
 Datenbank
Redis
So realisieren Sie die Identifizierung und den Austausch heißer und kalter Daten in Redis
Datenbank
Redis
So realisieren Sie die Identifizierung und den Austausch heißer und kalter Daten in Redis
So realisieren Sie die Identifizierung und den Austausch heißer und kalter Daten in Redis

Hintergrund
Das Redis-Hybridspeicherprodukt ist ein von Alibaba Cloud unabhängig entwickeltes Hybridspeicherprodukt, das vollständig mit dem Redis-Protokoll und den Redis-Funktionen kompatibel ist.
Durch die Speicherung eines Teils der kalten Daten auf der Festplatte werden die Benutzerkosten erheblich reduziert und das Speicherlimit für das Datenvolumen einer Redis-Einzelinstanz durchbrochen, während gleichzeitig sichergestellt wird, dass die Zugriffsleistung größtenteils nicht abnimmt.
Unter anderem sind die Identifizierung und der Austausch heißer und kalter Daten Schlüsselfaktoren für die Leistung hybrider Speicherprodukte.
Definition von Hot- und Cold-Daten
Im Redis-Hybridspeicher ist das Verhältnis von Arbeitsspeicher zu Festplatte vom Benutzer frei wählbar:
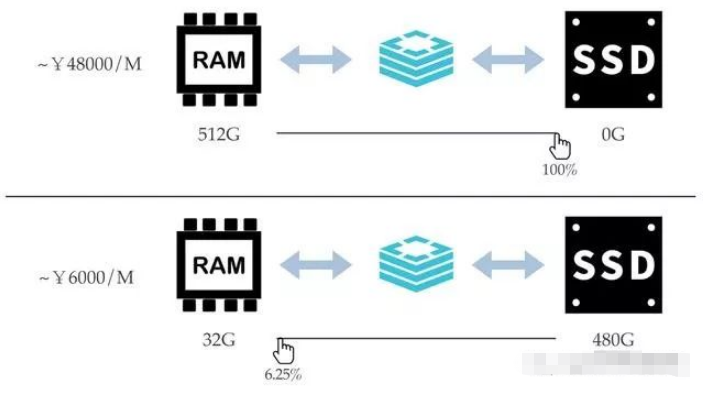
Die Redis-Hybridspeicherinstanz betrachtet alle Schlüssel als Hot-Daten und verbraucht nur wenig Speicher as Die Kosten stellen sicher, dass die Leistung aller Schlüsselzugriffsanforderungen effizient und konsistent ist. Wenn für den Wertteil nicht genügend Speicher vorhanden ist, wählt die Instanz selbst einen Teil des Werts basierend auf der letzten Zugriffszeit, der Zugriffshäufigkeit, der Wertgröße und anderen Dimensionen als kalte Daten aus und speichert sie im Hintergrund asynchron auf der Festplatte, bis der Speicher verfügbar ist liegt unter dem angegebenen Schwellenwert.
In der Redis-Hybridspeicherinstanz betrachten wir alle Schlüssel als Hot Data und speichern sie aus den folgenden zwei Gründen im Speicher:
Die Schlüsselzugriffshäufigkeit ist viel höher als der Wert.
Als KV-Datenbank müssen normale Zugriffsanfragen zunächst nach dem Schlüssel suchen, um zu bestätigen, dass ein Schlüssel nicht vorhanden ist. Um zu bestätigen, dass ein Schlüssel nicht vorhanden ist, müssen Sie den Satz aller Schlüssel in irgendeiner Form überprüfen. Durch die Beibehaltung aller Schlüsselwerte für speicherinterne Datenstrukturen kann sichergestellt werden, dass die Suchgeschwindigkeit genau der von reinen Speicherdatenstrukturen entspricht.
Das Tastengrößenverhältnis ist sehr niedrig.
In einem allgemeinen Geschäftsmodell ist sein Wert im Allgemeinen um ein Vielfaches größer als der Schlüssel, selbst wenn es sich um einen gewöhnlichen Zeichenfolgentyp handelt. Bei Sammlungsobjekten wie Set, List, Hash usw. ist der aus der Summe aller Mitglieder gebildete Wert mehrere Größenordnungen größer als der Schlüssel.
Daher gibt es zwei Hauptszenarien für Redis-Hybridspeicherinstanzen:
Ungleichmäßiger Datenzugriff und Hotspot-Daten;
Der Speicher reicht nicht aus, um alle Daten zu speichern, und der Wert ist groß ( relativ zum Schlüssel)
Identifizierung heißer und kalter Daten
Wenn nicht genügend Speicher vorhanden ist, berechnet die Instanz das Gewicht des Werts basierend auf der letzten Zugriffszeit, der Zugriffshäufigkeit, der Wertgröße und anderen Dimensionen und speichert den Wert mit das niedrigste Gewicht auf der Festplatte und wird aus dem Speicher entfernt.
Der Pseudocode lautet wie folgt:

Im idealsten Fall möchten wir in der Lage sein, den aktuell niedrigsten Wert genau zu berechnen. Der Heiß- und Kaltgrad eines Werts ändert sich jedoch je nach Zugriffssituation dynamisch, und der Zeitaufwand für die jedesmalige Neuberechnung der Heiß- und Kaltgewichte aller Werte ist völlig inakzeptabel.
Redis selbst löscht Daten gemäß der vom Benutzer festgelegten Eliminierungsstrategie, wenn der Speicher voll ist, und das Schreiben heißer Daten vom Speicher auf die Festplatte kann ebenfalls als „Eliminierungsvorgang“ betrachtet werden. Unter Berücksichtigung von Leistung, Genauigkeit und Benutzerverständnis verwenden wir bei der Identifizierung heißer und kalter Daten eine ungefähre Berechnungsmethode ähnlich wie Redis, unterstützen mehrere Strategien, reduzieren den CPU- und Speicherverbrauch durch zufällige Stichproben eines kleinen Teils der Daten und nutzen Stichproben durch historische Eviction-Pools Informationen zur Verbesserung der Genauigkeit.
Das schematische Diagramm der Trefferquote des ungefähren Eliminierungsalgorithmus von Redis wird in verschiedenen Versionen und mit unterschiedlicher Anzahl von Stichprobenkonfigurationen angezeigt. Datenpunkte, die eliminiert wurden, sind hellgrau gefärbt, Datenpunkte, die nicht eliminiert wurden, sind grau und Datenpunkte, die während des Tests hinzugefügt wurden, sind grün gefärbt.
Heißer und kalter Datenaustausch
Redis-Mischspeicher Der Prozess des heißen und kalten Datenaustauschs wird im Hintergrund-E/A-Thread abgeschlossen.
Heiße Daten ->Kalte Daten
Asynchrone Methode:
Der Hauptthread generiert eine Reihe von Datenaustauschaufgaben, wenn der Speicher fast voll ist;
Der Hintergrundthread führt diesen Datenaustausch aus Aufgaben: Nachdem die Ausführung abgeschlossen ist, wird der Hauptthread benachrichtigt.
-
Der Hauptthread aktualisiert den Wert im freigegebenen Speicher und aktualisiert den Wert im Datenwörterbuch im Speicher auf eine einfache Metainformation
Synchronisationsmethode: - Wenn der Datenverkehr beim Schreiben zu groß ist, kann die asynchrone Methode die Daten nicht rechtzeitig austauschen, was dazu führen kann, dass der Speicher die maximale Spezifikation überschreitet. Der Hauptthread führt die Datenaustauschaufgabe direkt aus, um den Zweck der verdeckten Strombegrenzung zu erreichen.
Kalte Daten ->Heiße Daten
Asynchrone Methode:
Bevor der Befehl ausgeführt wird, ermittelt der Hauptthread zunächst, ob sich die am Befehl beteiligten Werte im Speicher befinden.- Wenn nicht, Generieren Sie eine Datenladeaufgabe, halten Sie den Client an und der Hauptthread verarbeitet weiterhin andere Clientanforderungen.
- Der Hintergrundthread führt die Datenladeaufgabe aus und benachrichtigt den Hauptthread nach Abschluss den Wert im Datenwörterbuch im Speicher, weckt den zuvor angehaltenen Client auf und verarbeitet seine Anfrage.
- Synchronisationsmethode:
- Wenn im Lua-Skript während der spezifischen Befehlsausführungsphase festgestellt wird, dass ein Wert auf der Festplatte gespeichert ist, führt der Hauptthread direkt die Datenladeaufgabe aus, um die Semantik sicherzustellen des Lua-Skripts und -Befehls bleiben unverändert.
Das obige ist der detaillierte Inhalt vonSo realisieren Sie die Identifizierung und den Austausch heißer und kalter Daten in Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
Um alle Schlüssel in Redis anzuzeigen, gibt es drei Möglichkeiten: Verwenden Sie den Befehl keys, um alle Schlüssel zurückzugeben, die dem angegebenen Muster übereinstimmen. Verwenden Sie den Befehl scan, um über die Schlüssel zu iterieren und eine Reihe von Schlüssel zurückzugeben. Verwenden Sie den Befehl Info, um die Gesamtzahl der Schlüssel zu erhalten.
 So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
Zu den Schritten zum Starten eines Redis -Servers gehören: Installieren von Redis gemäß dem Betriebssystem. Starten Sie den Redis-Dienst über Redis-Server (Linux/macOS) oder redis-server.exe (Windows). Verwenden Sie den Befehl redis-cli ping (linux/macOS) oder redis-cli.exe ping (Windows), um den Dienststatus zu überprüfen. Verwenden Sie einen Redis-Client wie Redis-Cli, Python oder Node.js, um auf den Server zuzugreifen.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
