

Was ist die Redis-Cache-Update-Strategie?

1. Vorteile und Kosten des Cachings
1.1 Vorteile
Beschleunigtes Lesen und Schreiben: Da Caches normalerweise vollen Speicher haben (z. B. Redis, Memcache) und die Speicherschicht normalerweise nicht über eine unzureichende Lese- und Schreibleistung verfügt (z. B wie MySQL) ist die Geschwindigkeit des Speicherlesens und -schreibens viel höher als die der Festplatten-E/A. Die Verwendung von Cache kann das Lesen und Schreiben effektiv beschleunigen und das Benutzererlebnis optimieren.
Back-End-Last reduzieren: Helfen Sie dem Back-End, die Zugriffsmenge zu reduzieren (Mysql ist auf eine maximale Anzahl von Verbindungen eingestellt. Wenn eine große Anzahl von Zugriffen gleichzeitig die Datenbank und die Festplatte erreichen Die E/A-Geschwindigkeit ist sehr langsam, was leicht dazu führen kann, dass die maximale Anzahl an Verbindungen ausgeschöpft wird, aber Redis ist theoretisch die größte) und komplexe Berechnungen (z. B. sehr komplexe SQL-Anweisungen) durchführen, was die Belastung erheblich reduziert Backend. 1.2 Kosten
- Nach dem Hinzufügen des Caches müssen die Logik der Cache-Schicht und der Speicherschicht gleichzeitig verarbeitet werden, was die Kosten für die Wartung des Codes für Entwickler erhöht.
-
Betriebs- und Wartungskosten:
Nehmen Sie Redis Cluster als Beispiel. Nach dem Beitritt erhöhen sich die Betriebs- und Wartungskosten virtuell. 1.3 Nutzungsszenarien
Komplexe Berechnungen mit hohem Overhead: Nehmen Sie MySQL als Beispiel (z. B. eine große Anzahl gemeinsamer Tabellenoperationen, einige Gruppierungsberechnungen) ohne Zwischenspeicherung Eine hohe Parallelität ist nicht nur unbefriedigend, sondern stellt auch eine enorme Belastung für MySQL dar.
- Auch wenn die Abfrage eines einzelnen Backend-Datenelements schnell genug ist, können Sie den Cache dennoch verwenden. Redis kann als Beispiel Zehntausende Lese- und Schreibvorgänge pro Sekunde durchführen Die bereitgestellten Batch-Operationen können die Reaktionszeit der gesamten E/A-Kette optimieren nach einer Weile verschwunden sein. Was ist der Grund?
Normalerweise wird der Redis-Cache im Speicher gespeichert, aber da Speicher kostbar und begrenzt ist, werden häufig billige und große Festplatten zur Speicherung verwendet. Eine Maschine verfügt möglicherweise nur über ein paar Dutzend Gigabyte Arbeitsspeicher, kann aber über mehrere Terabyte Festplattenkapazität verfügen. Redis basiert hauptsächlich auf Speicher, um leistungsstarke Lese- und Schreibvorgänge mit hoher Parallelität durchzuführen. Da der Speicher beispielsweise begrenzt ist, kann Redis nur 10 GB verwenden. Was werden Sie tun, wenn Sie 20 GB Daten hineinschreiben? Natürlich werden die 10G-Daten gelöscht und dann bleiben die 10G-Daten erhalten. Welche Daten müssen gelöscht werden? Welche Daten müssen aufbewahrt werden? Natürlich müssen Sie selten verwendete Daten löschen und häufig verwendete Daten aufbewahren. Die Ablaufrichtlinie von Redis legt fest, dass die Daten auch dann weiterhin Speicher belegen, wenn sie abgelaufen sind. Wenn in Redis der verwendete Speicher die Obergrenze des maximalen Speichers (used_memory>maxmemory) erreicht, wird die entsprechende Überlaufkontrollstrategie ausgelöst. Die spezifische Richtlinie wird durch den Parameter maxmemory-policy gesteuert.
- Redis unterstützt 6 Strategien:
Löschen Sie gemäß dem LRU-Algorithmus Schlüsselwerte mit Timeout-Attributen (Ablauf) und geben Sie ausreichend Speicherplatz frei. Wenn kein löschbares Schlüsselobjekt vorhanden ist, greifen Sie auf die Noeviction-Strategie zurück.
volatile-random: Abgelaufene Schlüssel nach dem Zufallsprinzip löschen, bis genügend Platz geschaffen ist.
allkeys-lru: Schlüssel gemäß dem LRU-Algorithmus löschen, unabhängig davon, ob Es sind Daten vorhanden oder nicht. Timeout-Eigenschaft festlegen, bis genügend Platz geschaffen ist.
allkeys-random: Alle Schlüssel nach dem Zufallsprinzip löschen, bis genügend Platz geschaffen ist (nicht empfohlen).
volatile-ttl: Basierend auf dem TTL (verbleibende Zeit). Löschen Sie im Attribut des Schlüsselwertobjekts (Lebensdauer, TTL) die Daten, die kürzlich ablaufen. Wenn nicht, greifen Sie auf die Noeviction-Strategie zurück mit dem Zeitstempel, der von den vorhandenen Cache-Elementen am weitesten von der aktuellen Zeit entfernt ist, werden aus dem Cache gelöscht.
Die Strategie zur Speicherüberlaufkontrolle kann mithilfe des Konfigurationssatzes maxmemory-policy{policy} dynamisch konfiguriert werden. Schreibbefehle führen bei einem Speicherüberlauf zu einer häufigen Ausführung der Speicherwiederherstellung, was sehr kostspielig ist. In der Master-Slave-Replikationsarchitektur wird der Löschbefehl, der dem Speicherwiederherstellungsvorgang entspricht, mit dem Slave-Knoten synchronisiert, um die Datenkonsistenz zwischen dem Master und dem Slave sicherzustellen Slave-Knoten, was zu einem Schreibverstärkungsproblem führt. 2.2 Ablaufstrategie
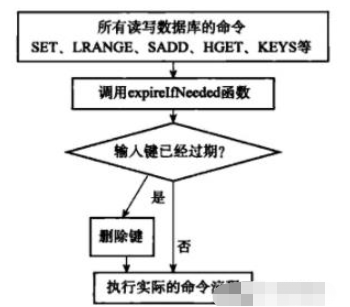
- Die vom Redis-Server übernommene Ablaufstrategie ist: verzögertes Löschen + reguläres Löschen Verzögertes Löschen:
-
Jede Redis-Bibliothek enthält ein Ablaufwörterbuch, das die Ablaufzeit aller Schlüssel speichert. Wenn der Client einen Schlüssel liest, prüft er zunächst, ob der Schlüssel im Ablaufwörterbuch abgelaufen ist. Wenn der Schlüssel abgelaufen ist, führt er einen Löschvorgang durch und gibt leer zurück. Mit dieser Strategie sollen CPU-Kosten gespart werden. Bei alleiniger Verwendung dieser Methode besteht jedoch das Problem eines Speicherverlusts. Wenn nicht auf den abgelaufenen Schlüssel zugegriffen wird, wird er nicht rechtzeitig gelöscht, was dazu führt, dass der Speicher nicht rechtzeitig freigegeben wird.

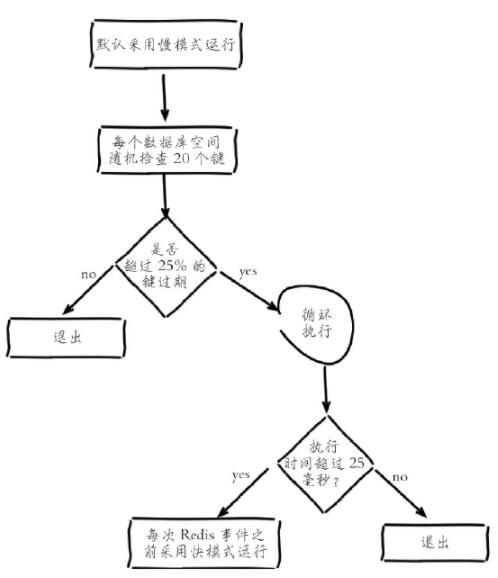
Geplantes Löschen:
Redis verwaltet intern eine geplante Aufgabe. Standardmäßig werden 10 Ablaufscans pro Sekunde ausgeführt (die Anzahl der Läufe wird durch die Hz-Konfiguration in redis.conf geändert). Stattdessen wird ein adaptiver Algorithmus verwendet, um Schlüssel basierend auf dem Ablaufverhältnis der Schlüssel und unter Verwendung von zwei Geschwindigkeitsmodi zu recyceln:
1. Entnehmen Sie zufällig 20 Schlüssel aus dem abgelaufenen Wörterbuch.
2 20 Schlüssel
3 .Wenn der Anteil der abgelaufenen Schlüssel 25 % überschreitet, wiederholen Sie die Schritte 1 und 2Um sicherzustellen, dass der Scan keinen übermäßigen Zyklus aufweist, wurden geplante Löschaufgaben ausgeführt und können keine Dienste für den Scan bereitstellen Außenwelt, was dazu führt, dass der Thread hängen bleibt und die Scanzeit zunimmt. Die Obergrenze beträgt standardmäßig 25 Millisekunden (d. h. im langsamen Modus wird standardmäßig in den Blockmodus gewechselt. Das Zeitlimit im Modus ist 1 Millisekunde und kann nur einmal in 2 Sekunden ausgeführt werden, wird normal beendet und wechselt zurück in den Schnellmodus)
3. Anwendungsaktualisierung
1 Ruft zuerst die Daten aus dem Cache ab. Wenn sie nicht abgerufen werden, werden die Daten aus der Datenbank abgerufen. Nach Erfolg werden sie in den Cache gelegt.
2. Löschen Sie zuerst den Cache und aktualisieren Sie dann die Datenbank: Nach dem Löschen des Caches wird eine Leseanforderung zum Aktualisieren der Daten empfangen direkt gelesen werden. Die Daten für den Lesevorgang sind alt und werden in den Cache geladen. Nachfolgende Leseanforderungen greifen auf alle alten Daten zu.
3. Aktualisieren Sie zuerst die Datenbank und löschen Sie dann den Cache (empfohlen). Der Hauptgrund besteht darin, dass zwei gleichzeitige Schreibvorgänge zu fehlerhaften Daten führen können.4. Cache-Granularität
1 Vielseitigkeit
Das Zwischenspeichern aller Daten ist vielseitiger als Teildaten, aber erfahrungsgemäß erfordern Anwendungen über einen langen Zeitraum nur wenige wichtige Attribute.
2 Platzbedarf
Das Zwischenspeichern aller Daten nimmt mehr Platz in Anspruch als Teildaten. Es gibt die folgenden Probleme:
Alle Daten führen zu einer Speicherverschwendung.
Alle Daten können jedes Mal eine große Menge Netzwerkverkehr erzeugen, relativ lange dauern und im Extremfall das Netzwerk blockieren.
Der CPU-Overhead für die Serialisierung und Deserialisierung aller Daten ist größer.
3 Codepflege
Vollständige Daten haben offensichtliche Vorteile, aber wenn Sie einigen Daten neue Felder hinzufügen möchten, müssen Sie den Geschäftscode ändern und normalerweise die zwischengespeicherten Daten aktualisieren.
Das obige ist der detaillierte Inhalt vonWas ist die Redis-Cache-Update-Strategie?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So erstellen Sie Message Middleware für Redis
Apr 10, 2025 pm 07:51 PM
So erstellen Sie Message Middleware für Redis
Apr 10, 2025 pm 07:51 PM
Redis unterstützt als Messing Middleware Modelle für Produktionsverbrauch, kann Nachrichten bestehen und eine zuverlässige Lieferung sicherstellen. Die Verwendung von Redis als Message Middleware ermöglicht eine geringe Latenz, zuverlässige und skalierbare Nachrichten.
