
 Technologie-Peripheriegeräte
KI
PandaLM ist reproduzierbar, automatisiert, kostengünstig und bietet eine hochwertige Auswertung, das erste große Modell, das große Modelle automatisch auswertet
Technologie-Peripheriegeräte
KI
PandaLM ist reproduzierbar, automatisiert, kostengünstig und bietet eine hochwertige Auswertung, das erste große Modell, das große Modelle automatisch auswertet
PandaLM ist reproduzierbar, automatisiert, kostengünstig und bietet eine hochwertige Auswertung, das erste große Modell, das große Modelle automatisch auswertet

Man kann sagen, dass die Entwicklung großer Modelle nach einem Regen wie Pilze aus dem Boden geschossen ist. Eine große Anzahl sogenannter ChatGPT-„Ersatz“-Großmodelle wurde nacheinander veröffentlicht. Bei der Schulung und Anwendungsentwicklung großer Modelle ist die Bewertung der tatsächlichen Fähigkeiten verschiedener großer Modelle wie Open Source, Closed Source und Selbstforschung zu einem wichtigen Glied bei der Verbesserung der Effizienz und Qualität von Forschung und Entwicklung geworden.
Insbesondere beim Training und der Anwendung großer Modelle sind Sie möglicherweise auf die folgenden Probleme gestoßen:
1. Bei der Feinabstimmung oder dem erweiterten Vortraining großer Modelle werden unterschiedliche Grundlagen verwendet Den beobachteten Beispieleffekten zufolge hat die Leistung des Modells in verschiedenen Szenarien ihre eigenen Vor- und Nachteile. Wie lässt sich bestimmen, welches Modell in tatsächlichen Anwendungen verwendet werden soll?
2. Verwenden Sie ChatGPT, um die Modellausgabe auszuwerten, aber ChatGPT erhält zu unterschiedlichen Zeiten unterschiedliche Auswertungsergebnisse für dieselbe Eingabe.
3. Die Verwendung manueller Anmerkungen zur Auswertung der Ergebnisse der Modellgenerierung ist zeitaufwändig und mühsam. Wie kann der Auswertungsprozess beschleunigt und die Kosten gesenkt werden, wenn das Budget begrenzt und die Zeit knapp ist?
4. Beim Umgang mit vertraulichen Daten, egal ob Sie ChatGPT/GPT4 verwenden oder Unternehmen zur Modellbewertung kennzeichnen, werden Sie mit Datenlecks konfrontiert.
Basierend auf diesen Fragen haben Forscher der Peking-Universität, der West Lake University und anderen Institutionen gemeinsam ein neues Paradigma zur Bewertung großer Modelle vorgeschlagen – PandaLM. PandaLM führt automatisierte und reproduzierbare Tests und Verifizierungen großer Modellfunktionen durch, indem ein großes Modell speziell für die Evaluierung trainiert wird. PandaLM wurde am 30. April auf GitHub veröffentlicht und ist das weltweit erste große Modell zur Evaluierung. Relevante Artikel werden in naher Zukunft veröffentlicht.

GitHub-Adresse: https://github.com/WeOpenML/PandaLM
PandaLM zielt darauf ab, dass das große Modell durch Training die allgemeine menschliche Präferenz für Text lernt, der von verschiedenen großen Modellen generiert wird . Und führen Sie relative Auswertungen basierend auf Präferenzen durch, um manuelle oder API-basierte Auswertungsmethoden zu ersetzen, um Kosten zu senken und die Effizienz zu steigern. Die Gewichte von PandaLM sind vollständig offengelegt und können auf Consumer-Hardware mit niedrigen Hardware-Schwellenwerten ausgeführt werden. Die Evaluierungsergebnisse von PandaLM sind zuverlässig, vollständig reproduzierbar und können die Datensicherheit gewährleisten. Der Evaluierungsprozess kann lokal durchgeführt werden, wodurch es sich sehr gut für den Einsatz in der Wissenschaft und in Einheiten eignet, die vertrauliche Daten benötigen. Die Verwendung von PandaLM ist sehr einfach und erfordert zum Aufrufen nur drei Codezeilen. Um die Evaluierungsfunktionen von PandaLM zu überprüfen, lud das PandaLM-Team drei professionelle Annotatoren ein, die Ergebnisse verschiedener großer Modelle unabhängig zu beurteilen, und erstellte einen vielfältigen Testsatz mit 1.000 Proben in 50 Feldern. Bei diesem Testsatz erreichte die Genauigkeit von PandaLM das Niveau von 94 % von ChatGPT, und PandaLM lieferte die gleichen Schlussfolgerungen über die Vor- und Nachteile des Modells wie die manuelle Annotation.
Einführung in PandaLM
Derzeit gibt es zwei Hauptmethoden zur Bewertung großer Modelle:
(1) Durch Aufrufen der API-Schnittstelle eines Drittunternehmens
(2) Einstellung von Experten für manuelle Anmerkung.
Allerdings kann die Übermittlung von Daten an Drittunternehmen zu Datenschutzverletzungen führen, ähnlich wie bei Samsung-Mitarbeitern, die Code preisgeben [1], und die Beauftragung von Experten für die Kennzeichnung großer Datenmengen ist zeitaufwändig und teuer. Ein dringendes Problem, das gelöst werden muss, ist: Wie kann eine datenschutzschonende, zuverlässige, reproduzierbare und kostengünstige Bewertung großer Modelle erreicht werden?
Um die Einschränkungen dieser beiden Bewertungsmethoden zu überwinden, wurde in dieser Studie PandaLM entwickelt, ein Schiedsrichtermodell, das speziell zur Bewertung der Leistung großer Modelle verwendet wird und eine einfache Schnittstelle bietet, mit der Benutzer PandaLM aufrufen können, um Datenschutz mit nur drei zu erreichen Codezeilen. Schützende, zuverlässige, wiederholbare und wirtschaftliche Modellbewertung im großen Maßstab. Einzelheiten zur Schulung zu PandaLM finden Sie im Open-Source-Projekt.
Um die Fähigkeit von PandaLM zur Bewertung großer Modelle zu validieren, erstellte das Forschungsteam einen vielfältigen, von Menschen kommentierten Testsatz mit etwa 1.000 Beispielen, wobei der Kontext und die Beschriftungen von Menschen generiert wurden. Im Testdatensatz erreichte PandaLM-7B eine Genauigkeit von 94 % von ChatGPT (gpt-3.5-turbo).
Wie verwende ich PandaLM?
Wenn zwei verschiedene große Modelle unterschiedliche Antworten auf dieselben Anweisungen und denselben Kontext erzeugen, besteht das Ziel von PandaLM darin, die Antworten der beiden Modelle zu vergleichen. Qualität, und Vergleichsergebnisse, Vergleichsbasis und Antworten als Referenz ausgeben. Es gibt drei Vergleichsergebnisse: Antwort 1 ist besser; Antwort 1 und Antwort 2 sind von gleicher Qualität. Wenn Sie die Leistung mehrerer großer Modelle vergleichen, verwenden Sie einfach PandaLM, um paarweise Vergleiche durchzuführen und diese Vergleiche dann zu aggregieren, um die Leistung der Modelle einzustufen oder die Teilreihenfolge der Modelle darzustellen. Dies ermöglicht eine visuelle Analyse der Leistungsunterschiede zwischen verschiedenen Modellen. Da PandaLM nur lokal bereitgestellt werden muss und kein menschliches Eingreifen erfordert, kann es datenschutzschonend und kostengünstig evaluiert werden. Um eine bessere Interpretierbarkeit zu gewährleisten, kann PandaLM seine Auswahl auch in natürlicher Sprache erklären und einen zusätzlichen Satz Referenzantworten generieren.
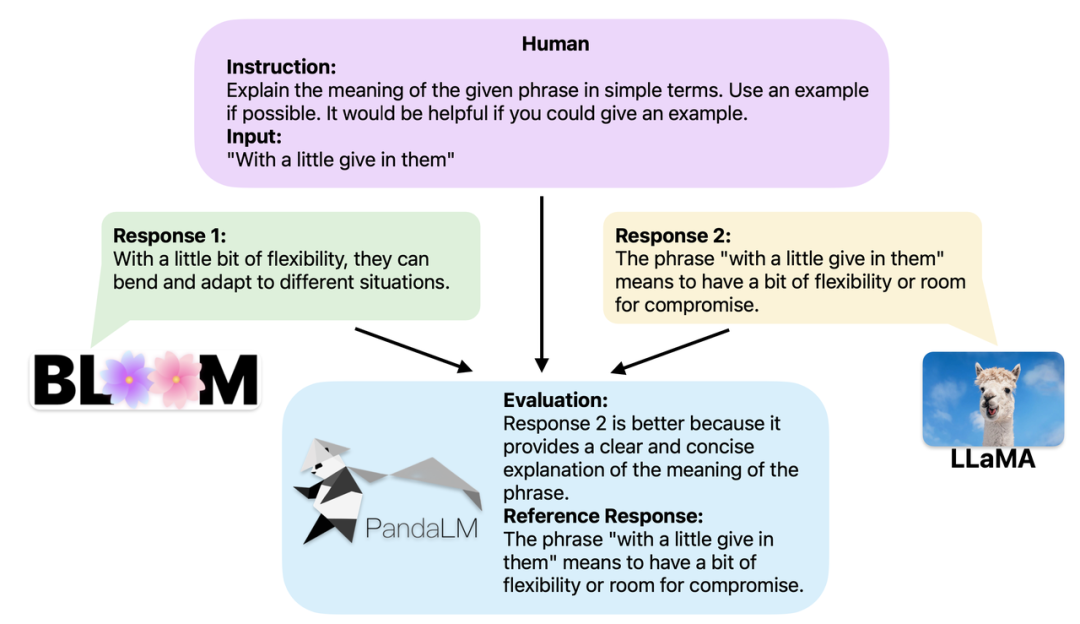
PandaLM unterstützt nicht nur die Verwendung der Web-Benutzeroberfläche, um die Fallanalyse zu erleichtern; Drei Codezeilen rufen PandaLM auf, um textuelle Auswertungen beliebiger Modelle und Daten zu generieren. In Anbetracht der Tatsache, dass viele vorhandene Modelle und Frameworks möglicherweise nicht Open Source sind oder lokal nur schwer abzuleiten sind, ermöglicht PandaLM die Generierung von auszuwertendem Text durch Angabe von Modellgewichten oder die direkte Übergabe einer .json-Datei mit dem auszuwertenden Text. Benutzer können PandaLM nutzen, um benutzerdefinierte Modelle und Eingabedaten auszuwerten, indem sie einfach eine Liste mit Modellnamen, HuggingFace-Modell-IDs oder .json-Dateipfaden bereitstellen. Das Folgende ist ein minimalistisches Anwendungsbeispiel:

Zusätzlich, um Damit jeder PandaLM flexibel zur kostenlosen Evaluierung nutzen kann, hat das Forschungsteam die Modellgewichte von PandaLM auf der HuggingFace-Website veröffentlicht. Sie können das PandaLM-7B-Modell ganz einfach mit dem folgenden Befehl laden:

Funktionen von PandaLM# 🎜🎜#
Zu den PandaLM-Funktionen gehören Reproduzierbarkeit, Automatisierung, Datenschutz, niedrige Kosten und ein hohes Bewertungsniveau.
1. Da die Gewichte von PandaLM öffentlich sind, auch wenn die Ausgabe des Sprachmodells Zufälligkeiten aufweist, werden nach der Korrektur des Zufallsstartwerts die Bewertungsergebnisse von PandaLM angezeigt Wird immer noch konsistent sein. Bewertungsmethoden, die auf Online-APIs basieren, können aufgrund undurchsichtiger Aktualisierungen zu unterschiedlichen Zeitpunkten inkonsistente Aktualisierungen aufweisen, und wenn Modelle iteriert werden, sind alte Modelle in der API möglicherweise nicht mehr zugänglich, sodass auf Online-APIs basierende Bewertungen häufig nicht reproduzierbar sind.
2. Automatisierung, Datenschutz und niedrige Kosten: Benutzer müssen das PandaLM-Modell nur lokal bereitstellen und vorgefertigte Befehle aufrufen, um verschiedene große Modelle zu bewerten, ohne Experten einzustellen. Dies erfordert die Aufrechterhaltung einer Echtzeitkommunikation und die Sorge vor Datenlecks. Gleichzeitig fallen für den gesamten Evaluierungsprozess von PandaLM keine API-Gebühren oder Arbeitskosten an, was sehr günstig ist.
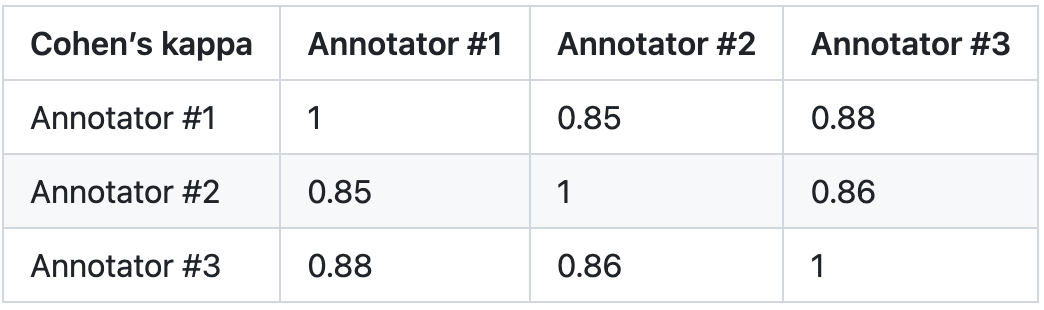
3. Bewertungsebene: Um die Zuverlässigkeit von PandaLM zu überprüfen, wurden für diese Studie drei Experten mit der unabhängigen Durchführung wiederholter Annotationen beauftragt und ein manueller Annotationstestsatz erstellt. Das Testset enthält 50 verschiedene Szenarien mit jeweils mehreren Aufgaben. Dieser Testsatz ist vielfältig, zuverlässig und entspricht den menschlichen Vorlieben für Text. Jede Stichprobe im Testsatz besteht aus Anweisungen und Kontext sowie zwei Antworten, die von verschiedenen großen Modellen generiert wurden, und die Qualität der beiden Antworten wird von Menschen verglichen.
Diese Studie eliminiert Proben mit großen Unterschieden zwischen Annotatoren und stellt sicher, dass die IAA (Inter Annotator Agreement) jedes Annotators im endgültigen Testsatz nahe bei 0,85 liegt. Es ist zu beachten, dass es keinerlei Überschneidungen zwischen dem PandaLM-Trainingssatz und dem in dieser Studie erstellten manuell kommentierten Testsatz gibt.
Diese gefilterten Proben erfordern zusätzliches Wissen oder schwer zu beschaffende Informationen zur Beurteilung, was es für Menschen schwierig macht, sie genau zu kennzeichnen. Der gefilterte Testsatz enthält 1000 Proben, während der ursprüngliche ungefilterte Testsatz 2500 Proben enthält. Die Verteilung des Testsatzes beträgt {0:105, 1:422, 2:472}, wobei 0 angibt, dass die beiden Antworten von ähnlicher Qualität sind; 1 angibt, dass Antwort 1 besser ist; 2 angibt, dass Antwort 2 besser ist.
Basierend auf dem menschlichen Testsatz ist der Leistungsvergleich zwischen PandaLM und gpt-3.5-turbo wie folgt:
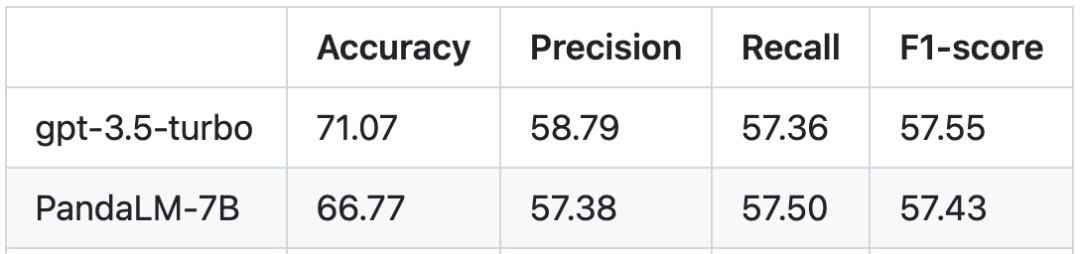
Es ist ersichtlich, dass PandaLM-7B gpt-3.5-turbo erreicht hat In Bezug auf die Genauigkeit erreicht Turbo ein Niveau von 94 %, und in Bezug auf Präzision, Rückruf und F1-Ergebnisse liegt PandaLM-7B fast auf dem gleichen Niveau wie gpt-3.5-turbo. Man kann sagen, dass PandaLM-7B bereits über große Modellbewertungsfunktionen verfügt, die gpt-3.5-turbo entsprechen.
Zusätzlich zu Genauigkeit, Präzision, Rückruf und F1-Ergebnissen des Testsatzes liefert diese Studie auch Ergebnisse von Vergleichen zwischen 5 großen Open-Source-Modellen ähnlicher Größe. Die Studie verwendete zunächst dieselben Trainingsdaten zur Feinabstimmung der fünf Modelle und führte dann mithilfe von Menschen, gpt-3.5-turbo und PandaLM paarweise Vergleiche der fünf Modelle durch. Das erste Tupel (72, 28, 11) in der ersten Zeile der Tabelle unten gibt an, dass es 72 LLaMA-7B-Antworten gibt, die besser sind als Bloom-7B, und 28 LLaMA-7B-Antworten, die schlechter sind als Bloom-7B Es gibt 11 Antworten von Modellen mit ähnlicher Qualität. In diesem Beispiel denken Menschen also, dass LLaMA-7B besser ist als Bloom-7B. Die Ergebnisse in den folgenden drei Tabellen zeigen, dass Menschen, gpt-3.5-turbo und PandaLM-7B in ihren Urteilen über die Überlegenheit und Unterlegenheit der einzelnen Modelle völlig übereinstimmen.
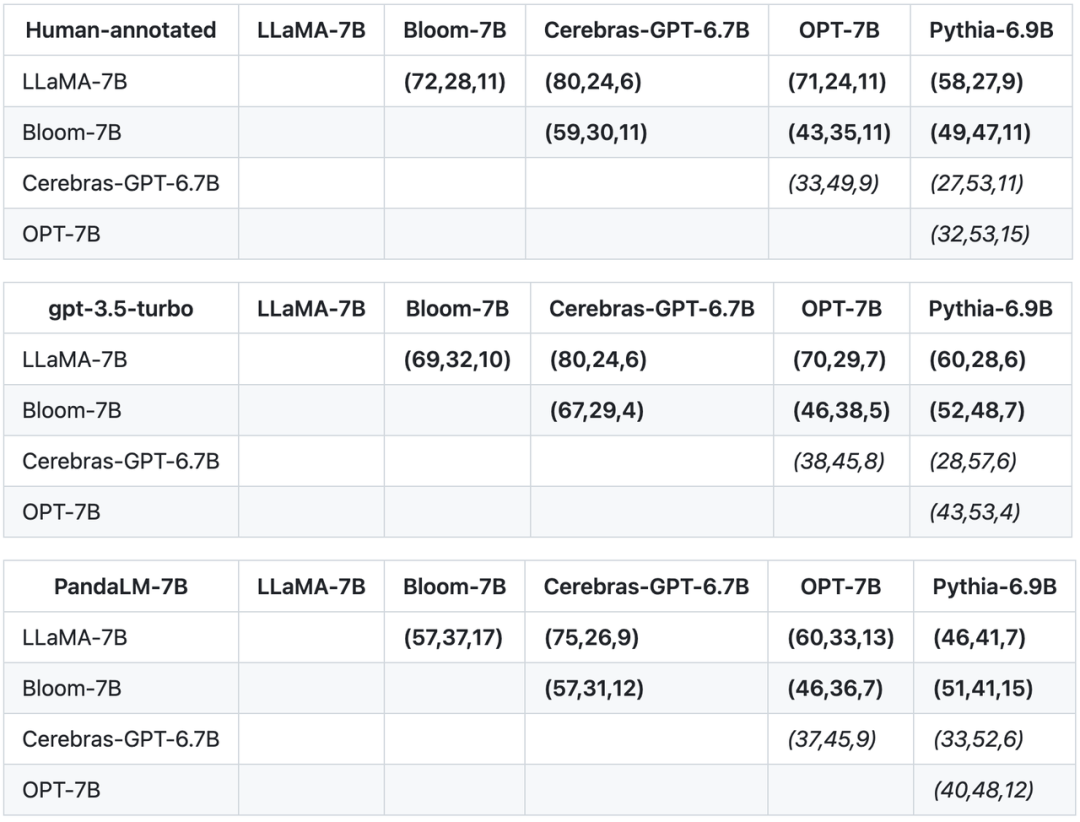
Basierend auf den oben genannten drei Tabellen hat diese Studie ein Teilordnungsdiagramm der Vor- und Nachteile des Modells erstellt. Dieses Teilordnungsdiagramm stellt die Gesamtordnungsbeziehung dar, die ausgedrückt werden kann als: LLaMA- 7B > Bloom-7B > Pythia-6.9B >
Zusammenfassung
Zusammenfassend bietet PandaLM neben der manuellen Auswertung und APIs von Drittanbietern eine dritte Möglichkeit zur Auswertung großer Modelle. Das Bewertungsniveau von PandaLM ist nicht nur hoch, sondern auch die Ergebnisse sind reproduzierbar, der Bewertungsprozess ist hochgradig automatisiert, die Privatsphäre ist geschützt und die Kosten sind niedrig. Das Forschungsteam ist davon überzeugt, dass PandaLM die Forschung an Großmodellen in Wissenschaft und Industrie fördern und es mehr Menschen ermöglichen wird, von den Fortschritten in diesem Forschungsbereich zu profitieren. Jeder ist herzlich eingeladen, dem PandaLM-Projekt Aufmerksamkeit zu schenken. Weitere Schulungen, Testdetails, verwandte Artikel und Folgearbeiten werden auf der Projektwebsite veröffentlicht: https://github.com/WeOpenML/PandaLM
Einführung in das Autorenteam
Autor Im Team ist Wang Yidong* vom National Engineering Center for Software Engineering der Peking University (Ph.D.) und der West Lake University (wissenschaftlicher Mitarbeiter) und Yu Zhuohao*, Zeng Zhengran , Jiang Chaoya, Xie Rui, Ye Wei† und Zhang Shikun† kommen vom National Engineering Center of Software Engineering der Universität Peking, Yang Linyi, Wang Cunxiang und Zhang Yue† kommen von der Westlake University, Heng Qiang kommt aus dem Bundesstaat North Carolina Chen Hao kommt von der Carnegie Mellon University und Wang Jindong und Xie Xing von Microsoft Research Asia. * gibt Co-Erstautor an, † gibt Co-Korrespondenzautor an.
Das obige ist der detaillierte Inhalt vonPandaLM ist reproduzierbar, automatisiert, kostengünstig und bietet eine hochwertige Auswertung, das erste große Modell, das große Modelle automatisch auswertet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Bei der Konvertierung von Zeichenfolgen in Objekte in Vue.js wird JSON.Parse () für Standard -JSON -Zeichenfolgen bevorzugt. Bei nicht standardmäßigen JSON-Zeichenfolgen kann die Zeichenfolge durch Verwendung regelmäßiger Ausdrücke verarbeitet und Methoden gemäß dem Format oder dekodierten URL-kodiert reduziert werden. Wählen Sie die entsprechende Methode gemäß dem String -Format aus und achten Sie auf Sicherheits- und Codierungsprobleme, um Fehler zu vermeiden.
 Vue- und Element-UI-Kaskaden-Dropdown-Box V-Model-Bindung
Apr 07, 2025 pm 08:06 PM
Vue- und Element-UI-Kaskaden-Dropdown-Box V-Model-Bindung
Apr 07, 2025 pm 08:06 PM
Vue- und Element-UI-kaskadierte Dropdown-Boxen V-Model-Bindung gemeinsame Grubenpunkte: V-Model bindet ein Array, das die ausgewählten Werte auf jeder Ebene des kaskadierten Auswahlfelds darstellt, nicht auf einer Zeichenfolge; Der Anfangswert von ausgewählten Optionen muss ein leeres Array sein, nicht null oder undefiniert. Die dynamische Belastung von Daten erfordert die Verwendung asynchroner Programmierkenntnisse, um Datenaktualisierungen asynchron zu verarbeiten. Für riesige Datensätze sollten Leistungsoptimierungstechniken wie virtuelles Scrollen und fauler Laden in Betracht gezogen werden.
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
Zusammenfassung: Es gibt die folgenden Methoden zum Umwandeln von VUE.JS -String -Arrays in Objektarrays: Grundlegende Methode: Verwenden Sie die Kartenfunktion, um regelmäßige formatierte Daten zu entsprechen. Erweitertes Gameplay: Die Verwendung regulärer Ausdrücke kann komplexe Formate ausführen, müssen jedoch sorgfältig geschrieben und berücksichtigt werden. Leistungsoptimierung: In Betracht ziehen die große Datenmenge, asynchrone Operationen oder effiziente Datenverarbeitungsbibliotheken können verwendet werden. Best Practice: Clear Code -Stil, verwenden Sie sinnvolle variable Namen und Kommentare, um den Code präzise zu halten.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
