
 Technologie-Peripheriegeräte
KI
GPT fungiert als Gehirn und weist mehrere Modelle an, zusammenzuarbeiten, um verschiedene Aufgaben zu erledigen. Das allgemeine System AutoML-GPT ist da.
Technologie-Peripheriegeräte
KI
GPT fungiert als Gehirn und weist mehrere Modelle an, zusammenzuarbeiten, um verschiedene Aufgaben zu erledigen. Das allgemeine System AutoML-GPT ist da.
GPT fungiert als Gehirn und weist mehrere Modelle an, zusammenzuarbeiten, um verschiedene Aufgaben zu erledigen. Das allgemeine System AutoML-GPT ist da.

Obwohl KI-Modelle derzeit in sehr vielen Anwendungsbereichen eingesetzt werden, sind die meisten KI-Modelle für bestimmte Aufgaben konzipiert und erfordern oft viel Personal, um die richtige Modellarchitektur, Optimierungsalgorithmen und Hyperparameter fertigzustellen. Nachdem ChatGPT und GPT-4 populär wurden, erkannten die Menschen das enorme Potenzial großer Sprachmodelle (LLM) für das Verständnis, die Generierung, die Interaktion, das Denken usw. von Texten. Einige Forscher versuchen, LLM zu nutzen, um neue Wege zur künstlichen allgemeinen Intelligenz (AGI) zu erkunden.
Kürzlich haben Forscher der University of Texas in Austin eine neue Idee vorgeschlagen – aufgabenorientierte Eingabeaufforderungen zu entwickeln, LLM zur Automatisierung der Trainingspipeline zu verwenden und ein neues System AutoML-GPT auf der Grundlage dieser Idee zu starten.

Papieradresse:
https://www.php.cn/link/39d4b545fb02556829aab1db805021c3
AutoML-GPT nutzt GPT als Brücke zwischen verschiedenen KI-Modellen und das Modell dynamisch mit optimierten Hyperparametern trainieren. AutoML-GPT empfängt dynamisch Benutzeranfragen von Model Card [Mitchell et al., 2019] und Data Card [Gebru et al., 2021] und erstellt entsprechende Eingabeaufforderungsabsätze. Schließlich verwendet AutoML-GPT diesen Eingabeaufforderungsabsatz, um automatisch mehrere Experimente durchzuführen, einschließlich der Datenverarbeitung, des Aufbaus einer Modellarchitektur, der Optimierung von Hyperparametern und der Vorhersage von Trainingsprotokollen.
AutoML-GPT löst komplexe KI-Aufgaben über eine Vielzahl von Tests und Datensätzen hinweg, indem es seine leistungsstarken NLP-Funktionen und vorhandenen KI-Modelle maximiert. Zahlreiche Experimente und Ablationsstudien haben gezeigt, dass AutoML-GPT für viele Aufgaben der künstlichen Intelligenz (einschließlich CV-Aufgaben und NLP-Aufgaben) vielseitig und effektiv ist.
Einführung in AutoML-GPT
AutoML-GPT ist ein kollaboratives System, das auf Daten und Modellinformationen basiert, um Eingabeaufforderungsabsätze zu formatieren. Unter ihnen fungiert LLM als Controller und mehrere Expertenmodelle fungieren als kollaborative Ausführende. Der Arbeitsablauf von AutoML-GPT umfasst vier Phasen: Datenverarbeitung, Modellarchitekturentwurf, Hyperparameteranpassung und Trainingsprotokollerstellung.
Im Einzelnen ist der Arbeitsmechanismus von AutoML-GPT wie folgt:
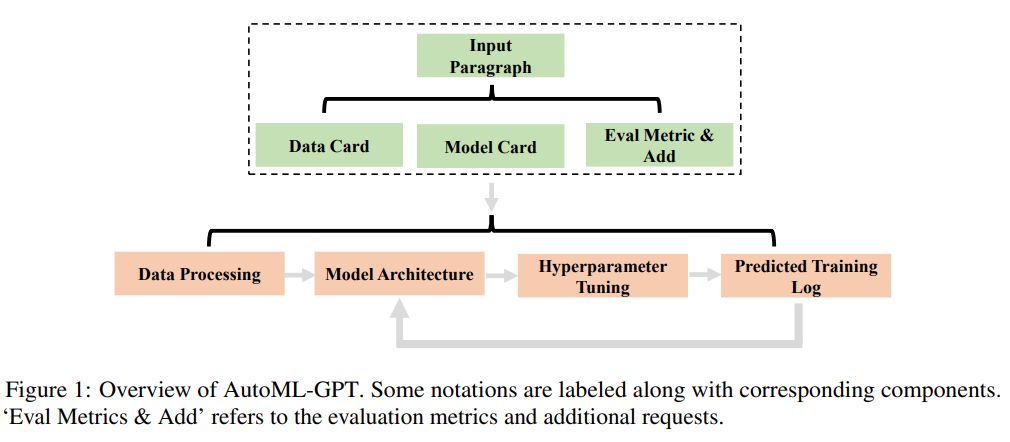
- Generieren Sie Eingabeaufforderungsabsätze mit festem Format über Modellkarte und Datenkarte.
- Erstellen Sie eine Trainingspipeline für den ausgewählten Datensatz und Benutzeranforderungen an die Modellarchitektur berücksichtigen
- Erstellung von Leistungstrainingsprotokollen und Anpassung von Hyperparametern
- Anpassung des Modells basierend auf automatisch vorgeschlagenen (automatisch vorgeschlagenen) Hyperparametern
Eingabezerlegung
AutoML – Die erste Stufe von GPT besteht darin, dass LLM Benutzereingaben akzeptiert. Um die Leistung von LLM zu verbessern und effektive Eingabeaufforderungen zu generieren, werden in dieser Studie spezifische Anweisungen für Eingabeaufforderungen übernommen. Diese Anweisungen umfassen drei Teile: Datenkarte, Modellkarte, Bewertungsmetriken und zusätzliche Anforderungen.
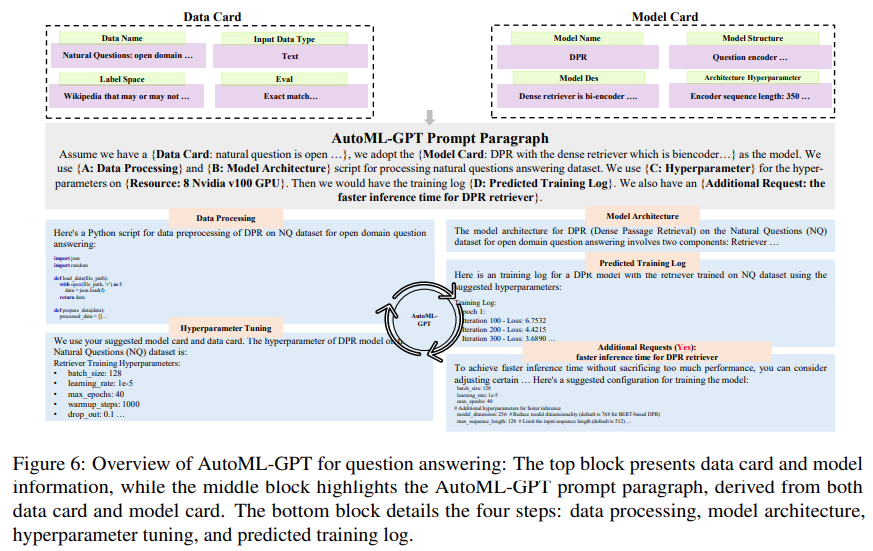
Wie in Abbildung 2 unten dargestellt, bestehen die wichtigsten Teile der Datenkarte aus dem Namen des Datensatzes, dem Typ des Eingabedatensatzes (z. B. Bilddaten oder Textdaten), dem Beschriftungsbereich (z. B. Kategorie oder Auflösung) und Standardbewertungsmetriken .
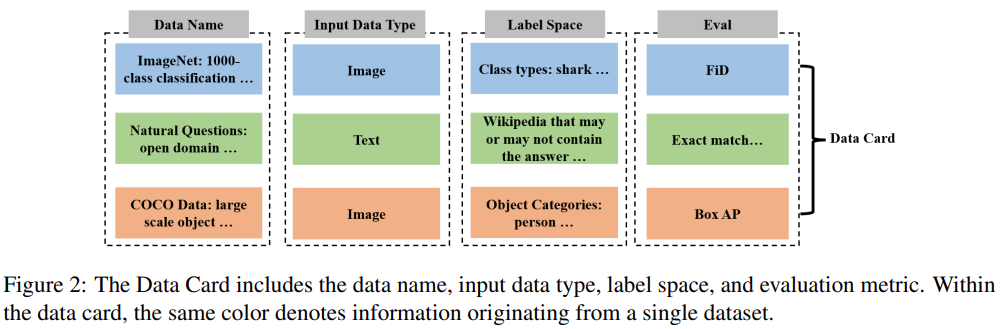
Wie in Abbildung 3 unten dargestellt, besteht die Modellkarte aus Modellnamen, Modellstruktur, Modellbeschreibung und Architektur-Hyperparametern. Durch die Bereitstellung dieser Informationen kann Model Card LLM mitteilen, welche Modelle vom gesamten maschinellen Lernsystem verwendet werden und welche Präferenzen der Benutzer für die Modellarchitektur hat.
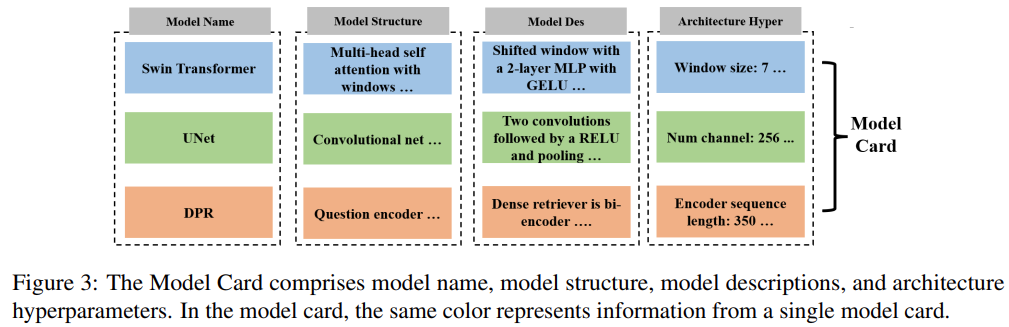
Zusätzlich zur Datenkarte und Modellkarte können Benutzer auch weitere Bewertungsbenchmarks, Bewertungsmetriken oder andere Einschränkungen anfordern. AutoML-GPT stellt LLM diese Aufgabenspezifikationen als übergeordnete Anweisungen zur entsprechenden Analyse der Benutzeranforderungen zur Verfügung.
Wenn eine Reihe von Aufgaben verarbeitet werden müssen, muss AutoML-GPT das entsprechende Modell für jede Aufgabe anpassen. Um dieses Ziel zu erreichen, muss das System zunächst die Modellbeschreibung von der Modellkarte und Benutzereingaben abrufen.
Dann verwendet AutoML-GPT den kontextbezogenen Aufgabenmodellzuordnungsmechanismus, um Modelle dynamisch Aufgaben zuzuweisen. Dieser Ansatz ermöglicht einen inkrementellen Modellzugriff und sorgt durch die Kombination der Modellbeschreibung mit einem besseren Verständnis der Benutzerbedürfnisse für mehr Offenheit und Flexibilität.
Hyperparameter mit vorhergesagten Trainingsprotokollen abstimmen
AutoML-GPT legt Hyperparameter basierend auf Datenkarte und Modellkarte fest und sagt die Leistung voraus, indem Trainingsprotokolle von Hyperparametern erstellt werden. Das System führt das Training automatisch durch und gibt Trainingsprotokolle zurück. Modellleistungstrainingsprotokolle im Datensatz zeichnen verschiedene Metriken und Informationen auf, die während des Trainingsprozesses gesammelt wurden. Dies hilft, den Modelltrainingsfortschritt zu verstehen, potenzielle Probleme zu identifizieren und die Wirksamkeit der ausgewählten Architektur, Hyperparameter und Optimierungsmethoden zu bewerten.
Experimente
Um die Leistung von AutoML-GPT zu bewerten, verwendete diese Studie ChatGPT (die GPT-4-Version von OpenAI) zur Implementierung und führte mehrere Experimente durch, um die Wirkung von AutoML-GPT aus mehreren Perspektiven zu demonstrieren.
Abbildung 4 unten zeigt die Ergebnisse des Trainings für den unbekannten Datensatz mit AutoML-GPT:

Abbildung 5 unten zeigt den Prozess, bei dem AutoML-GPT die Zielerkennungsaufgabe für den COCO-Datensatz abschließt:
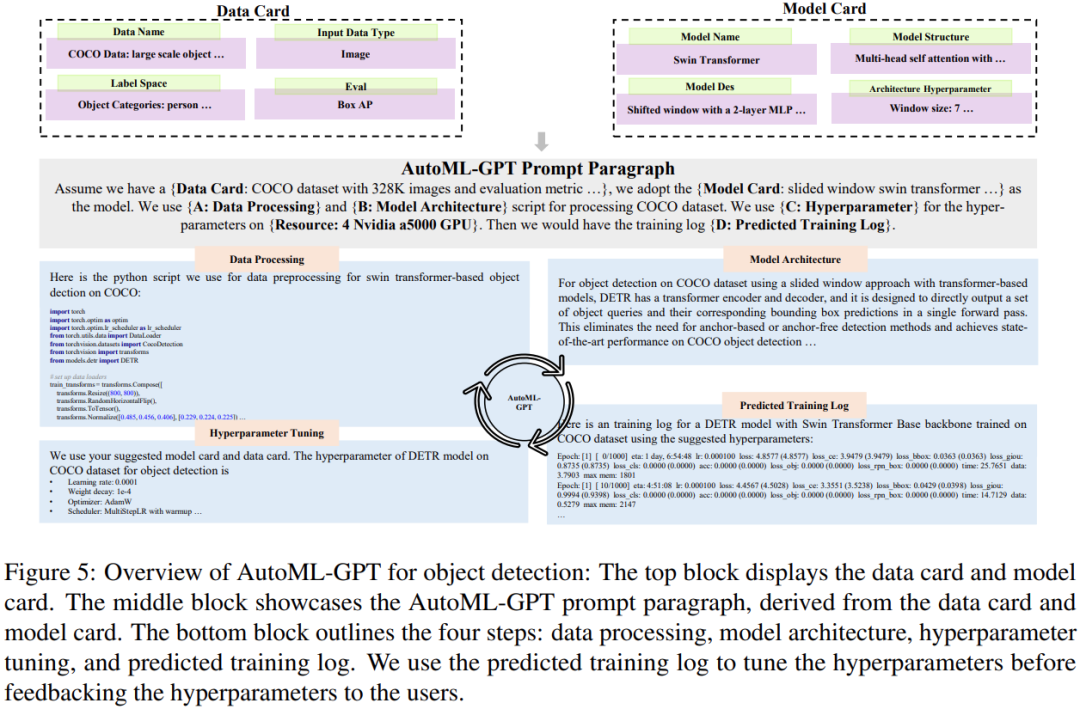
Abbildung 6 unten zeigt die experimentellen Ergebnisse von AutoML-GPT für den NQ Open-Datensatz (Natural Questions Open-Datensatz, [Kwiatkowski et al., 2019]):
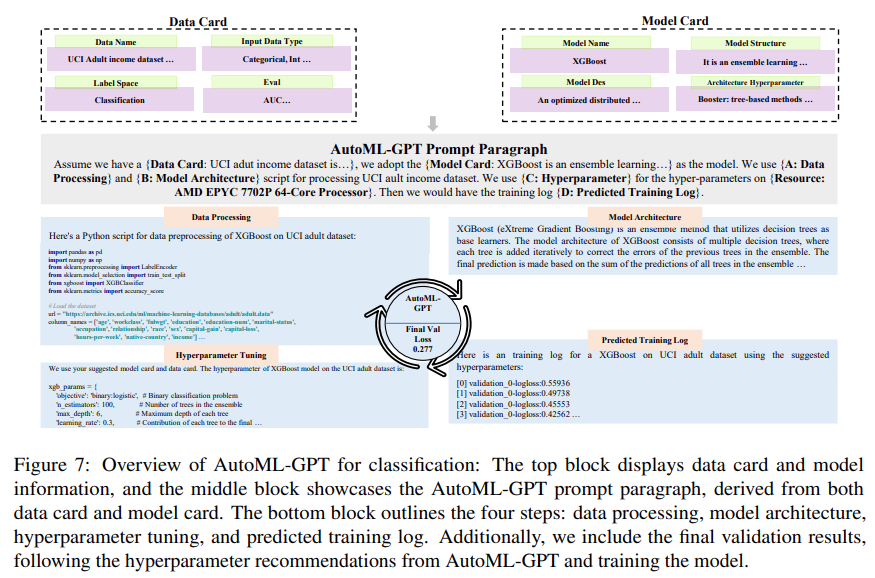
Diese Studie wurde auch verwendet XGBoost hat AutoML-GPT anhand des UCI-Datensatzes für Erwachsene [Dua und Graff, 2017] ausgewertet, um seine Leistung bei Klassifizierungsaufgaben zu untersuchen. Die experimentellen Ergebnisse sind in Abbildung 7 unten dargestellt:
Interessierte Leser können das Originalpapier lesen um mehr über die Forschungsdetails zu erfahren.
Das obige ist der detaillierte Inhalt vonGPT fungiert als Gehirn und weist mehrere Modelle an, zusammenzuarbeiten, um verschiedene Aufgaben zu erledigen. Das allgemeine System AutoML-GPT ist da.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
DALL-E 3 wurde im September 2023 offiziell als deutlich verbessertes Modell gegenüber seinem Vorgänger eingeführt. Er gilt als einer der bisher besten KI-Bildgeneratoren und ist in der Lage, Bilder mit komplexen Details zu erstellen. Zum Start war es jedoch exklusiv
 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
Laut Nachrichten dieser Website vom 1. August hat SK Hynix heute (1. August) einen Blogbeitrag veröffentlicht, in dem es ankündigt, dass es am Global Semiconductor Memory Summit FMS2024 teilnehmen wird, der vom 6. bis 8. August in Santa Clara, Kalifornien, USA, stattfindet viele neue Technologien Generation Produkt. Einführung des Future Memory and Storage Summit (FutureMemoryandStorage), früher Flash Memory Summit (FlashMemorySummit), hauptsächlich für NAND-Anbieter, im Zusammenhang mit der zunehmenden Aufmerksamkeit für die Technologie der künstlichen Intelligenz wurde dieses Jahr in Future Memory and Storage Summit (FutureMemoryandStorage) umbenannt Laden Sie DRAM- und Speicheranbieter und viele weitere Akteure ein. Neues Produkt SK Hynix wurde letztes Jahr auf den Markt gebracht
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
