Sie an einem neuen Xianxia-Abenteuer teil! Der Vorab-Download von „Zhu Xian 2' „Wuwei Test' ist jetzt verfügbar
Apr 22, 2024 pm 12:50 PM
Der „Inaction Test“ des neuen Fantasy-Märchen-MMORPG „Zhu Xian 2“ startet am 23. April. Was für eine neue Märchen-Abenteuergeschichte wird auf dem Kontinent Zhu Die Six Realm Immortal World, eine Vollzeitakademie zur Kultivierung von Unsterblichen, ein freies Leben zur Kultivierung von Unsterblichen und jede Menge Spaß in der Welt der Unsterblichen warten darauf, von den unsterblichen Freunden persönlich erkundet zu werden! Der Vorab-Download von „Wuwei Test“ ist jetzt möglich. Sie können sich zum Herunterladen auf die offizielle Website begeben. Der Aktivierungscode kann nach dem Vorab-Download und der Installation verwendet werden abgeschlossen. „Zhu Als Blaupause wird der Spielhintergrund festgelegt
