
 Technologie-Peripheriegeräte
KI
Das Bild stimmt nicht mit dem Code überein. Im Transformer-Papier wurde ein Fehler gefunden: Es hätte 1.000 Mal darauf hingewiesen werden sollen.
Technologie-Peripheriegeräte
KI
Das Bild stimmt nicht mit dem Code überein. Im Transformer-Papier wurde ein Fehler gefunden: Es hätte 1.000 Mal darauf hingewiesen werden sollen.
Das Bild stimmt nicht mit dem Code überein. Im Transformer-Papier wurde ein Fehler gefunden: Es hätte 1.000 Mal darauf hingewiesen werden sollen.

Im Jahr 2017 hat das Google Brain-Team die Transformer-Architektur in seinem Artikel „Attention Is All You Need“ kreativ vorgeschlagen. Seitdem ist diese Forschung bahnbrechend und hat sich heute zu einem der beliebtesten Modelle im Bereich NLP entwickelt Es wurde häufig auf verschiedene Sprachaufgaben angewendet und erzielte viele SOTA-Ergebnisse.
Darüber hinaus hat Transformer, das im Bereich NLP eine Vorreiterrolle spielt, schnell Bereiche wie Computer Vision (CV) und Spracherkennung durchschritten und bei Aufgaben wie Bildklassifizierung und Zielerkennung gute Ergebnisse erzielt und Spracherkennung.

Papieradresse: https://arxiv.org/pdf/1706.03762.pdf
Seit seiner Einführung ist Transformer zum Kernmodul vieler Modelle geworden, wie z Bekannte BERT, T5 usw. haben alle Transformatoren. Sogar das in letzter Zeit populär gewordene ChatGPT setzt auf Transformer, das bereits von Google patentiert wurde.

Bildquelle: https://patentimages.storage.googleapis.com/05/e8/f1/cd8eed389b7687/US10452978.pdf
Darüber hinaus hat OpenAI eine Reihe veröffentlicht Beim Modell GPT (Generative Pre-Trained Transformer) mit Transformer im Namen ist ersichtlich, dass Transformer der Kern des GPT-Serienmodells ist.
Gleichzeitig sagte OpenAI-Mitbegründer Ilya Stutskever kürzlich, als er über Transformer sprach, dass die Erstveröffentlichung von Transformer tatsächlich am zweiten Tag nach der Veröffentlichung des Papiers erfolgte und sie es kaum erwarten konnten, ihre vorherige Version zu wechseln Forschung zu Transformer. Transformer, gefolgt von GPT. Es ist ersichtlich, dass die Bedeutung von Transformer offensichtlich ist.
In 6 Jahren hat sich das auf Transformer basierende Modell immer weiter entwickelt und ist gewachsen. Jetzt hat jedoch jemand einen Fehler im ursprünglichen Transformer-Papier entdeckt.
Transformer-Architekturdiagramm und Code sind „inkonsistent“
Die Person, die den Fehler entdeckte, war Sebastian Raschka, ein bekannter Forscher für maschinelles Lernen und KI und Chef-KI-Ausbilder des Startups Lightning AI. Er wies darauf hin, dass das Architekturdiagramm im ursprünglichen Transformer-Papier falsch sei und eine Layer-Normalisierung (LN) zwischen Restblöcken platziert habe, was nicht mit dem Code übereinstimme.
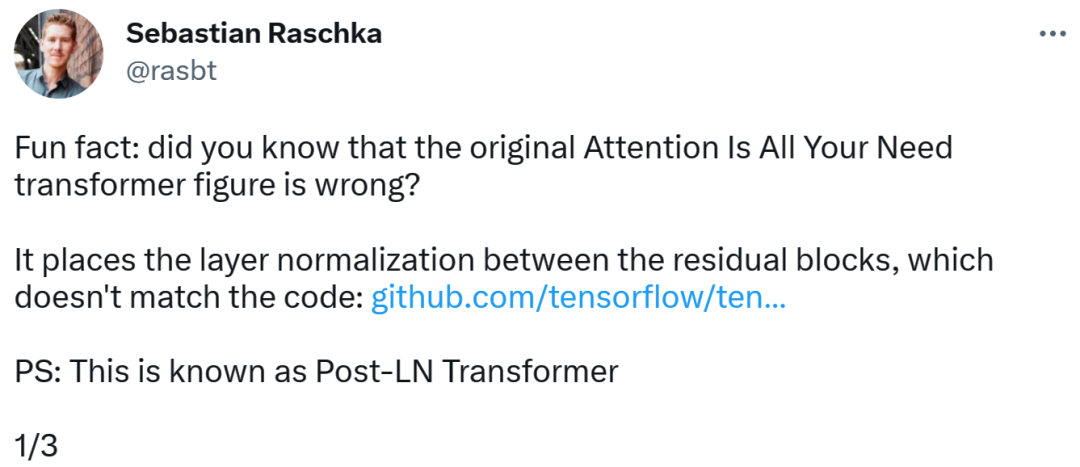
Das Diagramm der Transformatorarchitektur sieht wie folgt auf der linken Seite aus, und auf der rechten Seite befindet sich die Post-LN-Transformatorschicht (aus dem Artikel „On Layer Normalization in the Transformer Architecture“ [1]).
Der inkonsistente Codeteil lautet wie folgt: Zeile 82 schreibt die Ausführungssequenz „layer_postprocess_sequence="dan"", was bedeutet, dass die Nachverarbeitung Dropout, Residual_Add und Layer_norm nacheinander ausführt. Wenn add&norm in der linken Mitte des obigen Bildes so verstanden wird: add liegt über der Norm, also zuerst normieren und dann addieren, dann stimmt der Code tatsächlich nicht mit dem Bild überein.
Code-Adresse:
https://github.com/tensorflow/tensor2tensor/commit/f5c9b17e617ea9179b7d84d36b1e8162cb369f25#diff-76e2b94ef1 68 71bdbf46bf04dfe7f1477bafb884748f08197c9cf1b10a4dd78e…
Als nächstes sagte Sebastian, dass das Papier „On Layer „Normalisierung in der Transformatorarchitektur“ geht davon aus, dass Pre-LN eine bessere Leistung erbringt und das Gradientenproblem lösen kann. Dies ist bei vielen oder den meisten Architekturen in der Praxis der Fall, kann jedoch zum Zusammenbruch der Darstellung führen.
Bessere Farbverläufe können erreicht werden, wenn die Ebenennormalisierung in der Restverbindung vor den Aufmerksamkeits- und vollständig verbundenen Ebenen platziert wird.
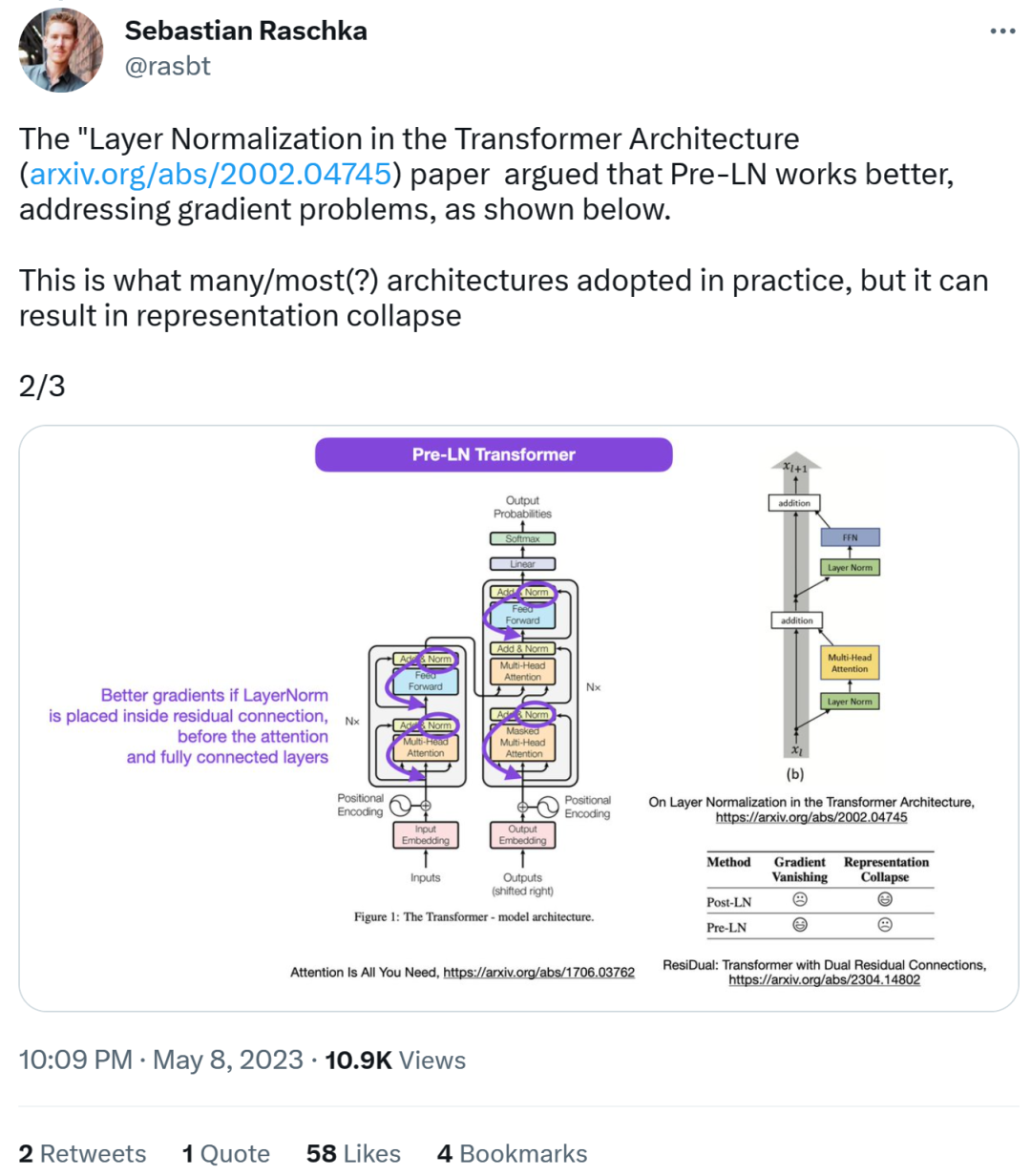
Während also die Debatte über Post-LN oder Pre-LN weitergeht, kombiniert ein anderer Artikel diese beiden Punkte, nämlich „ResiDual: Transformer with Dual Residual Connections“ [2] .
In Bezug auf Sebastians Entdeckung denken einige Leute, dass wir oft auf Papiere stoßen, die nicht mit dem Code oder den Ergebnissen übereinstimmen. Das meiste davon ist ehrlich, aber manchmal ist es seltsam. Angesichts der Popularität des Transformer-Papiers hätte diese Inkonsistenz tausendfach erwähnt werden müssen.
Sebastian antwortete, dass der „originellste“ Code zwar fairerweise mit dem Architekturdiagramm übereinstimmt, die 2017 eingereichte Codeversion jedoch geändert und das Architekturdiagramm nicht aktualisiert wurde. Das ist also wirklich verwirrend.
Ein Internetnutzer sagte: „Das Schlimmste am Lesen von Code ist, dass man oft kleine Änderungen wie diese findet und nicht weiß, ob sie beabsichtigt oder unbeabsichtigt sind. Sie können' Ich teste es nicht einmal, weil Sie nicht genug Rechenleistung haben, um das Modell zu trainieren.“
Ich weiß nicht, ob Google den Code oder das Architekturdiagramm in Zukunft aktualisieren wird, wir werden abwarten und sehen!
Das obige ist der detaillierte Inhalt vonDas Bild stimmt nicht mit dem Code überein. Im Transformer-Papier wurde ein Fehler gefunden: Es hätte 1.000 Mal darauf hingewiesen werden sollen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
