

Zunächst einmal, was ist xPath: xPath ist eine Sprache zum Auffinden von Informationen in XML.
xPath enthält sieben Arten von Knoten: Elemente, Attribute, Text, Namespaces, Verarbeitungsanweisungen, Kommentare und Dokumentstammknoten. XML-Dokumente werden entsprechend der Struktur des Dokumentbaums analysiert. Die Wurzel des Dokumentbaums wird als Dokumentknoten oder Wurzelknoten bezeichnet.

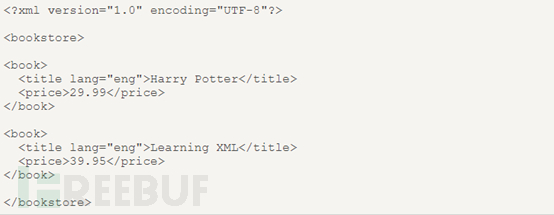
Dies ist der Quellcode eines einfachen XML-Dokuments. Aus diesem XML-Quellcode können wir ersehen, dass der Buchladen der Dokumentknoten (Wurzelknoten) ist und Buch, Titel, Autor, Jahr und Preis Elemente sind Knoten. Der Buchknoten hat vier untergeordnete Elementknoten: Titel, Autor, Jahr, Preis, und der Titelknoten hat drei Geschwister: Autor, Jahr, Preis. Der Titelelementknoten hat einen Attribut- und Textknoten. Der Attributknoten ist lang und sein Wert ist en. Der Wert des Textknotens ist HarryPotter.
Im Folgenden finden Sie auch einige Beschreibungen von XML-Knotenbeziehungen (ähnlich wie Bäume in Datenstrukturen):
Übergeordneter Knoten: Der übergeordnete Knoten des Buchknotens ist die Buchhandlung, und der Buchknoten ist der übergeordnete Knoten des Titels, des Autors, des Jahres und Preisknoten. (Jeder Knoten kann nur einen übergeordneten Knoten haben).
Untergeordnetes Element: Buch ist das untergeordnete Element des Buchladens und das untergeordnete Element des Buchknotens ist das untergeordnete Element von Titel, Autor, Jahr und Preis.
(Elementknoten können null, ein oder mehrere untergeordnete Elemente haben).
Zu den Geschwisterelementen des Titels gehören Autor, Jahr und Preis. Diese Elemente haben denselben übergeordneten Knoten, ähnlich wie Geschwisterknoten in einer Baumstruktur. (Knoten können null, eins oder mehrere Geschwister haben).
Vorfahren: Das übergeordnete Element des Knotens, das übergeordnete Element des übergeordneten Elements, das übergeordnete Element des übergeordneten Elements (Endlosschleife), die Vorfahren des Titelelementknotens sind Buch und Buchhandlung.
Nachkommen: Kinder von Knoten, Kinder von Kindern, Kinder von Kindern (Endlosschleife), die Nachkommen von Buchhandlungsdokumentknoten sind Buch, Titel, Autor, Jahr, Preis, Sprache.
Es reicht nicht aus, die Knotenbeziehungen von XML zu kennen, Sie müssen auch wissen, wie xPath Pfadausdrücke verwendet, um Knoten oder Knotensätze im Dokument auszuwählen. Knoten werden entlang von Pfaden oder Schritten ausgewählt.
XPath verwendet Pfadausdrücke, um Knoten in XML-Dokumenten auszuwählen. Knoten werden ausgewählt, indem einem Pfad oder Schritt gefolgt wird. Die nützlichsten Pfadausdrücke sind unten aufgeführt:
nodename: wählt alle Knoten dieses Knotens aus
/: wählt aus dem Wurzelknoten aus
//: wählt Knoten im Dokument aus dem aktuellen Knoten aus, die der Auswahl entsprechen, unabhängig von ihrer Positionen
.: Wählen Sie den aktuellen Knoten aus
..: Wählen Sie den übergeordneten Knoten des aktuellen Knotens aus
@: Wählen Sie das Attribut aus
Lassen Sie uns direkt mit der XPath-Abfragesyntax über js abfragen
Schreiben Sie zunächst einen Artikel über XPath-Aufruf von HTML (Der aufrufende Code wird in js geschrieben) Dateivorlage und bereiten Sie dann eine XML-Datei für die Abfrage vor.
Der Quellcode der JS-Vorlage lautet wie folgt:
https://www.runoob.com/try/try.php?filename=try_xpath_select_cdnodes
Sehen Sie sich den JS-Code in dieser HTML-Datei einzeln an (weil (es gibt nur js-Code)
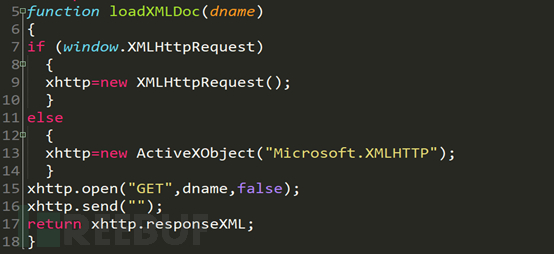
Dies ist eine asynchrone Aufruffunktion von js. Die wichtigen Codes befinden sich in den Zeilen 15 und 17. Die von der Funktion in Zeile 15 übergebene dname-Funktion ist der Pfad von XML und Zeile 17 gibt die erhaltene XML-Datei zurück.
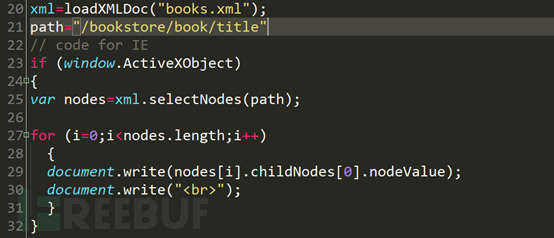
Bitte beachten Sie Zeile 20. Die Variable xml ruft die XML-Datei ab, die nach Ausführung der Funktion „loadXMLDOC“ erhalten wurde. Die Pfadvariable in Zeile 21 ist die Abfragesyntax von xpath. Die erste if-Anweisung bestimmt, ob es sich um einen Browser von IE6 oder niedriger handelt. Wenn es sich um einen Browser von IE6 oder niedriger handelt, werden nach dem Abrufen des Knotenarrays der entsprechenden Abfrage die Werte im Array durchlaufen und auf der Seite ausgegeben.
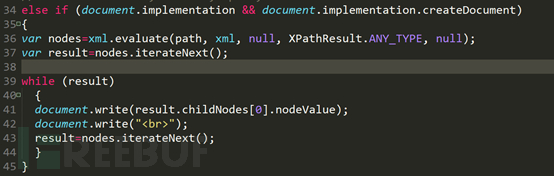
Für Nicht-IE6- und niedrigere Browser ist der Ausführungsprozess der zweiten if-Anweisung derselbe, aber die Syntax unterscheidet sich geringfügig. Bei Nicht-IE6- und niedrigeren Browsern wird die Abfrage über die Auswertungsfunktion durchgeführt, und das Format ist grundsätzlich gleich behoben. Üben Sie, was Sie gerade gesagt haben. Mehrere Grammatiken.
Um die Abfragesyntax zu ersetzen, müssen Sie nur den Wert von path ändern.

Listen Sie zunächst die Syntax auf, die abgefragt werden muss:
Hinweis: Wenn der Pfad mit einem Schrägstrich (/) beginnt, stellt dieser Pfad immer den absoluten Pfad zu einem Element dar!
Buchhandlung: Wählen Sie alle untergeordneten Knoten des Buchhandlungselements aus.
/bookstore: Wählen Sie das Stammelement bookstore aus.
bookstore/book: Wählt alle Buchelemente aus, die untergeordnete Elemente des bookstore sind.
//Buch: Wählt alle untergeordneten Buchelemente aus, unabhängig von ihrer Position im Dokument.
bookstore//book: Wählt alle Buchelemente aus, die Nachkommen des bookstore-Elements sind, unabhängig davon, wo sie sich unterhalb von bookstore: befinden.
//@lang: Wählen Sie alle Attribute mit dem Namen lang aus.
Wenn Sie nur diese einzelnen Abfragen verwenden, erhalten Sie möglicherweise nicht die erwarteten Ergebnisse. Sie müssen sie mit anderen Abfrageanweisungen kombinieren. Das Folgende ist eine Syntax, die angepasst werden muss:
Prädikat (verwenden Sie eckige Klammern, um präzisere Abfrageergebnisse zu erhalten):
Wählen Sie den Pfad des ersten Unterelements book des Bookstore-Elements zu /bookstore/book aus [1].
/bookstore/book[last()]: Wählen Sie das letzte Buchelement aus, das ein untergeordnetes Element von bookstore ist.
/bookstore/book[last()-1]: Wählen Sie das vorletzte Buchelement aus, das ein untergeordnetes Element von bookstore ist.
/bookstore/book[position()
//title[@lang]: Wählen Sie alle Titelelemente mit einem Attribut namens lang aus.
//title[@lang='eng']: Wählt alle Titelelemente aus, die ein lang-Attribut mit dem Wert eng haben.
/bookstore/book[price>35,00]: Wählen Sie alle Buchelemente des Buchladenelements aus, und der Wert des Preiselements muss größer als 35,00 sein.
/bookstore/book[price>35,00]/title: Wählen Sie alle Titelelemente des Buchelements im Buchladenelement aus, und der Wert des Preiselements muss größer als 35,00 sein.
Unbekannte Knoten auswählen:
*: Entspricht einem beliebigen Elementknoten.
@*: Entspricht einem beliebigen Attributknoten.
node(): Entspricht jedem Knotentyp.
Zum Beispiel:
/bookstore/*: Wählen Sie alle untergeordneten Elemente des Buchladenelements aus.
//*: Alle Elemente im Dokument auswählen.
//title[@*]: Wählen Sie alle Titelelemente mit Attributen aus.
Wählen Sie mehrere Pfade aus:
//book/title | //book/price: Wählen Sie alle Titel- und Preiselemente des Buchelements aus.
//Titel |. //Preis: Wählen Sie alle Titel- und Preiselemente im Dokument aus.
/bookstore/book/title |. //price: Wählen Sie alle Titelelemente aus, die zum Buchelement des bookstore-Elements gehören, und alle Preiselemente im Dokument.
Sehen Sie sich einige Abfragebeispiele an:
Fragen Sie den Titel ab zweiter Buchwert: /bookstore/book[1]/title

Fragen Sie den Wert des Titels aller Bücher ab: /bookstore/book//title

Fragen Sie den Wert aller Titel mit ab lang-Attribut: /bookstore /book//title[@lang]

Das obige ist der detaillierte Inhalt vonWas sind die grundlegenden Syntaxen für die xPath-Injektion?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So verwandeln Sie zwei Seiten in ein Word-Dokument
So verwandeln Sie zwei Seiten in ein Word-Dokument
 vue v-wenn
vue v-wenn
 Wie man Bilder in ppt scrollen lässt
Wie man Bilder in ppt scrollen lässt
 Kostenloser Website-Domainname
Kostenloser Website-Domainname
 Verwendung der Matlab-Griddata-Funktion
Verwendung der Matlab-Griddata-Funktion
 Standarddrucker festlegen
Standarddrucker festlegen
 Welche Software ist ig
Welche Software ist ig
 So lösen Sie das Problem, das Einschaltkennwort eines Win8-Computers zu vergessen
So lösen Sie das Problem, das Einschaltkennwort eines Win8-Computers zu vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



